Overview
在这篇 blog 中,我们将回顾 DeepSeek 系列的发展以及关键技术改进。
发布时间如下
训练数据如下
DeepSeek-LLM
已有的 scaling law 如 Kaplan 和 Chinchilla 介绍了 model size, dataset size, compute budget 与模型表现之间的关系。在本文中,作者进一步探究了 learning rate 和 batch size 等超参数与模型表现之间的关系。基于发现的 scaling law, 作者为不同大小的模型设置了最优的超参数。并且,作者还发现不同数据集与模型表现之间的关系。
最终,基于这些实验结果,作者提出了 DeepSeek LLM (DeepSeek-AI et al., 2024), 模型使用 2T token 进行预训练,使用 1M samples 进行后训练,后训练包括 SFT 以及 DPO (Rafailov et al., 2023).
Architecture
DeepSeek-LLM 的架构与 LLaMA (Touvron et al., 2023) 基本相同,作者在 67B 的模型上使用了 GQA 来提高 inference 效率。最终模型的配置如下表所示
| Params | 7B | 67B |
|---|---|---|
| Context Length | ||
| Sequence Batch Size | ||
| Learning Rate | ||
| Tokens | 2T | 2T |
Data
作者主要从 Common Crawl 构建预训练数据,数据处理过程包括:去重,过滤以及 remixing 三个步骤。
对于 tokenizer, 作者使用了 BBPE 算法,tokenizer 的大小设置为 100,000, 最终的 tokenizer 大小为 102400.
Hyper Parameters
作者主要对比了一下不同 learning rate schedule 的表现:
- cosine learning schedule
- multi-step learning rate schedule: 包含三个 Stage, 第一个 stage 保持最大学习率,第二个 stage 将学习率降低为最大学习率的 , 第三个 stage 降低为最大学习率的 .
实验结果显示,multi-step learning rate scheduler 的表现与 cosine learning rate 表现差不多。并且,multi-step learning rate scheduler 对于 continue pretraining 支持更好。因此在本文中作者使用了 multi-step learning rate scheduler.
Infra
作者使用了DP,TP,SP 以及 1F1B PP 来提高计算效率。作者还使用了 flash attention (Dao et al., 2022) 来提高硬件利用率。
Scaling Law
本节中,作者分析了 scaling law, 主要有以下三点:
- 构建了针对 learning rate 和 batch size 的 scaling law
- 作者使用 non-embedding FLOPs/token 来表示 model scale
- 预训练数据的质量对最后中的 scaling 影响很大
作者首先构建了针对 batch size 和 learning rate 的 scaling law, 结果显示最优的 learning rate 和 batch size 范围都比较广,这个结论与 Kaplan 一致。
接下来,作者进一步探究了 batch size 与 generalization error 之间的关系。作者希望找到 model scale , data scale 与 compute budget 之间的关系,即
compute budget 与 model scale, data scale 之间的关系可以近似表示为 .
如果我们用 分别表示模型的 non-embedding parameter 以及 complete parameters, 则我们可以用 或者 来近似 model scale, 但是作者认为 和 均没有考虑 attention 的计算开销,因此这两种近似的误差都比较大。
为了解决这个问题,作者提出了一个新的 model scale 表示形式,即 non-embedding FLOPS/token , 其中 包含 attention 的计算开销但是不包含 vocabulary computation. 基于这种表示,compute budget 可以近似表示为 . 与 的区别表示如下所示
其中, 是 hidden size, 是 layers 个数, 是 vocabulary size, 是 sequence length. 作者在不同 scale 的模型上比较了三种表示方式,结果发现 和 要么低估,要么高估了模型的参数量。
基于 model scale 的表示方式,作者构建了如下的优化问题
作者使用了 Chinchilla 提出来的 IsoFLOP 曲线进行拟合,拟合的曲线为
作者还进一步拟合了 compute budget 与 optimal generalization error 之间的关系,实验结果显示,作者提出的 scaling law 可以很好预测模型的表现。
最后,作者探究了以下不同数据集的 scaling law, 作者分别使用 early in-house data, current in-house data 以及 OpenWebText2 来将进行实验,结果如下图所示
| Approach | Coeff. | Coeff. |
|---|---|---|
| OpenAI (OpenWebText2) | 0.73 | 0.27 |
| Chinchilla (MassiveText) | 0.49 | 0.51 |
| Ours (Early Data) | 0.450 | 0.550 |
| Ours (Current Data) | 0.524 | 0.476 |
| Ours (OpenWebText2) | 0.578 | 0.422 |
结果显示,scaling law 与数据质量高度相关。 当数据质量提升时,model scaling exponent 逐步提升,data scaling exponent 逐步下降,说明 compute budget 更多由模型参数量决定。 因此,作者认为提升 compute budget 之后,我们应该优先提高模型的 model size.
Post-training
作者构建了 1.5M 的中英文指令数据。 其中安全性的数据有 300K, 有帮助性的数据有 1.2M, 其中包括 的通用数据, 的数学相关数据, 的代码数据。
作者发现模型在训练过程中会出现重复输出的情况,特别是数学 SFT 数据,为了解决这个问题,作者使用了一个两阶段的 SFT 以及 DPO.
post-training 包含两个阶段:
- SFT: 7B 的模型训练了 4 个 epoch, 67B 的模型训练了 2 个 epoch,
- DPO: 提高模型的能力,作者发现 DPO 可以提高模型 open-ended generation skill.
Evaluation
我们主要关注一下消融实验。
首先作者探究了分阶段 SFT 对模型表现的影响。 作者发现,小模型在 math 和 code 数据集上需要训练更长时间,但是这也损害了模型的对话能力。 为了解决这个问题,作者使用两阶段的训练模式,第一个阶段使用所有的数据进行训练,第二个阶段仅使用对话数据进行训练,实验结果如下表所示
| Model | HumanEval | GSM8K | Repetition | IFEval |
|---|---|---|---|---|
| DeepSeek LLM 7B Chat Stage1 | 48.2 | 63.9 | 0.020 | 38.0 |
| DeepSeek LLM 7B Chat Stage2 | 48.2 | 63.0 | 0.014 | 41.2 |
可以看到,经过第二阶段训练之后,模型的表现有所提升
接下来,作者探究了 Multi-choice question 对模型表现的影响,MCQ 要求模型不仅需要有相关的知识,还要理解每个选项的含义。 作者使用 20M 中文 MCQ 来进行消融实验,结果如下表所示
| Model | MMLU | CEval | CMMLU | TriviaQA | ChineseQA | |
|---|---|---|---|---|---|---|
| DeepSeek LLM 7B Chat | 49.4 | 47.0 | 49.7 | 57.9 | 75.0 | |
| DeepSeek LLM 7B Chat + MC | 60.9 | 71.3 | 73.8 | 57.9 | 74.4 |
实验结果显示,MCQ 确实可以提高模型在上述几个 benchmark 上的表现,但是其泛化性会下降。 因此,作者在 pre-training 和 fine-tuning 阶段并没有使用 MCQ 数据进行训练。
作者还探究了在 pre-training 阶段加入 instruction data, 来提高 base model 在下游 benchmark 上的表现。 结果发现,base model 的表现提升优先。 作者认为,尽管 instruction data 可以提高 base model 表现,但是如果 Instruction data 数量过少,则模型表现不太可能学习到有用的知识。 因此,作者的做法是不在 pretraining 阶段加入 Instruction data.
最后,作者探究了 system prompt 对模型表现的影响。受 LLaMA2 (Touvron, Martin, et al., 2023) 启发,作者也尝试在输入中加入 system prompt. 实验结果如下所示
| Model | MT Bench |
|---|---|
| DeepSeek LLM 7B Chat | 7.15 |
| DeepSeek LLM 7B Chat + System Prompt | 7.11 |
| DeepSeek LLM 67B Chat | 8.35 |
| DeepSeek LLM 67B Chat + System Prompt | 8.58 |
可以看到,7B 的模型加入 system prompt 之后,模型表现有所下降;67B 的模型加入 system prompt 之后,模型表现有所提升。 作者认为,大模型更容易理解 system prompt 的意图,而小模型的指令跟随能力则较差,因此 system prompt 反而会影响模型表现。
- Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Re, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In A. H. Oh, A. Agarwal, D. Belgrave, & K. Cho (Eds.), Advances in Neural Information Processing Systems. https://openreview.net/forum?id=H4DqfPSibmx
- DeepSeek-AI, :, Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., Gao, H., Gao, K., Gao, W., Ge, R., Guan, K., Guo, D., Guo, J., … Zou, Y. (2024). DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. https://arxiv.org/abs/2401.02954
- Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. Thirty-Seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=HPuSIXJaa9
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., & Lample, G. (2023). LLaMA: Open and Efficient Foundation Language Models. https://arxiv.org/abs/2302.13971
- Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., … Scialom, T. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. https://arxiv.org/abs/2307.09288
DeepSeek 在 2024 年 1 月发布了 DeepSeekMoE, 一个解决 MoE 模型 specialization 不足以及 redundancy 问题的大模型系列。
DeepSeek-MoE
DeepSeek-MoE (Dai et al., 2024) 与 DeepSeek-LLM 几乎同时发布,前者主要探究了 MoE 模型的上限。
作者首先回顾了已有 MoE 模型的不足,主要有两点:
- knowledge hybridity: 已有 MoE 模型的专家个数比较少,这就导致每个专家需要掌握更多样化的知识,提高了训练难度
- knowledge redundancy: 不同专家掌握的知识可能有重叠,从而导致了模型参数存在 redundancy
为了解决这两个问题,作者提出了 DeepSeek-MoE (Dai et al., 2024), DeepSeek-MoE 主要做出了两点改变:
- Fine-Grained Expert Segmentation: 作者使用了更多的专家,来提高每个专家的 specialization, 降低训练成本
- Shared Expert Isolation: 作者在 routing expert 的基础上,加入了 shared expert 来学习 common knowledge.
作者使用了 2B-A0.6B 的模型进行了实验,结果显示模型表现超过了 GShard (Lepikhin et al., 2021), 说明了 DeepSeekMoE 模型架构的有效性。 作者还进一步将模型 scale 到了 16B-A2.8B 和 145B-A22B, 实验结果均验证了模型的 scaling 效果。
Architecutre
MoE 模块替换;额 Transformer (Vaswani et al., 2017) 中 FFN 模块,其表达式如下
这里 是专家的总个数, 是激活专家个数, 是 routing layer 的权重矩阵, 是每个专家对应的 FFN, 是 MoE layer 的输出。
DeepSeekMoE 架构如下图所示
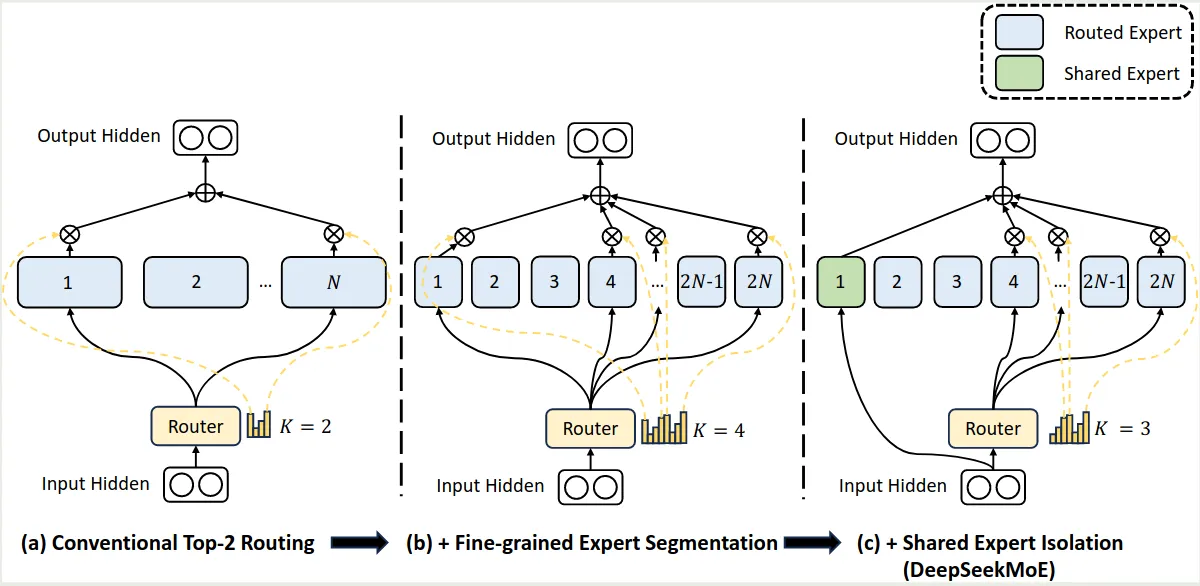
相比于其他 MoE 架构,DeepSeekMoE 主要做了以下几点改变。
Fine-Grained Expert Segmentation
作者首先解决了每个专家学习内容过多的问题。作者的做法就是将每个 expert FFN 分割为 个更小的专家,具体做法就是将 FFN intermediate hidden size 降低为原来的 . 这样的话就可以在不增加模型参数量的情况下提高模型的表现。修正后的 MoE 模块为
可以看到,现在我们一共有 个专家,激活专家个数为 个。作者认为,通过提高专家的粒度,我们可以有效增加专家组合的可能性,这就提高了最终的组合多样性。
Shared Expert Isolation
接下来,作者介绍了解决不同专家学习到重复知识的问题,作者的做法是在 routing Expert 的基础上加入 Shared expert. 也就是说,有固定几个专家始终都会被激活,这部分专家复杂学习通用知识,从而减少知识冗余。增加 shared expert 之后的 MoE 模块为
此时,模型中一共包含 个共享专家, 个 routing expert, 其中激活专家个数为 .
Load Balancing Loss
接下来,作者解决了训练时的 load imbalance 问题,作者提出了两个 loss 来分别解决不同层面的 load imbalance 问题。
首先,在 expert 层面,作者使用了如下的 load balancing loss:
其中 是超参数,
分别为以及分配给第 个专家的 token 比例以及概率之和。, . 是 indicator function.
其次,在 device 层面,作者也是用了 load balancing loss 来减少不同设备之间不必要的通信。作者将 routed experts 分为 个 group , 然后每个设备部署一个 group, group level 的 load balancing loss 定义如下:
其中 是超参数,
实际中,作者使用了一个较小的 来避免 routing collapse, 使用了一个较大的 来提高 Device 层面的负载均衡。
Training
作者使用了中英文数据进行训练,tokenizer 基于 BPE 算法,vocab size 为 8K. 模型训练基于 HAI-LLM.训练时使用了 TP, DP, PP, EP 等并行策略。
2B, 16B, 145B 模型的参数如下表所示
| Model | 2B | 16B | 145B |
|---|---|---|---|
| total params | 2B | 16.4B | 144.6B |
| activated params | 0.3B | 2.8B | 22.2B |
| hidden size | 1280 | 2048 | 4096 |
| layers | 9 | 28 | 62 |
| attention heads | 10 | 16 | 32 |
| head dimension | 128 | 128 | 128 |
| routed experts | 63 | 64 | 128 |
| activated experts | 7 | 6 | 12 |
| shared experts | 1 | 2 | 4 |
| training tokens | 100B | 2T | 245B |
Alignment
作者针对 DeepseekMoE 16B 进行了微调,微调使用了 1.4M 的训练样本,覆盖了 math, code, QA, reasoning 等任务。
Ablation Study
作者在 2B 的模型上进行了 ablation study.
