Introduction
Attention 是现代大语言模型架构的核心组件。在这篇 blog 中,我们将回顾 attention 架构的发展。
TimeLine
Roots
Softmax Attention
Introduction
令 为 hidden size, 为 attention heads 的个数, 为 transformer layer 的层数, 为每个 head 的 dimension, 为 attention layer 中第 个 token 对应的 hidden states。 对于标准的 MHA, 我们首先计算 Q, K, V 如下:
其中, 分别为 query, key, value projection layer 的权重。接下来 MHA 的计算方式如下
其中 , , . 为 output projection 的权重。 在 inference 阶段,每个 token 需要缓存其 key 以及 value 对应的值,从而每个 token 的 kv cache 占用为 . 当序列长度过大时,KV cache 会影响整体的 inference efficiency.
对于 multi-head attention, 我们假设其 hidden size 为 , 有 个 heads, 每个 head 的 size 为 , 输入 sequence 长度为 , batch size 为 . 则总的 arithmetic operations 为 . 总的内存访问量为 , 第一项是 的内存占用( 分别是 query, key 和 value layer 的输出),第二项是 attention score 的占用,第三项是 query, key 和 value layer 的权重。
因此,其 Memory Access Ratio (MAR), 也就是内存访问量 与 arithmetic operations 之比为
对于现代的 GPU 来说,其一般算力比较强,但是内存访问带宽相对较慢,因此我们希望 MAR 越低越好,以充分发挥 GPU 的算力。
Analysis
在训练的时候,由于我们知道 ground truth sequence, 因此我们可以并行计算。但是在 inference 的时候,我们只能 token-by-token 进行计算,因此我们分析一下 token-by-token 场景下的 MAR
我们整体的 arithmetic operations 还是 .
但是,现在我们要调用 次 multi-head attention, 因此我们总的内存访问量为 , 第一项是 和 , 第二项是 query, key 和 value layer 的权重。
这种情况下,MAR 就变成了
当 或者 时,MAR 就非常接近于 1,意味着内存带宽成了一个主要的瓶颈。为了解决这个问题,我们有两种做法:
- 提升 batch size , 也就是同时 inference 多次
- 降低 和 的大小
Necessity of Position Encoding
我们知道,transformer使用position encoding的一个原因就是,attention layer具有置换不变性,也就是说,我们随机打乱输入token的顺序,并不影响其最终结果 (我们后面会证明,实际上只对key和value具有置换不变性,对query具有置换等变性,也就是改变query的顺序之后,结果的顺序也相应改变)。因此为了让模型学习到正确的上下文知识,我们需要加上position encoding。
已有的工作大部分都在讨论如何构建更好的position encoding,但是鲜有工作探究为什么attention layer具有置换不变性. 因此,本文将从这一点出发,抽丝剥茧探究其内在原因,最后通过数学公式证明原始transformer是如何具有置换不变性的。
attention layer
原始transformer layer的架构比较简单,其结构具有attention-LayerNorm-FFN-LayerNorm的形式。给定输入 和上下文 . 其中,attention的定义为
其中 是模型的hidden_size, , , , 分别是QKV projection layer的参数.
LayerNorm的定义为:
其中 是一个超参数, 是可学习的参数.
FFN的定义为:
其中 , , , 是可学习的参数。
最后,一个attention layer的的结构可以表达为:
Permutation Invariance
置换不变性(permutation invariant)的定义:假设 ,如果
则我们说 是置换不变的. 这里 是一个置换函数 (permutation function). 当输入的是一个矩阵时,我们默认置换其列,即对 , 我们有 , 其中 是一个置换矩阵 (permutation matrix)。
置换等变性 (permutation equivariant)的定义:假设 ,如果
则我们说 是置换等变的.
Analysis on attention
我们首先证明attention 对于key和value是置换不变的,即
证明: 我们直接计算即可得到:
由于softmax是按列计算的,置换只是改变了元素的顺序,因此我们自然有
这里我们使用了性质 .
接下来我们证明,attention对于query是置换等变的,即
证明:
从以上的证明可以看到,attention layer对于key和value具有置换不变性,也就是说,我们改变文字顺序不影响最终的输出结果。 但是,我们发现,尽管我们证明了attention具有置换不变性,我们却忽略了一件事:那就是我们计算query, key和value的时候,没有加上bias! 为什么bias如此重要呢?这是因为,, 但是 . 因此,我们就会思考,难道是transformer实际上可以通过增加bias的方式来让模型学习到上下文知识?事实上并非如此,我们将要通过分析表明,我们计算query, key和value时,增加的query bias和key bias会被softmax操作给消除掉,而key bias则会被LayerNorm消除掉。因此,我们加与加bias,对attention的置换不变性没有任何影响。
Effect of bias
接下来,我们考虑在计算query, key和value时加入bias。为了简化,我们只考虑query为一个向量的情况,即 , 我们计算query, key和value如下:
这里 . 我们这里简化了scaling的操作,因为其不对结果产生影响。
参考 (Namazifar et al., 2023), 我们首先展开attention中的 :
由于 的列求和为, 因此,, 我们有
接下来,我们展开 :
这里,我们需要用到softmax函数的平移不变性,即 , 这里 是一个常数,证明起来很简单:
而这里 ,因此我们可以将这一项给去掉,我们得到:
接下来,我们展开 ,
因此,我们最终的结论为: key bias对attention输出没有任何贡献,query bias和key bias会影响结果。
到这里,看了 (Yun et al., 2020),我本以为可以进一步简化。但实际上并不行。
(Yun et al., 2020) 关于 “transformer block is equivariant” 的结果是错的,因为在 attention layer 之后还有一个 LayerNorm,而 LayerNorm 不是置换不变的,这也是LayerNorm和BatchNorm之间的区别。
也就是如果我们在 nn.Linear 后加一个BatchNorm,那么nn.Linear的bias是无效的,反之如果是LayerNorm的话,则bias是有效的.
Why there is no bias
实际上这个问题并没有定论。特别是加入 position encoding 之后,就更难探究bias对最终结果的影响了。但是,我认为一个原因就是bias其实就是某种先验知识,假设输入满足高斯分布,那么我们有
加上先验知识后,当训练数据出现distribution shift之后,模型在训练过程中可能就会不稳定(PaLM). 而后来将LayerNorm替换为RMSNorm,使用RoPE而不是其他的additive position encoding, 我认为也是避免模型学习到先验知识,从而影响其泛化性。在未来,我认为transformer里应该是没有bias的,尽管这样效果可能会差一些,但是其稳定性更好,泛化性应该也会更好。
Test code on permutation invariance of attention
import torch
import torch.nn as nn
import torch.nn.functional as F
# 设置随机种子,确保可复现性
torch.manual_seed(42)
# 输入参数
batch_size = 1
seq_len = 16
embed_dim = 1024 # 嵌入维度
num_heads = 32 # 多头注意力头数
head_dim = embed_dim // num_heads
# 输入张量 (batch_size, seq_len, embed_dim)
x = torch.randn(batch_size, seq_len, embed_dim)
# 有 bias 的 QKV 线性层
class Attention(nn.Module):
def __init__(self, embed_dim, q_bias=False, k_bias=False, v_bias=False):
super().__init__()
self.q = nn.Linear(embed_dim, embed_dim, bias=q_bias)
self.k = nn.Linear(embed_dim, embed_dim, bias=k_bias)
self.v = nn.Linear(embed_dim, embed_dim, bias=v_bias)
def forward(self, x):
B, N, C = x.shape
q = self.q(x).reshape(B, N, num_heads, head_dim).transpose(1, 2)
k = self.k(x).reshape(B, N, num_heads, head_dim).transpose(1, 2)
v = self.v(x).reshape(B, N, num_heads, head_dim).transpose(1, 2)
attn = (q @ k.transpose(-2, -1)) * (1.0 / (head_dim**0.5))
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
return x, attn
# 初始化模型
model_no_bias = Attention(embed_dim, q_bias=False, k_bias=False, v_bias=False)
model_with_bias = Attention(embed_dim, q_bias=False, k_bias=True, v_bias=False)
model_with_bias.q.weight.data = model_no_bias.q.weight.data
model_with_bias.k.weight.data = model_no_bias.k.weight.data
model_with_bias.v.weight.data = model_no_bias.v.weight.data
# 推理
out_no_bias, attn_no_bias = model_no_bias(x)
out_with_bias, attn_with_bias = model_with_bias(x)
# 比较差异
diff_output = torch.abs(out_no_bias - out_with_bias).mean()
diff_variance = torch.abs(out_no_bias - out_with_bias).var()
diff_attn = torch.abs(attn_no_bias - attn_with_bias).mean()
print("\nMean difference in output:", diff_output.item())
print("Mean difference in variance:", diff_variance.item())
print("Mean difference in attention weights:", diff_attn.item())
# Mean difference in output: 1.2734082233123445e-08
# Mean difference in variance: 1.7173628739783402e-16
# Mean difference in attention weights: 3.949708116124384e-09
- Namazifar, M., Hazarika, D., & Hakkani-Tur, D. (2023). Role of Bias Terms in Dot-Product Attention. https://arxiv.org/abs/2302.08626
- Yun, C., Bhojanapalli, S., Rawat, A. S., Reddi, S., & Kumar, S. (2020). Are Transformers universal approximators of sequence-to-sequence functions? International Conference on Learning Representations. https://openreview.net/forum?id=ByxRM0Ntvr back: 1, 2
Multi-Query Attention (MQA)
Google 在 2019 年提出了 multi-query attention (MQA) (Shazeer, 2019), 用于解决 MQA 内存带宽瓶颈问题。
MQA 的做法就是第二种,也就是降低 和 的大小,但是 分别是 key 和 value layer 的输出,要降低输出大小,我们就必须改变 key 和 value layer 的 size。基于这个考虑,作者在所有的 head 上共享了一个 key 和 value layer,也就是说,原来
self.k_proj = nn.Linear(hidden_size, num_heads * head_dim) # (d, n*d_h)
self.v_proj = nn.Linear(hidden_size, num_heads * head_dim) # (d, n*d_h)
现在在 MQA 里,其变成了
self.k_proj = nn.Linear(hidden_size, head_dim) # (d, n*d_h)
self.v_proj = nn.Linear(hidden_size, head_dim) # (d, n*d_h)
Analysis
我们还是在 token-by-token 的场景下进行分析。
我们整体的 arithmetic operations 还是 .
调用 次 multi-query attention 的总的内存访问量为 , 第一项是 , 第二项是 和 , 第三项是是 query, key 和 value layer 的权重。
此时,MAR 变成了
现在,我们就将 这一项给降低了 倍。如果我们的 batch size 足够大的话,理论上 MQA 应该能极大提高整体的计算效率。
MQA 通过在所有的 heads 中共享 key 和 value 来实现降低 kv cache 的作用,在 MQA 中,, 在计算时,对应的 和 通过广播机制参与 attention 的计算。此时,KV cache 占用为 MHA 的 , 即 .
- Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need. https://arxiv.org/abs/1911.02150
GQA
Multi-head attention (MHA) 的问题在于 inference 阶段,每次 decoding,都需要重新加载 attention 模块中 query layer, key layer 和 value layer 的权重,而加载权重会受带宽限制。
已有的工作有 MQA (Shazeer, 2019), 也就是我们把多个 head 的 key layer 以及 value layer 压缩成一个,这样对于 个 head 的 attention,我们有 个 query layer, 个 key layer 以及 1 个 value layer. 但是 MQA 的问题在于其会导致性能下降,而且训练过程会不稳定。
因此,在本文中作者就提出了Group Query Attention (GQA) (Ainslie et al., 2023),一个在保持模型性能的同时,提高计算效率的注意力机制,作者还介绍了如何将一个 MHA 模型转化为一个一个 MQA 模型。
Uptraining
将 MHA 模型转化为 MQA 模型分为两步:
- 将 MHA 权重转化为 MQA 权重
- 额外的预训练
具体来讲,作者使用了一个 mean pooling 的方法,来将不同 head 的 query layer 以及 key layer 的权重转化为 MQA 对应 layer 的权重。然后作者 pre-training 若干步来让模型适应新的结构。
GQA
GQA 的思路在于在 MHA 和 MQA 之间达到一个平衡,也就是说我们将 key layer 和 value layer 进行分组,每个组内共享一个 key layer 和 value layer, 我们假设有 个 head, 个 group,那么
- 时,所有的 head 共享一个 key layer 和一个 value layer, 此时 GQA 等价于 MQA
- 时,每个 head 都有一个 key layer 和一个 value layer, 此时 GQA 等价于 MHA
- 时,GQA 时 MQA 和 MHA 的一个 trade-off,兼顾两者的性能与效率
三者的示意图如下所示

