Introduction
Models
Aya Vision
Aya Vision是一个多模态大语言模型,包含8B, 32B两个size,支持23种语言。Aya Vision基于 Aya Expanse大语言模型。
Aya Vision的模型架构如下图所示
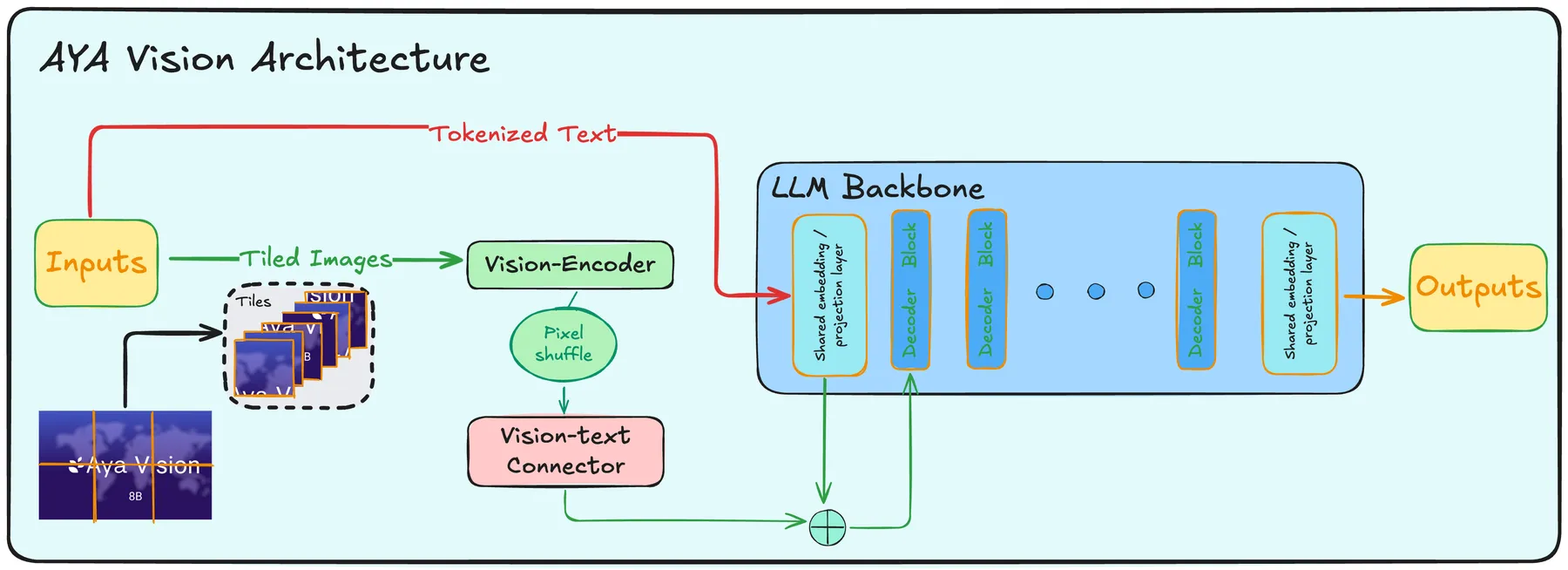
- Vision Encoder: SigLip2-patch14-384
- Vision-text connector: 2 layer MLP
- LLM: Aya Expanse 8B/ 32B
训练
训练包含两个stage:
- Vision-language alignment: 仅训练vision-text connector,基于image-text pairs进行训练
- SFT:训练connector和LLM,基于合成的多语种数据进行训练
Model merging
最后为了提高模型在纯文本任务上的表现,作者还使用了model merging的技巧。具体做法就是merge使用的base language model和SFT之后的vision-language model
AFM
Apple 在 7 月份发布了 AFM 技术报告,包括两个多语种多模态大模型,分别为 3B 和 xB, 一个面向 device, 另一个面向 server, 前者主要集中于效率,后者集中于表现。
Architecture
On-Device Model
对于 on-device model, 作者将模型分为两个 block, Block1 占 的 transformer layers, Block2 占 的 transformer layers. 但是,对于 Block2, 作者移除了 key, value projection, 对应的 KV cache 则直接从 Block1 中获取。通过这种方式,作者将 KV cache memory usage 减少了 . 并且,由于 Block2 不产生任何 key values, prefill stage 可以跳过这些计算,这样 TTFT 也可以减少 .
Server Model
对于 server model, 作者对架构进行了改进,来提高效率。架构如下图所示
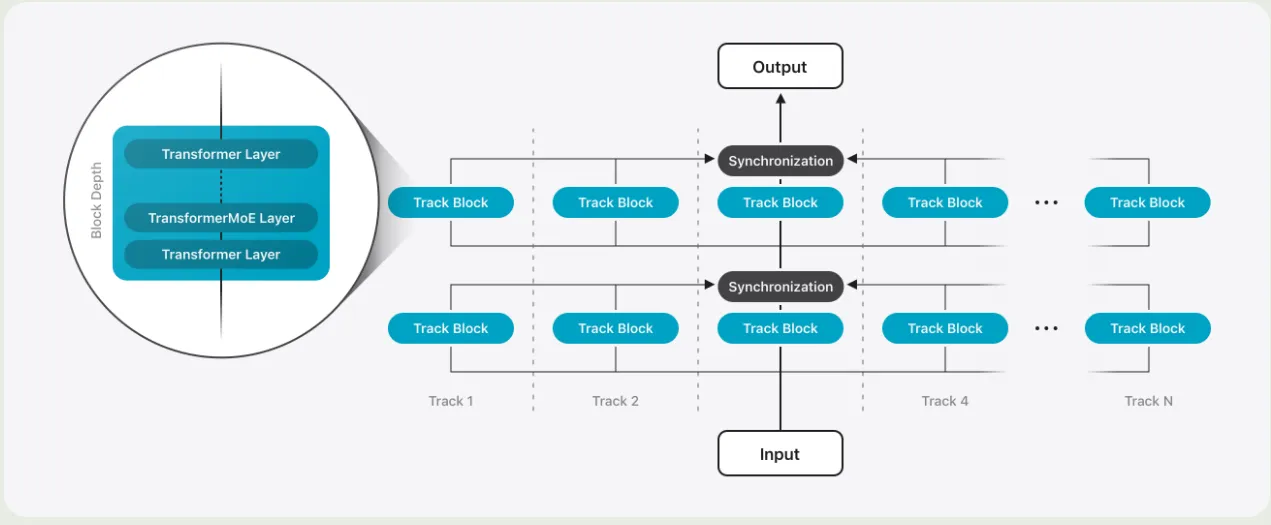
Parallel Track Transformer 作者提出了 Parallel Track (PT) Transformer 架构,PT-Transformer 将 transformer 模型分割多个小的 transformer, 作者将这些小的 transformer 称之为 track. 每个 track 包含多个 transformer block. 不同的 track 只会在输入和输出的时候进行交互,这样就能够减少同步的开销。作者讲这种模式称为 track parallelism.