首先,作者探究了细粒度专家和共享专家的有效性,结果如下图所示
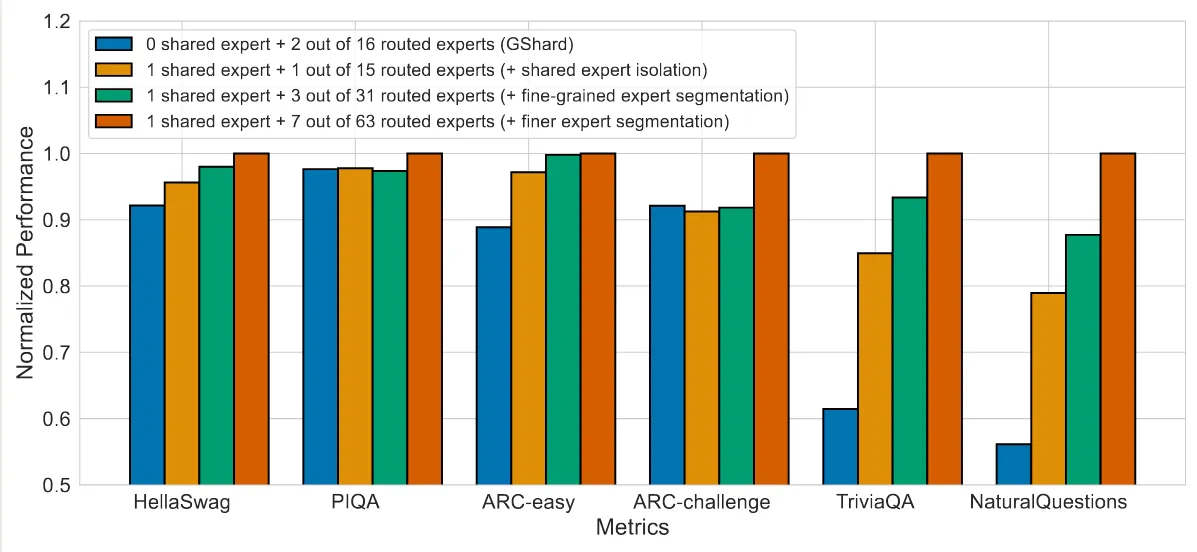
实验结果显示,与 GShard 相比,使用共享专家可以有效提高模型的表现。并且,使用更细粒度的专家也可以进一步提高模型的表现
作者还探究了共享专家与路由专家的比例,作者分别使用不同的比例进行实验,结果发现共享专家:路由专家个数为 1:3 的时候模型效果最好。
作者还探究了模型的泛化性,作者 mask 掉一部分概率最高的 routing expert, 然后从剩下的专家里进行 topK 的挑选,然后作者比较模型和 GShard 的表现,结果如下图所示
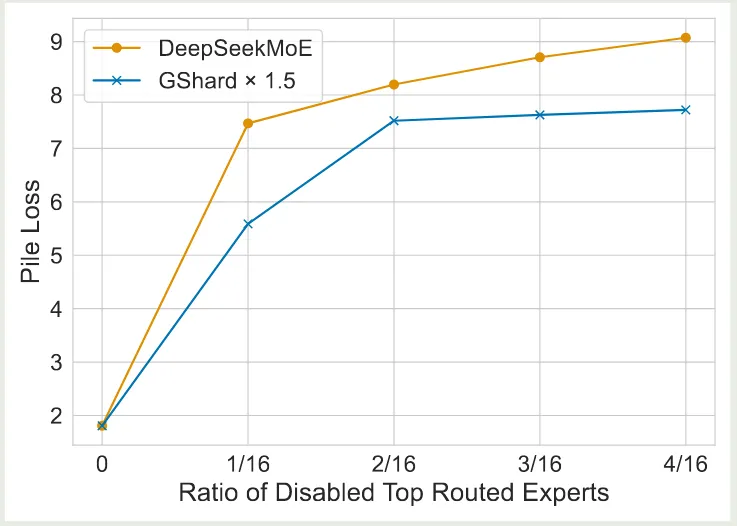
实验结果显示,DeepSeekMoE 对于 mask 操作更敏感,这说明 DeepSeekMoE 模型中专家的 specialization 更强。
作者还探究了 mask 掉共享专家对模型表现的影响,结果显示共享专家与路由专家之间的 overlap 很小,去掉共享专家之后,模型表现会变差。
作者进一步分析了共享专家与路由专家组合的有效性。作者探究 DeepSeekMoE 是否可以使用更少的路由专家来获取知识。作者通过使用不同的 activated routed experts 来进行实验,实验结果如下图所示
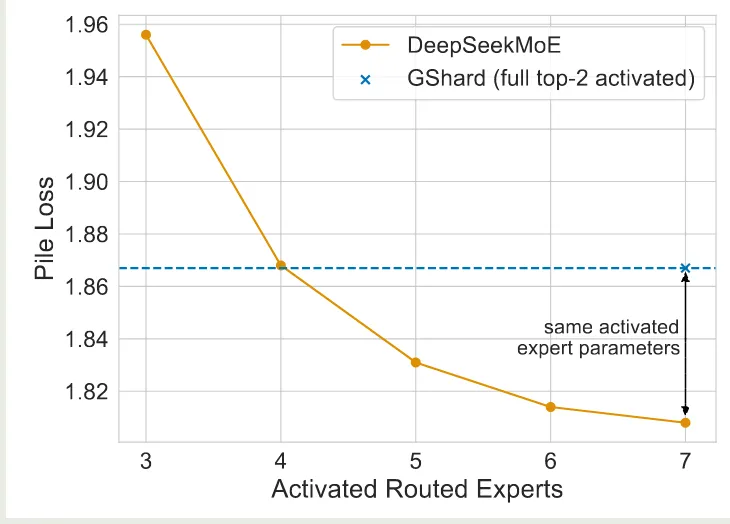
实验结果显示,DeepSeekMoE 仅需激活 4 个路由专家,就可以达到与 GShard 相同的表现。这说明了 DeepSeekMoE 模型中每个专家可以学习到更准确的知识。
- Dai, D., Deng, C., Zhao, C., Xu, R. X., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y., Xie, Z., Li, Y. K., Huang, P., Luo, F., Ruan, C., Sui, Z., & Liang, W. (2024). DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. https://arxiv.org/abs/2401.06066 back: 1, 2
- Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., & Chen, Z. (2021). Ghard: Scaling Giant Models with Conditional Computation and Automatic Sharding. International Conference on Learning Representations. https://openreview.net/forum?id=qrwe7XHTmYb
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems.
DeepSeek-V2
作者首先提到如何提高模型的训练效率以及 inference efficiency 是两个尚未解决的问题。
基于这两个问题,作者在本文中提出了 DeepSeek-V2 (DeepSeek-AI et al., 2024),一个开源的 MoE 模型,DeepSeek-V2 的亮点在于训练和推理都非常高效。最终 DeepSeeK-V2 包含 236B 总参数,激活参数为 21B, 上下文长度为 128K. 作者还开源了 DeepSeek-V2-Lite, 一个 15.7B-A2.4B 的 MoE 模型,用于学术研究。
DeepSeek-V2 主要改进点为:
- 基于 DeepSeekMoE (Dai et al., 2024), 使用了 MoE 架构
- 使用了 MLA 压缩 KV cache, 大幅度提高推理效率
DeepSeek-V2 预训练使用了 8.1T tokens, 相比于 DeepSeek-LLM (DeepSeek-AI, :, et al., 2024), 预训练数据主要增加了中文数据以及提高了数据的质量。
接下来,作者收集了 1.5M 对话数据来进行 SFT, 最终作者基于 DeepSeek Math 提出的 GRPO 来进行对齐。
Architecture
DeepSeek-V2 的模型架构如下
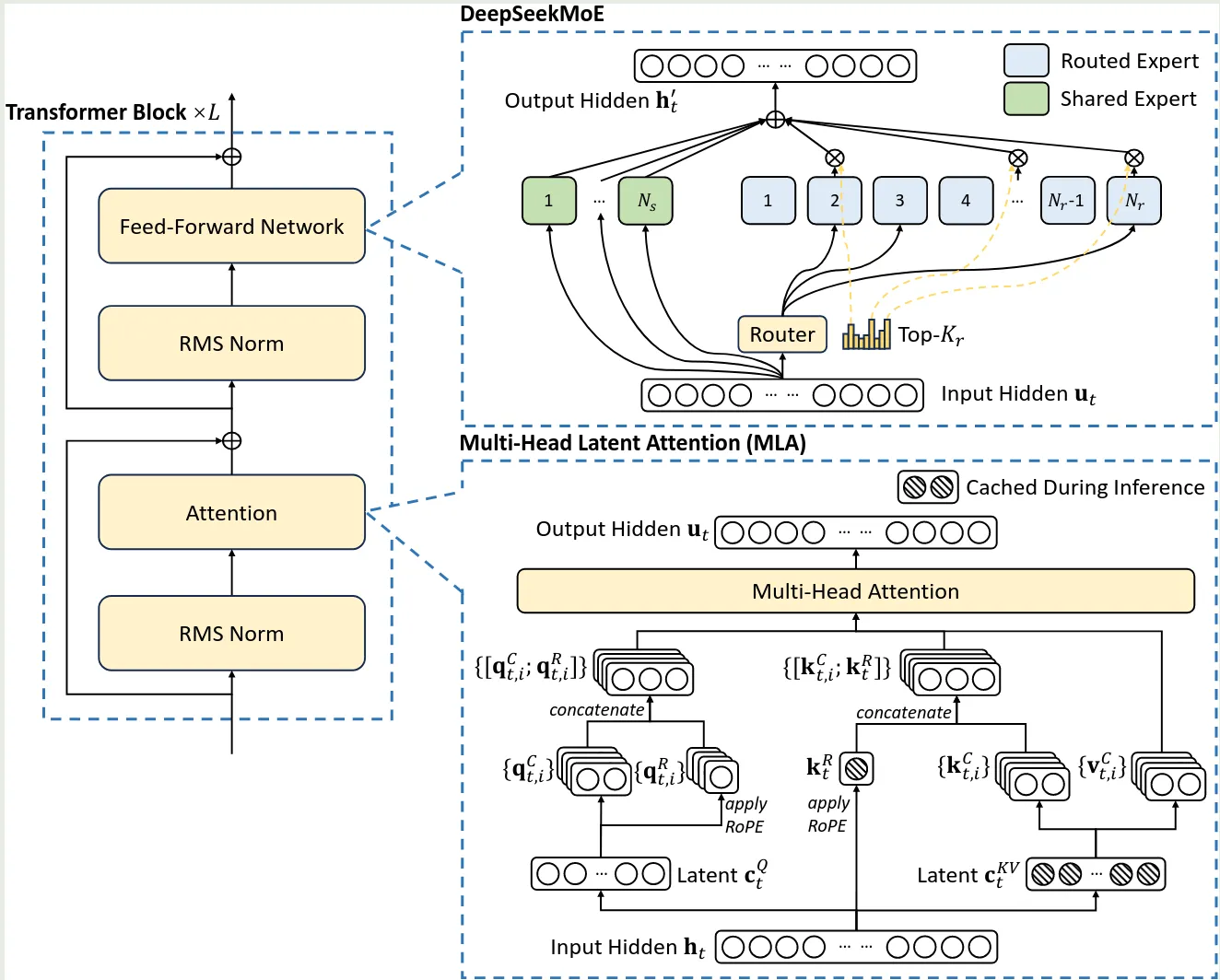
模型基于 DeepSeekMoE 开发得到,相比于 DeepSeekMoE, DeepSeek-V2 主要是使用了 MLA
MLA
这部分介绍见 MLA
Device-Limited Routing
由于 DeepSeek-MoE 使用了细粒度的专家,因此专家会分布在更多的设备(GPU)上,计算时,基于 routing 的 expert 所在设备,会产生不同大小的通信开销。为了降低通信开销,作者构建了 device-limited routing mechanism. 具体的做法就是,在 Routing 之前,先基于 experts 的 affinity score 挑选 个设备,然后基于这 个设备的专家挑选 top-K 专家进行计算。
作者通过实验发现,当 时,device-limited routing 可以和标准的 top-K routing 表现差不多。
Auxiliary Loss for Load Balance
作者使用了三个 loss 来实现负载均衡。其中,expert level 和 device level 的 load balancing loss 与 DeepSeekMoE (Dai et al., 2024) 相同。第三个 loss 是 communication balance loss, 这个 loss 的目的是让每个设备的通信开销保持平衡。损失函数的表达式如下所示
其中 是超参数, 是 expert group 的个数。
device limited routing 让每个 device 发送至多 个 hidden states 到其他设备上。而 communication balancing loss 则让每个设备最多从其他设备接收 个 hidden states.
Token-Dropping Strategy
尽管前面已经增加了 load balance loss, 但毕竟不是硬约束。因此,作者就从硬件层面提出了 Token dropping 策略,来提高训练效率。核心思想就是,在训练时,主动丢弃部分 token, 强制让各个设备的计算量不会超过额度限制,进而减少资源浪费。
具体做法就是,在训练之前,先将每个设备的 capacity factor 设置为 1 (定义见 Switch Transformer (Fedus et al., 2022). 然后按照 affinity score 来丢弃一些分数比较低的 token, 直到该设备的 token 数量刚到达到 capacity。为了避免过度学习导致模型表现较差,对于 的训练数据,作者不执行 token dropping 策略。
最终,在 inference 时,可以根据需求来决定是否丢弃 token, 比如在 low latency 场景,我们可以丢弃低价值的 token, 在高精度场景,我们就可以保留所有的 token.由于在训练阶段已经才去过 token dropping 策略,因此在推理时不管是丢弃还是全部保留模型都能比较好的适应。
Pre-training Data
预训练数据与 DeepSeek-LLM (DeepSeek-AI, :, et al., 2024) 基本上差不多,作者针对中文数据,数据质量进行了改进。最终预训练数据包括 8.1T token, 其中中文数据比英文数据多 .
tokenizer 与 DeepSeek-LLM (DeepSeek-AI, :, et al., 2024) 一致。
Model Configuration
模型配置如下表所示
| Model | DeepSeek-V2 | DeepSeek-V2-Lite |
|---|---|---|
| Date | 2024-5 | 2024-5 |
| # Total Parameters | 236B | 15.7B |
| # Activated Parameters | 21B | 2.4B |
| # tokens | 8.1T | 5.7T |
| # Dense Layers | 1 | 1 |
| # MoE Layers | 60 | 26 |
| Hidden Dim | 5120 | 2048 |
| Dense Intermediate Dim | 12288 | 10944 |
| MoE Intermediate Dim | 1536 | 1408 |
| Attention | MLA | MLA |
| # Attention Heads | 128 | 16 |
| # Key-Value Heads | 128 | 16 |
| # Routed Experts | 160 | 64 |
| # Experts Active Per Token | 6 | 6 |
| # Shared Experts | 2 | 2 |
这里比较特殊的一点在于,模型在第一层使用了 MoE layer, 这个做法的原因在后面的 olmoe 里有提到,核心思想是 early layer 特别是第一层 layer 收敛比较慢。
MLA 的配置如下 (DeepSeek-V2)
| field | value |
|---|---|
| 512 | |
| 1536 | |
| 16 | |
| 128 | |
| 64 |
Training Recipe
训练的配置也与 DeepSeek-LLM (DeepSeek-AI, :, et al., 2024) 差不多,对于 MoE,作者使用了 PP 将不同的 layers 分配在不同的 device 上,然后 MoE 的 experts 被分配在 8 个 device 上 (), 对于 device-limited routing, 每个 token 发送到至多 3 个 device, 也就是 .
Infra
在 infra 上,DeepSeek-V2 也是用了 HAI-LLM 框架进行训练。这里面使用了 16-way zero-bubble PP, 8-way EP, ZeRO-1 DP.
由于 DeepSeek-V2 的激活参数比较少,因此,作者没有使用 TP, 进而降低通信开销。作者还将 shared experts 的计算与 expert all-to-all 通信进行重叠来提高计算效率。作者还使用了 kernel fusion 和 flash attention 2 来加速训练。
Long Context
在预训练阶段结束之后,作者使用了 YaRN (Peng et al., 2026) 来将模型的上下文从 4K 扩展到 128K. 超参数设置为
| Parameter | Value |
|---|---|
| 40 | |
| 1 | |
| 32 | |
| target context length | 160K |
| scaling factor |
作者在 32K 的上下文下额外训练了 1000 步,然后在推理阶段通过 YaRN (Peng et al., 2026) 将模型的上下文长度扩展到 128K.
Evaluation
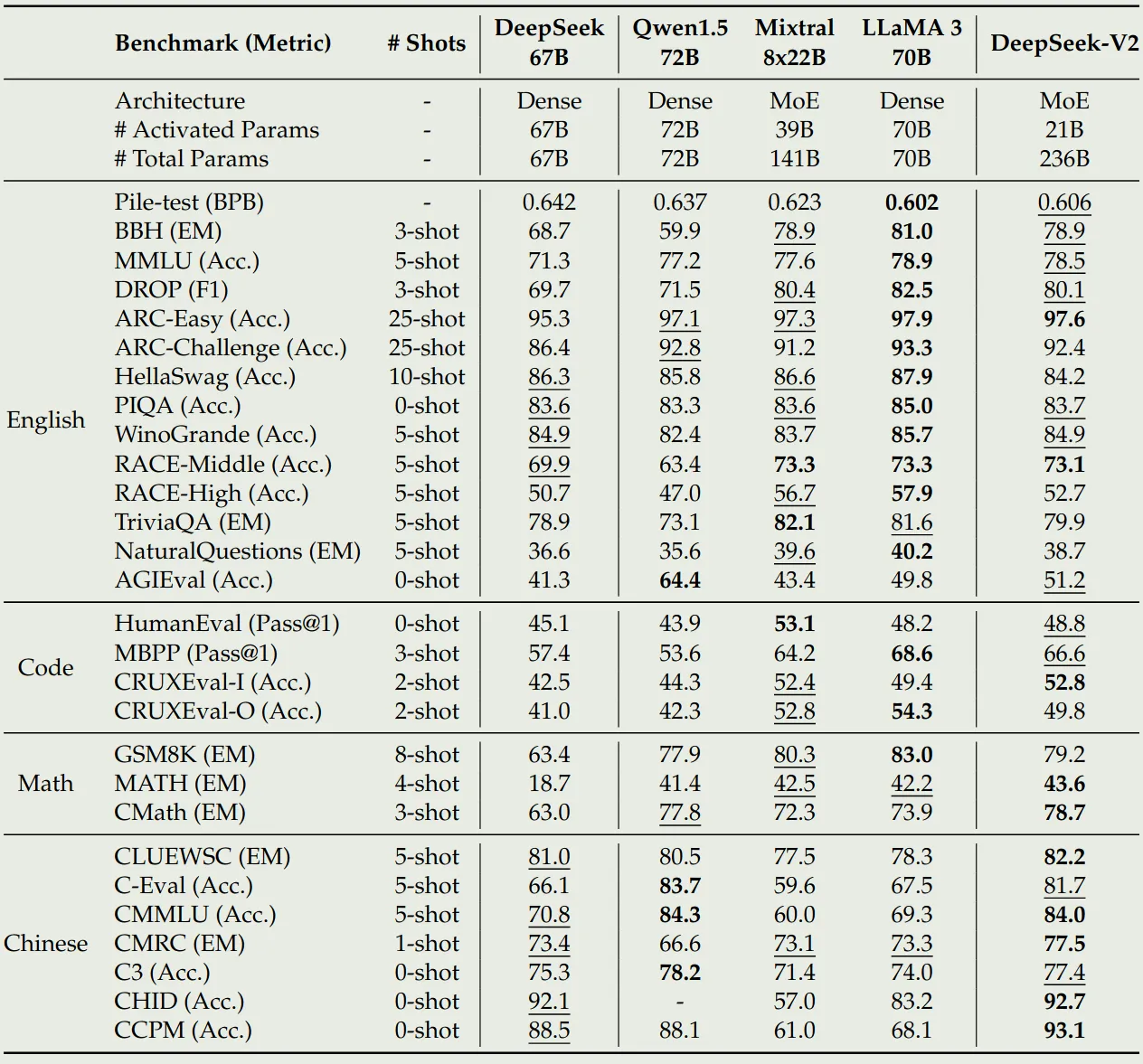
作者对比了 DeepSeek-LLM (DeepSeek-AI, :, et al., 2024), Qwen1.5, Mixtral MoE 以及 LLaMA3 (Grattafiori et al., 2024), 实验结果如下
Efficiency
作者对比了以下 DeepSeek-MoE 和 DeepSeek-LLM 的训练效率,结果发现,对于 1T 的 token, DeepSeek-LLM 需要 300.6K GPU hours, 而 DeepSeek-V2 仅需要 127.8K GPU hours. 也就是说,DeepSeeK-V2 节省了 的训练成本
在推理时,作者首先将模型的精度转换为 FP8,然后作者进一步对模型进行 KV cache quantization 来进一步压缩每个 token 的 KV cache 到 6bits. 最终,DeepSeek-V2 的 throughtput 为 50K tokens/s.