Code
MQA 的代码也比较好理解,我们首先定义 group size,即 num_key_value_heads, 然后基于 group size 定义对应的 key layer self.k_proj 和 value layer self.v_proj.
计算得到 key_states 和 value_states 之后,在计算 attention,即 eager_attention_forward 的时候,我们对 key_states 和 value_states 进行复制,即 repeat_kv
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
def eager_attention_forward(
module: nn.Module,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
attention_mask: Optional[torch.Tensor],
scaling: float,
dropout: float = 0.0,
**kwargs: Unpack[TransformersKwargs],
):
key_states = repeat_kv(key, module.num_key_value_groups)
value_states = repeat_kv(value, module.num_key_value_groups)
attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
if attention_mask is not None:
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
attn_weights = attn_weights + causal_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
return attn_output, attn_weights
class Qwen3Attention(nn.Module):
def __init__(self, config: Qwen3Config, layer_idx: int):
super().__init__()
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
self.scaling = self.head_dim**-0.5
self.q_proj = nn.Linear(
config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
)
self.k_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.v_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.o_proj = nn.Linear(
config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
)
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_value: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states = self.q_norm(self.q_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
attn_output, attn_weights = eager_attention_forward(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0,
scaling=self.scaling,
sliding_window=self.sliding_window, # diff with Llama
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights
MQA 的问题是表达能力太弱(表现差),因此后续 GQA 进行了改进,GQA 在 MQA 和 MHA 之间进行了权衡,即将 heads 分为若干个 group, 每个 group 中共享 key 和 value, 即 , 这里 是 group 个数,在计算 attention 时,key 和 value 在 group 内部共享,此时,GQA 的 KV cache 占用是 MQA 的 倍,即 .
- Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebron, F., & Sanghai, S. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. The 2023 Conference on Empirical Methods in Natural Language Processing. https://openreview.net/forum?id=hmOwOZWzYE
- Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need. https://arxiv.org/abs/1911.02150
Dual Chunk Attention (DCA)
提升 LLM 上下文长度的方法可以分为两类:一类是 training-free 的,包括 LM-infinite 和 StreamingLLM 等,这些方法以损失 long range dependency 为代价来保持较低的 perplexity。 另一类为了保留全局信息,则是通过外插来扩展模型的上下文,如 YaRN (Peng et al., 2026).
第二类方法的问题在于,其依赖训练,在 training-free 的 setting 下,这些方法也会导致 perplexity 的上升
因此,在本文中,作者就提出了 Dual Chunk Attention (DCA) (An et al., 2024),一个无需训练的,扩展 LLM 上下文长度的方法。DCA 的主要做法是将 attention 的计算进行分块,这样就可以提高计算效率。
通过实验,作者给出了三点关键发现:
- Extrapolation: DCA 可以在无需训练的情况下,将 LLM 的上下文提升到 32K,而不导致 Perplexity 大幅度增加
- Orthogonality: DCA 可以和其他方法一起使用,如 YaRN (Peng et al., 2026), 这一点已经在 Qwen2.5-1M 以及 Qwen3 中得到了应用
- Long Context Understanding: DCA 可以在无需训练的情况下,在长上下文设置下,达到已有 SOTA 模型的表现
Preliminary
对于一个长度为 的 token 序列,我们首先定义对应的 position id 如下
然后,对于第 个位置和第 个位置的 token,其 attention score 定义为:
具体细节参考 Position Encoding 中的 RoPE 部分介绍。这里面的关键在于,最后的结果只与相对位置 相关,而与绝对位置 和 无关。因此,我们可以用一个相对位置矩阵 来表示这个信息,其中 代表了第 个位置的 query 和第 个位置的 key 的相对位置信息,其示意图如下所示