PT-MoE 为了进一步提高 server model 的效率,作者将 MoE 和 PT-transformer 结合在一起。具体的做法就是,每两个 transformer block 为一组,每组里包含一个 dense layer 和一个 MoE layer.
Interleaving Global and Local Attention Layers 作者还设计额 interleaved attention 机制,也就是,将 transformer block 按照四个为 1 组,前面 3 个 block 使用 window attention, window size 为 4096 和 RoPE. 最后一个 block 使用 global attention layer 以及 NoPE. 作者认为,使用 NoPE 可以提高模型对长上下文的泛化性。
Recall Qwen2.5-VL 的 ViT 使用的类似的做法,即 8 个 block 为一组,前面 7 个 block 使用 window attention, 最后一个 block 使用 full self attention.
Vision Encoder
Vision encoder 包含 ViT 和 adapter 两个模块
对于 ViT 来说,作者使用了 ViT 架构:
- server model 使用了 1B 参数的 ViT-g
- on-device model 使用了 300M 参数的 ViTDet-L backbone
作者在 ViTDet 的基础上加入了 Register-Window 机制,这个机制用于编码一个 global register token 来与不同的 loca windows 进行交互。
对于 adapter 来说,其包含了一个 transformer layer, 一个 linear projection layer, 一个 的 convolutional layer. 其中, linear projection 用于将 visual token 映射到 LLM 的特征空间,pooling layer 用于压缩 visual token 个数。
Data
主要包括 web data 和 image data 两部分
image data 部分:
- Image-Text Crawl Data: 包含 175M 图文交错数据,包含 550M images
- Synthetic Image Caption data: 5B image caption 数据
- Text-Rich Image Data
- High-quality Domain-Specific Image-text Data: 包括 caption 数据, grounding 数据,table, chart, plots 数据以及 knowledge-required domains 的数据
Training Recipe
text tokenizer 大小为 150K.
Vision encoder 的训练包含两个 stage:
- 基于 CLIP 的方法,使用 6B的 image-text pair 数据进行训练,图片精度为 448, 作者还使用了 FLIP 来提高训练效率
- 使用一个 compact LLM, 同时训练 vsion encoder, adapter 和 compact LLM. 加入了更高质量的数据,图片精度为 672.
LLM 的训练使用了 13.4T token
Post-training
SFT
SFT 数据包括:
- General knowledge
- Reasoning: 纯文本包括 math 和 reasoning, 多模态包括 STEM, math, CoT 数据
- Text-Rich Image understanding: chart, table 数据
- Multilingual OCR: OCR 相关数据
- Text and visual grounding: grounding 数据
- Multi-image reasoning: 多图推理数据
作者还基于 retrieval-based 方法来收集数据,具体做法就是给定一些 prompt, 然后通过一个 Image search pipeline 来进行检索。
训练的时候,作者将图片精度从 672 提升到 1344, 处理方式就是将图片切分为四个子图,然后作者还加入了一个总蓝图。这样,vision encoder 的输入包括四个子图和一个 thumbnail 图.
为了提高 on-device model 的效率,作者设置了三种模式:
- rapid mode: 图片精度为 224
- balanced mode: 只有 thumbnail 图
- high-resolution mode: 四个子图和一个 thumbnail 图
对于不同的 mode, 如果输入的是低精度图片,则 概率为 rapid mode; 如果输入的是高精度图片,则 的概率为 rapid mode. 对于其他数据,作者将 的数据设置为 balanced mode.
RLHF
作者使用 RLOO 作为 RLHF 的算法。
RL 的 infra 如下图所示
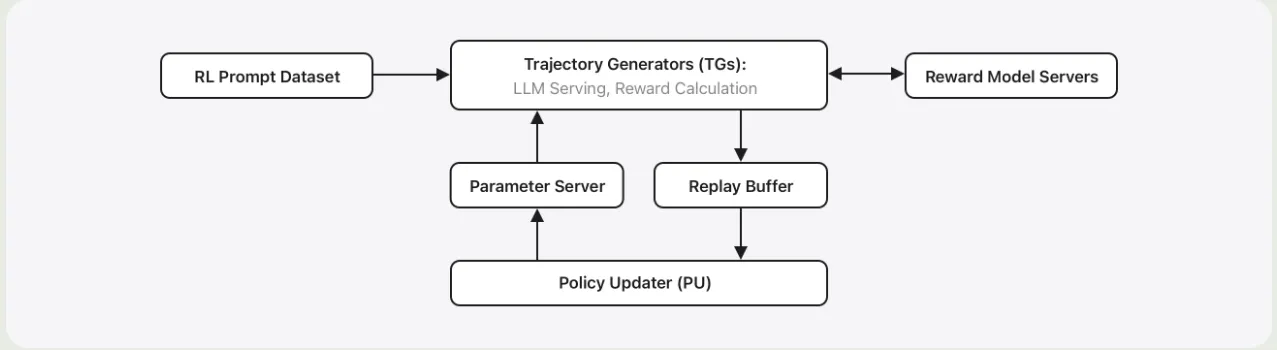
infra 主要由两个部分组成:
- Trajectory Generators: 生成轨迹并提供反馈
- Policy updater: 更新 policy
训练时,作者首先训练了一个 reward model, 与 AFM-2024 相似,作者使用了一个 preference loss function 以及一个 single-sided grading 作为 regularization.
数据包括以下类别:
- text-only prompts
- Image-text prompts
- Math prompts
- Image-text STEM reasoning prompts
其中,前面两个使用 reward function 进行打分,后面两个基于 ruled-based verifier 进行打分
作者还发现,人类的打分和 reward model 的发奋可能会出现 的偏差。为了解决这个问题,作者训练了一个单独的 reward model, 专门用于 prompt selection.
