Overview
在这篇 blog 中,我们将回顾 Qwen 系列的发展以及关键技术改进。
Qwen-LLM
Qwen 在 23 年 9 月份发布了 Qwen 系列大语言模型,包括 1.8B, 7B,14B 三个 size,训练过程使用了 3T token. 作者还基于 Qwen,构建了 Code-Qwen-Chat,Math-Qwen-Chat 等系列领域大语言模型。
Pre-training
Data
数据一共使用了 3T token,主要是 public web documents, encyclopedia, books, codes, etc,覆盖了中文和英文两种语言
数据处理:
- 语言识别
- 去重,包括 MinHash 和 LSH 算法
- 质量过滤,包括基于规则和和基于 ML 的方法
- 上采样,特定数据会进行上采样
- 加入指令数据,提高模型的 zero-shot 和 few-shot 表现
Tokenization
BPE tokenizer,最终的 tokenizer 大小为 152K
Architecture
模型架构基于 LLaMA, 改动:
- tie embdding: input embdding 和 output embdding 使用的权重相同
- position encoding, inverse frequency 的精度为 FP32
- bias: 取消了大部分的 bias,增加了 QKV bias,来提高模型的外推能力
- Pre-Norm & RMSNorm
- Activation function: SwiGLU
Training
- 上下文长度:2048
- attention:flash attention (Dao et al., 2022)
- optimizer:AdamW, , , .
- data type: BF16
Context Extention
使用了三个技巧:
- NTK-aware position interpolation
- log-N scaling
- window attention
后续前两个统一成了 YARN.
observation: lower layer 对上下文长度扩展更敏感, 因此作者动态调整了 window size
Post-training
包括 SFT 和 RLHF 两个阶段
SFT
data: 使用了 ChatML 格式
RLHF
PPO 算法
reward model 构建:基于 Qwen-base model
RL 训练:先更新 value model 50 steps
发现:top-p 设置为 0.9 比设置为 1.0 更好
Tool-use and Agent
作者使用了 self-instruct 来进行 SFT,基于 ReAct 构建数据,数据包括 2000 条高质量数据
Specialization
Code-Qwen
code-qwen 基于 qwen continue Pretraining 得到,然后基于 code-qwen 进行 sft 得到 code-qwen-chat,包括 7B 和 14B 两个 size
Math-Qwen
基于 qwen 直接 SFT 得到,包括 7B 和 14B 两个 size
- Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Re, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In A. H. Oh, A. Agarwal, D. Belgrave, & K. Cho (Eds.), Advances in Neural Information Processing Systems. https://openreview.net/forum?id=H4DqfPSibmx
Qwen1.5
Qwen 在 24 年 1 月份发布了 Qwen1.5,包含 0.5B, 1.8B, 4B, 7B, 14B, 32B, 72B, 以及 110B 6 个 size,还有一个 MoE 模型。
Qwen1.5 的主要特点:
- 支持 12 中语言
- 统一支持 32768 tokens 上下文长度 。
- 提供 量化版本 (Int4、Int8、AWQ、GGUF)以适应低资源环境或部署需求。
训练过程使用了 DPO 以及 PPO 来进行对齐
Qwen1.5-MoE
Qwen1.5-MoE 的激活参数为 2.7B,一共包含 64 个专家,其中激活 4 个专家,共享 4 个专家
相比于 Qwen1.5-7B,去训练的 FLOPS 降低了 75%,inference 的速度提高了 174%
Qwen1.5-MoE 采用了改进的 MoE 架构,主要优化包括:
- 细粒度专家(Fine-grained experts) :通过将 FFN 层划分为多个片段,构建更多专家而不增加参数总量。
- 初始化策略(Upcycling) :基于 Qwen-1.8B 初始化模型,并引入随机性以加速收敛。
- 路由机制(Routing Mechanism) :在每个 MoE 层中使用 64 个专家,其中 4 个共享专家始终激活,60 个路由专家中有 4 个被激活,提高了灵活性和效率。
效率对比
作者对比了 throughput (requests processed per second) 以及 tokens per second (TPS):
| Model | Throughput | TPS |
|---|---|---|
| Qwen1.5-7B-Chat | 1.15 | 2298.89 |
| Qwen1.5-MoE-A2.7B-Chat | 2.01 | 4010.27 |
Qwen2
2024 年 9 月 Qwen 发布了 Qwen2 [Qwen2] 系列技术报告,Qwen2 系列包括 4 个 dense 模型(0.5B, 1.5B, 7B, 72B)和一个 MoE 模型(总参数 57B,激活参数 14B),作者主要在架构,数据和长上下文上进行了改进。
Architecture
对于 dense 模型,Qwen2 在 Qwen-LLM 的基础上做了如下改动:
- 使用 Group Query Attention (GQA) 替换 MHA,来优化 KV cache,提高 throughput
- 使用 Dual Chunk Attention 和 YARN 来提高模型上下文长度和训练效率
其余与 Qwen 一致,包括 SwiGLU,RoPE,RMSNorm 和 pre-normalization
对于 MoE 模型,Qwen2-MoE 基于 Qwen1.5 进行了改进,主要是 3 点:
- 作者使用了更细粒度的专家个数,作者认为细粒度的专家可以提供更丰富的 combination,这一点与 olmoe 的结论相同
- 与 DeepSeek-MoE 一样,作者使用了共享专家和路由专家
- 作者使用了类似 upcycling 的方法来初始化模型。假设一共有 个专家,每个专家的维度为 , 原始 dense 模型的维度为 , 那么我们会把 dense 模型的参数复制 次,这样就可以扩展到任意个数的 MoE 模型上。作者还对参数进行 shuffle,来提高 diversity。最后,作者还对 50% 的参数进行随机初始化,来提高模型的 capacity。
模型配置如下
| Configuration | 0.5B | 1.5B | 7B | 72B | 57B-A14B |
|---|---|---|---|---|---|
| Hidden Size | 896 | 1,536 | 3,584 | 8,192 | 3,584 |
| # Layers | 24 | 28 | 28 | 80 | 28 |
| # Query Heads | 14 | 12 | 28 | 64 | 28 |
| # KV Heads | 2 | 2 | 4 | 8 | 4 |
| Head Size | 64 | 128 | 128 | 128 | 128 |
| Intermediate Size | 4,864 | 8,960 | 18,944 | 29,568 | 2,560 |
| # Routed Experts | - | - | - | - | 64 |
| # Activated Experts | - | - | - | - | 8 |
| # Shared Experts | - | - | - | - | 8 |
| Embedding Tying | True | True | False | False | False |
| Vocabulary Size | 151,646 | 151,646 | 151,646 | 151,646 | 151,646 |
| # Trained Tokens | 12T | 7T | 7T | 7T | 4.5T |
Pre-training
预训练阶段的数据基于 Qwen 和 Qwen1.5,数据处理策略如下:
- 使用基于 heuristic 和 model-based 方法来过滤掉低质量的数据
- 加入了 code, math 和 multilingual 的数据
- 平衡了各个类别的数据分布
初始数据包括 12T token,经过过滤得到 7T token。作者发现,使用 12T token 进行训练,模型的表现不如使用 7B token 训练得到的模型效果好。因此除了 0.5B 的模型,其他模型使用的都是 7T 的 token
对于 MoE 模型,作者使用了额外的 4.5T token 来进行预训练。
在训练过程中,作者还加入了 multi-task instruction 数据,来提高模型的上下文学习能力和指令跟随能力。
作者还将 Qwen2 模型系列的上下文长度从 4096 扩展到 32768,扩展过程中作了三个改动:
- 加入了更多高质量的长上下文数据
- 将 RoPE 的 frequency 从 10,000 提升到了 1,000,000
- 使用了 YARN 来扩展上下文长度
- 使用了 Dual Chunk Attention 来优化 attention 的计算
Post-training
post-training 包括 SFT 和 RLHF 两个阶段
数据包括 SFT 数据和 RLHF 使用的偏好数据
数据标注过程有:
- 使用 InsTag 对数据进行打标
- 选取高质量的 instruction
- 构建了一个 self-evolution 策略,来扩展 instruction 数据
- 请人类来标注数据
作者还合成了一些数据,合成数据的过程如下:
- rejection sampling:对 LLM 进行多次采样,然后保留结论正确的数据作为 SFT 数据,以正确和错误的数据对作为偏好数据
- Execution feedback:对于代码任务,使用 Python 来验证答案的正确性
- Data Repurposing:对于写作类任务,以文档为输入,让 LLM 生成对应的 instruction
- Constitutional Feeback:基于预设的 principle 来生成回答
最终,SFT 数据包括 500, 000 条样本
RLHF 的训练包括 offline stage 和 online stage,offline stage 就是用收集到的偏好数据。在 online stage,作者使用 reward model 来给输出的回答进行打分,然后再使用 DPO 进行训练。
与 Qwen 不同,Qwen2 中作者使用了 Online Merging Optimizer 来解决因为 alignment 导致的性能降低
Qwen2.5
Qwen 在 2025 年 1 月提出了 Qwen2.5-1M (Yang et al., 2025),一个拥有 1M 上下文长度的大语言模型系列。包含 7B,14B 两个开源模型以及 API 模型 Qwen2.5-Turbo. 主要改进方法包括长上下文数据合成,渐进式预训练以及多阶段 post-training 等。作者还对 inference 进行了优化,提高了 inference 的效率。
Architecture
架构上,Qwen2.5-1M 与 Qwen2.5 的架构一致,Qwen2.5-1M 包括 7B,14B 两个 size,还包括一个基于 MoE 的 API 模型 Qwen2.5-Turbo,不同的点在于,Qwen2.5-1M 的上下文长度为 1M,最大生成长度为 8K
Pretraining
Data
作者首先从 CC, arxiv, book, code repositories 等 domain 收集了原始数据。但是,作者发现,原始数据的局部相关性强,但是全局相关性弱。因此,作者基于原始数据进行了增广,来提高数据的长上下文依赖关系。具体有三个任务:
- Fill in the middle: FIM 是 openAI 提出来的一个做法,核心思想就是将填空类问题转化为 next-token-prediction 的问题。通过这种方式,作者希望提升模型理解长上下文依赖的能力
- Keyword-based and Position-based retrieval: 基于 keywords 或者 position 来找到对应的 paragraph,这个任务的目的是提高模型识别并连接相关信息的能力
- Paragraph Reordering: 对输入的 paragraphs 进行随机打乱,然后要求模型重新组织段落的关系
Training
作者将训练拆分为了 5 个 stage:
- stage 1 和 stage 2 与 Qwen2.5 的训练过程一致,stage 1 的上下文长度为 4096,stage 2 的上下文长度为 32768, 训练时,作者使用了 ABF 技巧来将 RoPE 的 base frequency 从 10,000 调整到了 1,000,000.