原始版本的 RoPE 的问题在于,在训练时,模型没有见过更长的上下文,因此其泛化性也最差,这一点在 YaRN (Peng et al., 2026) 已经得到了验证
Method
DCA 的关键在于将 sequence 分割为若干个 Chunk,然后将 attention 的计算拆分为三个部分:
- intra-chunk:负责计算每个 chunk 内部的 attention
- inter-chunk :负责计算 chunk 之间的 attention
- successive-chunk:负责计算相邻两个 chunk 之间的 attention
为了更好理解 DCA,我们接下来假设 , 这时我们有
Intra-Chunk Attention
我们首先定义个超参数 chunk size , 然后我们将我们的 sequence 分割成 个 chunk,然后每个 chunk 重新进行编号,就得到了如下的 position id
接下来,我们定义 intra-chunk 的相对位置矩阵 , 此时,我们仅在每个 chunk 内部进行计算 attention,即
在上面的例子中,假设 , 那么我们新的 position id 就变成了
对其进行可视化,我们就得到

Inter-Chunk Attention
接下来,我们来看一下不同 chunk 之间如何计算彼此的 attention。在 Intra-chunk attention 计算中,我们忽略了跨 chunk 的信息,而且,由于现在的 position id 不再是单调递增的了,我们直接使用 和 给出的位置信息不对,这也是为什么我们在 Intra-chunk attention 中要求 query 和 key 在同一个 chunk 中才能计算的原因。
为了解决这个问题,作者构建了一个新的 position id。首先我们引入一个新的超参数 , 代表了模型预训练时的上下文长度,如 4096。
接下来,基于 , 我们定义新的 position id 如下:
注:这里的 指的是某一个 chunk 中的 position id,每个 chunk 中的 position id 都相同,请参考例子理解,后面不再赘述。
也就是说,在计算跨 chunk 的 attention 的时候,我们直接把 query 的 position id 设置为最大值,然后 key 的 position id 依然使用 intra-chunk 的位置信息。由于 , 因此我们有
最后,我们对于 inter chunk 的位置矩阵 定义如下:
在上面的例子中,当 时,, 我们有
对其进行可视化,得到

Successive-Chunk Attention
现在我们既可以计算 intra-chunk,也可以计算 inter-block 的 attention,但是问题是对于相邻的 chunk,其位置信息不对了,从上面的可视化中,我们可以看到,当 , 时,我们有
也就是说,inter-block 的 attention 会破坏原有的相对位置信息,因此我们就通过 successive chunk attention 来解决这个问题,使得 .
作者发现,这个问题不是所有的 chunk 都有,而是只存在于相邻的 chunk 中,因此,作者又加入了一个超参数 代表了 local window size,我们可以直接将其设置为 , 通过这个 local window,我们调整对应的 position id 如下:
对于 successive chunk 的位置矩阵 定义如下:
在上面的例子中,我们设置 , 就得到
对其进行可视化,得到

Computation
接下来,我们把所有的改进放在一起,就得到
基于上面的位置矩阵 , 我们再依次计算对应的 attention score
Code
首先是 RotaryEmbedding 部分的修改
class DCARotaryEmbedding(nn.Module):
def __init__(self, max_len, chunk_size, local_window):
self.max_len = max_len
self.chunk_size = chunk_size
self.local_window = local_window
self.inv_freq = ...
def forward(self, x):
q_t = torch.arange(self.chunk_size)
qc_t = (q_t + self.chunk_size).clamp(max=self.chunk_size)
k_t = torch.arange(seq_len) % self.chunk_size
q_freqs = torch.outer(q_t, self.inv_freq) # seq_len x dim/2
qc_freqs = torch.outer(qc_t, self.inv_freq)
k_freqs = torch.outer(k_t, self.inv_freq) # seq_len x dim/2
q_emb = torch.cat((q_freqs, q_freqs), dim=-1) # seq_len x dim
qc_emb = torch.cat((qc_freqs, qc_freqs), dim=-1)
k_emb = torch.cat((k_freqs, k_freqs), dim=-1) # seq_len x dim
# compute related sin, cos
return q_sin, q_cos, qc_sin, qc_cos, k_sin, k_cos
attention 计算时的逻辑
class Attention(nn.Module):
def forward(...):
key_states = apply_rotary_pos_emb(key_states, k_cos, k_sin, position_ids)
q_states_intra = apply_rotary_pos_emb(query_states[:, :, :chunk_len, :], q_cos, q_sin,
position_ids[:, :chunk_len])
k_states_prev = key_states[:, :, :chunk_len, :]
v_states_prev = value_states[:, :, :chunk_len, :]
# first chunk
flash_result = do_flash_attn(q_states_intra, k_states_prev, v_states_prev)
flash_results.append(flash_result)
remain_len = kv_seq_len - chunk_len
while remain_len > 0:
flash_per_chunk = []
begin = kv_seq_len - remain_len
curr_chunk_len = min(chunk_len, remain_len)
end = begin + curr_chunk_len
# current chunk, intra-chunk attention
q_states_intra = apply_rotary_pos_emb(query_states[:, :, begin:end, :], q_cos, q_sin,
position_ids[:, begin:end])
k_states_intra = key_states[:, :, begin:end, :]
v_states_intra = value_states[:, :, begin:end, :]
flash_result = do_flash_attn(q_states_intra, k_states_intra, v_states_intra)
flash_per_chunk.append(flash_result)
# successive chunk attention
q_states_succ = apply_rotary_pos_emb(query_states[:, :, begin:end, :], qc_cos, qc_sin,
position_ids[:, begin:end])
flash_result = do_flash_attn(q_states_succ, k_states_prev, v_states_prev, False)
flash_per_chunk.append(flash_result)
# inter chunk attention
if begin - (k_states_prev.size(-2)) > 0:
prev_len = k_states_prev.size(-2)
q_states_inter = apply_rotary_pos_emb(query_states[:, :, begin:end, :], qc_cos, qc_sin,
position_ids[:, chunk_len - 1][:, None].repeat(1, curr_chunk_len))
k_states_inter = key_states[:, :, :begin - prev_len, :]
v_states_inter = value_states[:, :, :begin - prev_len, :]
flash_result = do_flash_attn(q_states_inter, k_states_inter, v_states_inter, False)
flash_per_chunk.append(flash_result)
flash_results.append(flash_per_chunk)
k_states_prev = k_states_intra
v_states_prev = v_states_intra
remain_len = remain_len - chunk_len
# merge the final results
attn_output = merge_attn_outputs(flash_results)
Evaluation