Tool Use
工具调用数据由于 Multi-turn 和依赖软件工具,比较难以收集。为了解决这个问题,作者设计了一个交互式标注平台,包括一个 agent 和一个工具执行环境。环境包括了工具和数据库,能执行工具调用并反馈。
标注时,用户发起一个请求,然后 agent 自动执行工具调用,最后平台返回反正的轨迹。
Multilingual
作者逐步增加模型对于新语言的理解能力。默认情形下,输入和输出的语种一致,但是包含 的跨语种数据。在 SFT 和 RLHF 阶段,英语和多语种数据的比例为 .
Optimization
作者使用了 QAT 来将 on-device model 压缩到 2 bits-per-weight, 使用 Adaptive Scalable Texture Compression (ASTC) 来 post-training 3.56 bits-per-weight 版本的 server model.
QAT
QAT 是一个在模型训练过程中模拟量化误差,从而提升模型量化后表现的方法。它解决了传统后量化方法精度损失较大的问题,是平衡模型性能用户效率的关键手段。
训练时,作者通过修改权重 来模仿量化:
其中, 是 scaling factor, 是 zero point, , 是 quantization 的 range. 为了解决 rounding operation 不可微的问题,作者使用了 straight-through estimator 的方法来近似梯度。
作者还提出了一个可学习的 scaling factor 用于计算 quantization scale, 计算方法如下所示
作者通过精细设计 的初始化来保证模型训练的 robust.
ASTC
对于 server model, 作者使用了 ASTC, 一个针对 GPU 图形纹理压缩的技术,来压缩模型权重。具体做法就是,模型训练好之后,作者对模型权重应用 ASTC, 然后对每个块进行预处理。存储时,每个块用 ASTC-HAR-ch 模式压缩为 128 位。最小值单独存储为 float16.
推理时,GPU 硬件自动解压缩 ASTC 块,然后解压的权重最小值相加参与矩阵计算
Quality Recovery Adapters
作者还是用 LoRA 来恢复量化模型的精度,并通过选择性压缩策略优化 ASTC 过程,在极小的算力开销下实现了接近全量微调的性能。
Evaluation
On-device model 表现如下
| Model | MMLU | MMMLU | MGSM |
|---|---|---|---|
| AFM On-Device | 67.85 | 60.60 | 74.91 |
| Qwen-2.5-3B | 66.37 | 56.53 | 64.80 |
| Qwen-3-4B | 75.10 | 66.52 | 82.97 |
| Gemma-3-4B | 62.81 | 56.71 | 74.74 |
| Gemma-3n-E4B | 57.84 | 50.93 | 77.77 |