- stage 3, stage 4 和 stage 5 分别将模型的上下文长度扩展到了 65,536 tokens, 131,072 tokens 以及 262,144 tokens, 对应的 RoPE base frequency 分别为 1M, 5M 和 10M. 训练时,作者使用了 75% 的长文本和 25% 的短文本,这样可以保证模型在短文本任务上的表现
最后,作者在评估了一下每个 stage 的表现,结果如下表所示
| Training Length | RULER | ||||||
|---|---|---|---|---|---|---|---|
| Avg. | 4K | 8K | 16K | 32K | 64K | 128K | |
| 32,768 Tokens | 82.3 | 96.8 | 94.7 | 95.9 | 92.2 | 76.4 | 37.6 |
| 65,536 Tokens | 86.8 | 96.5 | 95.5 | 93.6 | 92.5 | 86.7 | 56.0 |
| 131,072 Tokens | 92.5 | 96.5 | 95.9 | 93.0 | 92.6 | 93.0 | 83.8 |
| 262,144 Tokens | 92.7 | 95.6 | 93.8 | 93.1 | 94.1 | 91.9 | 87.6 |
可以看到,随着训练的上下文长度的提升,模型在更长上下文下的能力也有提升,说明模型具有一定的泛化性。
Post-training
Post-training 阶段与 Qwen2.5 一样,也分为了 SFT 和 RL 两个阶段。
在 SFT 阶段,作者从预训练预料中选择了一部分长文档的片段,然后让 Qwen2.5 来生成对应的 query,query 类型包括 summarization, information retrieval, multi-hop QA 等任务。接下来,作者使用 Qwen-Agent 框架基于全文来回答这些问题。最后,作者基于生成的 query,全文,以及模型产生的回答作为训练数据。
SFT 训练时,作者拆分为了两个 stage。 stage 1 作者在 32768 的上下文上进行训练,来提高模型短文本回答能力。第二个阶段,作者混合了 262,144 和 32768 上下文长度的训练数据。
RL 训练时,与 Qwen2.5 不一样的是,作者进使用了 offline RL,也就是 DPO。作者仅在 8192 的上下文长度上面进行训练。作者认为,长上下文的 RL 训练是非常耗时的,并且作者发现,短文本上进行 RL 的训练之后,模型在长文本上的表现也能得到提升。结果如下表所示
| Model | Before RL | After RL |
|---|---|---|
| Qwen2.5-7B-Instruct-1M | 7.32 | 8.08 (+0.75) |
| Qwen2.5-14B-Instruct-1M | 8.56 | 8.76 (+0.20) |
| Qwen2.5-Turbo | 7.60 | 8.34 (+0.74) |
Inference
前面是训练部分的优化,主要是提升模型的上下文能力。接下来,作者详细介绍了如何在 Inference 阶段提升整体的推理效率和减少内存占用。
Length Extrapolation
与 Qwen2.5 一样,Qwen2.5-1M 也是用了 Dual Chunk Attention 和 YARN 来在推理阶段扩展模型的上下文长度,作者做了如下实验,来对比 Qwen2.5, Qwen2.5-1M 加上 DCA 之后的影响
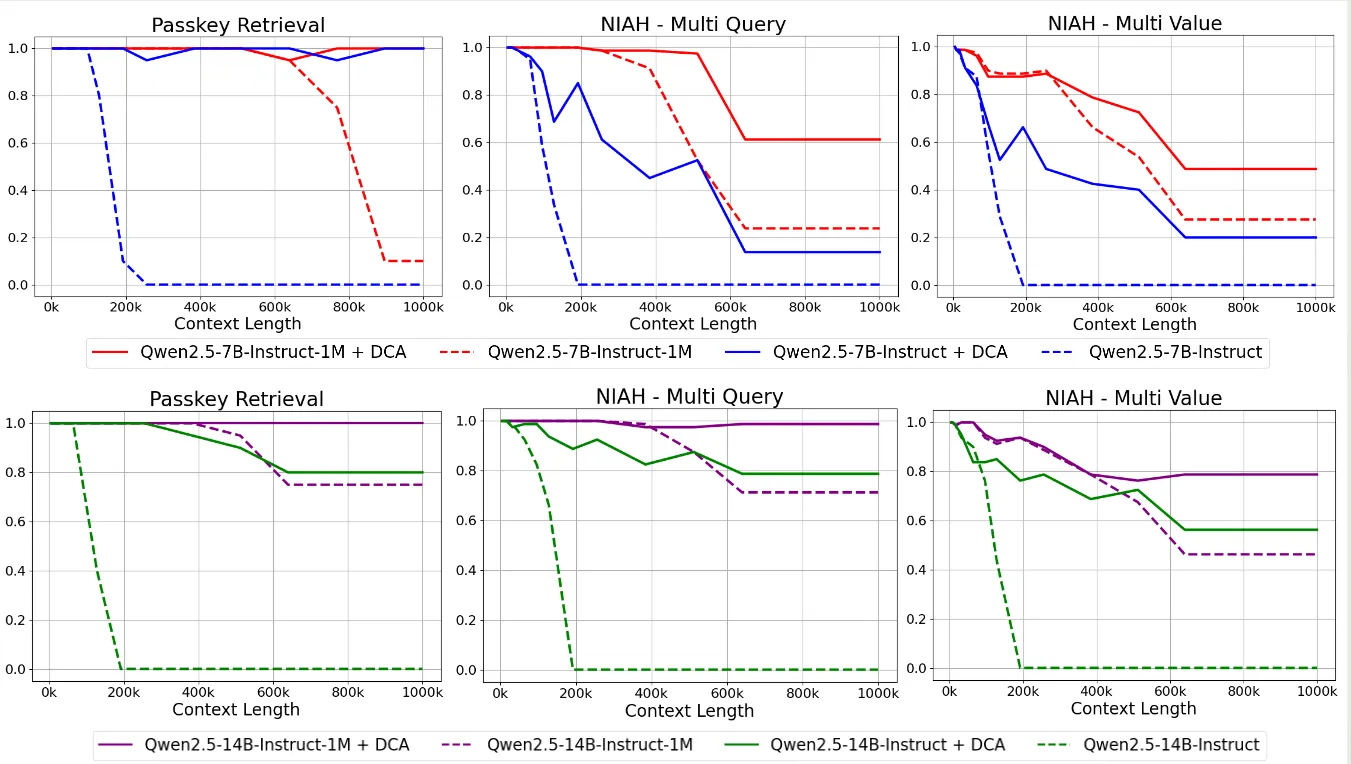
结果显示,Qwen2.5-1M 的表现比 Qwen2.5 更好,并且加上 DCA 之后,两者的表现都有进一步的提升。
Sparse Attention
为了进一步提高计算效率,作者基于 MInference 来加速 perfilling phase. 并结合了 前面的技巧来防止模型性能下降。
MInference MInference 的主要思想就是在长上下文中,有一些 critical token 对最终结果的影响是更大的。因此我们可以识别出这些 critical token 并只计算这些 token 对应的 attention score. 这些 critical token 对应的 pattern 被称为 Vertical-Slash pattern.
为了识别出这个 pattern,作者首先进行离线搜索,来决定最优的 configuration。这个 configuration 决定了 attention 应该如何计算。在 Inference 阶段,MInference 首先计算最后一个 query 和前面所有 key 的 attention,然后基于 configuration 来动态选择 pattern。通过 MInference,我们可以降低 10 倍以上的内存和算力消耗。
Integrating with Chunked prefill 但是 MInference 的问题在于,整个 sequence 是并行处理的,这会导致内存占用持续上升。为了解决这个问题,作者提出了 chunked prefilling 的技巧,来降低 VRAM 的消耗。具体做法就是,将整个 sequence 分为若干个 chunk,然后每个 chunk 里,选取最后 64 个 token 作为 query,在每个 chunk 中分别识别出 critical token,这样就降低了 MInference 的内存占用
接下来,作者在集成 DCA 的时候,发现性能有所下降。作者认为,这是由于 DCA 的 position id 信息不连续所导致的,为了解决这个问题,作者在选择 critical token 的时候,使用了连续版的 position id 信息。在最终推理的时候,还是使用 DCA 本身的位置信息。
Sparsity refinement 前面提到,MInference 需要先进行离线搜索决定最优的 configuration,但是对于 1M token 的上下文,这个过程还是非常耗时的。因此,作者构建了一个加速离线搜索的方法,具体做法就是定义两个 attention score,一个是 full attention, 另一个是 sparse attention, 然后计算两者的差值,如果说相差比较小,则说明 critical token 抓住了全局信息,这个配置是有效的。其公式定义如下:
Attention Recall 越高,说明选取的 critical token 越好,其 configuration 也就越好。
作者进一步分析了 sparse attention 对 accuracy 的影响,结果如下
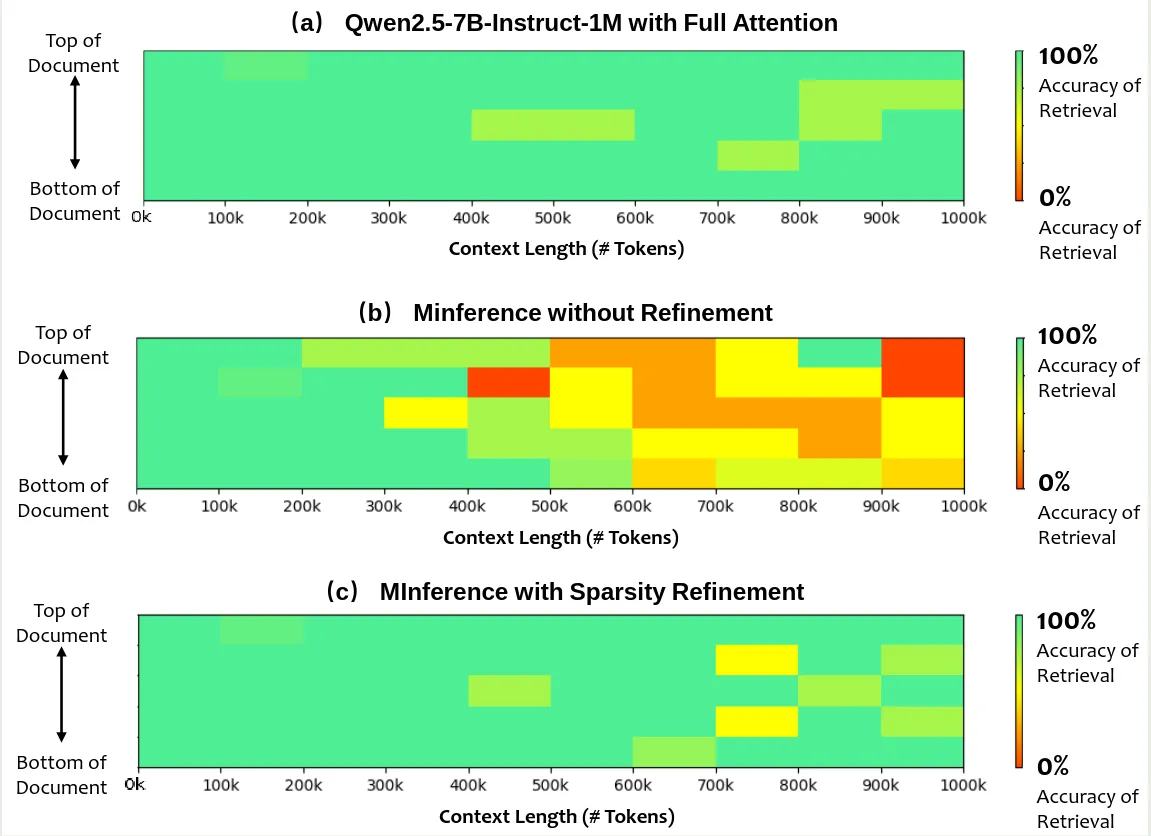
可以看到,仅使用 MInference 会导致模型性能 下降,但是加入 refinement 之后,模型的表现基本上和 full attention 差不太多。
Inference Engine
Kernel Optimization 作者还对 inference engine 进行了优化,作者使用 BladeLLM 作为 Qwen2.5-1M 的推理引擎。
作者主要做了两点优化,第一是对 sparse attention kernel 进行了优化,提高了 sparse attention 的计算效率,结果发现,在 1M 的上下文下,BladeLLM 比 flash attention (Dao et al., 2022) 要快 27.8 倍。
第二是针对 MoE kernel 的优化。作者发现,decoding 的表现是与 memory access speed 相关的。具体来讲,当 batch size 超过 32 之后,获取模型参数成了效率的瓶颈。因此,作者使用了一系列技巧来提高 memory access 的效率
Pipeline parallelism 作者还对 Chunked pipeline parallelism 进行了优化,Chunked pipeline parallelism 的问题在于,在长上下文的场景下,不同长度的 chunk 会对 attention 的计算时间产生很大影响。不同的计算时间会产生 pipeline bubbles.