作者还分析了一下 DCA 的效率,结果如下

可以看到,在 flash attention (Dao et al., 2022) 的基础上加上 DCA 之后,内存占用和推理时间并没有发生太大变化
作者还分析了三种 attention 对结果的贡献,如下图所示

结果显示,intra block 的 perplexity 是最低的,但是其在下游任务上表现是最差的。当三者结合在一起之后,perplexity 和下游任务上的表现都是最好的。
- An, C., Huang, F., Zhang, J., Gong, S., Qiu, X., Zhou, C., & Kong, L. (2024). Training-Free Long-Context Scaling of Large Language Models. https://arxiv.org/abs/2402.17463
- Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Re, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In A. H. Oh, A. Agarwal, D. Belgrave, & K. Cho (Eds.), Advances in Neural Information Processing Systems. https://openreview.net/forum?id=H4DqfPSibmx
- Peng, B., Quesnelle, J., Fan, H., & Shippole, E. (2026). YaRN: Efficient Context Window Extension of Large Language Models. https://arxiv.org/abs/2309.00071 back: 1, 2, 3
Multi-head Latent Attention (MLA)
传统的 multi head attention (MHA) 虽然效果好,但是在 inference 时,其 KV cache 会变成瓶颈,影响推理效率。 为了解决这个问题,已有的工作如 MQA (Shazeer, 2019) 和 GQA (Ainslie et al., 2023) 通过共享权重来减少 KV cache 内存占用,但是结果发现模型的表现也会降低。
为了解决这个问题,作者提出了 multi-head latent attention (MLA) (DeepSeek-AI et al., 2024), 来压缩推理时 KV cache 占用.
Method
MLA 的架构图如下所示