server model 表现如下
| Model | MMLU | MMMLU | MGSM |
|---|---|---|---|
| AFM Server | 80.20 | 74.60 | 87.09 |
| LLaMA 4 Scout | 84.88 | 80.24 | 90.34 |
| Qwen-3-235B | 87.52 | 82.95 | 92.00 |
| GPT-4o | 85.70 | 84.00 | 90.30 |
Ovis
作者分析了已有多模态大模型的架构,已有多模态大模型的输入对于文本来说是离散的 (text token), 对于图片来说是连续的 (visual embedding)。 作者认为这种连续 - 离散的输入可能会影响模型最终的表现。
为了解决这个问题,作者构建了一个 visual embedding table, 将 visual embedding 也转换成离散的 token 表示形式,进而统一 LLM 输出的粒度。
模型的架构如下图所示
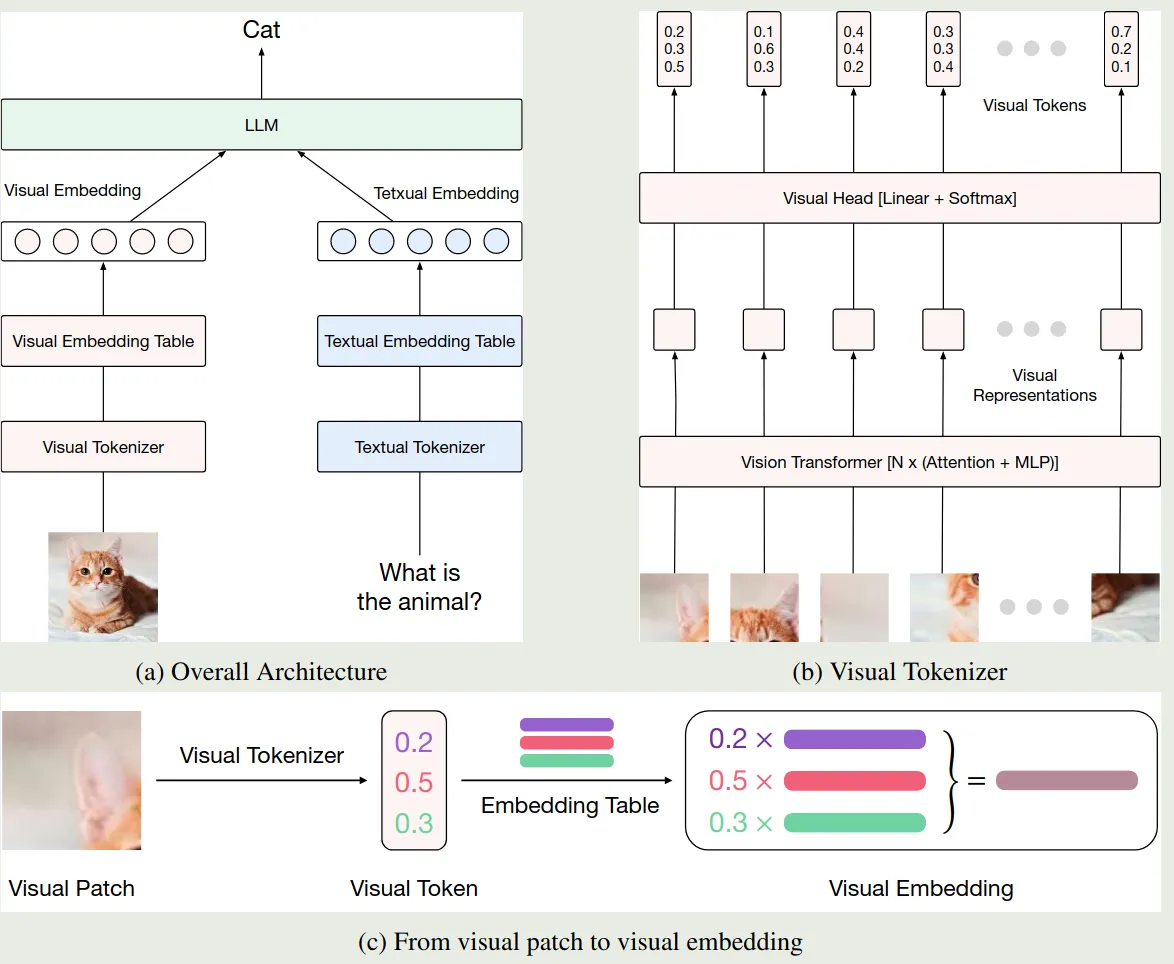
我们首先会构建一个 visual vocabulary , 其大小为 , 然后对于 ViT 输出的 个 visual feature , 我们会加入一个 linear head 以及一个 softmax 来构建一个 vocabulary 上的分布,即
这里 是 visual vocabulary 上的概率分布。最终,视觉模块的输入是 vocabulary 中 visual token 的一个加权求和
训练分为三个阶段:
- Stage 1: 训练 , visual encoder 最后一个 block 以及 visual vocabulary
- Stage 2: 训练 , visual vocabulary 以及 visual encoder
- Stage 3: multimodal SFT, 提高模型的指令跟随能力,模型所有参数都参与训练
训练数据分布如下表所示
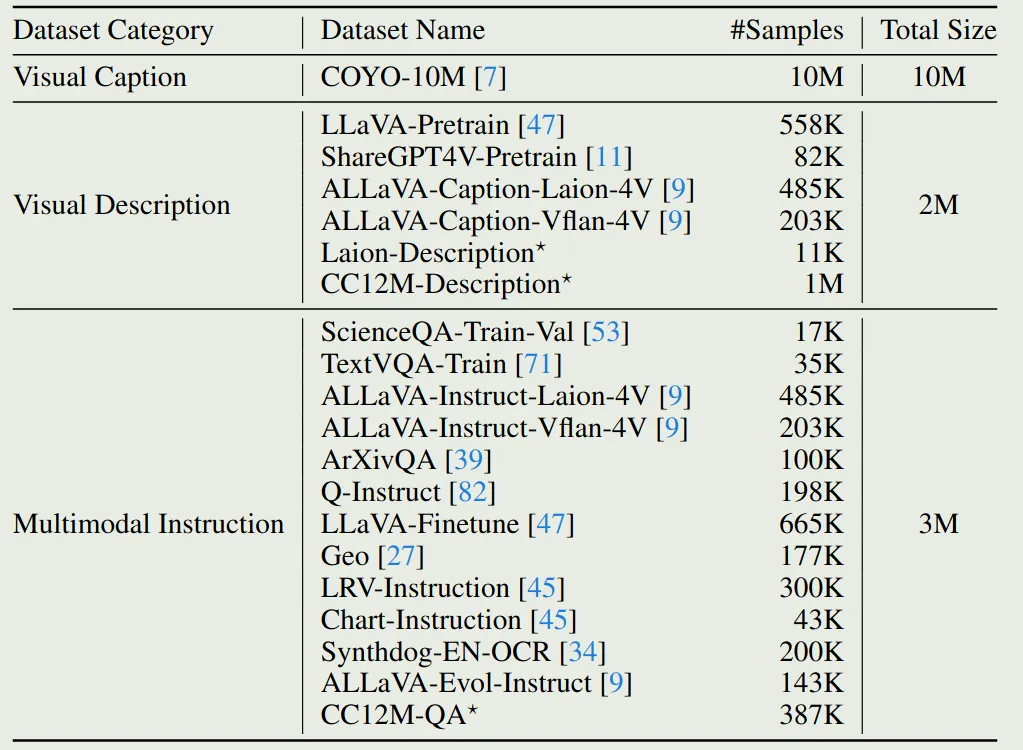
Ovis2.5
一个基于 Ovis 改进的多模态大模型系列,包括 2B 和 9B 两个 size,Ovis2.5 主要强调了支持不同分辨率图片输入以及深度思考这两个 feature
作者首先回顾了 Ovis, Ovis 主要是解决 text embedding 以及 visual embedding 对齐程度比较低的问题。
接下来,作者介绍了以下 Ovis 的两个问题:
- 只能支持固定大小的图片输入
- 缺乏深度思考能力
为了解决这两个问题,作者提出了 Ovis 2.5, Ovis 主要做出了两点改进:
- 使用了 NaViT 来处理不同分辨率图片的输入
- 作者通过训练提高了模型的深度思考能力
最终 Ovis2.5 主要有以下 feature
- 支持动态分辨率图片输入
- 深度思考能力
- SOTA 的表现