BladeLLm 使用了 Dynamic Chunked pipeline parallelism 来解决这个问题,该方法通过计算复杂度来调整每个 chunk 的大小,进而使得最终的处理时间尽可能一致

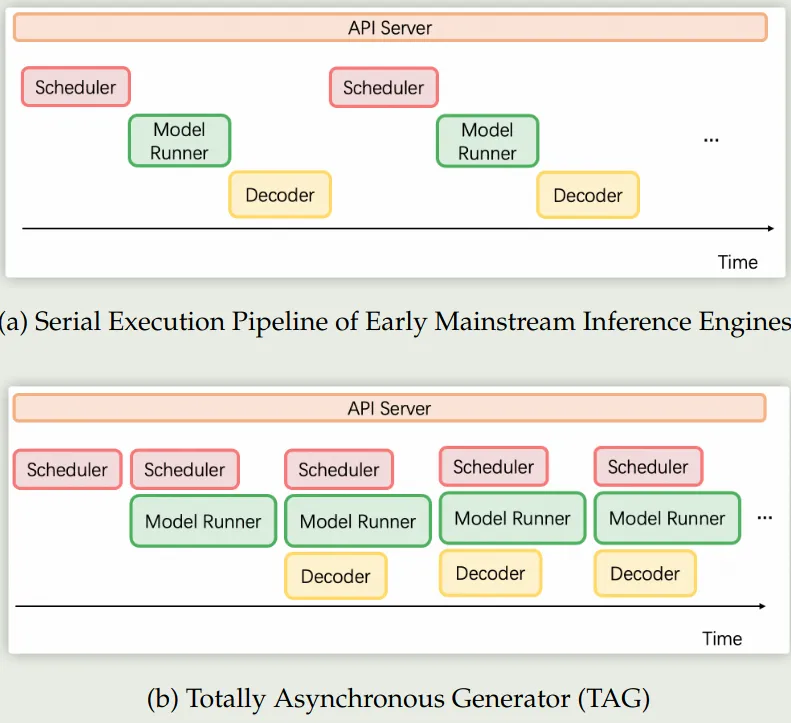
Scheduling 作者还在 Scheduling 上进行了优化,已有的推理引擎主要分为四个模块:API server, scheduler, model runner 以及 decoder
已有方法的问题在于,non-GPU 的操作会占用大量时间,导致 GPU 利用率非常低。因此,作者在 BladeLLM 中进行了改进,使用了 Totally Asynchronous Generator (TAG) 的架构,主要有:
- Scheduler:动态分配 KV cache,类似于 speculative sampling, 而不必等前面的结果完成
- Runner: 基于 Scheduler 分配的任务直接进行处理,处理完之后直接处理下一个任务
- Decoder:基于 token id,进行解码,然后发送给前端的 API server
Evaluation
作者主要在三个 benchmark 上进行了评测:
- RULER: RULER 是 Needle-in-ahaystack 任务的一个扩展笨笨,其要求模型从不相关的上下文中找到多个 “needles” 或者回答多个问题,数据最长为 128K tokens.
- LV-Eval: LV-Eval 要求模型从上文本中同时理解多个 evidence fragments,数据最长为 256K tokens
- Longbench-Chat: 评估模型在长上下文下与人类偏好对齐的程度,数据最长为 100K tokens
Qwen2.5-1M 与 Qwen2.5 的对比表现如下
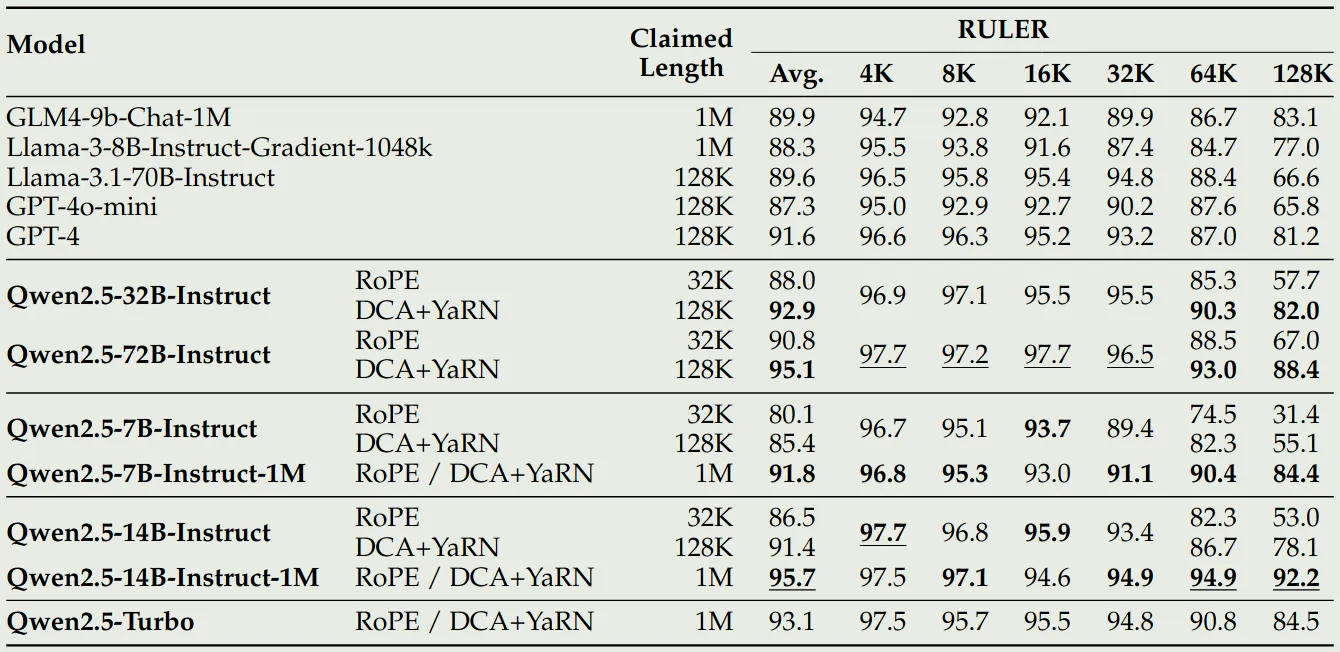
可以看到,相比于 Qwen2.5,Qwen2.5 模型的表现有了大幅度的提升。
Qwen2.5
2024 年 12 月 Qwen 发布了 Qwen 2.5 (Qwen et al., 2025) 系列大语言模型,包括 7 个 dense 模型以及两个 MoE 模型,Qwen2.5 在 pre-training 阶段使用了 18T token 进行。在 post-training 阶段使用了 1M 的样本,还使用了 DPO 以及 GRPO 来进行 RL 的训练
Qwen2.5 主要在以下方面进行了改进
- 模型方面,提供了更多的 size,Qwen2 中只有 0.5B, 1.5B, 7B, 72B 四个 size, 在 Qwen2.5 中,加入了 3B, 14B 和 32B 三个 size 的模型
- 数据方面,pre-training 阶段使用了 18T 的 token, post-training 阶段使用了 1M 的样本
- 功能方面,Qwen2.5 支持更长的上下文长度(8K),支持结构化输入和输出,拥有更强的工具调用能力。
Architecture
模型架构这方面,Qwen2.5 和 Qwen2 的模型架构是一致的,tokenizer 页没有太大变化。为了支持工具调用,作者额外增加了 18 个 control token
Pre-training
data
Qwen2.5 从以下方面提高了预训练数据的质量
- Better data filtering: 使用 Qwen2-Instruct 来过滤掉质量的数据,然后从多维度对训练数据进行打分,从而提高数据的质量
- Better math and code data: 加入了 Qwen2.5 Math 以及 Qwen2.5 Coder 的训练数据来提高模型的数学和代码能力
- Better synthetic data: 作者使用 Qwen2-72B-Instruct 以及 Qwen2-Math-72B-Instruct 来合成 math, code, knowledge domain 的数据,然后通过过滤以及 Qwen2-Math-RM-72B 来提高数据的质量
- Better data mixture: 作者使用 Qwen2-Instruct 来分类,然后平衡不同 domain 的数据分布。作者发现 e-commerce, social media 以及 entertainment 的数据重复性高,且大多都是机器生成的。而 technology, science 以及 academic research 等 domain 的数据质量更高。作者对不同 domain 的数据进行了上采样或者下采样。
基于这个过程,作者一共收集了18T tokens
Hyper-parameters
作者构建了针对超参数的 scaling law,即决定最优的训练超参数如 batch size, learning rate 等
作者通过实验得到了 model size 以及 pre-training data size 与 learning rate 和 batch size 之间的关系。
Long context pre-training
为了提升模型的上下文长度,作者将 pre-training 拆分为两个 stage,第一个 stage 的上下文长度为 4096, 第二个 stage,作者将上下文长度从 4096 扩展到 32768.
在提升模型上下文过程中,作者使用 ABF 技巧将 Position Encoding 的 base frequency 从 10,000 提升到了 1,000,000.
对于 Qwen2-5-Turbo,作者实现了渐进式上下文长度扩展策略,模型上下文长度扩展经历四个阶段:32768, 65536, 131072 到最终的 262,144. 此时,RoPE 的 base frequency 为 10,000,000. 在训练的每个阶段,作者都使用了 40% 的长文本以及 60% 的短文本,以保证在扩展模型上下文长度的同时,还能保持模型在不同上下文长度下的表现。
为了提高模型在 inference 时的长上下文表现,作者使用了 Dual Chunk Attention 和 YARN 两个技巧。通过这两个技巧,作者将 Qwen2.5-Turbo 的上锈阿文扩展到了 1M,将其他模型的上下文长度扩展到了 131072.