MLA 使用 low-rank joint compression 来压缩 key 以及 value 的 KV cache:
这里 为 key 以及 value 压缩后的 latent vector. 为 KV cache compression dimension. 为 down projection matrix, 这个矩阵是 key 和 value 共享的, 为 key, value 对应的 up projection matrix.
另外,为了减少训练时的 activation memory, 作者对于 query 同样也执行了 low-rank compression, 压缩方式如下
其中 为 query 压缩后的 latent vector, 为 query compression dimension, , 分别时 down projection, up projection matrix.
最后 attention 的计算与 MHA 保持一致:
在推理的时候,我们只需要缓存 即可,这样每个 token 的 KV cache 为 .
并且在 inference 时,我们可以将 和 融合在一起,将 和 融合在一起,也就是说我们不需要显式的计算出 以及 , 即
以及
这里 , , , .
Decoupled Position Embedding
接下来,作者介绍了如何解决 RoPE 不相容的问题。如果说我们直接在 上进行 RoPE, 那么我们有
此时,我们没有办法将 吸收到 中,这样就导致在 inference 时我们必须重新计算所有 prefix token 对应的 key, 这显然会降低 inference efficiency
为了解决这个问题,作者使用了partial RoPE的技巧,即将query和key拆解为NoPE以及RoPE两部分,前者由MLA产生,后者携带位置信息。 RoPE部分包括query 以及一个共享的 key , 其中 是 decoupled query 以及 decoupled key 的 head dimension.
[!remark] 这里 key 对应的 RoPE 共享的原因是这部分信息也需要使用 KV cache 进行缓存,通过共享可以降低 KV cache 占用; 而 query 对应的 RoPE 不共享的原因是提高 head 的表达能力,与 MHA 原理一致。
对应 MLA 的计算公式如下
其中 , , . 只执行 RoPE 矩阵乘法的操作。
在这种情形下,attention 的计算如下所示
可以看到,现在 attention 的计算分为了两部分,一部分是 MLA 自身的计算,这部分计算前面已经证明可以通过矩阵吸收的方式来进行优化,第二部分是关于 RoPE 部分的计算,这部分计算量不是很大
最终,MLA 完整的计算公式如下
在 inference 时,decoupled key 也需要被缓存,因此 DeepSeek-V2 每个 token 所需要的 KV cache 为 , 框选的部分即为 Inference 阶段需要缓存的内容
MLA 与 MHA, MQA, GQA 的对比如下图所示
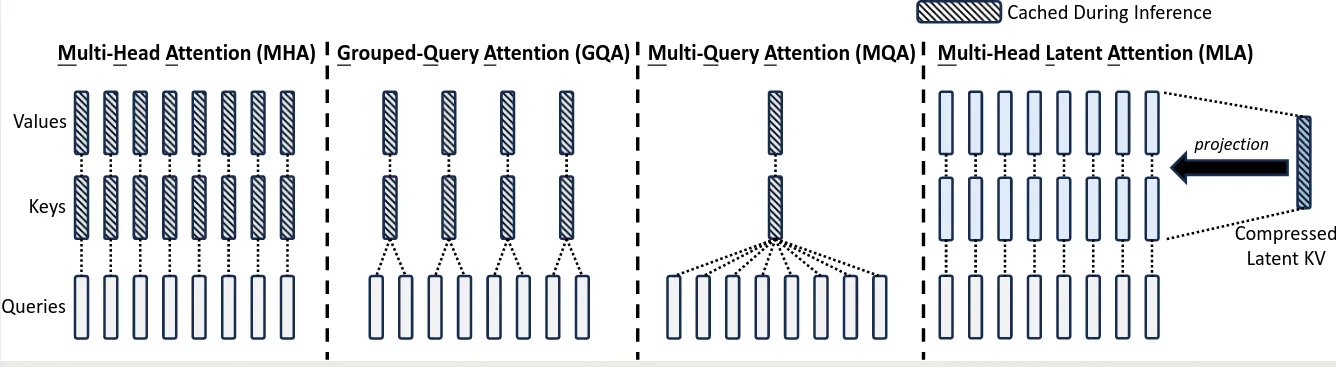
Comparison of KV Cache
接下来,作者对比了不同 attention 机制的 KV cache, 结果如下表所示
| Attention Mechanism | KV Cache per Token (# Element) | Capability |
|---|---|---|
| Multi-Head Attention (MHA) | Strong | |
| Grouped-Query Attention (GQA) | Moderate | |
| Multi-Query Attention (MQA) | Weak | |
| MLA (Ours) | Stronger |
这里作者将 设置为 , 设置为 , 因此得到了上面的 的近似。与 GQA 相比,相当于 MLA 使用了 2.25 个 group, 但是可以得到更强的效果。
为了避免 low-rank compression 以及 fine-grained expert segmentation 对输出的 scale 产生影响,作者对 compressed latent vectors 进行了 normalization.
Code
首先是代码变量与公式变量的对应关系
| code name | variable name | Value |
|---|---|---|
hidden_size | 5120 | |
kv_lora_rank | 512 | |
q_lora_rank | 1536 | |
qk_nope_head_dim | 128 | |
qk_rope_head_dim | 64 | |
v_head_dim | 128 | |
num_attention_heads | 128 |
在具体实现时,作者对计算过程进行了优化,具体就是先合并计算然后通过 split 进行拆分,这部分策略应用于三个部分:
代码如下所示
class DeepseekV2Attention(nn.Module):
def __init__(self, config, layer_idx):
# d_h + d_h^R
self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
# W^{DQ}
self.q_a_proj = nn.Linear(
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
)
# [W^{UQ}; W^{QR}]
self.q_b_proj = nn.Linear(
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False)
# [W^{DKV}; W^{KR}]
self.kv_a_proj_with_mqa = nn.Linear(self.hidden_size, config.kv_lora_rank + config.qk_rope_head_dim, bias=config.attention_bias)
# [W^{UK}; W^{UV}]
self.kv_b_proj = nn.Linear(config.kv_lora_rank, self.num_heads * (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim), bias=False)
# W^O
self.o_proj = nn.Linear(self.num_heads * self.v_head_dim, self.hidden_size, bias=config.attention_bias)
def forward(self, hidden_states, ...):
# [q_t^c; q_t^R]
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
# [c_t^{KV}; k_t^R]
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
compressed_kv, k_pe = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
# [k_t^c; v_t^c]
kv = (self.kv_b_proj(self.kv_a_layernorm(compressed_kv)).view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim).transpose(1, 2))
k_nope, value_states = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
# q_t^R, k_t^R
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
# q_{t, i}
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
# k_{t, i}
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
# Q^TK
attn_weights = (torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale)
# softmax(...) in FP32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
# o_{t, i}
attn_output = torch.matmul(attn_weights, value_states)
# u_t
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights, past_key_value
参数量计算
首先,我们结合 DeepSeek-V2 的 config 计算一下 MLA 部分的参数量:
| Matrix | Parameters | values | ratio |
|---|---|---|---|
| 2621440 | 1.91% | ||
| 8388608 | 6.12% | ||
| 8388608 | 6.12% | ||
| 7864320 | 5.74% | ||
| 25165824 | 18.37% | ||
| 327680 | 0.24% | ||
| 327680 | 0.24% | ||
| 83886080 | 61.24% | ||
| Total | 136970240 | 100% |
我们接下来对比一下各个模型架构之间 attention 部分的参数量,可以看到与 MHA 一致,大部分参数量都集中在最后的 Output projection layer 上
Experiments
作者首先对比了 MHA, GQA, MQA 的表现,作者基于一个 7B 的 dense 模型,使用 1.33T token 进行训练,实验结果如下
| Benchmark (Metric) | # Shots | MQA | GQA(8 Groups) | MHA |
|---|---|---|---|---|
| # Params | - | 7.1B | 6.9B | 6.9B |
| BBH (EM) | 3-shot | 33.2 | 35.6 | 37.0 |
| MMLU (Acc.) | 5-shot | 37.9 | 41.2 | 45.2 |
| C-Eval (Acc.) | 5-shot | 30.0 | 37.7 | 42.9 |
| CMMLU (Acc.) | 5-shot | 34.6 | 38.4 | 43.5 |
实验结果显示,MHA 的表现显著优于 GQA 和 MQA. 这说明了 MQA 和 GQA 虽然减少了 KV cache 的占用,但是相应地,它们对应的表现也有所降低。
接下来,作者对比了 MLA 和 MHA 的表现,实验结果如下
| Benchmark (Metric) | # Shots | MHA | MLA | MHA | MLA |
|---|---|---|---|---|---|
| # Activated Params | - | 2.5B | 2.4B | 25.0B | 21.5B |
| # Total Params | - | 15.8B | 15.7B | 250.8B | 247.4B |
| KV Cache per Token (# Element) | - | 110.6K | 15.6K | 860.2K | 34.6K |
| BBH (EM) | 3-shot | 37.9 | 39.0 | 46.6 | 50.7 |
| MMLU (Acc.) | 5-shot | 48.7 | 50.0 | 57.5 | 59.0 |
| C-Eval (Acc.) | 5-shot | 51.6 | 50.9 | 57.9 | 59.2 |
| CMMLU (Acc.) | 5-shot | 52.3 | 53.4 | 60.7 | 62.5 |
可以看到,MLA 的表现比 MHA 的表现更好,并且 KV cache 也更少。
对比不同模型的 KV cache 占用 (Zhao et al., 2025)
| Model | Parameters | Attention | KV cache per token | Multiplier |
|---|---|---|---|---|
| DeepSeek-V3 | 671B | MLA | 70.272 KB | 1x |
| Qwen-2.5 | 72B | GQA | 327.680 KB | 4.66x |
| LLaMA-3.2 | 405B | GQA | 516.096 KB | 7.28x |
- Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebron, F., & Sanghai, S. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. The 2023 Conference on Empirical Methods in Natural Language Processing. https://openreview.net/forum?id=hmOwOZWzYE
- DeepSeek-AI, Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Ji, D., Li, E., Lin, F., Luo, F., Hao, G., Chen, G., … Xie, Z. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. https://arxiv.org/abs/2405.04434
- Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need. https://arxiv.org/abs/1911.02150
- Zhao, C., Deng, C., Ruan, C., Dai, D., Gao, H., Li, J., Zhang, L., Huang, P., Zhou, S., Ma, S., Liang, W., He, Y., Wang, Y., Liu, Y., & Wei, Y. X. (2025, June). Insights into DeepSeek-V3: scaling challenges and reflections on hardware for AI architectures. Proceedings of the 52nd Annual International Symposium on Computer Architecture. 10.1145/3695053.3731412
Multi-matrix Factorization Attention (MFA)
multi-head attention (MHA) 的问题在于,其 KV cache 的内存占用(memory footprint)随 sequence length 以及 batch size 线性增长,从而成为了 LLM 在 decoding 阶段的瓶颈。
为了解决 MHA 的内存占用过高问题,已有的工作如 MQA (Shazeer, 2019), GQA (Ainslie et al., 2023) 等通过共享 key, value projection 来降低 KV cache size. 而 DeepSeek-V3 提出的 MLA 则是通过对 key, value projection 进行 low-rank compression, 然后只存储 latents 的方法来降低 KV cache size.
但是,已有的这些方法的问题在于,当我们设置 KV cache budget 之后,它们的表现就比标准的 MHA 要差。
基于以上这些发现,作者首先分析了已有 attention 机制的 modeling capacity, 然后使用一个统一的框架来表示这些 attention 机制。作者发现,attention heads 的个数以及 dimension 对模型表现有较大影响。
基于这个发现,作者提出了 Multi-matrix Factorization Attention (MFA) (Hu et al., 2025), 以及其变体 MFA-Key-Reuse (MFA-KR). MFA 的主要目的是在有限的 KV cache size 下提高模型的表现。
Background
作者首先介绍了 GMHA 的概念,GMHA 由三部分组成:
- QK circuit: 决定了信息之间如何交互
- valueoutput (VO) circuits:决定了信息如何传递
- per-head softmax attention.
接下来,作者介绍了 Fully Parameterized Bilinear Attention (FPBA), FPBA 的定义如下:
其中 是 softmax 函数, 是模型的 hidden dimension, 是 sequence length, 每个 channel 上的参数矩阵
- 每个 channel 都有各自的参数 来获取 与 之间的信息
- 提高泛化性,所有 channel 的 组合起来可以遍历 维空间中的任意一个 permutation, 这样就避免来的信息损失
- 利用率高,FPBA 获取了 与 之间 维空间可能的表示
基于以上这三个特点,作者认为 FPBA 是 GMHA 框架的一个 capacity upper bound. 此时每个 token 的 KV cache 占用为 (key and value).
然后,作者分析了 MHA 及其变体与 GMHA 的关系,MHA 可以写作如下形式
其中 , 分别是 query, key, value, output projection layer 对应的权重矩阵, 是 attention head 的个数,令 为每个 attention 的 head dimension,则我们有 .
可以看到,MHA 实际上是一个特殊的 FPBA, 其中, 和 分别由秩为 的低秩分解 以及 近似。此时每个 token 的 KV cache 占用为 (key and value).
MQA 可以看作是 GQA 的一个特殊情况。对于 GQA 来说,我们有一个 group size , 当 时,GQA 就是 MHA. 当 时,GQA 就是 MQA, 通常 满足 . GQA 的表达式与 MHA 基本相同,只是多个 head 会共享一个 以及 . 此时,每个 token 的 KV cache 占用为 . 对于 MQA,其每个 token 的 KV cache 占用为 .
对于 MLA, 其表达式如下所示
其中, 在所有的 heads 中是共享的, 是每个 head 的 query, key, value projection layer 的参数, 是 latent factorization 的维度。与 FPBA 相比,我们可以看到,MLA 实际上是在 个 head 上共享了参数,其中, 和 分别由秩为 的低秩分解 以及 近似。尽管模型中 , 但是最终的 rank 仍然是 , 因此模型的表现也就受到了限制。
Method
对已有的 attention 分析之后,作者认为,要提高模型的表现,attention 需要做到亮点:
- 最小化 KV cache 占用和参数量
- attention 的 capacity 尽可能接近 FPBA
基于这两个原则,作者提出了 MFA, MFA 主要依赖三个策略:
- 提升 attention heads 的 head dimension, 通过提高 head dimension, 我们可以有效提高 attention head 的表达能力
- 使用矩阵分解来降低参数量
- 使用单一的 KV head 来降低 KV cache 内存占用
最终,MFA 的表达式如下所示
其中 是所有的 attention head 所共享的, 是每个 head 的 query up projection 和 output projection, 是 latent factorization 的维度。
在 inference 的时候,由于我们只需要保存 和 , 因此所需要的 KV cache size 为 . 与 FPBA 相比,MFA 分别使用 和 来近似 和 , 近似矩阵的 rank 为 . 由于 , 因此其表达能力也更强,MFA 有如下优势:
- scalable head count: MFA 可以支持使用更多的 attention heads, 每增加一个 heads, 所需要的额外参数为 . 并且,增加 attention heads 个数不会增加 KV cache 占用
- enhanced head expressiveness: MFA 近似矩阵的 rank 为 , 因此表达能力更强
- Compatibility with position encodings: MFA 可以无缝集成 position encoding.
为了进一步降低 MFA 的 KV cache 占用,作者提出了 MFA-Key-Reuse (MFA-KA). 核心思想是使用 来表示 , 这样可以额外降低 的 KV cache 占用,表示方法如下所示
其中 , .
最终,MFA, MFA-KR 与 GQA 的对比如下图所示