- 高效的训练方式
Architecture
Ovis2.5 的架构如下所示
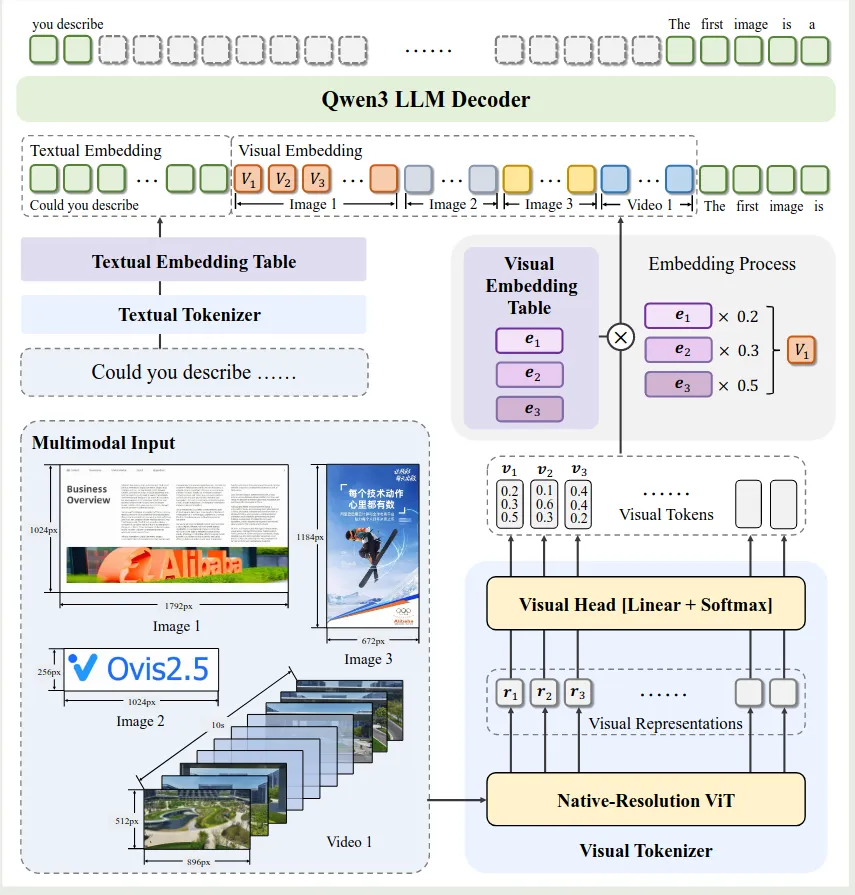
Ovis 包括三个模块:
- visual tokenizer: ViT 架构,
- visual embedding table: 类似 LLM 中的 text embedding table, 见 Ovis
- LLM: 基于 Qwen3
作者在架构上进行了如下改进:
- 动态分辨率图片输入处理:作者使用了 NaViT 来支持动态分辨率图片输入
- LLM: 作者使用了 Qwen3 来进一步提高模型的表现
Training
模型训练包括 pre-training 和 post-training 两个大的 stage, 其中 pre-training 又包含 3 个小的 stage, post-training 包含 2 个 stage. 训练过程如下所示

pre-training 阶段的数据包括 COYO, Laion, Wukong, DataComp, SAM 等。作者介绍了几个部分的数据:
- OCR 数据,作者基于 MLLM 来标注数据和合成 QA
- Grounding 数据,作者使用了 RefCoCo 等数据集以及先进的 MLLM 来标注数据
- Reasoning 数据,作者收集了数据然后使用 MLLM 来合成 Reasoning path
训练时,
- VET pretraining: 训练 VET, 作者基于 SigLIP 来初始模型的参数,然后仅训练最后一层 ViT layer, visual head 以及 VET, 图片精度为 448-896. 作者采用了动态 position embedding
- Multimodal pretraining: 这阶段全量微调所有参数,主要目的是使用对话格式的数据。图片精度为 448-1792
- multimodal instruction tuning: 这阶段训练所有参数,主要提高模型跟随多模态指令的能力
post-training 包括 DPO 和 GRPO 两个阶段。
- DPO: 训练所有参数,使用 pre-training checkpoint 来多次采样
- GRPO: 使用 RLVR 数据集进行训练
作者提出了几个未来的方向:
- 将输入图片精度提升到 4K
- 处理长视频输入并进行 temporal reasoning
- 在 Reasoning 过程中加入 tool-use.
Data mixture
SFT data mixture:
- general VQA
- document understanding: OCR, chart, knowledge
- Reasoning
- multi-image
- video
- pure text
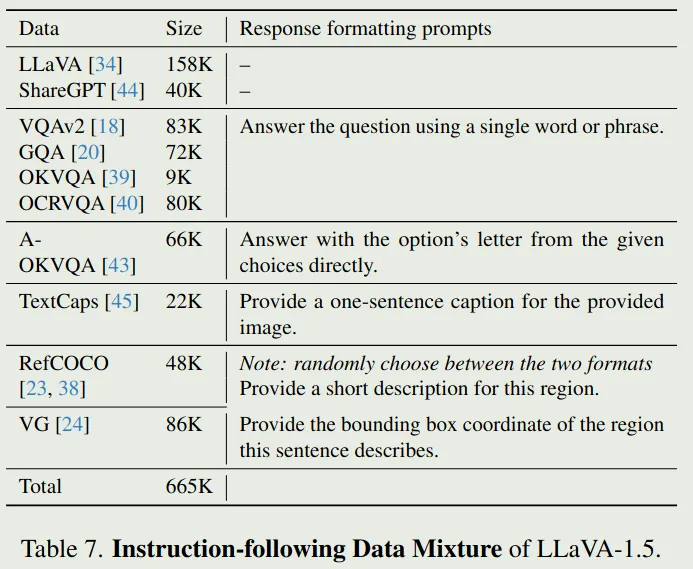
LLaVA
LLaVA 1.5 SFT数据配比如下:
LLaVA-OneVision