Post-training
Qwen2.5 的 post-training 分为两个大的 stage: SFT 和 RL,其中 RL 又分为两个小的 stage,分别是 offline RL 和 online RL
在 SFT 阶段,作者主要做了以下改进:
- Long-sequence generation: 作者将 Qwen2.5 的输出长度提升到了 8192, 为了扩展模型输出的长度,作者构建了 Long-response 数据集,然后基于 back-translation 来生成对应的 query,最后使用 Qwen2 来过滤低质量的数据
- Math: 作者在 SFT 阶段加入了 Qwen2.5-Math 的 CoT 数据,包括公开数据集,K12 问题集一集合成数据等。作者通过 rejection sampling 以及 annotated answers 来生成 CoT 过程
- Code: 作者加入了 Qwen2.5-Coder 的 SFT 数据,作者基于多个 agent 来生成多样化高质量的 Instruction, 然后还从 code-related QA website 以及 Github 上获取数据来扩展数据集。对于最终的数据,作者使用了 sandbox 来保证代码的质量
- Instruction following: 作者构建了一个基于 code 的验证框架,让 LLM 同时生成 Instruction 和对应的验证代码,验证的单元测试。最后,通过 rejection sampling 来得到最终的数据集
- Structured Data Understanding: 作者还构建了针对 tabular QA, fact verification, error correction 以及 structured understanding 等数据集。作者在回答中加入 CoT,作者提高了模型对 structured data 的理解能力
- Logical Reasoning: 作者构建了 70,000 个不同 domain 的 query,有多种格式,覆盖了 analogical reasoning, causal reasoning 等 domain
- Cross-Lingual Transfer: 作者使用了一个翻译模型,来将 Instruction 转换到 low-resource language 上,进而提高模型在对应语种上的表现
- Robust System Instruction: 作者构建了不同的 system prompt 用于提升 system prompt 的多样性。作者发现,使用不同的 system prompt 可以减少模型的 variance, 提高模型的 robustness.
- Response Filtering: 作者使用了多种自动化标注方法来保证最终 response 的质量
最终,作者一共收集到 1M 的 SFT 样本,模型训练了两个 epoch
在 RL 阶段,作者首先基于 SFT model 来进行采样,然后将高质量的回答作为正样本,低质量的回答作为负样本,通过这个过程,一共采集到了150K的样本。最后,作者使用 DPO 来进行训练。
然后,作者进行了 online stage 的 RL 训练,这一阶段主要是对齐模型与人类的价值观。这一阶段的数据包括公开数据集,私有数据集。作者使用不同的 checkpoint 来进行采样,然后作者使用 GRPO 来进行训练.
Long Cotnext Fine-tuning
作者还针对 Qwen2.5-Turbo 做了额外的 post-training, 来进一步提高其在长上下文下的表现。
在 SFT 阶段,作者使用了一个两阶段方法,第一阶段仅在短文本上进行训练(上下文长度为 32768),这一阶段的训练数据与其他 Qwen2.5 的模型训练数据相同。第二个阶段,作者混合了短文本和长文本(262144)来进行训练,来提高模型在长上下文情景下的指令跟随能力