不同 attention 的量化对比如下表所示
| Method | KV Cache | Parameter | Heads | Factor. rank per head | Shared latent subspace Dim. | Total effec. rank |
|---|---|---|---|---|---|---|
| FPBA | ||||||
| MHA | ||||||
| MQA | ||||||
| GQA | ||||||
| MLA | ||||||
| MFA |
Code
class Step3vAttention(nn.Module):
def __init__(self, config: Step3VLConfig, layer_idx):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
self.num_key_value_heads = 1
self.total_num_kv_heads = self.num_key_value_heads
self.num_attention_heads = config.num_attention_heads
self.num_key_value_groups = config.num_attention_heads // self.num_key_value_heads
self.q_size = getattr(config, "share_q_dim", self.head_dim)
self.kv_size = self.num_key_value_heads * self.head_dim
self.scaling = self.head_dim**-0.5
self.is_causal = True
self.q_proj = nn.Linear(config.hidden_size, self.q_size , bias=False)
self.k_proj = nn.Linear(config.hidden_size, self.head_dim, bias=False)
self.v_proj = nn.Linear(config.hidden_size, self.head_dim, bias=False)
self.o_proj = nn.Linear(config.num_attention_heads * self.head_dim, config.hidden_size, bias=False)
# query down projection normalization
self.inter_norm = Step3vRMSNorm(self.q_size, eps=config.rms_norm_eps)
# query up projection
self.wq = nn.Linear(self.q_size, self.head_dim * self.num_attention_heads, bias=False)
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: Tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_value: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
input_shape = hidden_states.shape[:-1]
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states).view((*input_shape, -1, self.head_dim)).transpose(1, 2)
value_states = self.v_proj(hidden_states).view((*input_shape, -1, self.head_dim)).transpose(1, 2)
query_states = self.inter_norm(query_states)
query_states = self.wq(query_states).view((*input_shape, -1, self.head_dim)).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
...
- Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebron, F., & Sanghai, S. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. The 2023 Conference on Empirical Methods in Natural Language Processing. https://openreview.net/forum?id=hmOwOZWzYE
- Hu, J., Li, H., Zhang, Y., Wang, Z., Zhou, S., Zhang, X., Shum, H.-Y., & Jiang, D. (2025). Multi-matrix Factorization Attention. https://arxiv.org/abs/2412.19255
- Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need. https://arxiv.org/abs/1911.02150
Natively trainable Sparse Attention (NSA)
现有的大模型主要是基于 Transformer 提出的 softmax attention, 其主要问题在于随上下文长度增加,其 latency 也上升更快。 理论估计,对于 64k 上下文长度的输出,softmax attention 部分的计算占 的 latency.
为了解决 softmax 的 high latency 问题,一个做法就是使用稀疏注意力机制,如 MInference 等,但是这些系数注意力机制大多没有实际部署,且它们一般只在 inference 阶段使用
作者认为解决这个问题有两个挑战:
- Hardware-aligned inference speedup: 降低 inference latency 需要算法与硬件结合,不能只关注算法层面的改进
- Training-aware algorithm design: 需要在训练阶段也支持算法,从而可以降低训练的算力消耗并且保持模型的表现
为了解决这两个问题,作者就提出了 natively trainable sparse attention (NSA) (Yuan et al., 2025). NSA 通过将 key 和 value 分割为不同的 block, 然后基于三种 path: compressed coarse-grained tokens, selectively retrained fine-grained tokens 以及 sliding windows for local contextual information 来进行处理和过滤。NSA 提出了两点观点改进:
- Hardware-aligned system: 优化了 blockwise sparse attention 来平衡 arithmetic intensity.
- Training-aware design: 支持端到端的训练和部署
Method
作者首先回顾了 attention 的定义如下:
其中 .
接下来是 Arithmetic Intensity. Arithmetic intensity 指的是 FLOPs 与内存访问次数之比。由于现在的 GPU 都是计算密集型设备,理想情况下应该是 Arithmetic intensity 越高越好。
对于 causal self-attention 来说,在训练以及 prefilling 阶段,由于 batch 较大,因此整体的 Arithmetic intensity 较高,因而这两个阶段是 computer-bound. 但是在 decoding 阶段,由于其 token-by-token generation 的性质,每次生成新的 token 时都需要重新加载 KV cache, 因而是 memory-bound.
从而我们的优化目标也变得不一致:在训练阶段,我们希望降低计算消耗,而在推理 (decodng) 阶段,我们希望降低内存访问次数。
基于这两个目标,作者提出了使用 的子集 来参与计算,其对应的 attention 如下所示
我们还可以结合不同的方法来进行组合:
作者在本文中使用了三种方法 , 分别代表了 compression, selection 以及 sliding window, 代表了不同方法对应的 gating score, 类似于 MoE 的 gating layer, 由一个 MLP 和一个 sigmoid activation 生成。最终 NSA 的架构如下图所示