SFT
post-training 分为 SFT 和 RL 两个阶段。
在 SFT 阶段,作者构建了 1.5M 样本,包括 1.2M 有帮助性的样本和 0.3M 安全性相关的样本。模型训练了 2 个 epoch, 学习率为 .
RL
作者使用了 GRPO 算法来进一步对齐模型的表现。
作者通过实验发现,在 reasoning data, 如 code 和 math 相关数据上进行训练时,可以有效提高模型的表现。因此作者将 RL 的训练分为两个阶段,第一个阶段用于提高模型的 reasoning 能力,第二个阶段用于对齐人类偏好。
在第一个阶段,作者首先训练了一个针对 code 和 Math 的 reward model , 然后基于这个 reward model 来训练 policy model:
在第二阶段,作者使用了一个 Multi-reward 框架,包括一个 helpful reward model , 一个 safety reward model 和一个 rule-based reward model , 最终的 reward 为
训练时,reward model 由 SFT model 初始化得到,然后基于 point-wise 或者 pair-wise loss 进行训练。
Evaluation
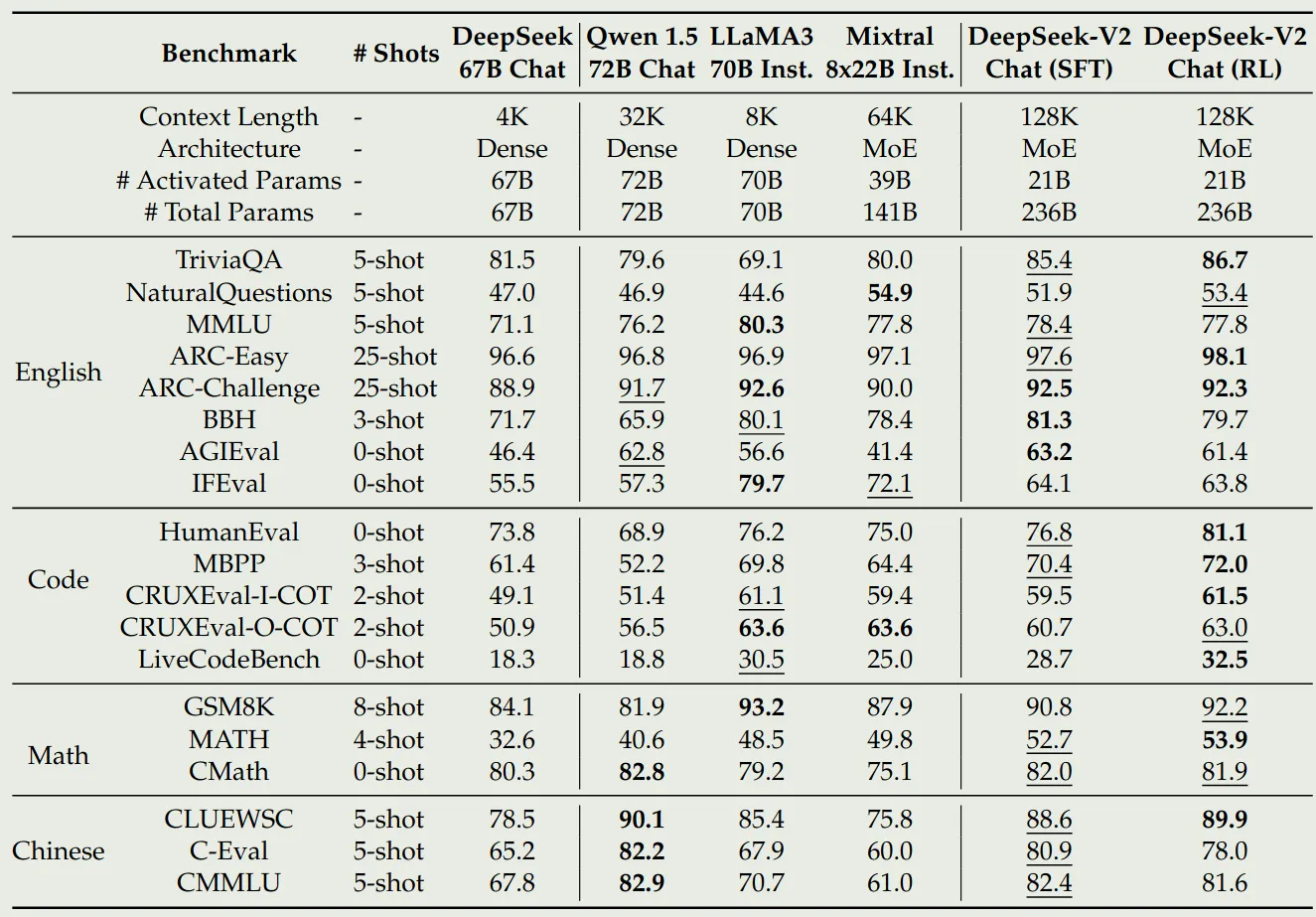
chat 版本的模型评估结果如下所示
Discussion
作者讨论了三点发现:
- SFT data 数量。已有工作认为进需要 10K 左右的样本就可以进行 SFT,但是作者发现当数据量小于 10K 时,模型在 IFEval benchmark 上的表现大幅度下降。作者认为,这是由于数据过少导致模型很难掌握特定的技能。因此,作者认为足够的数据以及数据质量都很重要,特别是写作类任务和 open-ended QA 类任务。
- alignment tax. 作者发现通过 human preference alignment, 模型在 open-ended generation benchmark 上的保险有了很大提升。与 RLHF 一样,作者也发现了 alignment 之后模型在一些 benchmark 上表现也会下降。作者通过改进解决了这个问题,作者认为如何在不损失模型表现的情况下实现对齐是一个值得探究的方向。
- online RL. 作者发现 Online RL 比 offline RL 的表现更好。作者认为如何根据不同的任务来选取 offline RL 和 online RL 也是一个值得探究的问题。
Conclusion
在本文中,作者提出了 DeepSeek-V2, 一个基于 MoE 架构的大语言模型系列,模型的上下文为 128K. 作者基于 DeepSeek-MoE, 提出了 MLA 来提高模型的 inference 效率,并大幅度降低了训练的成本。
作者介绍了几点未来工作:
- 进一步 scaling up MoE 模型,降低模型的训练以及推理成本
- 进一步对齐模型和人类的价值观,然后最小化人类监督信号
- 扩展模型到多模态版本
- Dai, D., Deng, C., Zhao, C., Xu, R. X., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y., Xie, Z., Li, Y. K., Huang, P., Luo, F., Ruan, C., Sui, Z., & Liang, W. (2024). DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. https://arxiv.org/abs/2401.06066 back: 1, 2
- DeepSeek-AI, :, Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., Gao, H., Gao, K., Gao, W., Ge, R., Guan, K., Guo, D., Guo, J., … Zou, Y. (2024). DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. https://arxiv.org/abs/2401.02954 back: 1, 2, 3, 4, 5
- DeepSeek-AI, Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Ji, D., Li, E., Lin, F., Luo, F., Hao, G., Chen, G., … Xie, Z. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. https://arxiv.org/abs/2405.04434
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch transformers: scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res., 23(1).
- Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., … Ma, Z. (2024). The Llama 3 Herd of Models. https://arxiv.org/abs/2407.21783
- Peng, B., Quesnelle, J., Fan, H., & Shippole, E. (2026). YaRN: Efficient Context Window Extension of Large Language Models. https://arxiv.org/abs/2309.00071 back: 1, 2
DeepSeek-V3
作者在本文中提出了 DeepSeek-V3 (DeepSeek-AI et al., 2025), 一个 671B-A37B 的 MoE 大语言模型。
在训练目标和架构上,作者做了如下改进:
- efficiency inference: 采用了 DeepSeek-V2 提出的 MLA
- cost-effective training: 采用了 DeepSeekMoE 提出了 MoE 架构
- auxiliary-loss-free strategy: 采用了 Loss-Free Balancing 提出的 loss balancing 策略
- multi-token prediction: 采用了 MTP 的训练目标来提升模型的表现
在训练框架上上,作者做了如下改进:
- 使用了 FP8 混合精度进行训练并验证了其在大规模模型上的有效性
- 作者构建了 DualPipe 算法用于高效的 pipeline parallelism
- 构建了 cross-node all-to-all communication kernel 来高效使用 InfiniBand 以及 NVLink bandwidth
- 优化了 memory footprint, 来避免使用 tensor parallelism
在训练方式上:
- 预训练阶段,DeepSeek-V3 使用了14.8T token.
- 在 mid-training 阶段,作者将模型的上下文长度由 8K 扩展到 32K, 再扩展到 128K.
- 后训练阶段,作者使用了 SFT 和 RL 两个阶段来提高模型的表现,作者还对 DeepSeek-R1 进行蒸馏来提高模型的 reasoning 能力
Architecture
DeepSeek-V3 的架构与 DeepSeek-V2 的架构一致,见 DeepSeek-V2.
DeepSeek-V3 在 DeepSeekMoE 的基础上,使用 sigmoid function 来单独计算每个专家的贡献,然后再进行 normalization.
DeepSeek-V3 还使用了 Loss-Free Balancing, 其表达式如下
其中 是一个随机扰动,仅影响 routing 结果。 训练时,如果对应的 expert 负载不均衡,则对 进行更新,更新方式为 , 这里 是一个超参数。
为了提高 routing 在 sequence 层面的负载均衡,作者还使用了一个 complementary sequence-wise balance loss:
其中 是 balance factor, 为超参数, 是 sequence length, 加入这个损失后,每个 sequence 上的负载会变得更加均衡
MTP
受 MTP (Gloeckle et al., 2024) 启发,DeepSeek-V3 也构建了 MTP 模块用于预测未来的多个 token, 作者认为 MTP 模块有两个优势:
- MTP objective 提供了更多的学习信号,进而提高了数据使用效率
- MTP 可以让模型更好预测未来的 token, 提高模型的规划能力
DeepSeek-V3 所使用的 MTP 模块架构图如下所示
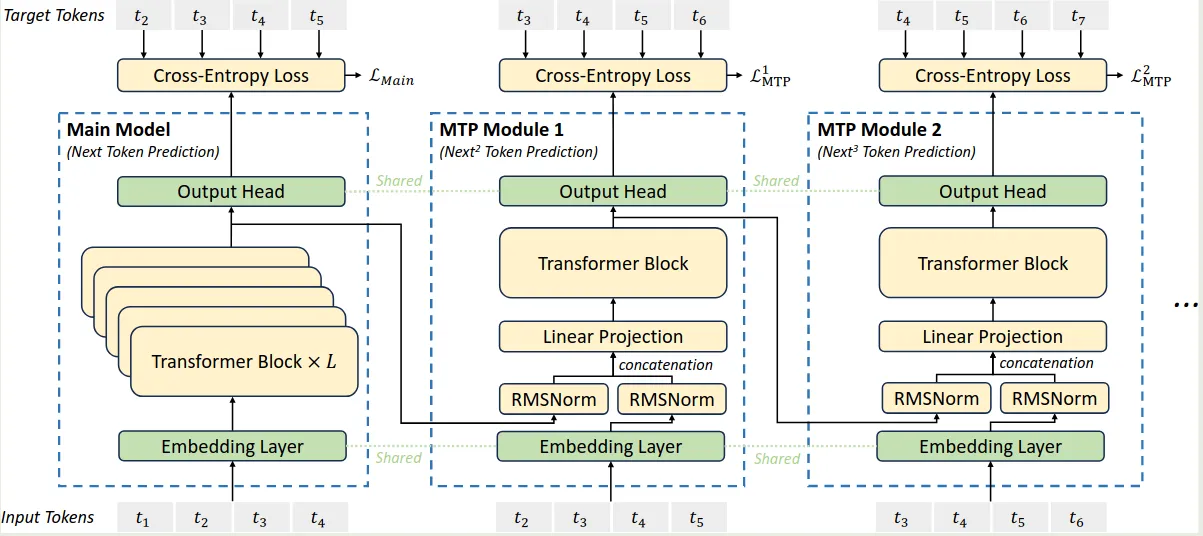
MTP 模块使用了 个 sequential modules 来预测未来的 个 token. 其中,第 个 MTP 模块包含:
- 一个共享的 embedding layer
- 一个共享的 output head
- 一个 transformer block
- 一个 projection matrix .
对于第 个 token 以及第 个 MTP 模块,作者首先将第 个 MTP 模块的第 个 token 的 hidden states 和第 个 token 的 embedding concate 在一起
是 main model 的输出。 每个 MTP 模块的 embedding layer 和 main model 的 embedding layer 是共享的,接下来, 作为第 个 MTP 模块 transformer block 的输入,得到
最后,共享的 output head 输出对应的概率分布:
这里的 的权重与 main model 也是共享的。作者这里提到,所使用的思想与 EAGLE 是类似的,但是不同的地方在于,EAGLE 主要是用于 speculative decoding, 而 MTP 主要用于提升训练。
MTP 的训练目标为未来 个 token 的 cross-entropy loss:
其中 是 sequence length, 是第 个位置对应的 ground truth token, 代表低 个 MTP 模块给出的 的预测概率。最后,作者对所有的 MTP loss 进行求和,得到
Infra
DeepSeek-V3 训练使用了 2048 张 H800, 每个 node 包含 8 张 GPU, node 内部使用 NVLink 和 NVSwitch 进行连接,node 之间使用 InfiniBand 进行连接
与之前的 DeepSeek 系列相同,DeepSeek-V3 也是用了 HAI-LLM 框架来支持训练。训练时,DeepSeek-V3 使用了 16-way PP, 64-way EP (spanning 8 nodes, GShard) 以及 ZeRO-1 DP.