在 RL 阶段,作者使用了和其他 Qwen2.5 模型相同的训练策略。作者认为:
- 长上下文下训练 RL 代价很大
- reward model 更偏向于长文本
- RL 尽管只在短文本上进行训练,其还是可以提高模型在长上下文下的表现。
Evaluation
我们仅关注 instruction 版本的 72B,32B 和 7B 模型
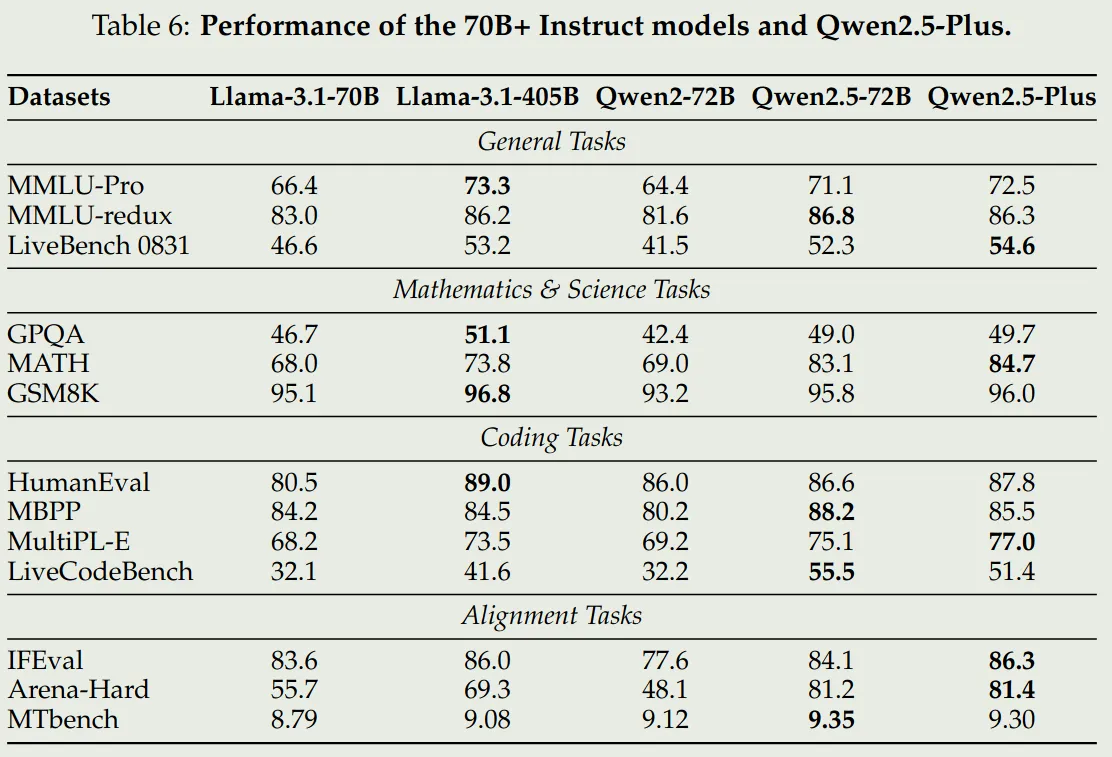
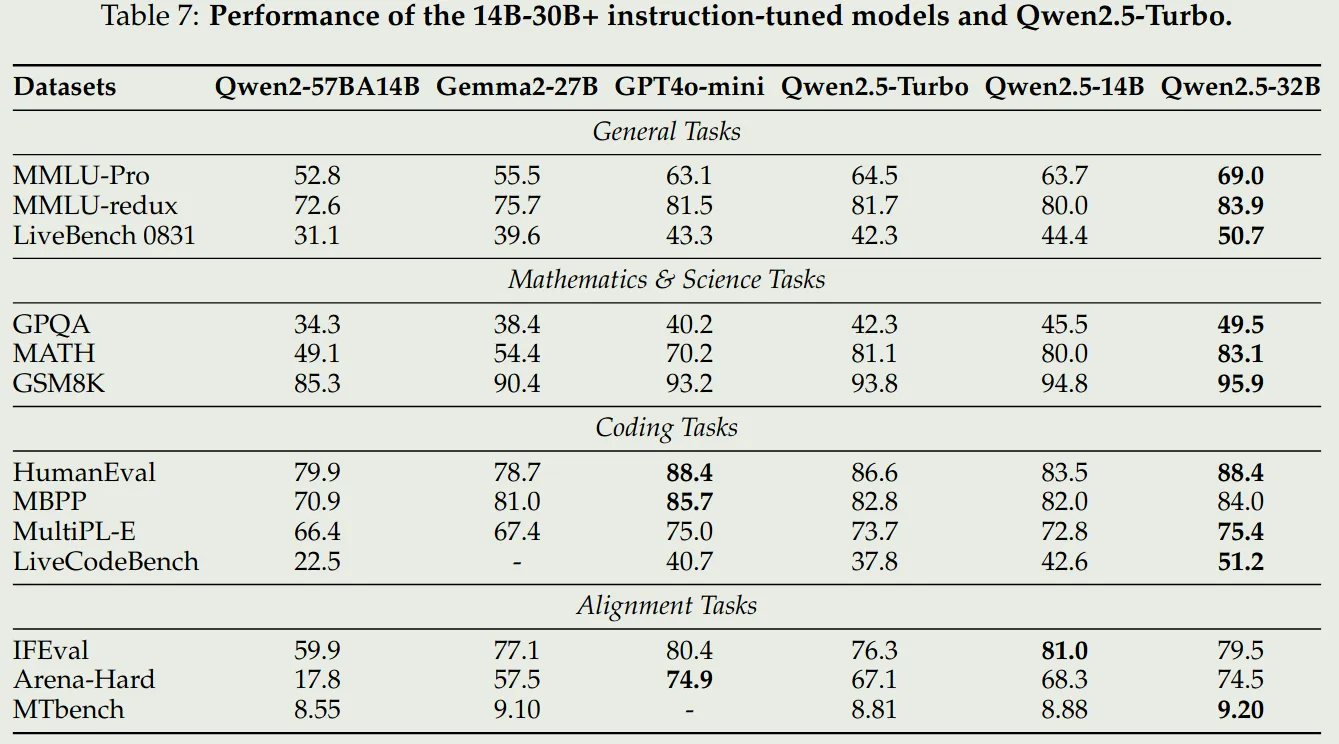
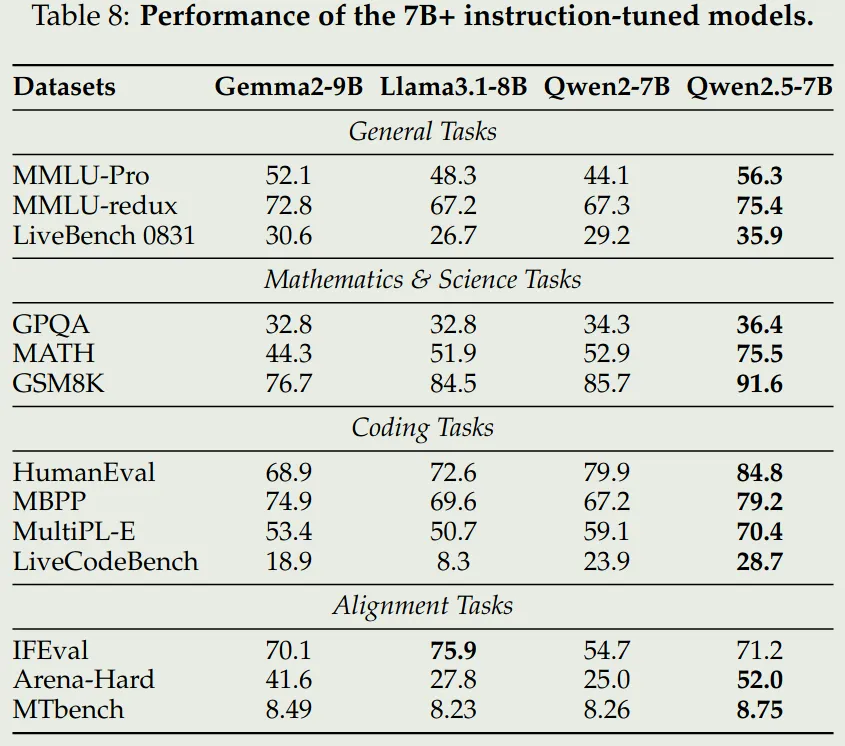
可以看到,Qwen2.5 72B 模型表现和 LLaMA3.1 405B 表现差不多,其他两个 size 的模型基本上达到了 SOTA
最后,作者评估了一下 DCA+YaRN v.s. Full attention 的表现,结果如下图所示
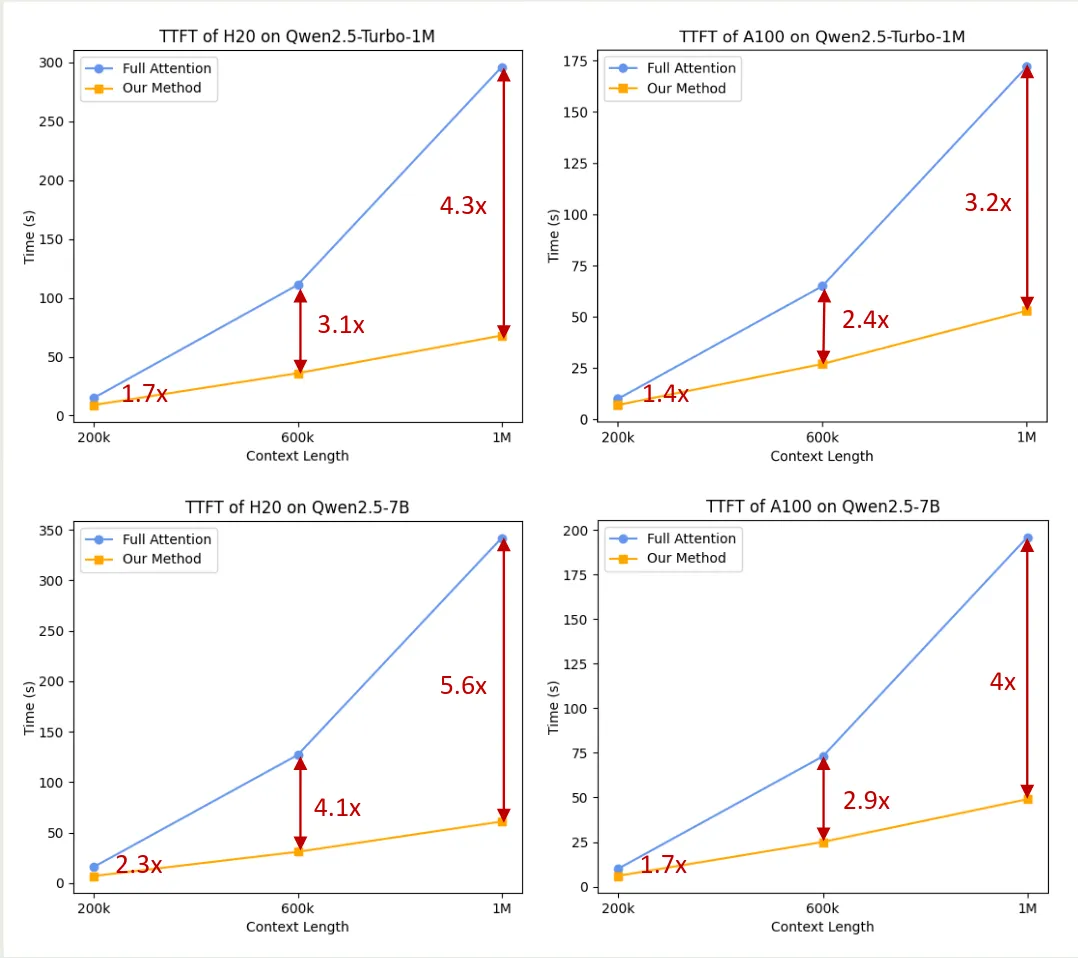
可以看到,使用 DCA+YaRN 之后,模型的推理效率比 full attention 要快 3-4 倍。
Conclusion
在本文中,作者提出了 Qwen2.5 系列大语言模型,包括 7 个 dense 模型以及两个 MoE 模型,作者详细介绍了模型的 pre-training 和 post-training. 评测结果发现 Qwen2.5 模型基本上达到了 SOTA.
作者认为,未来工作有:
- 使用更多更多样化的 pre-training 和 post-training 数据
- 多模态大模型的构建,特别是 omni-modal
- 提高模型的 Reasoning 能力
- Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., … Qiu, Z. (2025). Qwen2.5 Technical Report. https://arxiv.org/abs/2412.15115
QwQ
通义团队在3月6号发布了QwQ-32B (Team, 2025),一个基于RL的,32B参数的reasoning model,QwQ-32B的表现可以与DeepSeek-R1相比
Method
QwQ-32B基于Qwen2.5-32B开发。主要通过基于outcome-based rewards的RL进行训练。训练过程包括两个stage
- Stage 1:本阶段在math和coding domain上进行RL的训练,作者使用了一个verifier来保证最终数学问题结果的正确性,使用了一个code execution server来保证最终生成代码的正确性。
- Stage 2:本阶段在通用领域上进行RL的训练。模型基于general reward model和一些rule-based verifier进行训练。应该是类似 DeepSeek-R1 的规则。
Experiments
实验结果如下图所示
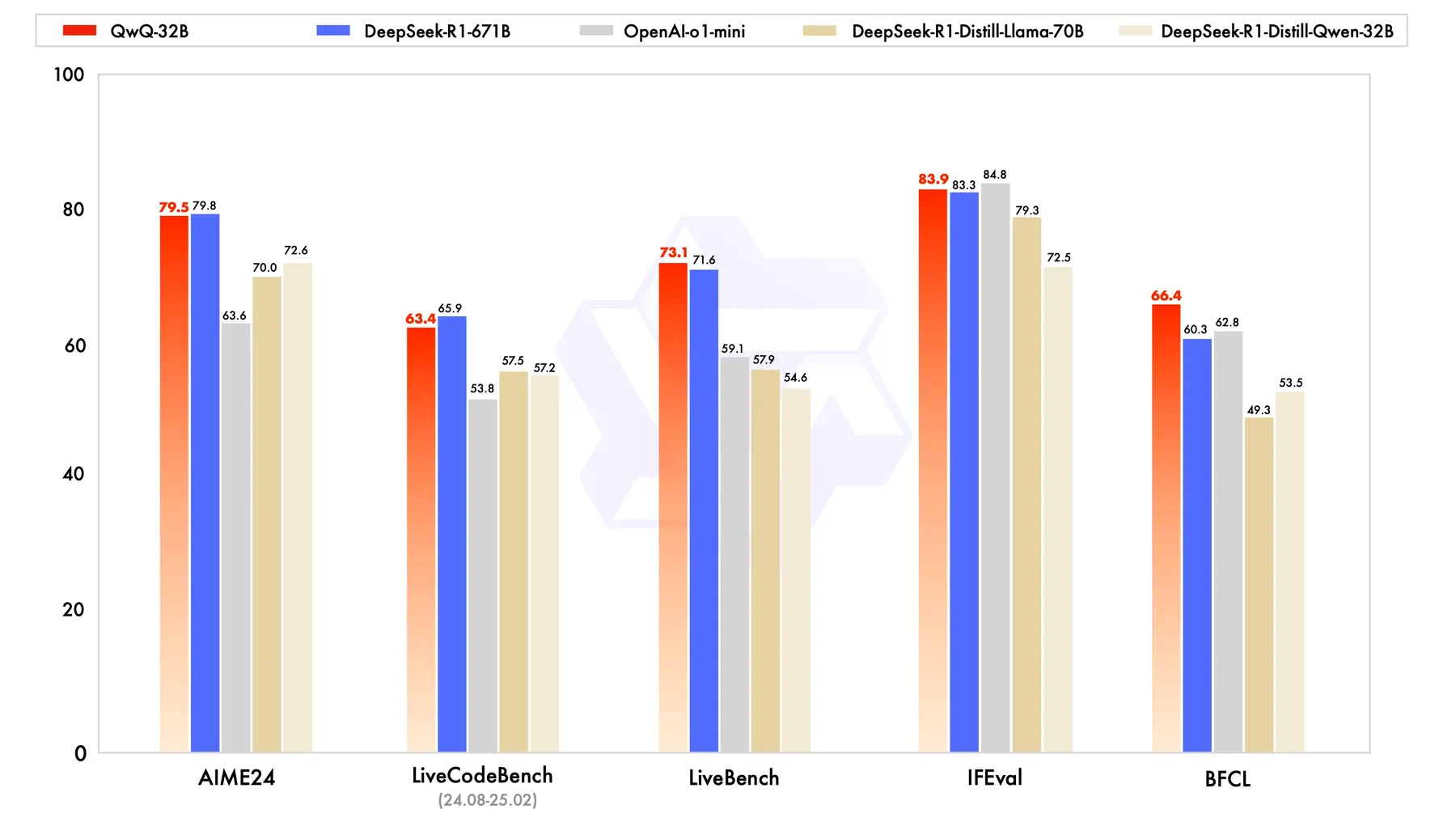
- Team, Q. (2025). QwQ-32B: Embracing the Power of Reinforcement Learning. https://qwen.ai/blog?id=qwq-32b
Qwen3
Qwen 在 2025 年 5 月发布了 Qwen3 (Yang et al., 2025) 系列大语言模型,Qwen3 包括 6 个 dense 模型和 2 个 MoE 模型,主要亮点为多语种能力,自适应快慢思考能力以及支持用户设置 thinking budget.