作者定义 代表参与计算的 KV 的总个数:
作者使用了一个较高的 sparsity ratio 来保证 .
NSA Design
接下来作者分别介绍了每一部分的设计
Token Compression
对于 token compression, 其定义如下:
其中 是 block size, 是 sliding stride, 是一个 MLP 用于将 block key 映射为一个单一的 key. 对于 作者也使用了类似的做法。
Token Selection
仅使用 compressed token 的话,可能会丢失一些细粒度的信息。因此,作者额外提出了 token selection 机制来解决这个问题。
作者使用的做法是 blockwise selection. 这样做的原因有两点:
- hardware efficiency. 这样做的原因是 GPU 访问内存是在 block 层面进行的,因而更加高效
- inherent distribution patterns of attention scores. MInference 证明了 attention score 在空间上存在连续性。即相邻的 key 对应的重要性非常相似
为了实现 block-wise selection, 作者首先将 key value sequences 分割为 blocks, 然后针对每个 blocks 分配 Importance score.
作者首先介绍了如何计算不同 block 的 importance score.
如果 selection block size 与 compression block size ,即 相同的话,则我们可以直接用 compression block 提供的信息:
其中 代表了 和 compressed key 之间的 attention score.
如果 的话,作者通过空间关系来进行计算,假设 , , , 则我们有
对于 GQA 和 MQA, 由于其 KV-cache 在 heads 之间共享,因此我们必须保证不同 heads 之间的 consistency, 因此作者提出了 shared importance score 如下:
接下来,对于每个 block 及其对应的 Importance score, 作者保存 top- sparse blcoks, 如下所示
其中 代表了降序排列的 importance scores. 是选择出来的 block indices, 表示了 concatenation operation. 代表了选择出来的 key.
Sliding Window
为了避免 local pattern 对 compression token 以及 selection token 的学习产生影响,作者额外使用了一个 branch 来学习这个 local pattern. 其具体做法就是维持一个 sliding window 用于最近的若干个 token, 即
这里 是 window size.
为了进一步避免 shortcut learning, 对于三个 branch 作者提供了不同的 key 和 values
Kernel Design
接下来是针对硬件设计进行的优化。由于 flash attention 2 (Dao, 2024) 对 compression attention 以及 sliding window attention 已经支持的比较好,作者这里介绍了如何针对 selection attention 进行优化。
Experiments
作者构建了一个 27B-A3B 的 MoE 模型,attention 基于 GQA, MoE 基于 DeepSeekMoE (Dai et al., 2024). 模型配置如下表所示
| field | value |
|---|---|
| layers | 30 |
| hidden dimension | 2560 |
| head groups | 4 |
| attention heads | 64 |
| query head dimension | 192 |
| value head dimension | 128 |
| routed experts | 72 |
| shared experts | 2 |
| activated experts | 6 |
| dense layers | 1 |
NSA 配置如下
| field | value |
|---|---|
| 32 | |
| 16 | |
| 64 | |
| 16 | |
| 512 |
其中 selection blocks 包含初始的一个 block 以及最近的 2 个 block.
模型先在 8K 的上下文长度下使用 270B token 进行预训练,接下来在使用 YARN 将模型上下文通过 continual pre-training 以及 SFT 扩展到 32K. 训练过程的损失如下图所示

作者从 general performance, long-context performance 以及 CoT reasoning performance 三个层面来评估 NSA 的表现。
首先是 NSA 与其他 sparse attention 以及 baseline 在通用任务上表现的对比,结果如下图所示

接下来是 NSA 在 LongBench 上的表现:

作者还使用了 DeepSeek-R1 中的知识蒸馏方法,结果如下表所示
| Generation token limit | 8192 | 16384 |
|---|---|---|
| Full Attention-R | 0.046 | 0.092 |
| NSA-R | 0.121 | 0.146 |
上面的结果均验证了 NSA 的有效性
Analysis
接下来,作者分析了 NSA 的性质。作者首先对比了 NSA 和 flash attention 2 (Dao, 2024) 的训练速度,结果如下图所示

可以看到,相比于 flash attention 2, NSA 在 forward 过程和 backward 过程的的效率分别提升了 9 倍和 6 倍。作者认为这是由于两个优点:
- NSA 使用了 block-wise memory access, 提高了 tensor core 的利用率
- loop scheduling 减少了 KV transfer 时的 kernel 冗余
作者还对比了不同 attention 的解码速度,在 NSA 中,每次只需要 个 token 就可以完成计算,作者对比不同 attention 所需余姚的 token 如下表所示如下表所示
| Context Length | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|
| Full attention | 8192 | 16384 | 32768 | 65536 |
| NSA | 2048 | 2560 | 3584 | 5632 |
| speedup | 4x | 6.4x | 9.1x | 11.6x |
- Dai, D., Deng, C., Zhao, C., Xu, R. X., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y., Xie, Z., Li, Y. K., Huang, P., Luo, F., Ruan, C., Sui, Z., & Liang, W. (2024). DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. https://arxiv.org/abs/2401.06066
- Dao, T. (2024). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=mZn2Xyh9Ec back: 1, 2
- Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., Xie, Z., Wei, Y., Wang, L., Xiao, Z., Wang, Y., Ruan, C., Zhang, M., Liang, W., & Zeng, W. (2025). Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). https://aclanthology.org/2025.acl-long.1126/
Gated Attention
现有的大部分模型都基于 Transformer 提出的 softmax attention (SDPA), 虽然也有相关的改进工作,但是主要集中于降低 attention 计算复杂度,提高 attention 在推理时的内存使用效率等。之前的工作提出了关于 attention 的两个问题:
- attention sink, 即模型的注意力会放在初始几个 token 上, 这限制了模型的上下文扩展能力
- massive activation, 少部分 token 的 hidden states 会非常大,这限制了模型的训练稳定性
在本文中,作者通过在 attention 中加入 gating 机制来探索 gating 对模型表现和训练稳定性的影响 (Qiu et al., 2026)。尽管 gating 并没有降低 attention 计算复杂度,但是 gating 提出了一个新的视角,即 sparity 与 attention sink 和 massive activation 息息相关,这为后面 sparse attention 的研究提供了 Insight.
作者发现,对 Multi head attention 的输出进行 head-specific gating 的效果最好,并且这种方式还可以提高训练稳定性,模型的表达能力和长上下文能力。作者还进一步分析了这种 gating 方式更好的原因,发现有两点:
- non-linearity: 通过 gating 可以有效提高 output projection layer 输入的秩,进而提高表达能力
- sparsity: gating 可以降低 massive activation 和 attention sink 的影响
作者最终推荐使用 element-wise SDPA gating 方式来进行训练
Related Work
作者主要介绍了 gating 和 attention sink 这两部分的工作。
gating 早在 LSTM 和 GRU 使其就得到了广泛的运用,在 transformer 之后,相关的现行注意力也有应用,比如 MiniMax-01 所使用的 Lightning Attention 等,但是这些工作没有系统性探究 gating 背后的机制。
第二部分是 attention sink, attention sink 现象由 StreamingLLM 提出, 即模型会将相当一部分注意力权重方开始开始的几个 token 上。而本文提出的 gating 机制可以缓解 attention sink 现象。
Method
首先是标准 MHA 定义:
这里 是 transformer layer pre-normalization 的输出(或者 attention block 的输入), 是 sequence length, 是 hidden size, 是 number of heads, 是 head dimension.
接下来,作者介绍了不同的 gating 策略。这里作者用同一的公式来进行表示
这里 是输入, 是 attention 的输入, 是可学习权重
Position 首先是位置,作者考虑了如下几种变体:
这里 是激活函数, 是激活函数的可学习参数,我们可以将其理解为一个 linear layer, 即当前模块的输出取决于输入 hidden sates 经过一个线性层和激活层之后的结果,相似的做法还有 MoE 中的 gating layer, NSA 中的 gating layer 等。对应的示意图如下所示