作者主要进行了三点优化:
- 构建了 DualPipe 用于高效 pipeline parallelism
- 构建了 cross-node all-to-all communication kernels 来高效利用 IB 以及 NVLink bandwidth
- 优化了训练时的 memory footprint, 使得训练时不再依赖 TP
Training Framework
DualPipe
DeepSeek-V3 中,由于 cross-node EP, computation-to-communication ratio 近似为 1:1, 为了解决这个问题,作者提出了 DualPipe. DualPipe 的核心思想是将 forward 和 backward 过程中的 computation 以及 communication 进行重叠。与 ZeroBubble 类似,作者将每个 chunk 分为四个部分:attention, all-to-all dispatch, MLP 以及 all-to-all combine. 对于 attention 和 MLP, 作者还进一步将 backward 拆分为 针对权重和输入的 backward. 其示意图如下所示,这里橙色部分代表 forward, 绿色代表了针对输入的 backward, 蓝色代表了针对权重的 backward

示意图里包含两个 block, 我们记为 block1, block2, 前向计算过程为
dispatch(F, block1) -> MLP(F, block1) -> combine(F, block1) -> attention(F, block2)
其中,dispatch(F, block1) 与 MLP 的反向传播 MLP(B, block1) 计算重叠, MLP(F, block1) 与 MLP 反向传播的 dispatch dispatch(B, block1) 通信重叠,combine(F, block1) 与 attention 反向传播的 attention(B, block2) 重叠,attention(F, block2) 与反向传播的 combine combine(block2) 重叠。下面是一个具体的例子

作者进一步对比了 DualPipe, 1F1B 和 ZeroBubble, 结果如下表所示
| Method | Bubble | Parameter | Activation |
|---|---|---|---|
| 1F1B | |||
| ZB1P | |||
| DualPipe (Ours) |
这里 是 forward chunk 的执行时间, 是 backward chunk 执行的时间, 是一个 chunk “backward for weights” 的执行时间, 是一个 chunk 前向反向传播重叠的时间。可以看到,DualPipe 只使用了额外的 倍的 peak activation memory, 就大幅度降低了 bubble 时间
Cross-node All-to-all Communication
作者针对 DualPipe 构建了 cross-node all-to-all communication kernels 来提高通信效率。
作者提到,跨节点通信使用的是 IB, 节点内部通信使用的是 NVLink, 通信方式如下图所示。
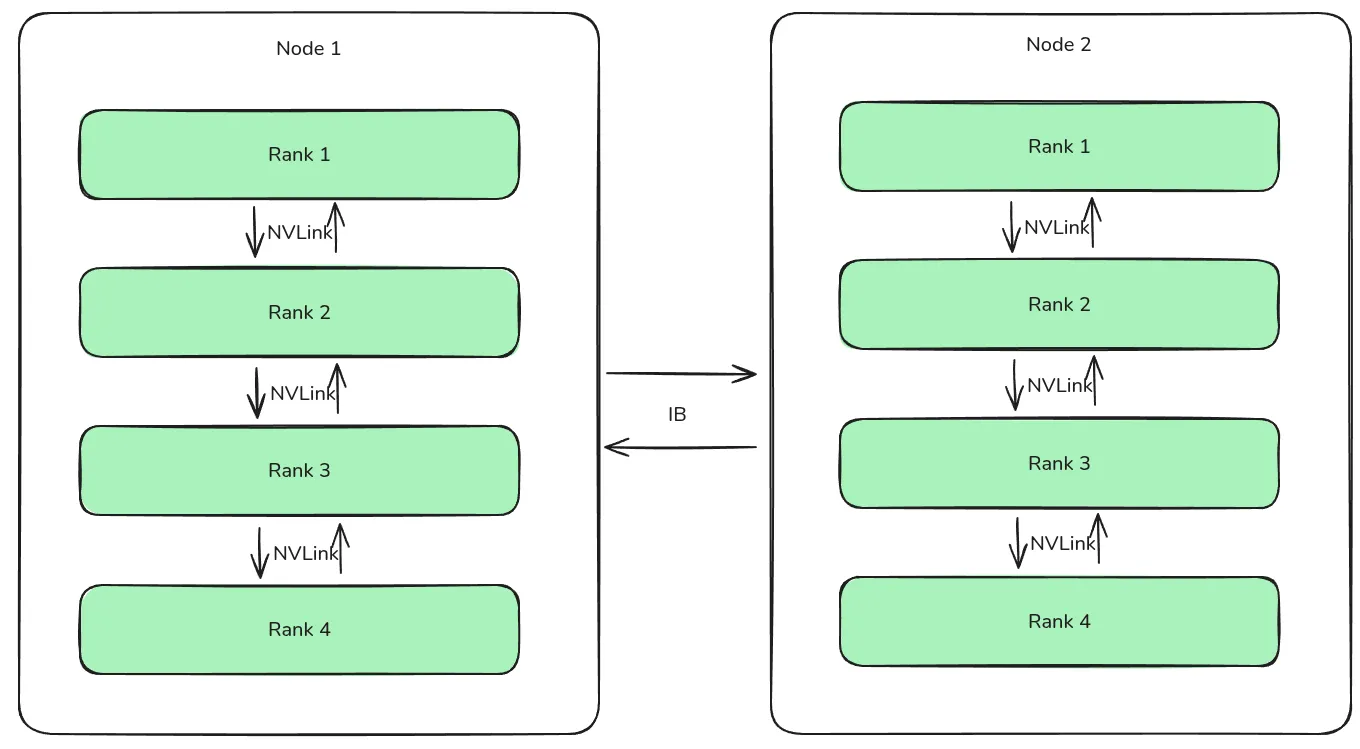
对于 H800 来说,NVLink 的带宽为 160GB/s, IB 的带宽为 50GB/s, 因此 NVLInk 的通信效率是 IB 的 3.2 倍,即节点内部通信效率高于节点之间的通信效率。为了提高通信效率,作者限制每个 token 只能被分发到至多 4 个节点上(DeepSeek-V2 里提到的 device limited routing)。其具体通信方式为想传输到目标 node index 相同的 rank 上,然后再通过节点内部通信传输到目标的 rank 上。通过这种方式,我们可以让节点间通信与节点内部通信进行重叠,从而每个 token 可以从一个节点上选取 3.2 个专家,这样 DeepSeek-V3 可以在不损失效率的情况下最高选取 个专家。
作者进一步采用了 warp specialization 技巧来将 20 个 SM 划分为 10 个通信 channel. 作者分别针对 dispatching 和 combing 阶段使用了不同数量的 warps.
Memory saving
作者使用了如下技巧来减少内存访问:
- Recomputation of RMSNorm and MLA Up-Projection. 在 backward 过程中重新计算 RMSNorm operation 以及 MLA up projection 来避免存储器对应的输出
- Exponential Moving Average in CPU. 作者将 EMA 参数保存在 CPU 中,然后进行异步更新来进一步减少内存访问
- Shared Embedding and Output Head for Multi-Token Prediction. 作者将 embedding layer 和 output head 放在一个 PP rank 上,这样就可以提高 MTP 的内存访问效率
FP8 Training
作者提出了一个基于 FP8 的混合精度训练框架。作者提出了两个改进方案:
- 分组量化,将 tensor 按照 tile 分组或者按照 block 分组来分组量化,这样就避免了全局量化的精度损失
- 高精度累加,作者在乘法计算时,使用了 FP8 格式,然后在累加阶段,使用了更高精度的格式
为了进一步减少内存和通信开销,对于 activation 的 cache 以及 dispatch, 作者使用了 FP8 数据格式,然后对于优化器状态,作者使用了 BF16 数据格式。下面是对上面改进的具体说明。
Mixed Precision Training
作者在本文中提出了使用 FP8 混合精度进行预训练,作者参考了 low precision training 构建 FP8 训练框架,即计算量高的使用 FP8 精度,计算量低的使用原本的数据精度, 框架如下图所示
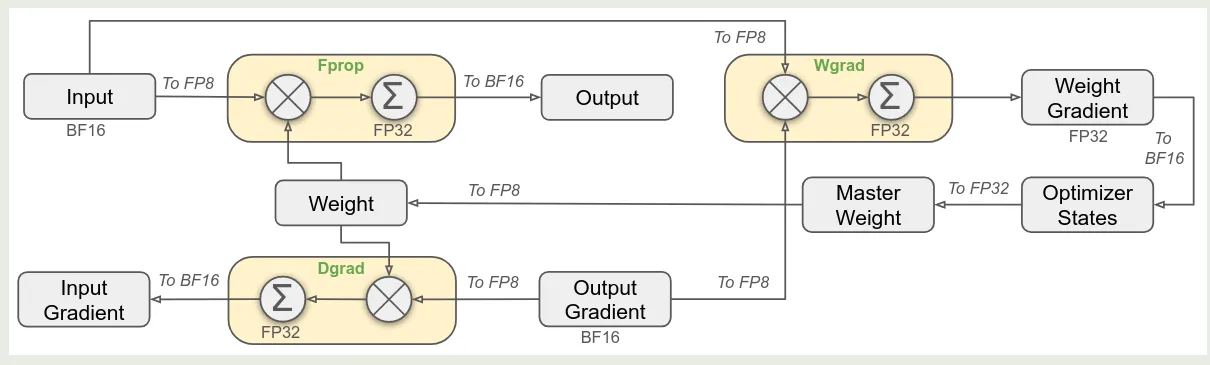
其中各个模块使用的精度如下表所示
| Precision | Modules |
|---|---|
| FP8 | Linear (Fprop, Dgrad, Wgrad) |
| higher precision | - embedding - output head - Moe gating - normalization - attention operator - master weights - weight gradients - optimizer states |
Enhancing Low-precision Training Accuracy
作者介绍了几个策略用于提高 FP8 混合精度训练的表现:
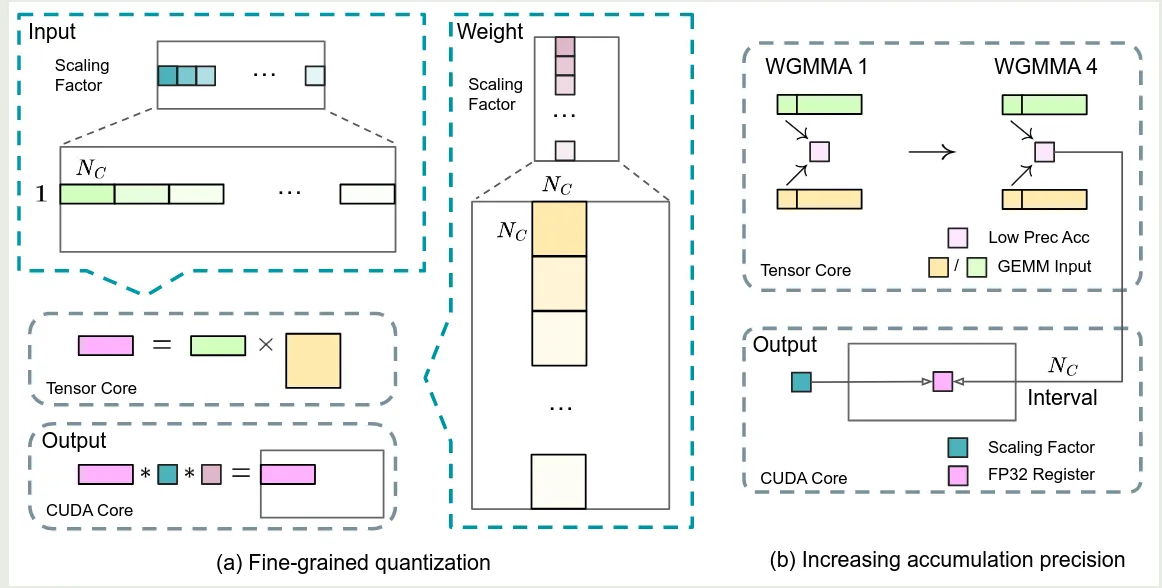
- fine-grained quantization: 对于激活值,作者将 tensor 分割为 大小的 groups, 然后每个 group 内部进行 quantization; 对于权重,作者将其分割为 大小的 groups, 然后进行 quantization, 这样可以降低 quantization error, 如上图左图所示
- increasing accumulation precision: 低精度训练会带来 underflow 的问题,而 FP8 GEMM 累加仅能保留约 14bit 精度,远低于 FP32 的 32bit 精度。为了解决这个问题,作者采用了 Tensor Core 不分累加 +CUDA core 高精度聚合的协同策略。即在 Tensor Core 上执行 MMA 指令时,先按照 14bit 精度对 个元素进行累加,当达到 时,作者将结果复制到 CUDA core 的 FP32 寄存器中,在 FP32 精度下完成累加。过程如上图右图所示
- Mantissa over exponents. 与之前的工作不同,作者使用了 E4M3 的数据格式来达到更高的精度
- Online Quantization. 为了降低 quantization 的误差,作者实时计算了 activation block 以及 weight block 的最大绝对值来导出 scaling factor 并量化为 FP8 精度
Low Precision Storage and Communication
作者通过压缩 cached activation 和 optimizer states 来进一步减少内存访问以及通信访问次数
- Low-precision optimizer states: 对于 optimizer states, 作者使用了 BF16 数据格式来保存 AdamW 的优化器的一阶和二阶动量,但是对于 master weight 和 gradients 作者仍然使用了 FP32 来保证训练的数值稳定性
- Low-Precision Activation: 对于 linear operator, 作者将其 cache activation 使用 FP8 格式进行存储,对于 attention 的输出,作者使用了 E5M6 数据格式来存储 activations, 这些 activations 的 tile size 为 , 作者还是用了 2 的幂次作为 scale factor 来减少 quantizationerror; 对于 SwiGLU, 作者将其输入也保存为 FP8 的数据格式来降低内存消耗
- Low-Precision Communication: 在 MoE up-projection 之前,作者将 attention 的输出量化为 FP8 数据格式再执行 dispatch 操作,这样可以降低通信开销。在反向传播的时候同理,先进行 FP8 量化,然后再进行反向 dispatch. 对于 combine 阶段,为了避免精度损失,作者还是使用了 BF16 数据格式
作者对比了 FP8 和 BF16 精度训练,结果如下图所示
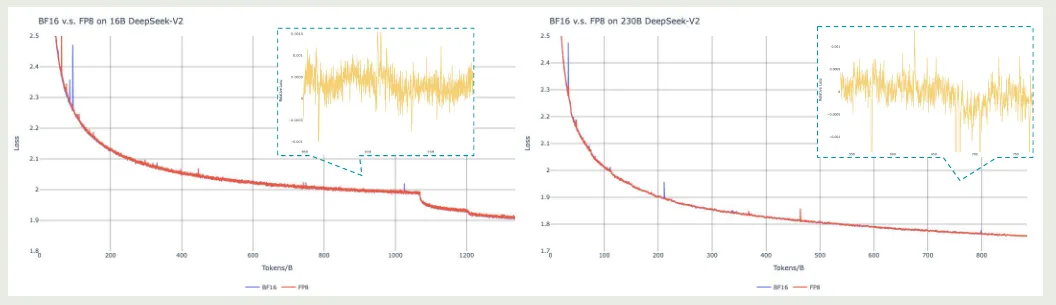
实验结果显示,FP8 混合精度训练的损失降低不足 .
Inference and Deployment
作者在 H800 集群上部署 DeepSeek-V3, 作者分别针对 prefilling 和 decoding 两个阶段进行了优化
Prefilling
prefilling 阶段在 4 节点 32 GPU 上进行,并行策略如下
| 模块 | 并行策略 | 说明 |
|---|---|---|
| Dense MLP | 1-wat TP | 减少 TP 通信 |
| Attention | 4-way TP, SP, 8-way DP | SP 用于长文本处理 |
| MoE | 32-way EP | 每个 GPU 包含 8 个专家 |
为了实现负载均衡,作者提出了redundant experts的策略,具体就是将负载比较高的专家进行复制。模型会周期性进行统计,然后计算出负载比较高的专家,接下来每个 GPU 除了原来的 8 个专家之外,还会 host 一个额外的 redundant expert.
为了提高 throughput, 作者同时处理两个 micro-batch, 来重叠 attention, MoE 和 dispatch, combine 通信,如下图所示
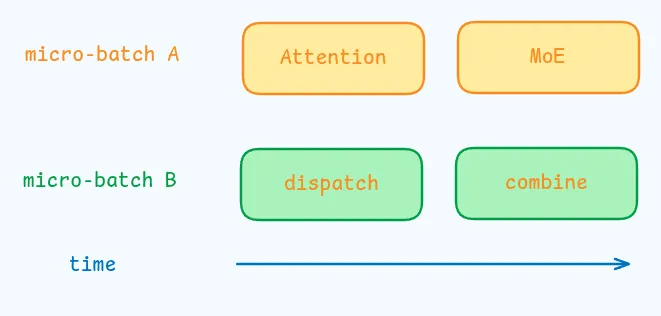
作者还探索了 dynamic redundancy 策略,即每个 GPU host 更多的专家(比如 16 个)然后 inference 的每一步仅激活其中的 9 个,在进行 all-to-all operation 时,作者首先进行 global optimal routing 来计算最合适的专家。作者认为 prefilling 计算量很大,因此 routing 的计算量可以忽略不计
Decoding
在 decoding 阶段,作者在 40 个节点 320 GPU 上进行部署,并行策略如下
| 模块 | 并行策略 | 说明 |
|---|---|---|
| Attention | 4-way TP, SP, 80-way DP | SP 用于长文本处理 |
| MoE | 320-way EP | 每个 GPU 包含 8 个专家 |
这个阶段,每个 GPU 只 host 一个专家,64 个 GPU 负责 host redundant expert 以及 shared expert. 作者通过在 IB 上直接进行 P2P 的传输来降低通信的开销,作者还是用了 IBGDA 来进一步最小化 latency 以及提高通信效率
在这个阶段,attention 的计算占据了大部分时间,因此,作者采取了如下的 overlap 策略
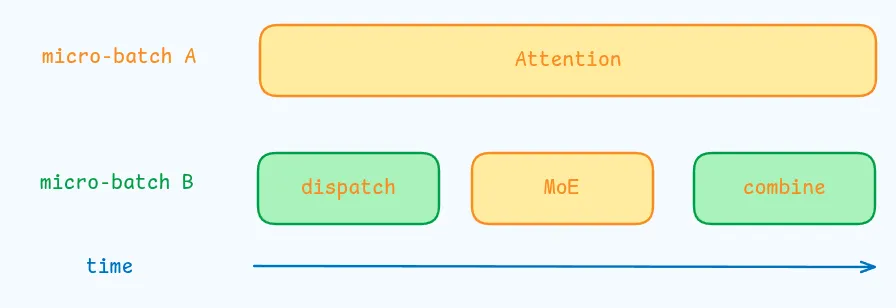
由于 decoding 阶段一般 batch size 比较小,因此整个 decoding 的瓶颈在于 memory access, 因此为了避免影响 attention 的计算效率,作者仅安排一小部分 SM 用于 dispatch-MoE-combine.