Qwen3 包括 6 个 dense 模型和 2 个 MoE 模型,其旗舰模型是一个 235B 的 MoE 模型,激活参数为 22B. Qwen3 系列的主要亮点如下:
- 快慢思考融合,模型原生支持在 reasoning/non-reasoning 模式之间切换
- Reasoning budget, 用户可以指定思考需要的 budget,来平衡 latency 和 performance
- Distillation, 使用蒸馏的方法训练小模型,大幅度提高模型的表现
- 多语种支持,相比于 Qwen2.5,Qwen3 支持 119 中语言和方言
Architecture
Qwen3 的 dense 模型的架构与 Qwen2.5 基本一致,包括使用 GQA , SwiGLU, RoPE, RMSNorm 和 pre-normalization. Qwen3 进一步移除了 QKV bias, 然 后加入了 QK-Norm 来提高训练的稳定性。
Qwen3 的 MoE 架构使用了 128 个专家,激活专家个数为 8 个。与 Qwen2.5-MoE 不同,Qwen3 里没有使用 shard experts。并且,Qwen3 加入了 global-batch load balancing loss,来提高 expert 的特化程度。
在 tokenizer 方面,Qwen 系列的 tokenizer 一直都是一样的,这也是 Qwen 系列领先的一点。
模型的具体参数如下两张表所示。
MoE 架构:上下文长度为 128K,128 个专家,每个 token 由 8 个专家负责处理
- Qwen3-235B-A22B, 总参数 235B,激活参数 22B
- Qwen3-30B-A3B, 总参数 30B,激活参数 3B
| Models | Layers | Heads (Q / KV) | # Experts (Total / Activated) | Context Length |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
dense 架构: Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B, and Qwen3-0.6B
| Models | Layers | Heads (Q / KV) | Tie Embedding | Context Length |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-4B | 36 | 32 / 8 | Yes | 32K |
| Qwen3-8B | 36 | 32 / 8 | No | 128K |
| Qwen3-14B | 40 | 40 / 8 | No | 128K |
| Qwen3-32B | 64 | 64 / 8 | No | 128K |
Pre-training
预训练数据一共包括 36T token,覆盖了 119 种语言。数据包括 coding, STEM, reasoning, books, multilingual texts 以及合成数据。
为了扩展训练数据,作者微调了 Qwen2.5-VL 来从 PDF 文档中提取文字,然后使用 Qwen2.5 来进行修正。最终收集到了几 T 的 token。另外,作者还使用 Qwen2.5, Qwen2.5-Math, Qwen2.5-Coder 来合成不同格式的数据,包括教科书,QA,指令以及代码片段等。最后,作者加入了更多的多语种数据。
作者从 educational value, fields, domains 以及 safety 对数据进行了标注。在数据混合时,Qwen3 在 instance 层面进行操作。
预训练阶段包括 3 个 stage:
- General Stage (S1): 这一阶段的目的是让模型掌握世界知识,使用了 30T 的 token,模型上下文长度为 4096
- Reasoning Stage (S2): 这一阶段的目的是提高模型的推理能力,使用了 5T 的高质量 token,模型上下文长度为 4096,数据包括 STEM, coding, reasoning 以及合成数据
- Long Context Stage (S3): 这一阶段的目的是提升模型的长上下文能力,使用了几百 B的 token,模型上下文长度为 32768.训练时数据混合 75% 的长文档数据,25% 的短文本数据。作者将 RoPE 的 frequency 从 10000 提升到了 1,000,000. 作者还是用 YARN 以及 Dual Chunk Attention 来提高 inference 效率
对 pre-training 的 base model 进行评测之后,作者发现:
Qwen3-235B-A22B-Base超过了其他 base 模型的表现,包括DeepSeek-V3 Base,Llama-4-Maverick Base,Qwen2.5-72B Base- Qwen3-MoE 模型与相同大小的 Qwen3-Dense 模型参数相比,其只需要 1/5 的参数就可以达到相同的表现
- Qwen3-MoE 模型与 2 倍参数量的 Qwen2.5-MoE 模型表现差不多
- Qwen3-Dense 模型与大一个量级的 Qwen2.5-Dense 模型表现差不多
Post-training
Qwen3 的 post-training 如下图所示:
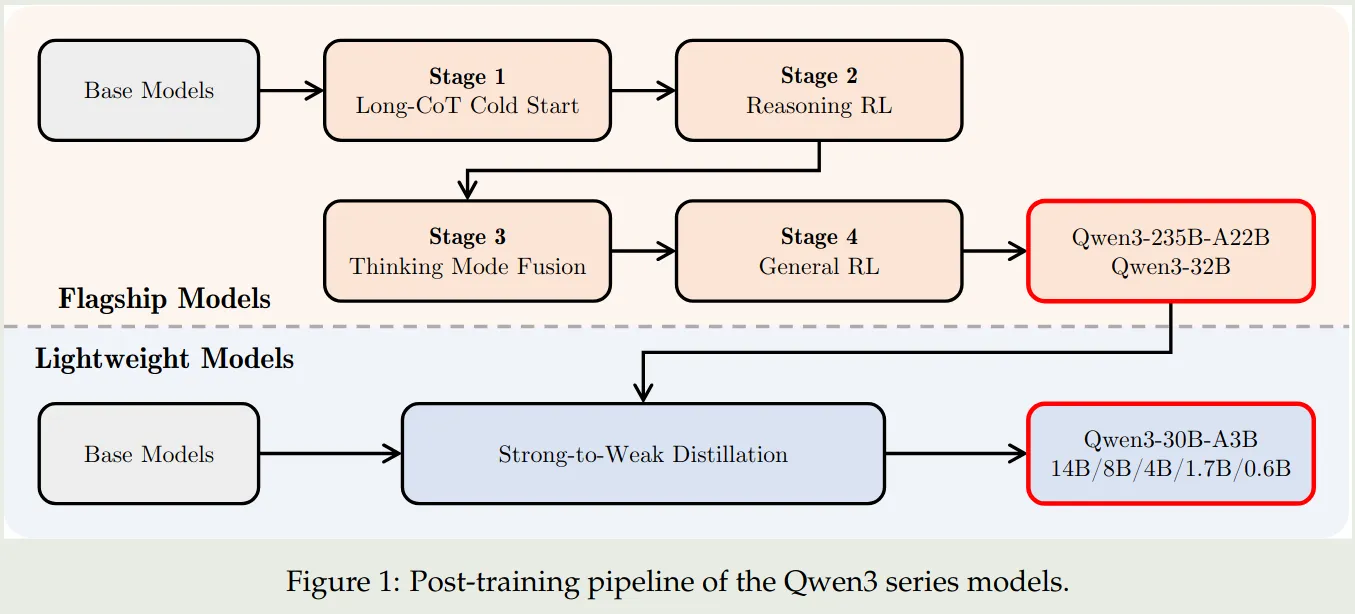
对于旗舰模型 (Qwen3-235B-A22B, Qwen3-32B) 的训练,Qwen3 使用了一个四阶段的训练 pipeline。对于轻量化模型(其他模型)的训练,Qwen3 使用了知识蒸馏。
旗舰模型的训练包括四个阶段,前两个阶段用于提升模型的 reasoning 能力,后两个阶段用于将 reasoning 和 non-reasoning 能力结合起来。
Flashship Model
Stage 1 (Long CoT Cold Start) 这个阶段的目的是让模型掌握 reasoning 的基础。这个阶段使用了数学,代码,逻辑推理和通用的 STEM 相关问题。每个问题都有参考答案或者 test-cases. 作者使用了 Qwen2.5-72B 来过滤数据,包括 non-verifiable prompts 以及太简单的 prompt. 作者认为,这一阶段应该减少训练使用的样本和训练步数。
Stage 2 (Reasoning RL) 这个阶段的目的是提升模型的 reasoning 能力。该阶段使用了 3,995 条过滤得到的样本,算法为 GRPO. 作者发现提高 batch size 和每个 query 的 rollouts 可以提高模型的表现。作者通过调整模型的 entropy 来控制 exploration 和 exploitation 的平衡
Stage 3 (Thinking Mode Fusion) 这一阶段的目的是将 non-reasoning 能力加入到之前的 reasoning 模型中。作者在第二阶段的 model 上进行了 continual SFT,然后构建了一个 chat template 用于融合两种模式。
reasoning 数据来源于 stage1 的 rejection sampling 和 stage 2 的模型. non-reasoning 数据来源于各种任务,如 coding, math, multilingual 等。为了保证模型的多语种能力,作者还加入了一些翻译相关的数据。