granularity 作者设计了不同粒度的 gating(假设输入为 ):
- head-shared: 不同 head 共享 gating score,
Y'[i,h,k]=gate[i,k]*Y[i,h,k] - head-wise: 同一个 head 共享 gating score,
Y'[i,h,:]=gate[i,h]*Y[i,h,:] - element-wise: 不同元素不共享 gating score,
Y'[i,h,k]=gate[i,h,k]*Y[i,h,k]
从 attention 的角度看,不同 head 本身就承担不同的语义子空间,如果强行共享 gating,会破坏这种分工。
format 作者还构建了 multiplication 和 addition 两种形式:
- multiplication:
- addition:
activation function 本文中作者使用了 SiLU 和 sigmoid 两种形式,即
Experiments
作者构建了三个模型进行实验,模型配置如下表所示
| Model | 1.7B-28 layers | 1.7B-48 layers | 15B-A2.4B MoE |
|---|---|---|---|
| Layers | 28 | 48 | 24 |
| query heads | 16 | 16 | 32 |
| key/value heads | 8 | 8 | 4 |
| head dim | 128 | 128 | 128 |
| tie embedding | yes | yes | no |
| QK normalization | yes | yes | yes |
| hidden size | 2048 | 1536 | 2048 |
| ffn hidden size | 6144 | 4608 | 768 |
| experts | - | - | 128 |
| top-K | - | - | 8 |
首先是不同 gating 方法对 MoE model 影响,结果如下图所示

结论如下:
- 对 SDPA 的输出 (G1) 或者 value (G2) 进行 gating 效果最好
- head-specific gating 效果更好
- multiplication 效果比 addition 效果更好
- sigmoid 效果比 SiLU 效果更好
总的来说,position 对最终结果提升最明显,其次是 granularity 和 activation function.
接下来是不同 gating 方法对 dense model 的影响,作者构建了两个 dense 模型,参数都是 1.7B, 这两个模型的 layers 和 FFN hidden size 不同(通过调整保持总参数一致)。作者对比了 G1 和 baseline 的表现, 结果如下图所示

结论验证了 gating 机制可以有效提高模型的表现。作者还发现使用 gating 之后,模型的训练也更加稳定,训练的损失变化曲线如下图所示

Analysis
首先,作者对 multi head attention 进行了重写,得到如下形式
也就是说, 和 可以吸收到一起,由于 , , 从而 . 对于 GQA 和 MQA, 最终的有效秩会进一步降低。
而使用本文提到的 G1 和 G2 gating 策略之后,我们相当于是通过非线性机制提高了上面的秩,进而解决了 softmax attention 表达能力不足的问题, 实际上,StepFun 的 MFA 也是类似的思想。下面是 G1 和 G2 做的改进:
通过 gating 的非线性机制,我们提高的矩阵的秩,进而提高了模型的表达能力,而 G5 提升有限的原因也在于此。实验结果如下图所示

可以看到,不同的 non-linearity 方法对模型表现都有提升,这验证了矩阵秩会影响模型表达能力的分析。
接下来,作者探究了 gating 机制对 attention score distribution 的影响,结果如下图所示

实验结果说明:
- 有效的 gating 机制对应的 attention score 是非常稀疏的
- head-specific sparsity 非常重要,当在不同的 head 共享 gating 时,模型表现会有所下降
- gating 必须与 query 相关,与 G2 先比,G1 的表现更好,这说明 gating score 更依赖于 query. 作者认为基于当前 query token 构建 gating, 可以有效过滤历史 token 的噪音信息
- non-sparse gating 效果比较差,作者构建了一个 non-sparse 版本的 sigmoid, 结果发现模型表现非常差,这说明了 attention score 应该是一个稀疏形式
通过前面的分析和实验结果,作者认为 gating 机制还可以缓解 attention sink 现象,作者对 baseline 以及 G1 两种方法的 attention 分布进行了可视化,结果如下图所示

实验结果整理如下表所示
| method | massive activation | attention sink |
|---|---|---|
| baseline | high | high |
| input-independence | high | high |
| head-shared gating | low | high |
| head-specific gating | low | low |
因此,作者的结论为,input-dependent, head-specific gating 可以提高 attention score distribution 的 sparsity, 进而减缓 attention sink. 并且引入 spaisity 之后,我们还可以避免 massive activation, 进而使用更低的精度进行训练。
最后,作者探究了以下 gating 机制的上下文扩展能力,作者在已有的模型上基于 32k 上下文长度使用了 80B token 进行 continue pre-training, 然后使用 YARN 将模型上下文长度扩展到了 128K。 测试的结果如下图所示
| Method | 4k | 8k | 16k | 32k | 64k | 128k |
|---|---|---|---|---|---|---|
| Baseline | 88.89 | 85.88 | 83.15 | 79.50 | - | - |
| SDPA-Gate | 90.56 | 87.11 | 84.61 | 79.77 | - | - |
| YaRN Extended | ||||||
| Baseline | 82.90 (-6.0) | 71.52 (-14.4) | 61.23 (-21.9) | 37.94 (-41.56) | 37.51 | 31.65 |
| SDPA-Gate | 88.13 (-2.4) | 80.01 (-7.1) | 76.74 (-7.87) | 72.88 (-6.89) | 66.60 | 58.82 |
可以看到,对于短上下文,虽然两者表现都有所下降,但是本文提出的 gating 表现下降程度较小。而对于长上下文,本文提出的 gating 机制效果明显更好。作者分析原因认为这是由于 softmax attention 倾向于退化为对少数 token 的依赖, 而 gating 通过引入 token-level sparsity,避免了这种路径依赖。
Conclusion
在本文中,作者系统性探究了 attention 中的 gating 机制,包括 gating 对模型表现,训练稳定性以及训练动态的影响。作者发现,通过提高 non-linearity 和 sparsity 我们可以有效提高模型的上下文能力以及减缓 attention sink 现象。
从更高层次看,本文的结果可以总结为一点:
attention 的问题不在于 softmax 本身,而在于线性 aggregation 的表达上限与缺乏选择性。而 gating 提供了一种几乎零成本、却极其有效的方式来引入非线性与稀疏性。
Appendix
作者在附录中还进一步分析了 massive activation 以及 attention sink.
- massive activation 并不是 attention sink 产生的必要原因,并且 sparsity 可以减缓这一现象
- head-specific gating 会提升 gating score 的值,因此不同的 head 需要安排不同的 sparsity
- 并不能通过 clipping 的方式来提高训练稳定性
- 在 continue pre-training 阶段加入 gating 机制并不能提高模型的表现