Suggestions on Hardware Design
Communication Hardware
尽管作者将计算与通信重叠来提高训练效率,但是已有的通信仍然依赖于 SM, 这样限制了计算的效率。作者希望工能够构建专门针对通信的设备,另一方面,作者希望统一 IB 和 NVLink 来降低实现难度
Computation Hardware
- 提升 FP8 GEMM 的累加精度,当前精度只有 14bit, 作者希望能够在 GPU 设计上进行改进,将这个精度提升到 34-bit
- 支持 tile 以及 block 层面的 quantization, 尽管前文作者已经设计出了改进的算法,但是 Tensor Core 以及 CUDA 之前平凡的数据移动降低了计算效率,作者希望未来能够支持细粒度的 quantization
- online quantization, 作者希望将 FP8 cast 以及 TMA 结合在一起,从而 quantization 可以在传输的时候完成计算,减少了内存读写。作者还建议使用 warp-level cast instruction
- Transposed GEMM operations. 本文中,矩阵被切分为不同的 tiles, 在计算的时候需要先加载这些 tiles 然后进行 dequantization, transpose 等操作,作者希望未来能够直接支持 transposed reads of matrices
Pre-training
Data
相比于 DeepSeek-V2, DeepSeek-V3 提升了数学和代码数据的比例,以及增加了多语种数据。最终训练数据一共包括 14.8T
作者还使用了 DeepSeekCoder-V2 里应用的 Fill in the middle 策略来让模型基于上下文越策中间的文本,对应的数据格式如下
<|fim_begin|>f_pre<|fim_hole|>f_suf<|fim_hole|>f_middle<|fim_end|>
这个结构与 sequence packing 结合在一起。
Tokenizer 基于 BBPE, 大小为 128K tokens. 在训练时,作者将随机一部分 combine token 进行切分来减少 token boundary bias 问题
Hyper-parameters
模型参数如下表所示,最终 DeepSeek-V3 拥有 671B 总参数,激活参数为 37B
| variable | notation | value |
|---|---|---|
| layers | 61 | |
| dense layers | - | 3 |
| hidden dimension | 7168 | |
| num of attention heads | 128 | |
| head dimension | 128 | |
| KV compression dimension | 512 | |
| query compression dimension | 1536 | |
| decouple query and key dimension | 64 | |
| routed expert | 256 | |
| shared expert | 1 | |
| MoE hidden dimension | 2048 | |
| activated experts | 8 | |
| limited node routing | 4 | |
| MTP depth | 1 |
训练时,作者使用了 learning rate scheduling, batch size scheduling 等方法。对于 PP, routed expert 会均匀分布为 8node 对应的 64 个 GPU 上,预训练时模型的上下文长度为 4k
Long Context Extension
作者使用了 YARN 来扩展模型的上下文长度,模型上下文长度经过两个额外的训练阶段从 4K 扩展到 32K 再扩展到 128K, 均训练了 1000 步。
YARN 配置与 DeepSeek-V2 基本一致,在额外的 decoupled query and key 上作者没有应用这一点。参数配置如下表
| parameter | ||||
|---|---|---|---|---|
| value | 40 | 1 | 32 |
第一阶段的上下文长度为 32K, batch size 为 1920, 第二个阶段的上下文长度为 128K, batch size 为 480.
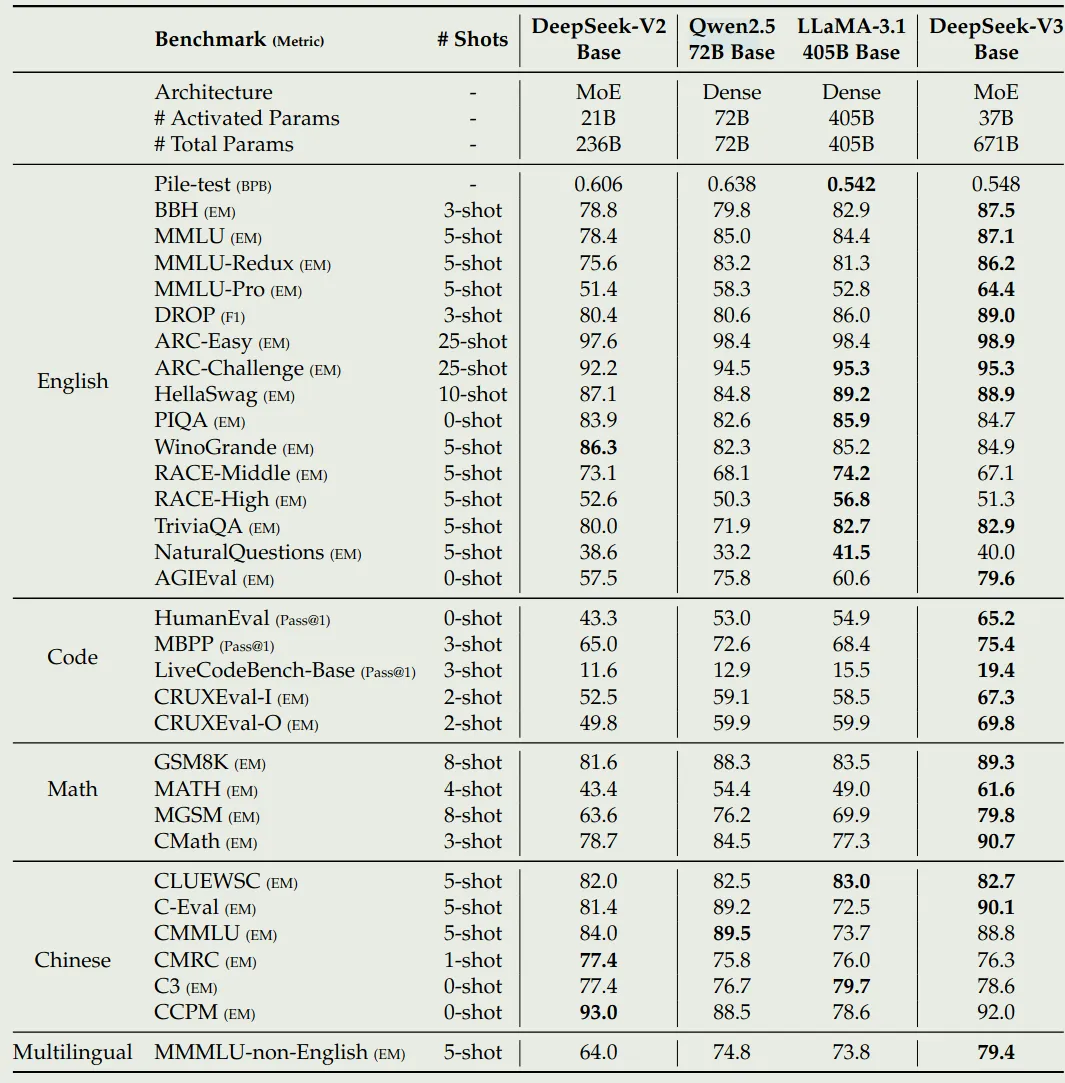
Performance
DeepSeek-V3 base 的表现下图所示,作者对比了 DeepSeek-V2 (DeepSeek-AI et al., 2024), Qwen2.5, LLaMA 3.1 (Grattafiori et al., 2024)
Discussion
作者首先验证了 MTP 的有效性,结果如下图所示
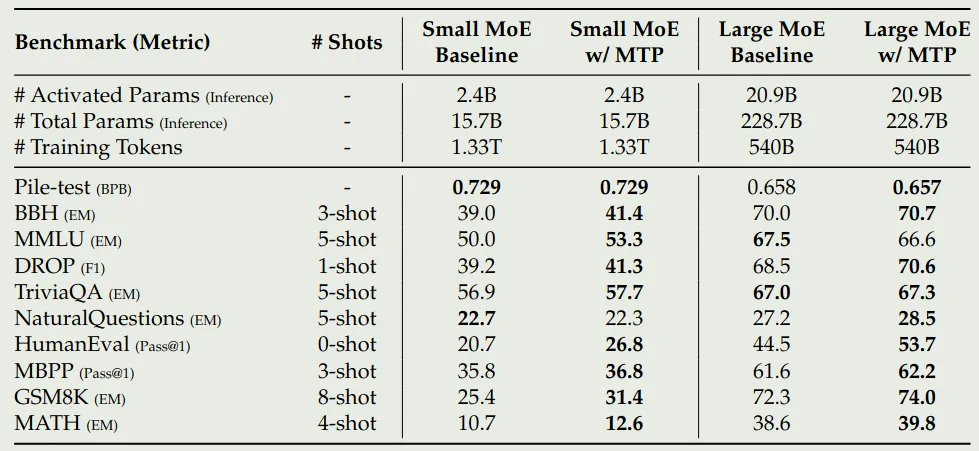
可以看到,在模型架构相同,训练数据相同的情况下,1-MTP 的效果超过了 baseline 的表现,说明了 MTP 策略的有效性
接下来,作者还验证了 Loss-Free Balancing 的有效性,结果如下图所示
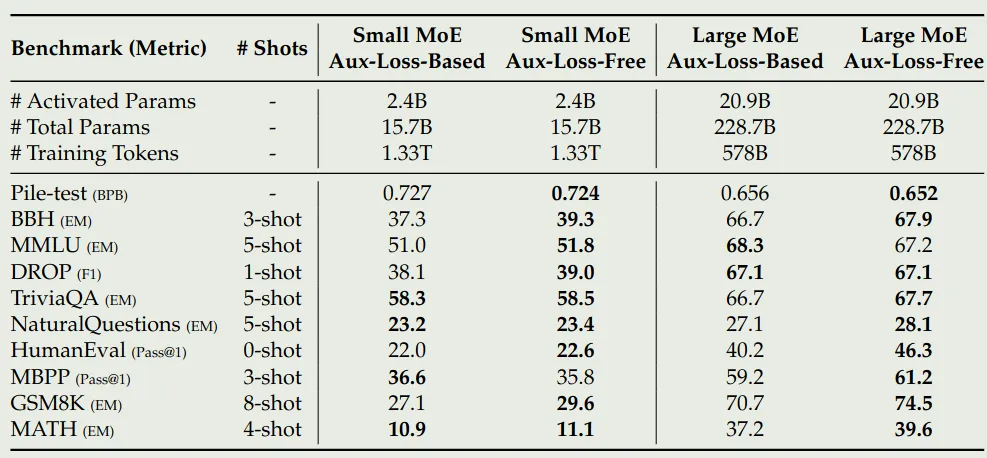
可以看到,loss-free Balancing 的效果比 loss balancing 的效果更好
接下来,作者对比了 loss-free balancing 和 sequence-wise auxiliary loss, 即 batch-wise v.s. sequence-wise. 作者认为,前者的约束更灵活,因为其不要求 in-domain balance. 作者在测试集上进行可视化,结果如下图所示
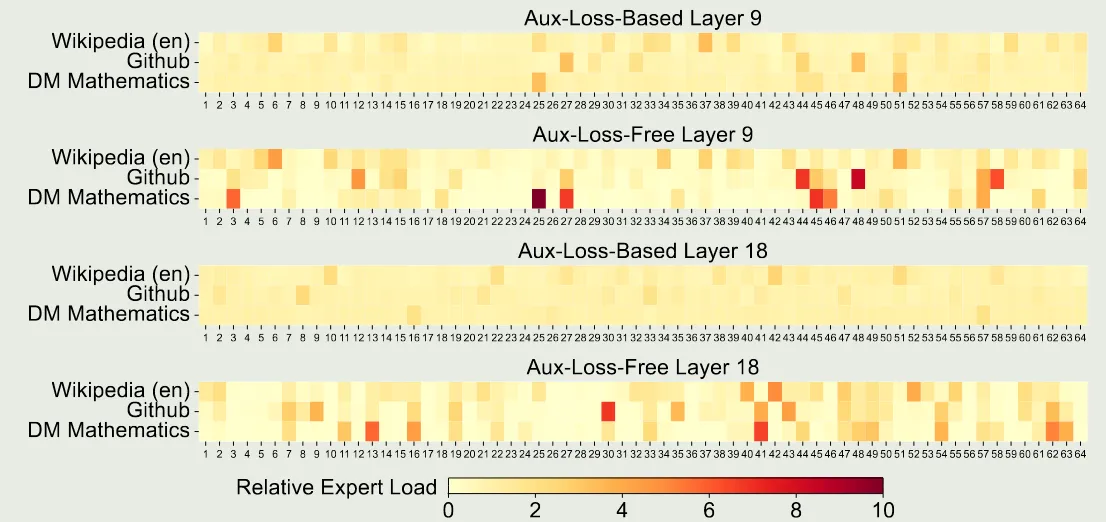
实验结果发现,loss-free 策略对应的 expert specialization 更强。作者进一步设计了一个 batch-wise auxiliary loss 来实现 batch-wise load balance, 结果发现,这种策略也能达到和 loss-free balancing 一样的效果,这说明了 batch-wise load balancing 效果更好
最后,作者提了两点 loss-free 策略的问题:
- 在特定的 sequence 或者小 batch 里出现负载不均衡。作者通通过增大 batch size 来解决这个问题
- 在推理阶段因为 domain-shift 导致的负载不均衡。作者实现了一个基于 redundant expert 的推理框架来解决这个问题
Post-training
SFT
post-training 包含 1.5M 样本,数据包括 reasoning 数据以及 non-reasoning 数据,前者由 DeepSeek-R1 合成,后者由 DeepSeek-V2.5 合成
SFT 时,作者训练了两个 epoch, 使用了 sequence packing 技巧
RL
Reward model 包含 rule-based reward model 和 model-based reward model.
RL 训练使用的算法为 GRPO
Performance
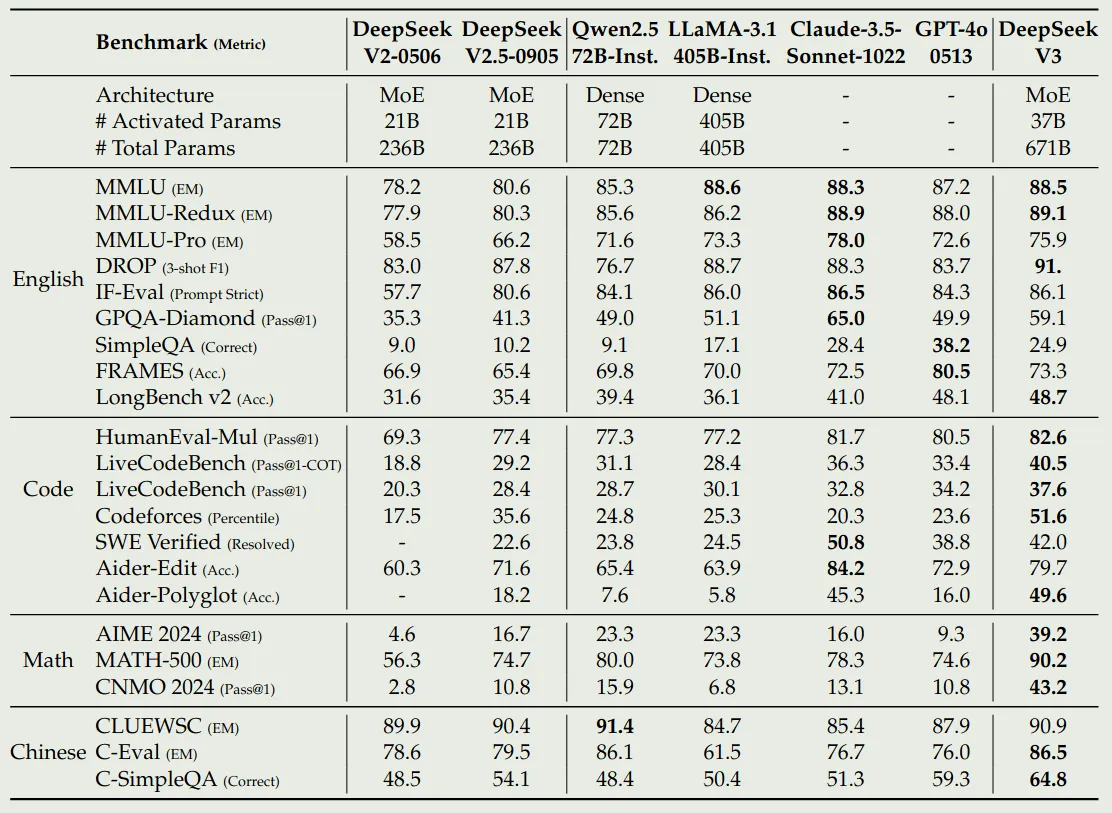
Discussion
作者首先探究了 Distillation 对模型表现的影响,作者使用 DeepSeek-R1 来蒸馏 DeepSeek-V2.5, 结果如下图所示
| Model | LiveCodeBench-CoT | MATH-500 | ||
|---|---|---|---|---|
| Pass@1 | Length | Pass@1 | Length | |
| DeepSeek-V2.5 Baseline | 31.1 | 718 | 74.6 | 769 |
| DeepSeek-V2.5 +R1 Distill | 37.4 | 783 | 83.2 | 1510 |
可以看到,distillation 可以显著提高模型的表现。但是其问题在于也会让模型输出的长度增加。作者认为知识蒸馏是 post-training optimization 的一个重要方向。
接下来,作者讨论了 self-rewarding, 具体做法就是使用 DeepSeek-V3 来对评估结果进行投票,结果发现最终的效果很好,作者认为 LLM 可以很好地将非结构化信息转换为 rewards.