作者还构建了一个 chat template, 用于统一数据格式。chat template 如下图所示

作者使用 /think 和 /no_think 来标记两种模式,对于 non-reasoning mode, 其 <think></think> 会被置空。模型在默认情况下处于 reasoning mode, 因此作者加入了一些不包含 /think 的 reasoning 数据。
作者发现,通过这种 Think mode fusion, 模型可以学会在 reasoning mode 和 non-reasoning mode 下进行回答,因此,模型也可以基于中间结果来给出最终的答案。 当超出 budget 之后,作者使用以下 Instruction
Considering the limit time by the user. I have to give the solution based on the thinking directly now. \n</think>.\n\n
来让模型直接终止思考二给出最终的答案。
Stage 4 (General RL) 这个阶段的目的是提升模型在不同场景下的能力。作者构建了一个 reward system 来覆盖 20 多种不同的任务。这些任务包括:instruction following, format following, preference alignment, agent ability 以及 abilities for specialized scenarios.
作者构建了三种不同的 rewards:
- Rule-based rewards: 覆盖的任务包括 instruction following 和 format following
- Model-based rewards: 作者使用 Qwen2.5-72B 来判别答案的正确性
- Model-based Reward without reference answer: 作者训练一个 reward model 来给模型的回答进行打分
Lightweight Model
对于轻量化的模型,作者发现直接通过蒸馏可以有效提高学生模型的表现,并且训练效率也更高。蒸馏训练包括两个阶段:
- Off-policy Distillation: 这个阶段的目的是让模型拥有基本的 reasoning 能力并且可以在不同的模式中进行切换。作者使用了教师模型的 reasoning 输出和 non-reasoning 输出来蒸馏学生模型
- On-policy Distillation: 在这个阶段,学生模型生成回答,然后基于教师模型的输出,使用 KL-divergence 来更新学生模型的参数
Evaluation
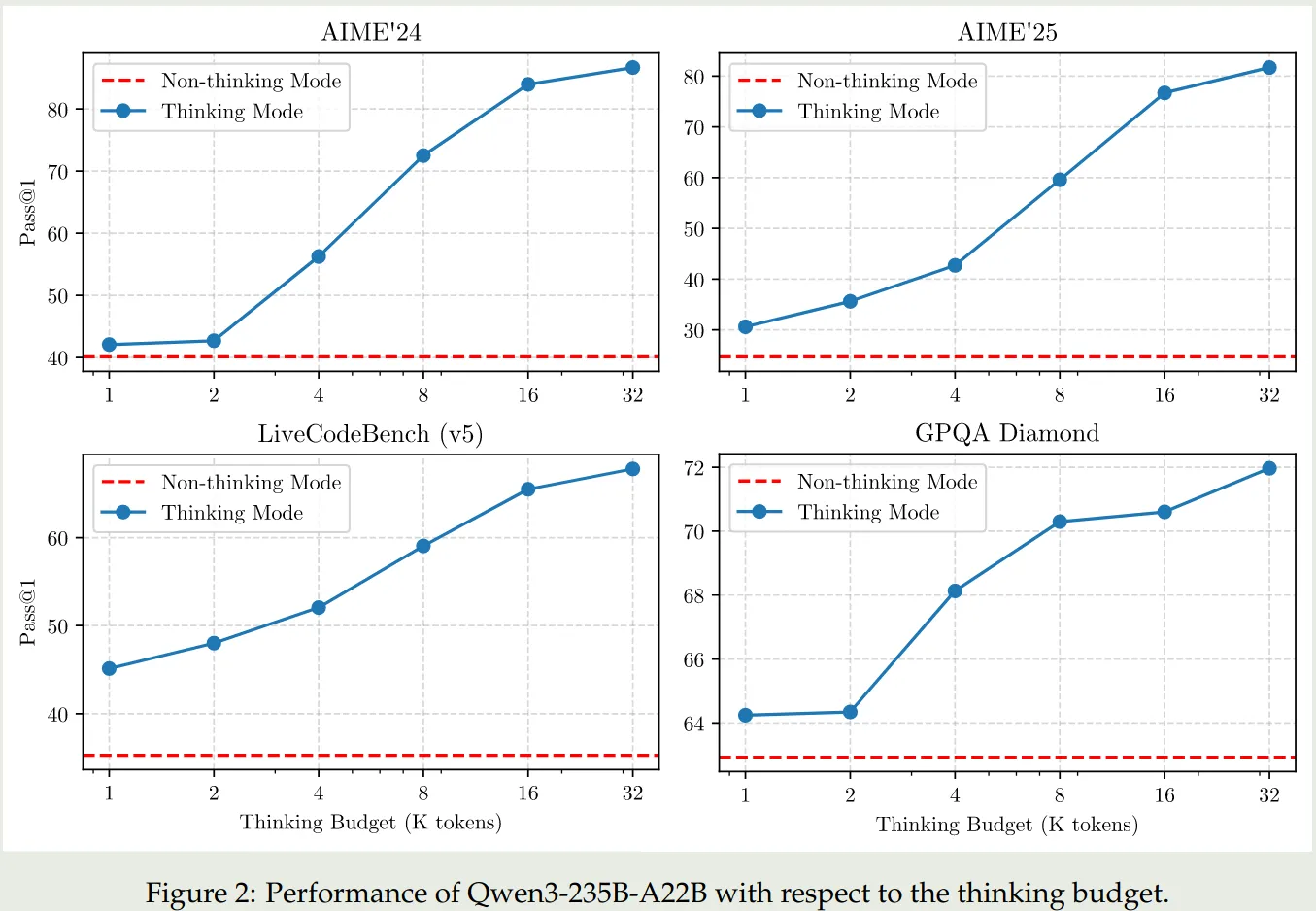
Thinking budget. 作者发现当我们提高 Thinking budget 之后,模型的表现是可以持续提升的。结果如下图
Efficiency of distillation. 作者发现使用 distillation 可以大幅度提高模型的表现和训练效率。下面是结果如下图所示

Effects of Thinking mode fusion and RL 作者进一步探究了三个 stage 对模型表现的影响,为此,作者构建了 in-house benchmarks 来评估模型的表现,这些 benchmarks 包括:
- CounterFactrQA. 问题是不符合事实的,用于评估模型的幻觉
- LengthCtrl. 有长度要求的写作任务,评估生成内容长度和给定长度之间的差别
- ThinkFollow. 多轮对话,每轮对话随机插入
/think和/no_thinkflag,评估模型是否能在两种模式之间切换 - Tooluse. 评估模型的工具调用能力
结果如下
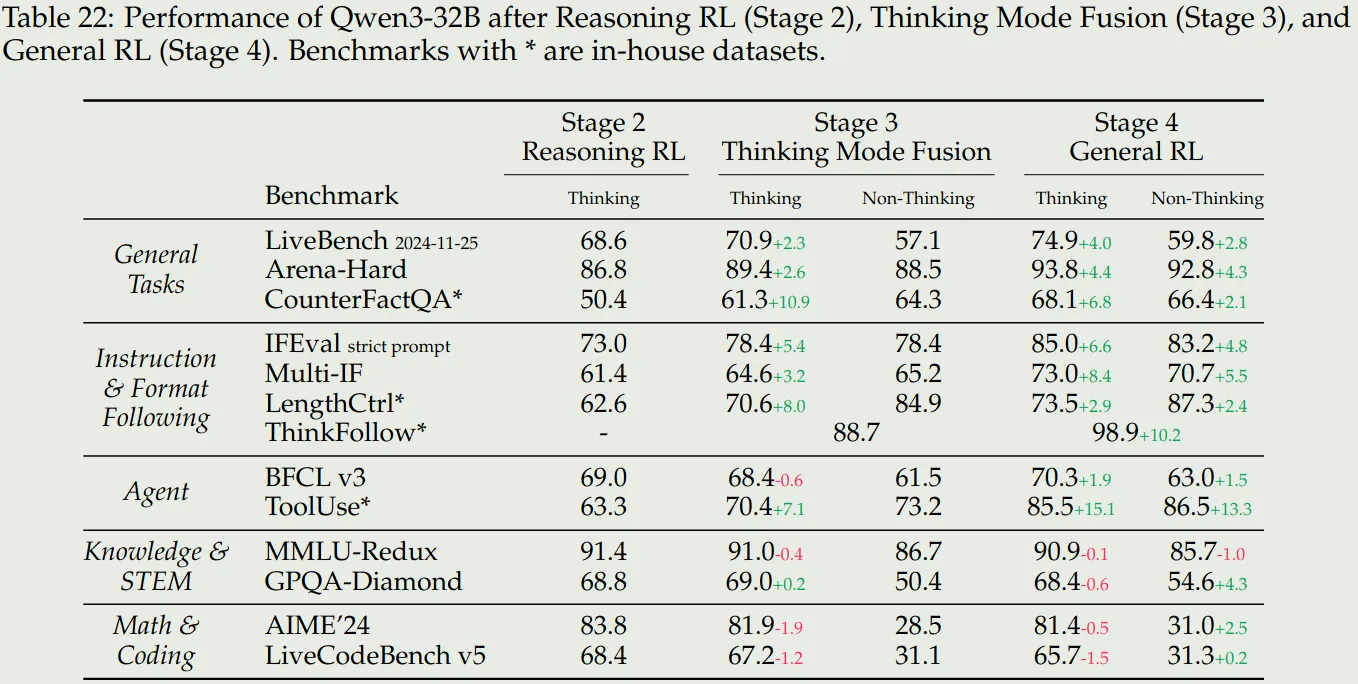
结论如下:
- Stage3 可以提高模型在两种 reasoning mode 切换的能力,并且 stage3 还可以提高模型的通用以及 instruction following 能力
- Stage4 进一步提高模型在两种模式下的通用,instruction following 和 agent 能力
- Stage3 和 stage4 并没有显著提高模型在 knowledge, STEM, math 和 coding 相关任务上的表现。甚至在一些竞赛如 AIME24 上模型的表现还有所下降,作者认为这是由于我们提升了模型的通用能力而导致其特化能力下降导致的,作者认为作为一个通用模型,这是可以接受的。
Conclusion
在本文中,作者提出了 Qwen3 系列大语言模型,包括 6 个 Dense 模型和 2 个 MoE 模型。Qwen3 模型标志了一个新的 SOTA,其特点主要是快慢思考结合,thinking budget,以及多语种。
作者认为后续工作有以下几点:
- 使用更高质量的数据来进行预训练
- 优化模型架构和训练方式,提升模型的上下文
- 提高针对 RL 的计算资源,来进一步提高模型的 agent 能力
- Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., … Qiu, Z. (2025). Qwen3 Technical Report. https://arxiv.org/abs/2505.09388
Qwen3-Next
当前大语言模型在性能与效率上面临双重挑战:纯 Softmax 注意力计算成本高,而纯线性注意力则性能不足。Qwen3-Next (Team, 2025) 尝试通过混合注意力机制解决这一矛盾,同时结合 MoE 架构与多项训练优化策略,实现在保持高性能的同时大幅提升训练与推理效率。
Qwen3-Next 包含三个模型:
- Qwen3-Next-80B-A3B-Base
- Qwen3-Next-80B-A3B-Instruct
- Qwen3-Next-80B-A3B-Thinking
Architecture
模型架构如下图所示
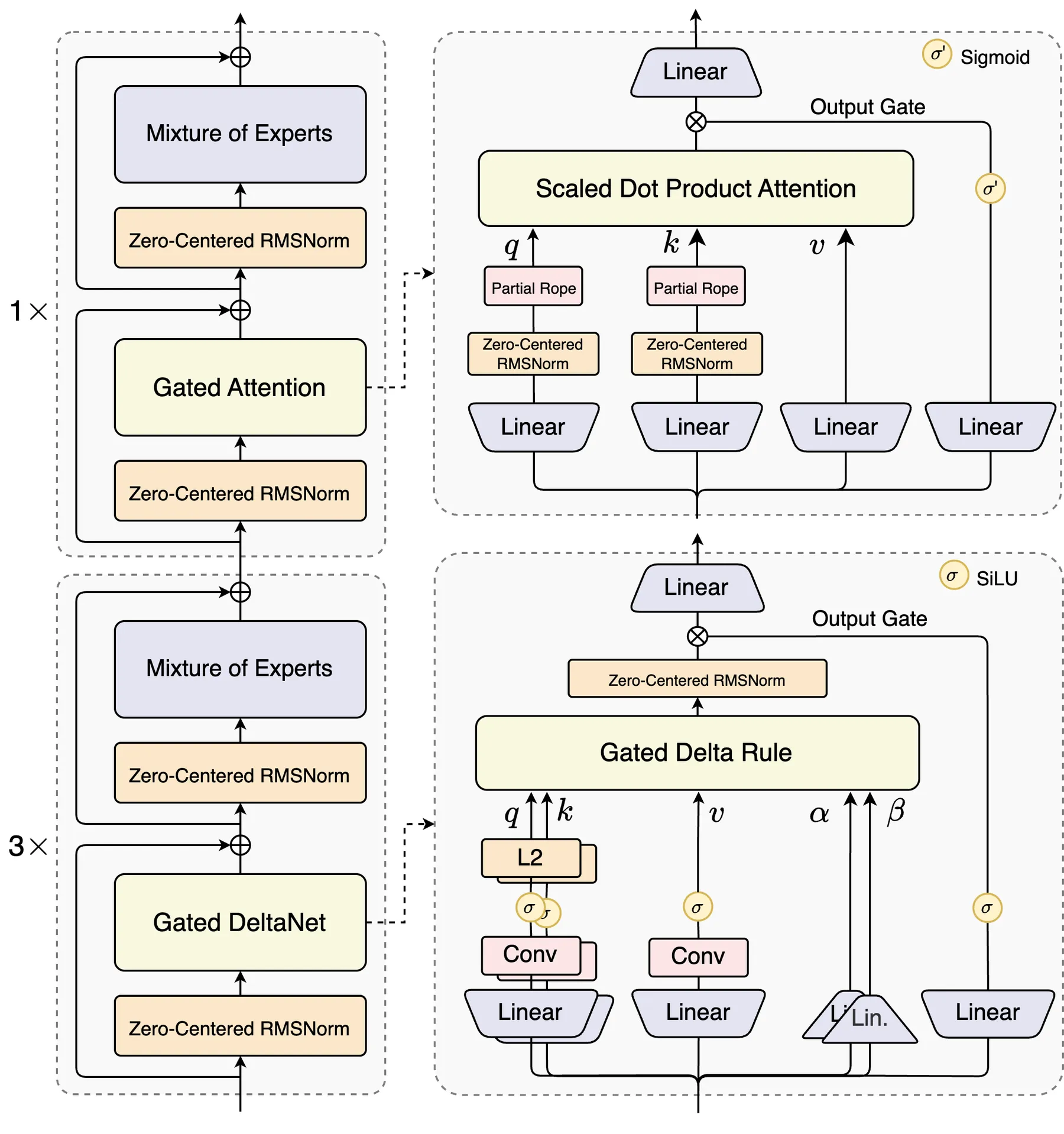
Hybrid Attention
作者首先总结了 linear attention 和 softmax attention 各自的优缺点。
| pros | cons | |
|---|---|---|
| linear attention | fast | low performance |
| softmax attention | slow | high performance |
因此,作者的动机就是是结合 linear attention 与 softmax attention, 在局部利用 linear attention 的高效性来提高训练和推理效率,在关键部分使用 softmax attention 来提高模型的能力。 这种混合注意力机制之前也有很多模型采用,比如 MiniMax-01 等。最终 Qwen3-Next 使用了 Gated DeltaNet+Gated Attention 的混合注意力机制,模型的 transformer layers 按照 4 个为一组,前三层使用 Gated DeltaNet, 第四层使用 Gated Attention.