LLaVA OneVision 的数据集统计在表16里,这里总结一下数据配比(总量为3.15M)
| Category | Ratio |
|---|---|
| general vqa | 36.1 |
| Doc/Chart/Screen | 20.6 |
| Math/Reasoning | 20.1 |
| general OCR | 8.9 |
| text only | 14.3 |
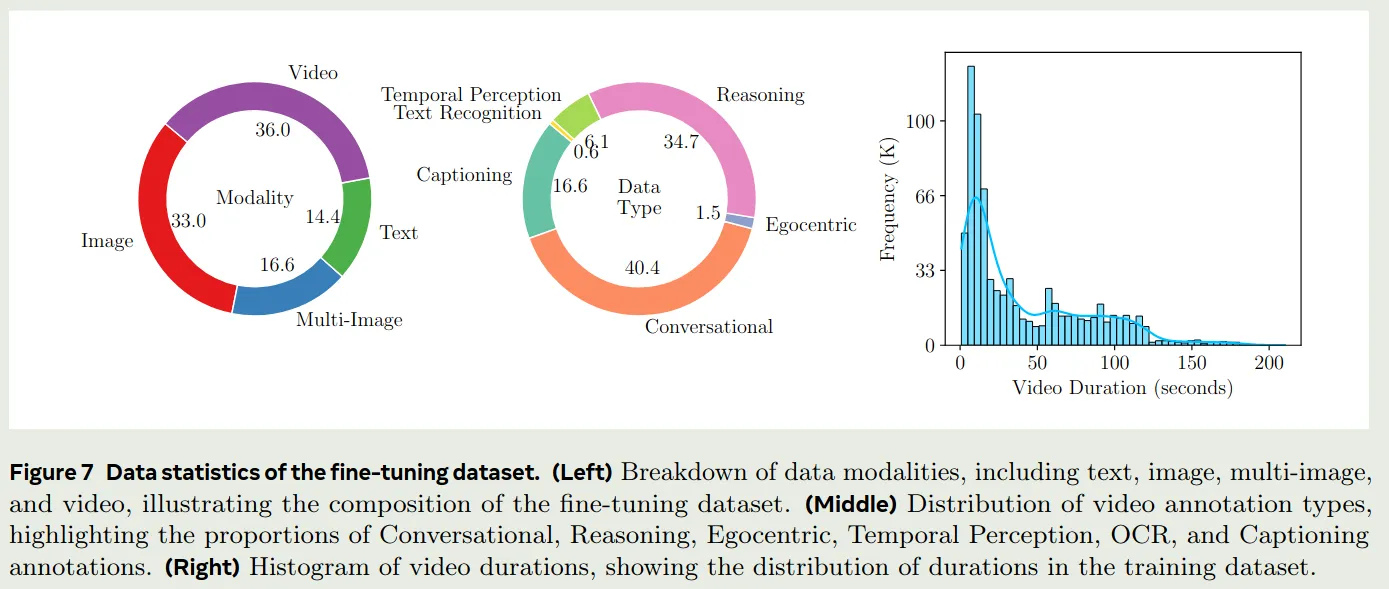
Apollo
Apollo 是Meta发布的一个视频理解多模态大模型,其数据集没有开源,论文中给出了其训练数据配比
Cambiran-1
Cambiran-1 是纽约大学提出了一个多模态大模型系列,论文发表在了 NeurIPS 2024(Oral) 上,作者给出了 Cambrain-10M 和 Cambrain-7M 两个数据集,Cambrain-7M 的数据分布如下

Idefics
Idefics系列(1/2/3)是huggingface提出的视觉多模态大模型系列,在 Idefics2 中,作者构建了The Cauldron数据集,其数据配比在表14里面。总结如下:
| Category | Ratio |
|---|---|
| general vqa | 11.02 |
| captioning | 5.14 |
| OCR | 17.47 |
| chart/figures | 14.05 |
| table | 11.3 |
| reasoning | 10.32 |
| textbook | 1.58 |
| difference | 2.38 |
| screenshot2code | 0.31 |
| text only | 26.41 |
在 Idefics3 中,作者基于The Cauldron进行了扩展,最终数据集的比例如下:
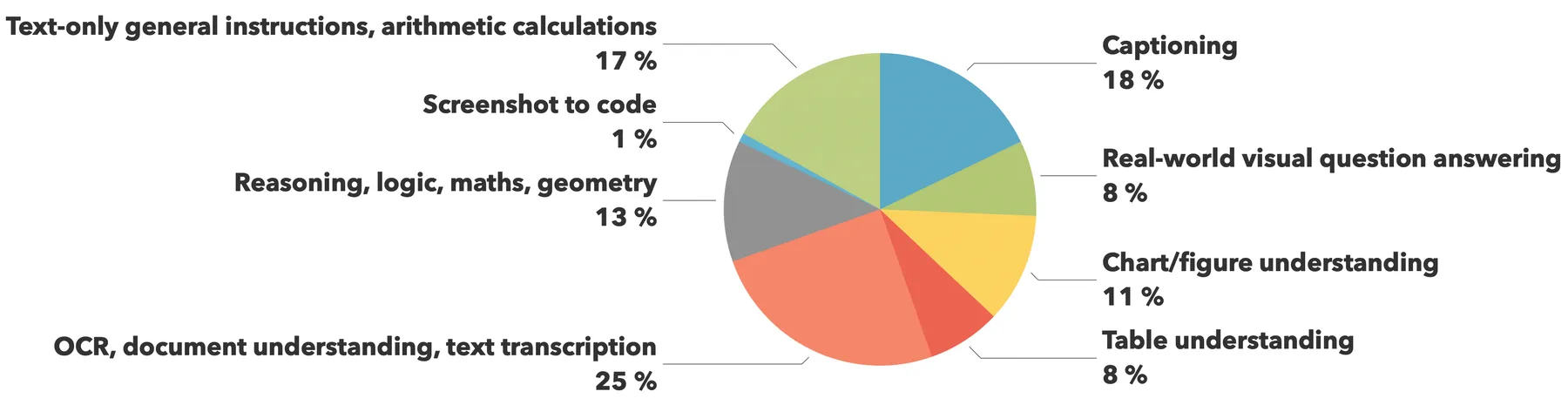
Molmo
Molmo 是Allen AI发布的一个多模态大模型,其SFT数据配比如下
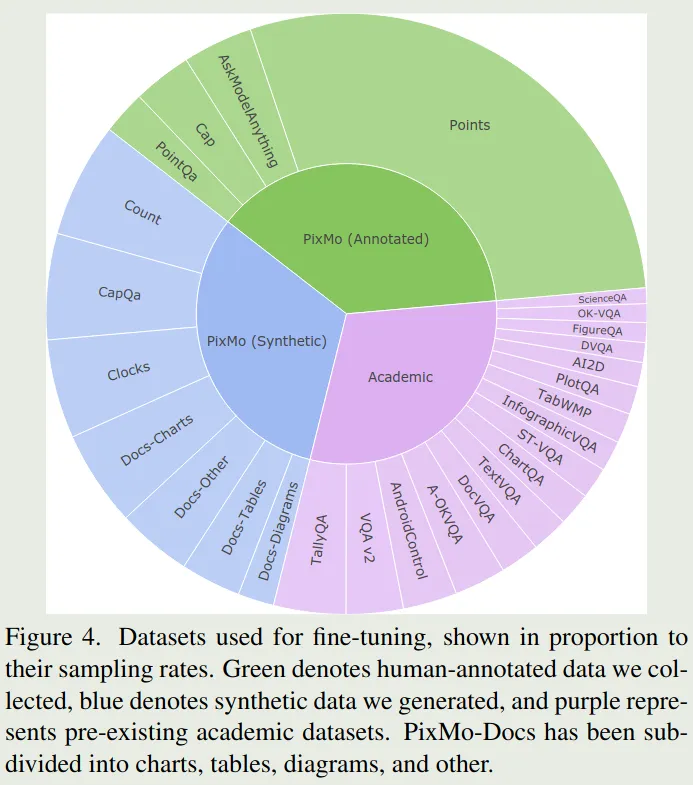
Eagle 2/2.5
Eagle (1/2/2.5) 是NVLab提出了系列多模态大模型,Eagle 2 给出了 stage 1.5 和 stage 2的数据配比
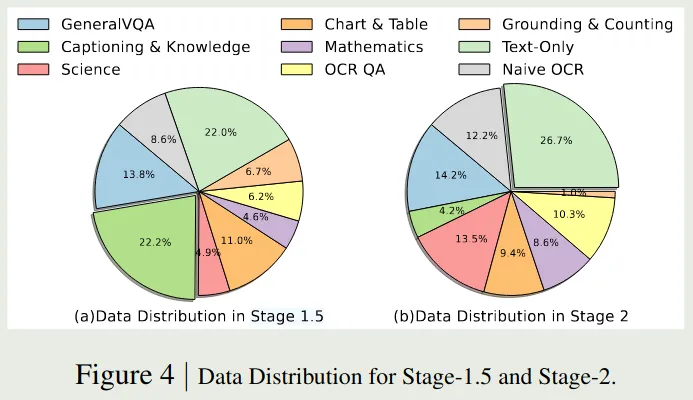
Eagle 2.5 在 Eagle 2的基础上加入了一些 long context 数据,其数据列表在表11里
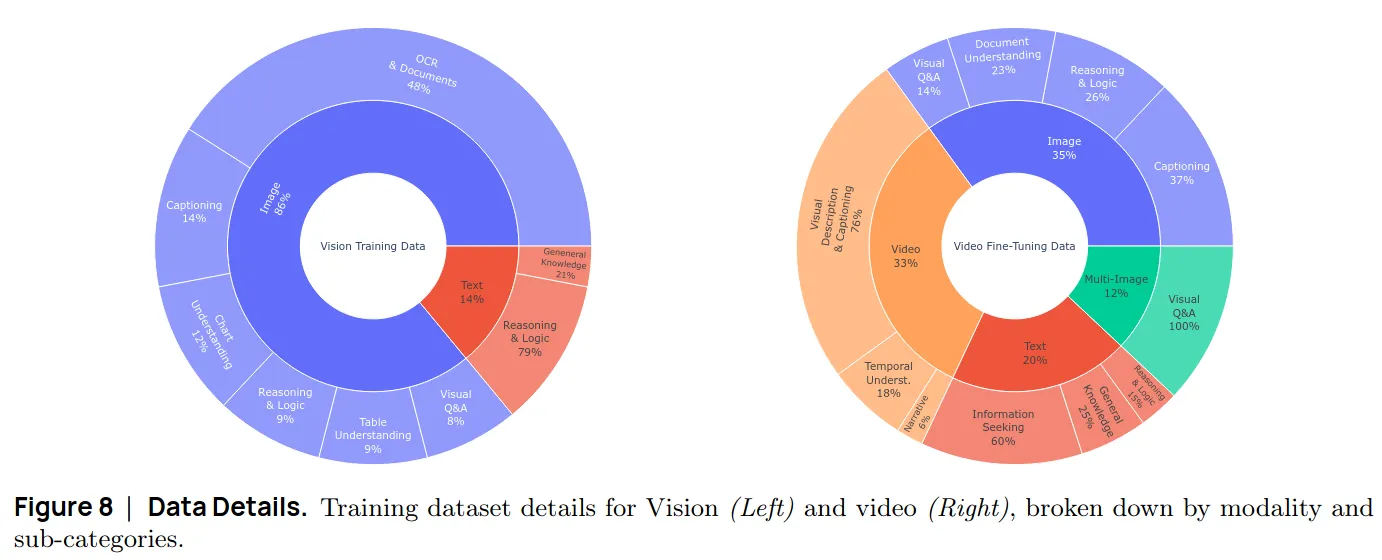
SmolVLM
SmolVLM 是huggingface开发的一款轻量化视觉多模态大模型,论文中的数据配比如下:
MM1/1.5
MM1 通过实验确定了训练数据的配比:
| Category | Ratio |
|---|---|