最后,作者讨论了 MTP. MTP 可以于 speculative decoding 结合,进一步提高 decoding 的速度。通过实验作者发现,second token prediction 的接受率在 之间,说明了其有效性。
Conclusion
在本文中,作者提出了 DeepSeek-V3, 一个 671B-A37B 的 MoE 大语言模型,训练 token 数为 14.8T. 作者使用了 loss-free-balancing strategy 来实现负载均衡。训练时作者使用了 FP8 混合精度。评估发现 DeepSeek-V3 的达到了 SOTA 表现。
作者认为,DeepSeek-V3 model size 太大,不适合部署。第二,部署策略需要进一步改进。
最后,作者认为未来工作有以下几点:
- 改进模型架构,进一步提高训练以及推理效率,扩展模型的上下文
- 提升训练数据的数量和质量
- 提高模型的 reasoning 能力
- 更详尽的评估
DeepSeek V 3.2
作者首先回顾了开源模型如 MiniMax-01, Kimi-k2, Qwen3, GLM-4.5 和闭源模型的进展,作者指出,现在的开源模型和闭源模型在表现上仍然存在较大差距。作者认为这种差距主要是由于三个原因:
- Transformer 提出的 softmax attention 在处理长文本时效率非常低
- 已有的开源模型在 post-training 阶段使用的算力不够
- 开原模型的泛化和指令跟随能力不如闭源模型
基于这三个问题,DeepSeek-V3.2 (DeepSeek-AI et al., 2025) 分别进行了改进:
- 在架构上,作者提出了 DSA,一个高效的稀疏注意力机制,用于降低计算复杂度
- 在 post-training 阶段,作者使用了比 pre-training 阶段高 的算力,用于提高模型的能力
- 作者提出了一个 pipeline 用于提高模型在工具调用场景下的 reasoning 能力
通过实验作者发现,模型达到了和 Kimi-k2 以及 GPT-5 差不多的 reasoning 表现。
Method
Architecture
DeepSeek-V3.2 与 DeepSeek-V3.1 不同之处在于使用了 DeepSeek Sparse Attention (DSA). 架构如下图所示
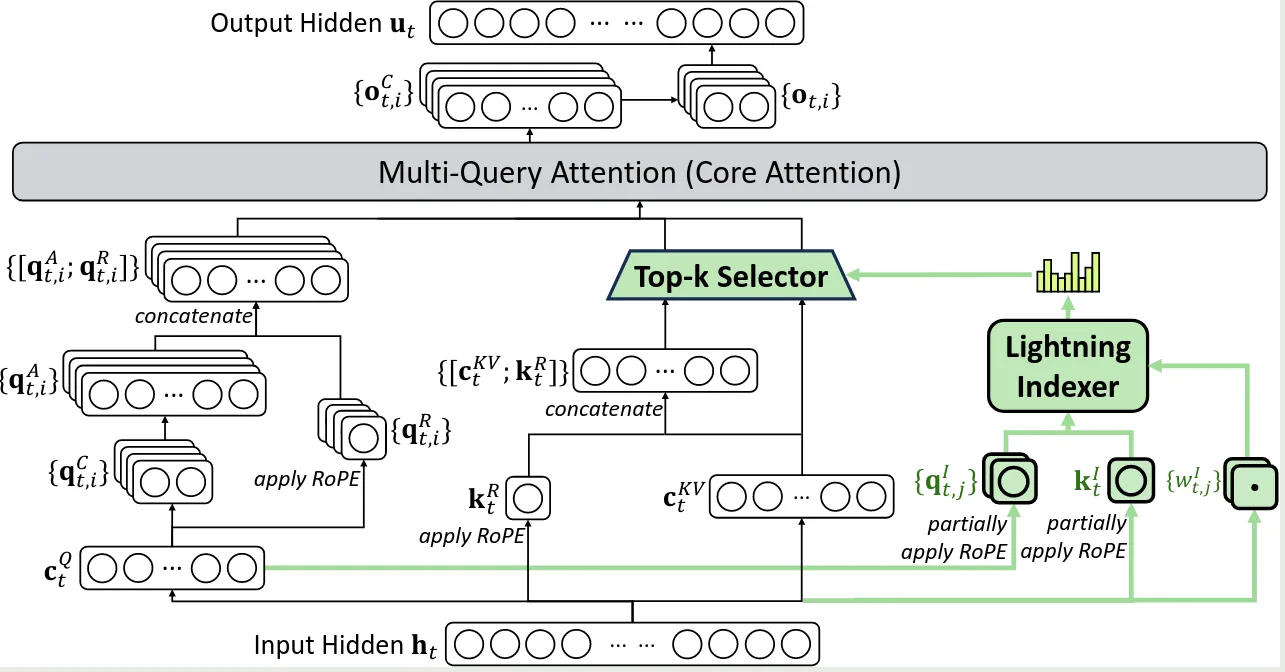
DSA 包含两个模块:
- lightning indexer
- fine-grained token selection mechanism
其中,lightning indexer 负责计算 query token 和一个 preceding token 之间的 index score 来决定 query token 选择的 token:
其中, 代表 indexer heads 的个数, 和 由 query token 得到, 由 preceding token 得到
给定 query token 对应的 index score , fine-grained token selection mechanism 负责选取 top-K index score 对应的 key-value entries , 然后 attention 的输出由 query token 个选取的 key value entries 得到:
[!Recall] MoBA 也提出了类似的方法,但是 MoBA 是一个无需训练的策略
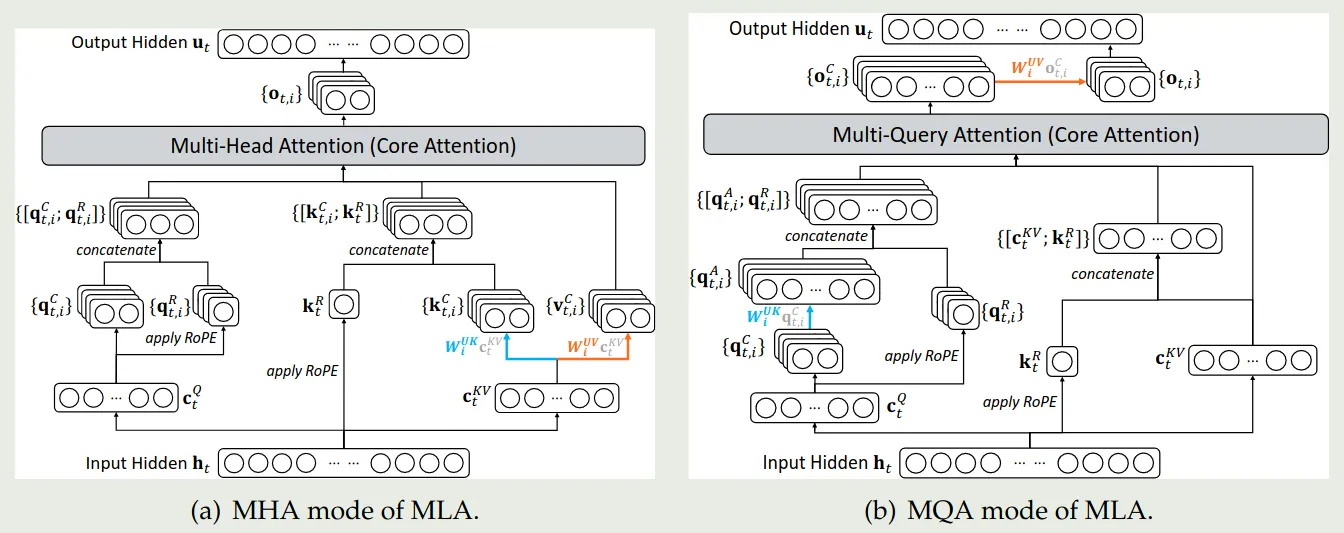
受 NSA 启发,作者实现了基于 MQA 模式的 MLA, 其中 latent vector 对于 query token 所有的 query heads 都是共享的。示意图如下所示
Continue Pre-training
作者在 DeepSeek-V3.1 的基础上进行了 continue pre-training. Continue pre-training 包含两个阶段:
Dense Warm-up stage 这个阶段用于训练 lightning indexer, 作者冻结除 lightning indexer 之外的参数,为了对齐 indexer output 和 main attention distribution, 对于第 个 query token, 作者首先计算所有 attention heads 的 main attention score 之和,然后在 sequence 层面进行 L1-normalization 得到 , 最后计算 lightning indexer 输出与 之间的 KL divergence:
这个阶段训练一共使用了 2.1B 的 token, lr 为 1e-3, 训练的步数为 1000 steps, batch size 为 16.
Sparse training stage 这个阶段模型所有的参数都参与训练,该阶段的目的是让模型学习到 DSA 的 sparse pattern. 训练时,作者让 lightning indexer 的输出与 之间的输出进行对齐,其中 :
实际训练时,lightning indexer 仅接受 的反向传播,而 LLM 则仅接受 next-token prediction loss. 这个阶段模型一共使用了943.7B token, 其中 设置为 . 学习率为 , 训练步数为 15,000 steps, batch size 为 480.
Post-training
post-training 与 DeepSeek-V3.1 一致:
Specialist Distillation 作者基于 DeepSeek-V3.2 base 构建了不同领域的 specialized model, 这些领域包括:
- math
- competitive programming
- general logical reasoning
- agentic coding
- agentic search
每个 specialized model 都使用 RL 进行训练,训练数据包括 long CoT reasoning 数据以及 direct response generation 数据,specialized model 训练完毕之后,就被用于生产 domain-specific data, 作者通过实验发现,基于这种蒸馏方法,模型的表现仅比 specialized model 低一点,并且这个 gap 可以被后续的 RL 训练所抵消。GLM-4.5 也采取了类似的做法
Mixed RL Training 作者使用了 GRPO 算法进行训练,与 DeepSeek-V3 不同,作者将 reasoning, agent 以及 human alignment 的 RL 训练合并为了一个阶段,作者认为这种方法可以平衡模型在多个 domain 上的表现,并且可以防止 multi-stage training 带来的灾难性遗忘问题。对于 reasoning 和 agent 任务,作者使用了 rule-basd outcome reward, length penalty 以及 language consistency reward. 对于通用任务,作者使用了 generative reward model, 每个 prompt 都有对应的 rubris 用于 evaluation. 作者构建 reward 时主要考虑了:
- length versus accuracy
- language consistency versus accuracy
DeepSeek-V3.2-Speciale 除了 DeepSeek-V3.2 之外,作者还训练了 DeepSeek-V3.2-Speciale 模型,该模型仅使用 reasoning 数据进行训练,reasoning 数据包含了 DeepSeek-Math-V2 的训练数据以及 reward 方法。训练时,作者降低了 length penalty 的惩罚系数,最终 DeepSeek-V3.2-Speciale 模型拥有更强的 reasoning 能力
Scaling GRPO
作者在 GRPO 的基础上对 KL estimate 进行了改进(见 KL divergence),使用了 importance sampling 对 K3 estimator 进行修正:
使用 K3 estimator 之后,现在 KL estimator 的梯度估计就变成无偏估计了,从而提高了整体训练的稳定性。作者还发现不同任务对 KL regularization 的需求不一致,对数学等 domain, 我们应该采取较小的 KL penalty 或者不使用 KL penalty 反而能提升性能
Off-Policy Sequence Masking 作者还使用了 sequence masking 来提高 off-policy data 的数据使用效率,由于不同 rollout 的完成时间不一致,训练过程中会出现 off-policy 现象,即某些 mini-batch 不是由当前 policy 产生,这个现象在 Magistral 中也有提到,这种训练 - 推理不一致性会进一步加剧 off-policy 程度,为了提高训练稳定性,作者将 policy divergence 程度比较高的 sequence 给 mask 掉,更新后的损失函数如下所示
其中,
用于决定是否对当前 sequence 进行 mask, 是一个超参数控制 policy divergence 程度。作者认为,模型主要从自身的错误进行学习,而 off-policy 的负样本模型学习提升有限甚至有害。作者发现加入这个 masking 策略之后,模型的训练稳定性有所提升。
Keep Routing MoE 模型在进行 On-policy RL 训练是,由于 policy 的更新,新 policy 和旧 policy 专家的 routing 可能会不一致,这种不一致性会降低训练的稳定性以及 off-policy 现象。为了解决这个问题,作者在采样室,保存了训练阶段所使用的 expert routing path, 来保证训练推理的一致性。这种策略可以有效提高针对 MoE 模型的 RL 训练稳定性
Keep Sampling Mask 作者发现,使用 top-p 和 top-K 可以提高 LLM 输出的质量,但是这种采样擦略也会导致 和 action space 的不匹配,因此,作者记录了 采样过程中的 truncation mask, 然后再训练的时候将其应用到 上,作者发现通过这种方式可以有效提高 RL 训练过程中的 language consistency
Thinking in Tool-Use
本节的目的是希望能够将 reasoning 能力应用到工具调用的场景下。
作者发现,如果使用 DeepSeek-R1 的策略,在下一轮对话到来时,丢弃到当前的 reasoning content 会让模型重新生成针对问题的 CoT, 从而产生 token inefficiency. 为了解决这个问题,作者构建了一个上下文管理策略,如下图所示