下面是一些细节:
- Gated DeltaNet 相比于 SWA 和 Mamba2, 其 in-context learning 能力更强
- 对于 softmax attention:
- 使用了 Gated Attention 提出的 gating 机制来解决 massive activation 和 attention sink 问题
- 将 attention head 的 dimension 从 128 提高到 256
- 使用了和 DeepSeek-V3 类似的 partial RoPE 机制,仅对前 的元素进行旋转
MoE
- 1 个共享专家,512 个路由专家,其中激活专家个数为 10 个。
- 对于 MoE router 的参数,作者还进行了 normalization 来保证每个专家被选择的概率相同。
- 与 Qwen3 一致,Qwen3-Next 也是用了 Global-batch load balancing 策略,在保持激活专家数不变的情况下,通过提高总专家个数来降低训练损失。
Normalization and Training
- 使用 Gemma 提出的 Zero-Centered RMSNorm 以及 weight decay 来避免过大的权重出现
- 为了提高数据使用效率,作者还使用了 MTP 策略来提高训练效率,模型表现以及 Speculative decoding 的接受率。
- 预训练时,Qwen3-Next 使用了15T token 进行训练,训练时间相比于 Qwen3-30B-A3B 有了大幅度的提升
Experiments
Efficiency
下图是 Qwen3-Next 与 Qwen3-32B 模型的训练效率对比
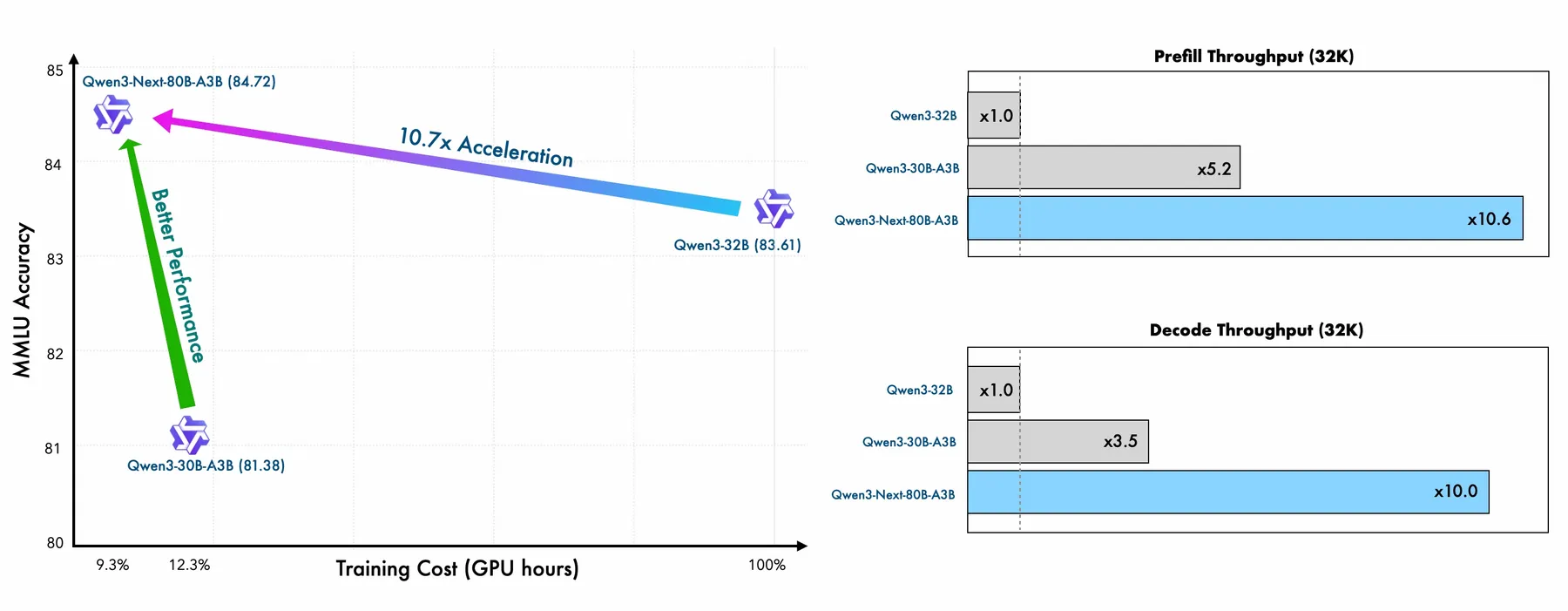
从结果可以看出,相比于 Qwen3-32B, Qwen3-Next 只用了 的算力就达到了更强的表现。
并且,在 inference 阶段,由于使用了 linear attention, Qwen3-Next 的效率也更高,下面是 Qwen3-Next 相比于 Qwen3-32B 的效率提升
| 4K | 32K | |
|---|---|---|
| Prefilling | ||
| Decoding |
Performance
下面是 Qwen3-Next-Base 的表现
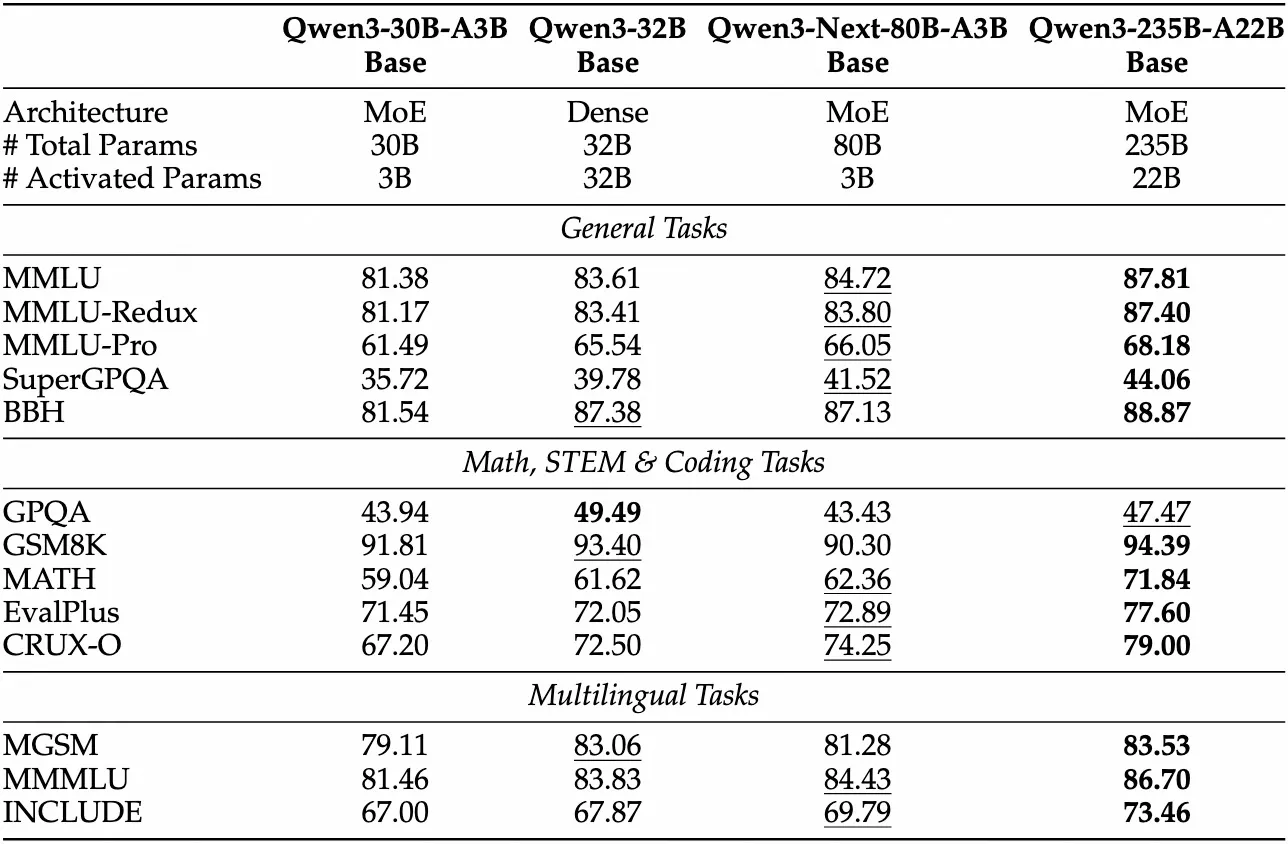
可以看到,Qwen3-Next-Base 在多个 Benchmark 上的表现仅次于 Qwen3-235B-A22B
Qwen3-Next-Instruct 的表现如下表所示
| Benchmark | Qwen3-Next-80B-A3B-Instruct | Qwen3-235B-A22B-Instruct-2507 | Qwen3-32B Non-thinking | Qwen3-30B-A3B-Instruct-2507 |
|---|---|---|---|---|
| SuperGPQA | 58.8 | 62.6 | 43.2 | 53.4 |
| AIME25 | 69.5 | 70.3 | 20.2 | 61.3 |
| LiveCodeBench v6 | 56.6 | 51.8 | 29.1 | 43.2 |
| Arena-Hard v2 | 82.7 | 79.2 | 34.1 | 69.0 |
| LiveBench | 75.8 | 75.4 | 59.8 | 69.0 |
Qwen3-Next-Instruct 的长文本表现(RULER Benchmark)如下
| Model | Avg. | 4K | 8K | 16K | 32K | 64K | 96k | 128K | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-30B-A3B-Instruct-2507 | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-235B-A22B-Instruct-2507 | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-Next-80B-A3B-Instruct | 91.8 | 98.5 | 99.0 | 98.0 | 98.7 | 97.6 | 95.0 | 96.0 | 94.0 | 93.5 | 91.7 | 86.9 | 85.5 | 81.7 | 80.3 | 80.3 |
可以看到, Qwen3-Next-Instruct 在 1M 长度范围内保持稳定性能,整体平均得分 91.8,接近 Qwen3-235B(92.5)。
Qwen3-Next-Thinking 的表现如下表所示
| Benchmark | Qwen3-Next-80B-A3B-Thinking | Gemini-2.5-Flash Thinking | Qwen3-32B Thinking | Qwen3-30B-A3B-Thinking2507 |
|---|---|---|---|---|
| SuperGPQA | 60.8 | 57.8 | 54.1 | 56.8 |
| AIME25 | 87.8 | 72.0 | 72.9 | 85.0 |
| LiveCodeBench v6 | 68.7 | 61.2 | 60.6 | 66.0 |
| Arena-Hard v2 | 62.3 | 56.7 | 48.4 | 56.0 |
| LiveBench | 76.6 | 74.3 | 74.9 | 76.8 |
可以看到,Qwen3-Next-Thinking 的表现在除了 Livebench 之外的三个 Benchmark 均达到了 SOTA
Conclusion
Qwen3-Next 通过混合注意力架构与精细化 MoE 设计,在训练与推理效率上实现突破性提升。其仅以较小计算代价达到接近超大模型性能的表现,为下一代高效大语言模型的设计提供了重要参考。
- Team, Q. (2025). Qwen3-Next: Towards Ultimate Training & Inference Efficiency. https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list