| interleaved image-text | 45 |
| imagetext | 45 |
| text only | 10 |
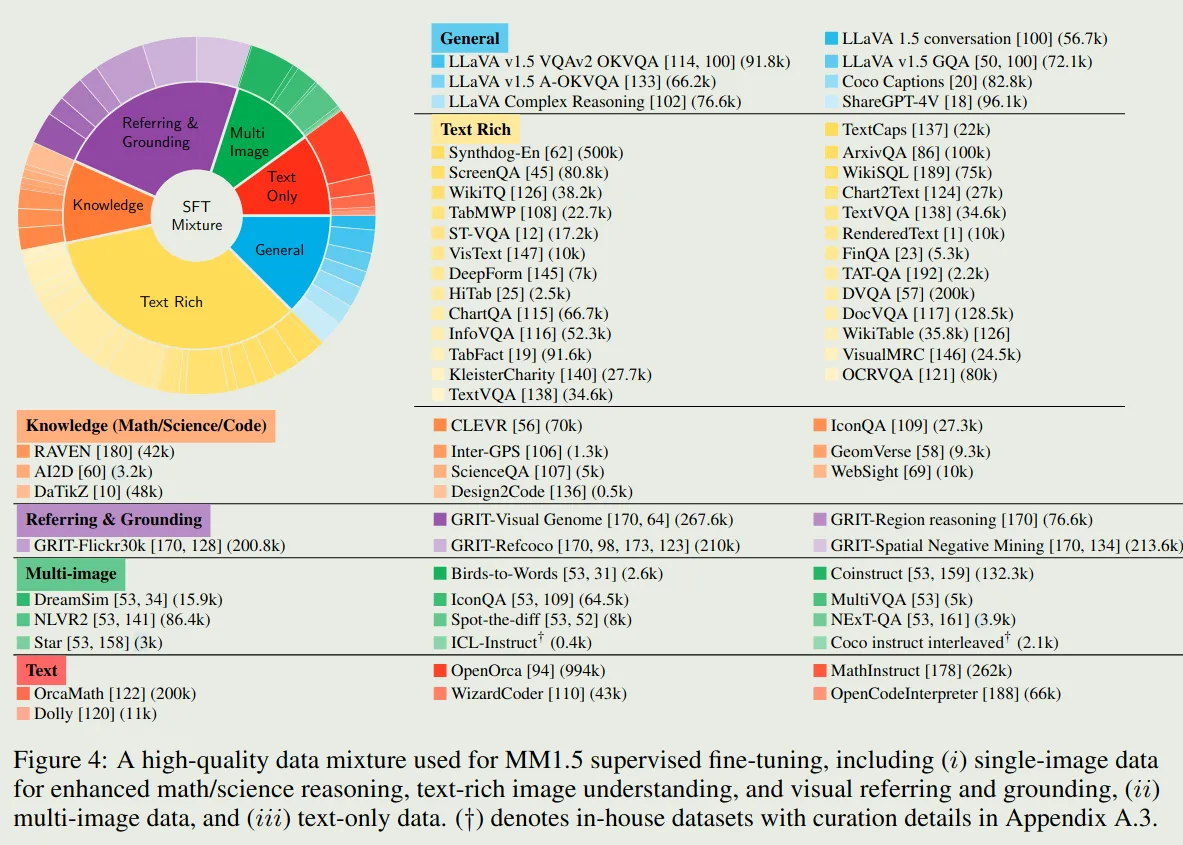
MM1.5 的SFT数据配比如下:
InternVL
InternVL2.5 在论文里总结了其使用的pretraining数据和SFT数据,但是没有具体的数据配比,请参考论文的表4和表5
SFT数据配比
| Category | Ratio |
|---|---|
| single-image | 45.92% |
| multi-image | 9.37% |
| video | 39.79% |
| pure-text | 4.92% |
MiniCPM V
MiniCPM V 是 OpenBMB发布的轻量化多模态大模型,其在表1和表2列出了ptraining和SFT数据的具体量级和类别。
Flash-VL
| Category | Ratio |
|---|---|
| Special Enhancement | 4% |
| Text | 21% |
| Caption | 4% |
| Chart | 16% |
| Math | 11% |
| OCR | 3% |
| Code | 8% |
| General | 33% |
Keye-VL 1.5
训练时数据分布为 video:images
=24:50:26.Phi-4
训练数据配比
| Domain | ratio |
|---|---|
| Text | 11.04 |
| Caption | 5.39 |
| VQA | 20.37 |
| OCR | 1.61 |
| Detection | 7.9 |
| Perception | 1.1 |
| Math & Science | 18.66 |
| alignment | 0.5 |
| Web | 15.19 |
| Grounding | 18.24 |
具体数据参见原论文
- LLaVA 1.5
- LLaVA OneVision
- Apollo
- Cambiran-1
- Idefics2
- Idefics3
- Molmo
- Eagle 2
- Eagle 2.5
- SmolVLM
- MM1
- MM1.5
- InternVL2.5
- MiniCPM V
Projection Layer
- QFormer: Qwen-VL, BLIP
- percever resampler: FLAMINGO
- MLP + patch merger/pixel shuffle: 大多数
- linear layer: smol-vl
layer types
Q-former
MLP
Linear Layer
Patch Merger
DeepStack
已有的 MLLM 将视觉 token 作为一个 1d sequence, 输入给 LLM. 在本文中,DeepStack (Meng et al., 2024) 将 visual token 注入到 LLM 的不同 layer 中来提高视觉信息的利用率