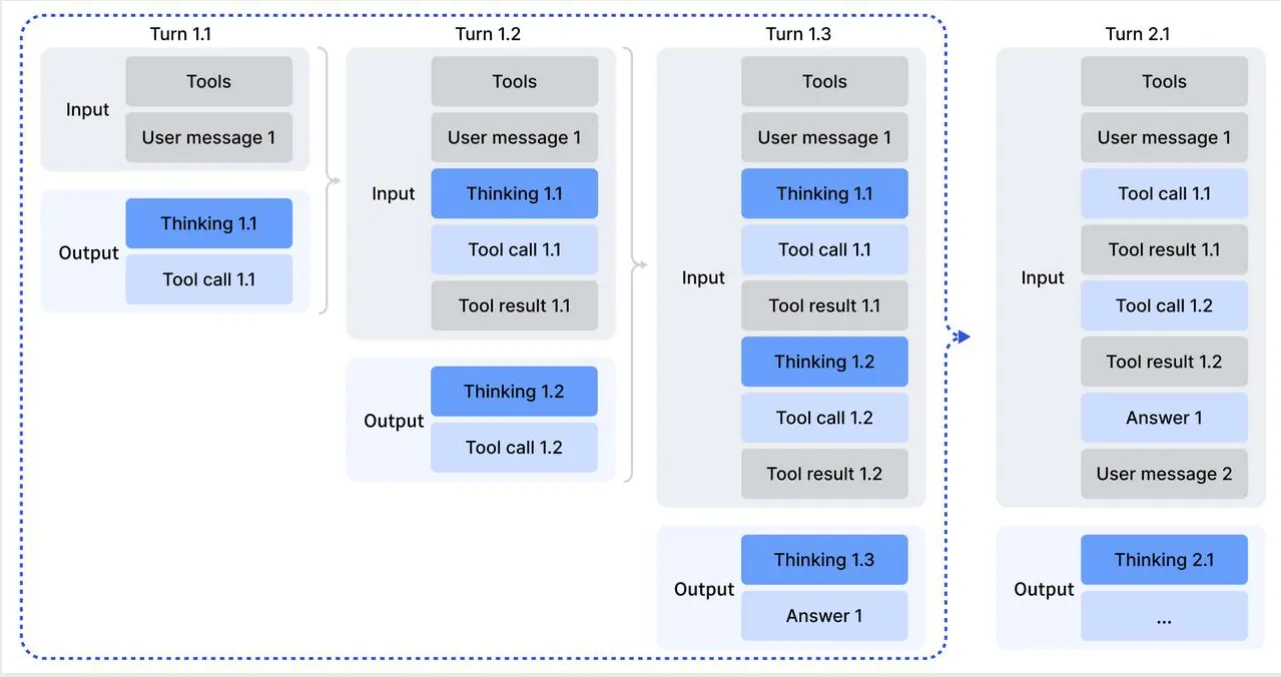
具体做法为:
- reasoning content 只有当有新的 user message 进入时才会丢弃;如果只有工具调用相关的 message, 则 reasoning content 会保留
- 移除 reasoning content 时,会保留对应的工具调用及其结果
在训练时,作者认为模型已经掌握了比较好的指令跟随能力,我们仅需要将 reasoning data (non-agentic) 和 non-reasoning data(agentic) 以不同的 prompt 输入给模型就能够得到比较好的结果。
对于训练的数据,作者认为 RL 任务的多样性可以有效提高模型的 robustness, 因此作者构建了不同的环境及其对应的 prompt, 生成的任务如下表所示
| number of tasks | environment | prompt | |
|---|---|---|---|
| code agent | 24667 | real | extracted |
| search agent | 50275 | real | synthesized |
| general agent | 4417 | synthesized | synthesized |
| code interpreter | 5908 | real | extracted |
- search agent: 作者使用了 multi-agent 的策略,包括 question-construction agent 用于构建 QA pair, multiple answer-generation agent 用于构建不同的 response, 一个 verification agent 用于评估生成的 response. 最后作者使用 generative reward model 来评分
- code agent: 作者爬取了 Github 上的 pull request, 然后进行过滤,接下来作者通过一个 environment-setup agent 来构建对应的环境
- code interpreter agent: 作者使用 jupyter notebook 作为代码解释器来解决复杂的 reasoning tasks, 包括 math, logic, data science 等
- general agent: 作者构建了验证简单解决困难的任务。首先作者基于 agent 和 task category 来生成或检索相关数据;接下来作者合成一个任务相关的工具集合;最后,作者让一个 agent 来提出任务以及对应的解法,并不断提高任务的难度。最后得到
<environment, tools, task, verifier>的 tuple 格式
Experiments
作者对比了 DeepSeek-V3.2-Exp 和 Claude-4.5 Sonnet, GPT-5, Gemini 3.0 Pro, Kimi-K2 thinking, MiniMax M2 的表现,评测结果如下
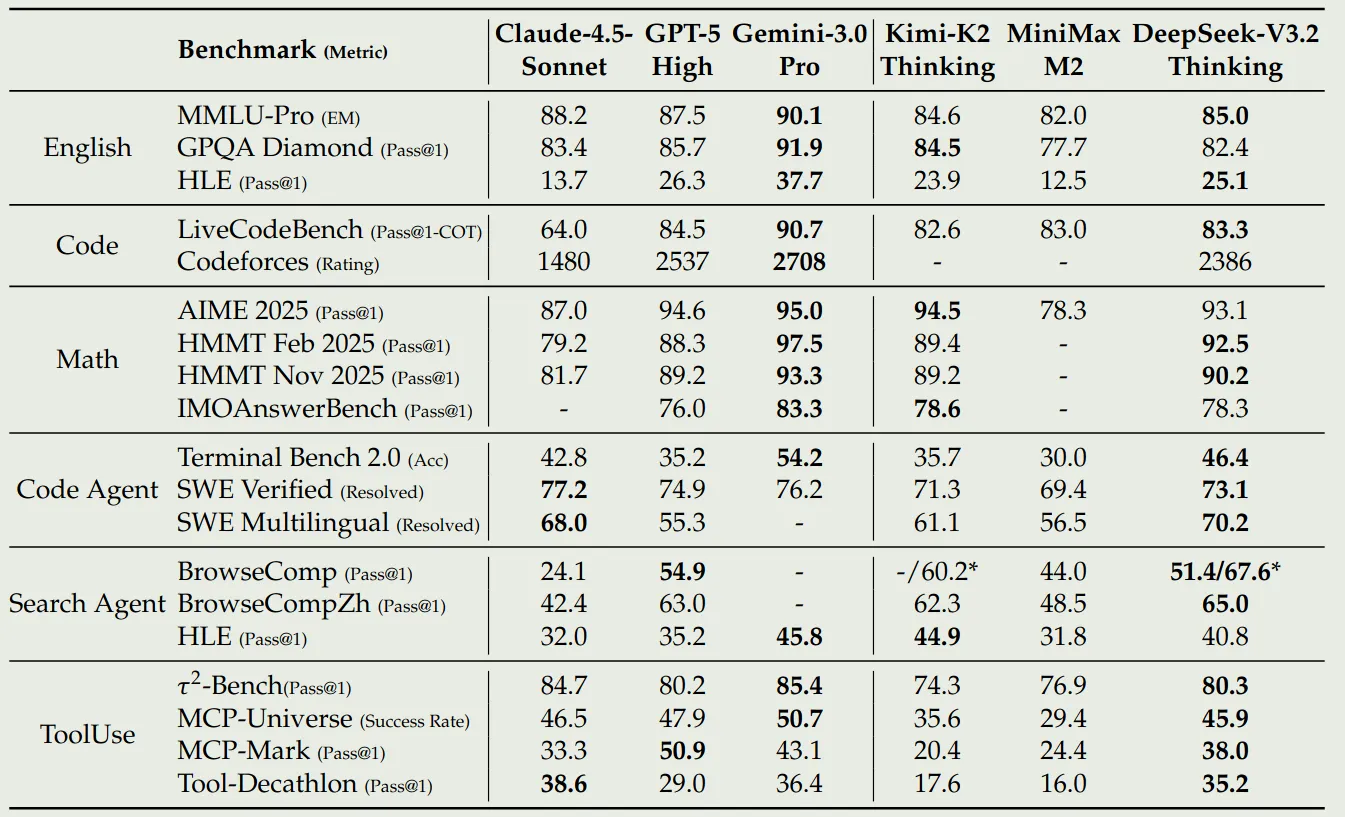
结果显示,DeepSeek V 3.2 和 GPT-high 在 reasoning 任务上的表现差不多。作者认为,进一步提高 RL 阶段的算力可以有效提高模型的表现
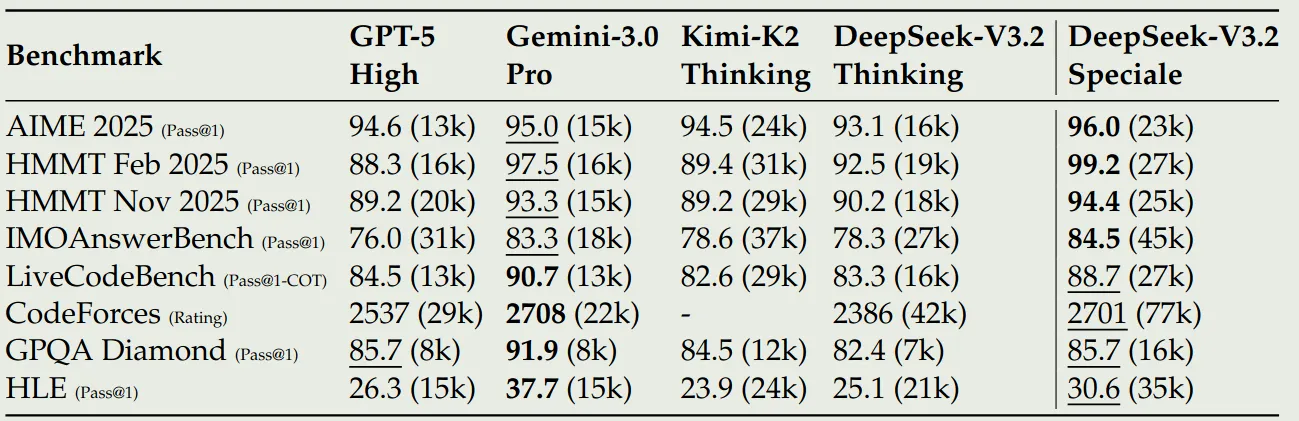
作者还对比了 DeepSeek-V 3.2-Speciale 的表现,结果显示,提高 token budget 之后,模型的表现显著提高,与 Gemini 3.0 Pro 可以相比,但是其 token efficiency 仍然弱于 Gemini 3.0 Pro, 结果如下图所示
接下来作者验证了 synthesis agentic tasks 对模型表现的影响。首先,作者随机采样一批样本使用闭源 LLM 进行测试,发现闭源模型表现最好为 , 这说明了合成数据对于 DeepSeek V3.2 和闭源模型都是有挑战的。
其次,作者探究了合成数据是否能够提高 RL 的泛化性,作者构建了两个额外模型:
- SFT: 在 SFT checkpoint 上进行 RL
- Exp: 仅在 search 以及 code environment 上进行 RL
对比结果发现,合成数据缺失可以有效提高模型的表现
作者还对比了 DSA 的效率,DSA 可以将 attention 的计算复杂度由 降低到 , 其中 是选取的 top-K tokens. 尽管 lightning indexer 的复杂度仍然是 , 但是其计算量远小于 MLA, 作者对比了两者的效率,实验结果如下图所示
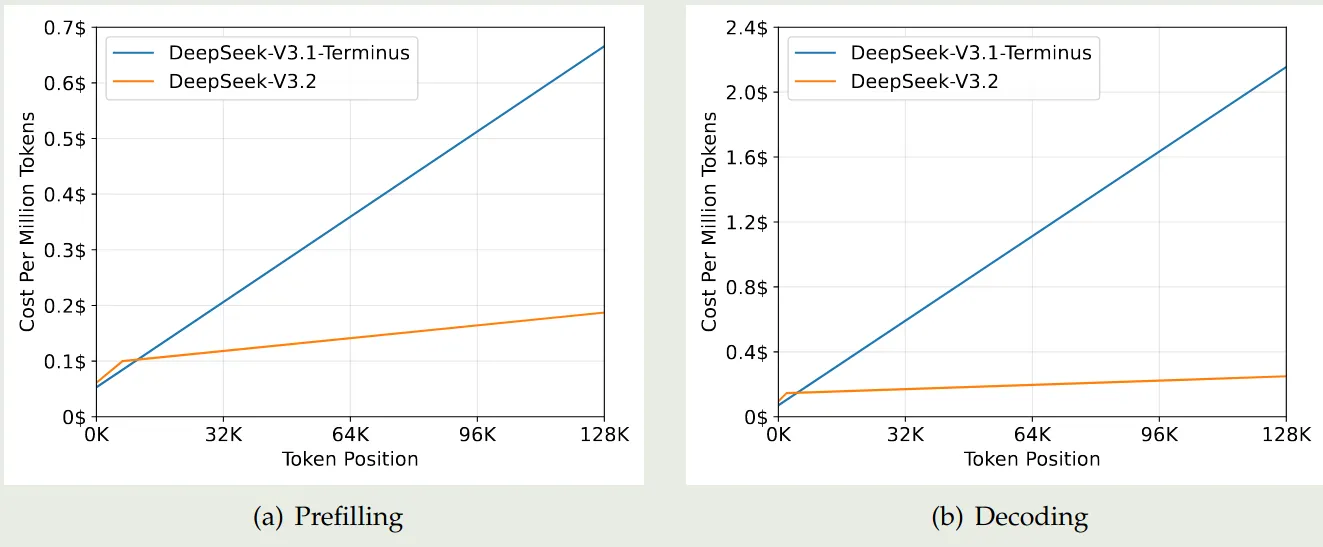
可以看到,DeepSeek-V3.2 的 prefilling 和 decoding 效率都远高于 DeepSeek-V3.1
最后,作者对比了不同上下文管理策略对模型表现的影响,对比策略有:
- Summary: 对轨迹进行总结然后重新初始化 rollout
- Discard 75%: 丢弃到初始 75% 的工具调用历史
- Discard-all: 丢弃掉所有的工具调用历史
- Parallel-fewest step: 多次采样然后保留步数最少得轨迹
实验结果如下图所示
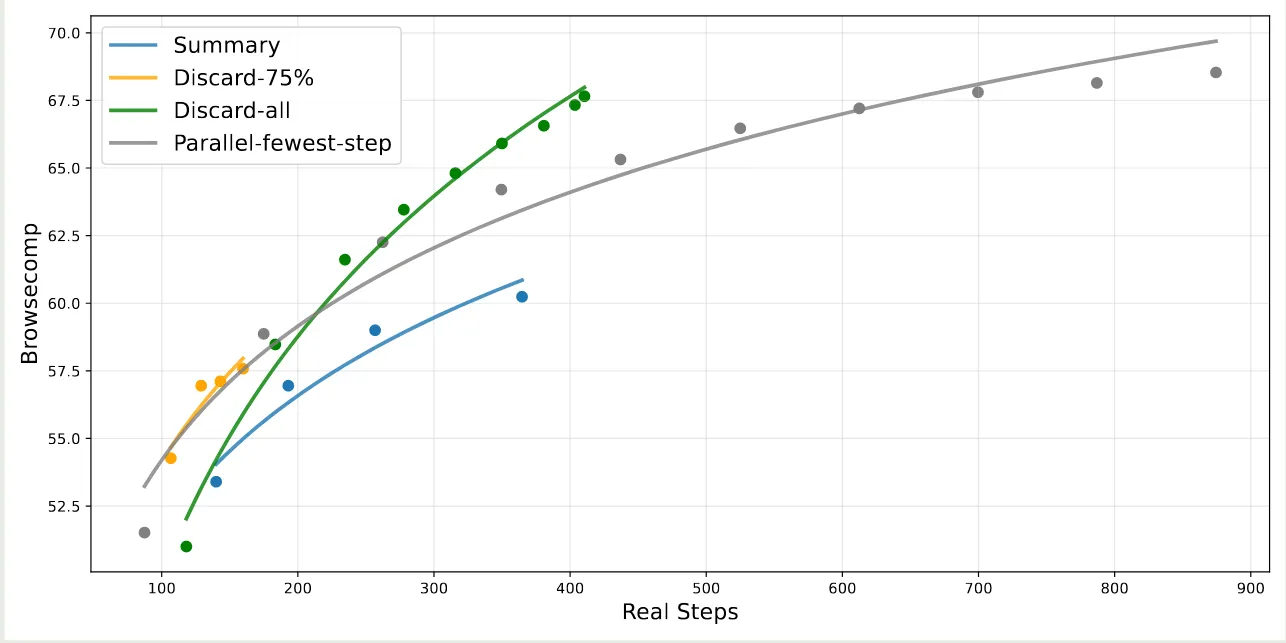
结果显示,使用上下文管理策略之后,模型的表现有了显著提升。并且,discard-all 策略虽然很简单,但是其表现非常好。作者认为如何根据不同场景来选取合适的策略是一个待解决的问题。
Conclusion
作者在本文中提出了 DeepSeek-V 3.2, DeepSeek-V 3.2 使用了一个稀疏注意力机制来提高模型在长上下文场景下的计算效率。作者还通过提升 RL 阶段的算力来提高模型在下游任务上的表现。最后,作者合成了大规模的 agentic task 来提升模型的 agent 能力。
作者认为,相比于 Gemini 3.0 Pro, 模型的知识广度仍然有限。并且,目前模型的 token efficiency 仍然是一个问题,模型需要更长的轨迹输出才能达到 Gemini 3.0 Pro 的表现。最后,模型解决复杂问题的能力仍然弱于闭源模型。
- DeepSeek-AI, Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., Lu, C., Zhao, C., Deng, C., Xu, C., Ruan, C., Dai, D., Guo, D., Yang, D., … Qu, Z. (2025). DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. https://arxiv.org/abs/2512.02556
DeepSeek-V4
DeepSeek-V4 在 DeepSeek-V3 的基础上进一步提高了在长上下文场景下的推理效率。
DeepSeek-V4 包含两个模型,模型配置如下表所示
| Model | DeepSeek-V4 Pro | DeepSeek-V4 Flash |
|---|---|---|
| total parameters | 1.6T | 284B |
| activated parameters | 49B | 13B |
Architecture
DeepSeek-V4 的架构如下所示
DeepSeek-V4 架构上主要有以下创新:
- 针对 DeepSeek-MoE 架构做了一些小的改动
- 将 residual connection 改进为 manifold hyper connection (mHC (Xie et al., 2026))
- 使用了 HCA, CSA 注意力机制来进一步压缩 KV cache 以及提高 attention计算效率
MoE
对于 MoE 模块,DeepSeek-V4 相比于 DeepSeek-V3 有以下变化:
- 将激活函数从
sigmoid()改进为Sqrt(Softplus()) - 增加了一个 sequence-wise balance loss 来实现 sequence 层面的负载均衡
- 移除了node 层面的负载均衡损失,通过并行策略优化来替代这个限制
- 移除了 DeepSeek-V3 中最开始的 3 层 FFN layers, 改用基于 hash routing 的 MoE layer.
mHC
在之前的 LLM 架构中,我们主要使用的是 residual connection (He et al., 2016), 即
这里 分别是第 层的输入和输出, 是 attention layer 或者 FFN layer.
Hyper-Connection (Zhu et al., 2025) 对 residual connection 进行了优化,增加了其表达能力,优化后的 residual connection 表达式如下
虽然 HC 通过扩展 channel 提高了模型的表征能力,但是,由于矩阵 是一个无约束的矩阵,因此很容易带来梯度消失或者爆炸,导致训练不稳定。
为了解决这个问题,DeepSeek-V4 在 HC 的基础上进一步使用了 mHC (Xie et al., 2026), 其关键思想是 将 residual mapping 限制到 Birkhoff polytope 上,其表达式如下:
通过增加 doubly stochastic matrix 这个限制,我们可以保证其谱范数始终小于等与1, 从而保证了残差链接的能力。
Attention
DeepSeek-V4 进一步使用了 Compressed Sparse Attention (CSA) 和 Heavily Compressed Attention (HSA) 来提高模型处理长上下文任务的效率。
Compressed Sparse Attention
Compressed Sparse Attention (CSA) 是 NSA (Yuan et al., 2025) 的一个改进版本。
在 NSA 中,我们构建了三个模块,分别是 token compression, token selection, sliding window 用于挑选上下文的一个子集参与 attention 计算。
CSA 则是先进行 token compression, 然后针对 compressed token 进行 token selection, 再将 selected token 和 sliding window token concate 到一起参与 attention 计算。 为了进一步压缩 KV cache, CSA 还使用了 MQA (Shazeer, 2019). 接下来我们采取 top-down 的形式详细介绍 CSA.