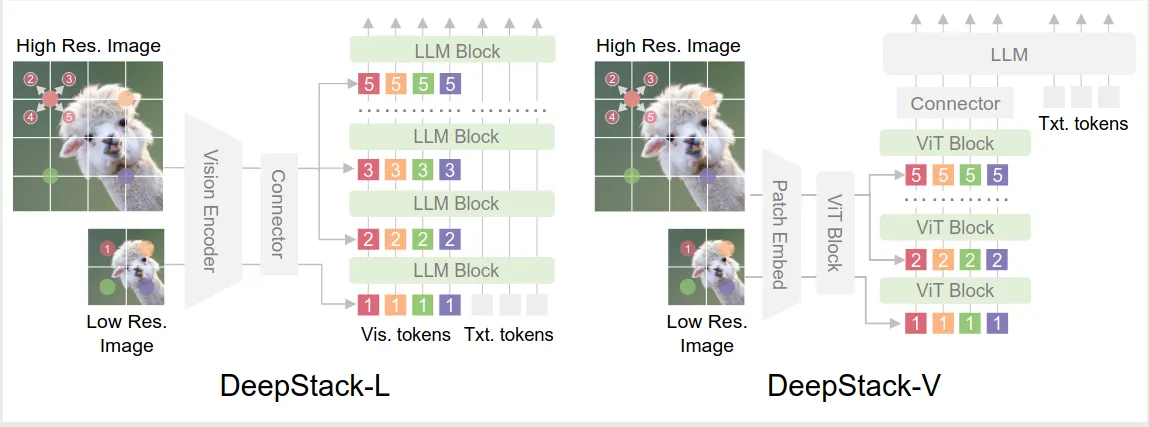
首先,对于输入的图片 , 我们将其分为高精度图片版本 和低精度图片版本 , 通过 vision encoder 和 MLP 得到对应的视觉 token 作为 LLM 的输入,然后在 LLM transformer block 的第 层,其对应的视觉 token 会与 stack feature 相加,这里 是对高精度图片输入的一个采样,即
算法伪代码如下所示
# H0: Input embeddings for LLM (Original inputs args for traditional LMM); # vis_pos: the location of visual tokens;
# X, Xstack: Original visual tokens, Extra high-resolution visual token list;
# lstart, n: Index of starting layer, and layer interval for stacking.
def forward(H0, Xstack, lstart, n, vis_pos):
H = H0
for (idx, TransformerLayer) in enumerate(self.layers):
# DeepStack:
if idx >= lstart & (idx − lstart) % n == 0:
H[vis_pos] += Xstack[(idx − lstart)//n]
# Original Transformer:
H = TransformerLayer(H)
作者进一步验证了不同实验配置,结果发现在 early layer 进行 deepstack 效果最好,越往后效果越差
作者还在 ViT 上应用了 DeepStack 策略,结果发现 ViT 的效果也有所提升
作者还发现,模型表现提升是因为加入了 high-reoslution image token 信息
Token Compression
为了防止 token 数量过多,通常在经过 projection layer 之前,会接入 pixel shuffle 或 perceiver resampler 层,来减少视觉 token 数量
Perceiver Resampler
Pixel Shuffle
- Meng, L., Yang, J., Tian, R., Dai, X., Wu, Z., Gao, J., & Jiang, Y.-G. (2024). DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs. The Thirty-Eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=fXDpDzHTDV