首先,我们使用了 MQA 来计算 attention:
这里 是 第 个 head 对第 个 token 的 attention output. 和 分别是 token selection, sliding window 对应的 key 和 value.
接下来,我们来介绍 CSA 中的 token selection. Token selection 的目的是挑选出一部分 token 来参与 attention 计算。 之前一般采用 block selection 方法,即将 context 分割为若干个 block, 然后计算每个 block的重要性程度,最后进行挑选。 CSA 在之前的方法上进行了扩展,既然我需要在 block 层面进行计算,为何我不直接存储每个 block 的信息? 也就是说,我现在直接存储 block 对应的 KV cache, 然后再进行挑选与计算。 此时,我们需要两个模块:
- compressor: 负责将 个 token 压缩为 个
- selection: 从压缩后的 token sequence 中进行挑选
Compressor Compressor 的目的是将一个包含 个 token 的 block 压缩为 个 entry
其计算逻辑图如下
可以看到,在压缩时,压缩后的每个 entry 依赖于其前后两个 block.
计算时,对于第 个输出 ,其依赖原始输入 hidden states 中的两个相邻的 block. 我们记输入的的 hidden state 为 , 这两个相邻的 block 为 和 , 对应的压缩步骤为
其中 , 是 head dimension. 同时,我们还需要像 SwiGLU 的 gate 来计算重要性
这里 , . 最后我们基于 weights 和 entry 来得到最终的结果
通过这个方式,我们就将原始的 hidden state 压缩为了 .
Selection 接下来,CSA 进一步通过 selection 的方法提高了 attention 的计算效率。 Selection 主要是通过 Indexer 来实现的。 Indexer 也包括一个 Compressor 用于计算 compressed keys . 接下来就是 index score 的计算
最终 CSA 得到的用于参与 MQA 计算的 KV entry 为
对于 CSA, 我们需要存储的 KV cache 大小为 , 其中 是 sliding window 的 kv cache, 是 选择出来的 top-K entry.
Heavily Compressed Attention
与 CSA 不同, HCA 只做 compression 不做 selection, 因此其不包含 Indexer 模块。 并且 HCA 的 compression ratio 来保证更高的压缩率。 此时 attention 计算为
这里 query 与上面计算一致, 为 sliding window 对应的 entry.
compressed entry 计算相比 CSA 也更简单,其只需要一个 block , 计算方式如下
这里 , .
此时,HCA 的 KV cache 大小为 , 也就是将序列压缩为了原来的 , 然后附加一个 sliding window.
Analysis
我们来对比一下不同的 attention (只考虑 single layer)
| Attention | selection | compression | KV cache | Note |
|---|---|---|---|---|
| MHA | No | None | ||
| GQA | No | No | ||
| SWA | latest | No | ||
| MLA | No | kv sharing | ||
| MoBA | top blocks | No | block size is also | |
| NSA | top + latest | |||
| CSA | top + latest | , | kv sharing | |
| HCA | No | , | , kv sharing |
这里 是 sequence length, 分别是 number of kv heads, number of attention heads, 是 head dimension. 为了方面,这里我们将 sliding window size, topK, compression block size 都设置为 .
可以看到,CSA 和 HCA集成了 NSA 和 MLA 各自的优势,即先基于 MLA 进行降维降低计算量,然后通过 token compression, token selection 来进一步压缩 kv cache. 其中 CSA 使用较小的 compression ratio 来进行细粒度 token selection, 而 HCA 则使用较大的 compression raio 来实现 kv cache 压缩.
Other details
- grouped output projection: 避免 output projection 计算开销太大,计算先降维再升维度。
- normalization: 使用 QK norm 来提高训练稳定性
- RoPE: 和 MLA 一样的 partial RoPE.
- attention sink: 使用和 GPT-oss (Agarwal et al., 2025) 一样的技巧来避免 attention sink 的影响
Configuration
以下是 DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 的配置对比总结表:
| 配置项 | DeepSeek-V4-Flash | DeepSeek-V4-Pro |
|---|---|---|
| Transformer 层数 | 43 | 61 |
| 隐藏维度 | 4096 | 7168 |
| 前两层注意力类型 | 纯滑动窗口注意力 | HCA |
| 后续层注意力模式 | CSA 与 HCA 交错 | CSA 与 HCA 交错 |
| CSA 压缩率 | 4 | 4 |
| CSA 索引查询头数 | 64 | 64 |
| CSA 索引头维度 | 128 | 128 |
| CSA 稀疏注意力 top‑k | 512 | 1024 |
| HCA 压缩率 | 128 | 128 |
| 查询头数 | 64 | 128 |
| 头维度 | 512 | 512 |
| 查询压缩维度 | 1024 | 1536 |
| 输出投影组数 | 8 | 16 |
| 中间注意力输出维度 | 1024 | 1024 |
| 滑动窗口大小 | 128 | 128 |
| MoE 层位置 | 所有 Transformer 块 | 所有 Transformer 块 |
| 前 3 个 MoE 层路由策略 | Hash 路由 | Hash 路由 |
| 共享专家数 | 1 | 1 |
| 路由专家数 | 256 | 384 |
| 每个专家的中间维度 | 2048 | 3072 |
| 每 token 激活的路由专家数 | 6 | 6 |
| 多 token 预测深度 | 1 | 1 |
| mHC 扩展因子 | 4 | 4 |
| Sinkhorn‑Knopp 迭代数 t_max | 20 | 20 |
| 总参数量 | 284B | 1.6T |
| 每 token 激活参数量 | 13B | 49B |
Training
Muon Optimizer
针对非矩阵参数,作者使用了 AdamW [@AdamW] 优化器,针对其他模块参数,作者使用了 Muon [@Muon] 优化器。 算法伪代码如下
Intialization: lr , momentum , weigth decay , rescaling factor
For each training step
-
For each logically independent weight
-
EndFor
EndFor
对于 Newton-Schulz Iterations, 作者迭代了10次,前8次使用的系数为 , 后2次使用的系数为 .
Pre-training
训练时,作者首先使用 dense attention 训练 1T token, 然后切换为 sparse attention.
两个导致训练不稳定的问题:
- Anticipatory Routing: 解耦 routing network 和 backbone network 的更新可以提高训练稳定性。
- SwiGLU clamping: 使用了 GPT-oss 的 SwiGLU clamping 策略。
Post-training
Post training 阶段 DeepSeek-V4 将 DeepSeek-V3.2 的 offline distillation 替换为了 online policy distillation (OPD), 其训练流程如下所示
每个 specialist 都经过 SFT 和 RL (GRPO) 算法进行训练,训练时,作者为每个 specialist 设计了三种思考模式:
- Non-think, 直接输出答案
- Think High, 正常进行思考
- Think Max, 最强思考模式
对于 RLHF 这类需要 reward model 的任务,作者构建了 rubric-guided RL data 并将模型同时作为 reward model 和 policy model 来进行训练,进而提高模型的表现。
OPD 的损失函数如下所示
这里 是对应的 specialist, 是 policy model, 是对应的权重。
由于现代大模型词表一般较大,因此现有做法一般是使用 single token 来近似 KL divergence, 即
这个估计虽然是无偏的,但是方差很大。 为了解决这个问题,作者使用了原始 KL divergence 定义,对于带来的计算量问题,作者在 infra 层面进行了优化。
Data
pre-training 阶段使用了 32T token, 使用了 token-splitting, fill-in-the middle 和 packing.
对于工具调用,DeepSeek-V4 提出了一个基于 XML 格式的 schema, 形式如下所示
DeepSeek-V4 tool-call schema
<|DSML|tool_calls>
<|DSML|invoke name="$TOOL_NAME">
<|DSML|parameter name="$PARAMETER_NAME" string="true|false">$PARAMETER_VALUE
</|DSML|parameter> ...
</|DSML|invoke>
<|DSML|invoke name="$TOOL_NAME2"> ...
</|DSML|invoke> </|DSML|tool_calls>
作者认为这种格式可以减少 excaping failures 以及 reduce tool-call errors.
Kimi-K2 (Team et al., 2026) 使用了 TypeScript 来减少工具调用所使用的上下文。
对于上下文管理,DeepSeek-V4 没有采用 DeepSeek-V3.2 的做法,而是保留了全部的工具调用内容,让模型能够更好的利用上下文来进行思考。 DeepSeek-V4 针对不同的场景使用了不同的策略:
- 对于工具调用场景,模型会保留完整的 reasoning history
- 对于通用对话场景,模型会丢弃之前的思考过程,仅保留上一轮的答案
针对工具调用,作者还介绍了 Quick Instruction, 也就是使用模型本身来进行意图识别。 之前的做法是用一个小模型来进行判断,但是这样无法利用模型的 kv cache, 作者通过在 prompt 之后加入一个特殊的 token 来完成这个任务。 此时模型就可以复用 kv cache 进而降低 latency.
Infra
Attention
为了提高 attention 计算效率与降低内存消耗,DeepSeek-V4 使用了如下改进
- RoPE dimension 使用 BF16 精度来存储 RoPE, non-RoPE 使用 FP8 精度
- lightning indexer 使用 FP4 精度来计算.
- 更小的 top-K 来实现 sparse attention
Expert Parallelism
通过 communication-computation overlap 来提高 Expert Parallelism (EP) 的计算效率。
Batch Invariance
Attention 为了保证 single sequence 和 batch 推理的结果一致,作者没有使用 FlashDecoding (Dao et al., 2023) 提出的 split-kv 方法,但是不使用这种方法会导致 wave-quantization 问题,即最后一个 wave 里只有少部分 SM 在工作,GPU 利用效率低。
DeepSeek-V4 使用了 Dual-Kernel 策略,第一个阶段让一个序列只在一个 SM 中计算,第二个阶段将序列拆分到多个 SM 上进行计算,为了保证与 一个 SM 中计算的结果一致,作者设计了严格的计算路径,确保和一个 SM 计算的结果一致。
Matrix Multiplication DeepSeek-V4 使用自研的 DeepGEMM 来解决 cuBLAS 没有 batch invariance 的问题。
在训练时,DeepSeek-V4 发现不稳定性主要是反向传播阶段,作者通过使用额外的显存来保证训练的唯一性:
- attention backward: 给每个 SM 分配独立的 buffer, 然后再用 deterministic summation 来进行求和
- MoE backward: all to all 之前,本地对 token 进行严格排序,确保发送的数据有序;并且在接收端,也设置 buffer
- mHC: mHC 又一个非常小的矩阵乘法,作者修改了 split-K 的行为,不允许 SM 在计算过程中直接用原子加法往最终结果里写数据,而是算完之后再使用 deterministic summation 来进行求和
Pre-Training
首先,作者针对 Muon 构造了一个分布式策略,由于 Muon 需要完整矩阵来计算,DeepSeek-V4 做了以下优化:
- 通过限制 ZeRO (Rajbhandari et al., 2020) 的 rank size 来避免通信效率低,
- 使用了背包算法进行最优组合分配,让每张卡的矩阵总大小尽可能均衡
- 对较小的 bucket 进行了 padding
- 当 DP rank size 过高时,每个 DP rank 独立计算 Muon
在计算时,作者发现使用 BF16 精度进行 Muon 计算也很稳定,为了避免低精度累加产生累计误差,作者仅使用 all to all 完成数据的通信,通信完成之后,在某一个 rank 上使用 FP32 进行累加。
对于 mHC, 作者进行了如下优化:
- kernel fusion
- selective checkpointing
- 调整了 DulePipe 1f1B overlapping scheme
Context Parallelism
对于 sparse attention, CP 有两个问题:
- length variation: 每个 rank 中的实际 KV 长度不一致,通常小于 , 无法直接通信
- boundary: 压缩需要连续的 个 entry, 但是这可能涉及不同卡之间的通信。
为了解决这个问题,DeepSeek-V4 做了如下优化:
- 第 imi+1$ 个 GPU
- 第 个 GPU 将其与自己的 个 token 拼在一起
最后,大家统一通过 padding 形成固定长度 , 保证所有 GPU 的数据形状一样。
AllReduce 之后,作者通过算子将中间的 padding 数据全部剔除,把 padding 放到序列的末尾。
Checkpointing
DeepSeek-V4 还实现了 tensor 级别的 checkpointing 机制,通过这个机制我们可以在 Tensor 级别来标记需要 checkpointing.
Inference
在 inference 阶段,由于采用了 hybrid attention, 因此内存管理非常复杂,这里有以下四类数据:
- CSA/HCA: 两个 attention 的 compression ratio 不一致,无法用统一的内存管理方式管理
- SWA: SWA 具有 cache hit 和 cache eviction 策略,存储内容一直在变
- pending buffer: 对于未来得及压缩的 hidden state, 也许要进行保存,直到满 个才进行释放。
为了解决内存管理问题,DeepSeek-V4 主要在 memory layout 和 on-disk storage 两个方面进行改进。
在内存上,作者设计了 state cache 用于存储 SWA 和 pending buffer, 并且作者还通过 co-design 方式来实现一个定制的 sparse attention kernel.
对于 KV cache, 由于 CSA 和 HCA 的内存较小,所以作者直接全量保存。对于 pending buffer, 作者重新进行计算。 对于 SWA KV cache, 由于 SWA kv cache 为 CSA/HCA 的 8 倍左右,作者提出了三种策略:
- Full caching: 全部保存,没有计算冗余,但是会导致 write-intensive, 对 SSD 不友好
- Periodic checkpointing: 设置不差个 , 没隔 个 token checkpoint 一下
- Zero Caching: 不存,使用已有的 CSA 和 HCA 重新计算,磁盘占用小
Post-training
作者在 post-training 阶段使用了 Quantization-Aware Training (QAT, (Jacob et al., 2018)) 来提高模型在 quantization 之后的表现。 作者在两个模块上使用了 FP4 quantization:
- MoE expert weights
- QK path
对于 index score, 作者在 QAT 过程中使用了 BF16 精度。
经过训练之后,在推理阶段,作者直接使用 FP4 quantized weights 来进行推理。
对于 OPD, 作者进行了如下优化:
- 所有 teacher model 的权重都进行 offload
- 保留 teacher model 最后一层的 hidden states, 避免计算
lm_head - 按照 teacher model index 来加载数据,使得在一个 mini-batch 里只需要加载一个 teacher model 的 hidden states
- 使用 TileLang kernel 来优化
lm_head以及 KL divergence的计算
对于长上下文推理,作者使用了 token level WAL, 每生成一个 token 就保留对应的 KV cache, 这样下次重新生成时就可以直接利用已有的 kv cache 继续生成。
Performance
Discussions
- 保留了一些验证过的模块和 tricks
- Anticipatory Routing 和 SwiGLU Clamping 的内部机制仍然不清晰
- 探究新的 sparsity 维度
- 探究 low-latency architectures
- long-horizon, multi-round agentic tasks
- multimodality
- data curation and synthesis strategies.
- Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R. K., Bai, Y., Baker, B., Bao, H., & others. (2025). gpt-oss-120b & gpt-oss-20b model card. arXiv Preprint arXiv:2508.10925.
- Dao, T., Haziza, D., Massa, F., & Sizov, G. (2023). Flash-Decoding for long-context inference. https://pytorch.org/blog/flash-decoding/
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778. 10.1109/CVPR.2016.90
- Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., & Kalenichenko, D. (2018, June). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Rajbhandari, S., Rasley, J., Ruwase, O., & He, Y. (2020). ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. https://arxiv.org/abs/1910.02054
- Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need. https://arxiv.org/abs/1911.02150
- Team, K., Bai, Y., Bao, Y., Charles, Y., Chen, C., Chen, G., Chen, H., Chen, H., Chen, J., Chen, N., Chen, R., Chen, Y., Chen, Y., Chen, Y., Chen, Z., Cui, J., Ding, H., Dong, M., Du, A., … Zu, X. (2026). Kimi K2: Open Agentic Intelligence. https://arxiv.org/abs/2507.20534
- Xie, Z., Wei, Y., Cao, H., Zhao, C., Deng, C., Li, J., Dai, D., Gao, H., Chang, J., Yu, K., Zhao, L., Zhou, S., Xu, Z., Zhang, Z., Zeng, W., Hu, S., Wang, Y., Yuan, J., Wang, L., & Liang, W. (2026). mHC: Manifold-Constrained Hyper-Connections. https://arxiv.org/abs/2512.24880 back: 1, 2
- Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., Xie, Z., Wei, Y., Wang, L., Xiao, Z., Wang, Y., Ruan, C., Zhang, M., Liang, W., & Zeng, W. (2025). Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). https://aclanthology.org/2025.acl-long.1126/
- Zhu, D., Huang, H., Huang, Z., Zeng, Y., Mao, Y., Wu, B., Min, Q., & Zhou, X. (2025). Hyper-Connections. The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=9FqARW7dwB