Introduction
Keye-VL 系列是快手 Kwai 团队提出的一个多模态大模型系列,这个系列主要强调了模型的视频理解能力。
模型架构变化如下
| Model | Keye-VL | Keye-VL 1.5 | Keye-VL 2.0 |
|---|---|---|---|
| Parameters | 8B | 8B | 30B-A3B |
| ViT | SigLIP-400M-384-14 | same | same |
| MLP | Patch Merger | same | same |
| LLM | Qwen3-8B | same | Qwen3-A30B-A3B-Thinking-2507 |
模型表现如下图所示
- 一开始的短视频理解是一个很实际的需求,是一个小而精的赛道
- 从 2.0 开始,感觉是啥都想做,还要对比 Qwen3.5, 我认为比较难达到相同级别的表现
- 总的来说,如果啥都想做,可能啥都没有
Keye-VL
Keye-VL (Team et al., 2025) 是快手在 25 年 7 月份提出的一个 8B 的多模态大模型,其亮点为短视频理解能力。
作者强调理解短视频仍然是一个很难的任务,特别是要求模型基于 video 和 audio 来理解视频。 因此,在本文中,作者提出了 Kwai Keye-VL,一个 8B 的多模态大模型,主要用于短视频理解任务。
Architecture
Keye-VL 是一个标准的 ViT-MLP-LLM 的架构,其中
- ViT 是 SigLIP-400M-384-14 (Zhai et al., 2023)
- MLP 是一个基于 SwiGLU (Shazeer, 2020) 的 2 层 MLP,使用了和 Qwen2.5-VL (Bai et al., 2025) 一样的 patch merge 方法
- LLM 使用的是 Qwen3-8B (Yang et al., 2025)
作者针对 ViT 和 visual encoding 分别做了如下改进
NaViT
作者实现了 native resolution ViT,来处理不同分辨率的图片。 具体做法为
- 基于 SigLIP-400M-384-14 (Zhai et al., 2023) 来初始化 ViT (Dosovitskiy et al., 2021)
- 采用 interpolation 来处理 ViT 的 position encoding 用于支持不同的图片输入。
- 使用 2D RoPE 来进一步 attention 对于空间位置信息的利用。
- 使用 NaViT 的 packing 技巧来继续预训练 ViT.
在 ViT 预训练的过程中,作者使用了 SigLIP loss, 用 500B 的 token 进行 continue pre-training.
Visual Encoding
为了提升模型理解图片和视频的能力,作者针对图片和视频也进行了处理。
- 对于图片,作者将最大 token 个数设置为 16384
- 对于视频,作者将每帧的 token 数限制在 , 每个视频的最大 token 个数设置为 24576
- 对于提取的 frames, 作者重新计算了 FPS, 然后在 3D RoPE 中让时间维度与真实时间严格对齐。
Data
Pretraining Data
预训练数据一共包括 600B token,覆盖了 6 个类别:
- Image caption: 包括中英文数据,来源为 LAION, DataComp 以及 Coyo.
- OCR & VQA: 数据包括开源数据和合成数据。
- Grounding & Counting: Grounding 数据主要包括 RefCoCo, VisualGenome, TolokaVQA, Counting 数据包括 PixMo.
- Interleaved text-image data: 主要从 academic PDF 以及结构化知识中提取对应的数据
- Video understanding: 作者使用 Qwen2.5-omni 从 interleaved video-ASR 来将视频数据转化图文交错数据, 然后基于 ASR 的结果进行 recaption,最后对每一帧进行 OCR.
- Pure Text: 未提及
数据清洗:
- 使用 CLIP 对数据进行打分,然后过滤掉低质量的数据
- 使用开源的 MLLM 作为 discriminator 来选择高质量的数据
- 去重
Training
Pre-training
预训练包括 4 个 stage:
- Stage 0: 使用 SigLIP 损失函数来继续训练 ViT
- Stage 1: cross-modal Alignment,仅训练 MLP
- Stage 2: multi-task pre-training, 解冻所有参数,使用 Multi-task 数据来训练模型
- Stage 3: annealing, 在高质量数据集上进行 fine-tune,进一步提升模型的能力
作者发现,预训练后的模型在下游任务上的表现对训练数据配比非常敏感。 为了解决这个问题,在最后一个训练阶段,作者使用了一个 merging 的技巧,来保持模型的能力。
Post-training
post-training 阶段一共包含了 2 个 step, 5 个 stage:
- Step 1: 包含 2 个 stage,用于提升模型的 non-reasoning 能力
- Stage 1.1: SFT, 70k tasks galaxy, 200k filtered QA pair, human annotated image/video captions
- Stage 1.2: MPO (Wang et al., 2025), 400K open sourced data, 50K preference samples, 10k RFT data, 90K text data, 30k human annotated data,
- Step 2: 包含 3 个 stage, 用于提升模型的 reasoning 能力
- Stage 2.1: CoT Cold-Start: 330K non-reasoning samples, 230K reasoning samples, 20K automatic samples, 100K agentic reasoning samples 32K video data (24k reasoning/ 8k non-reasoning)
- Stage 2.2: Mix-Mode RL: 4 个任务,训练算法为 GRPO (Shao et al., 2024)
- Multimodal perception: 复杂文本识别和 counting 任务
- Multimodal reasoning: MMPR (Wang et al., 2025b) 和 MM-Eureka (Meng et al., 2025)
- Text-based mathematical reasoning: 数学推理问题
- Agentic reasoning: 从 DeepEyes 中获取的 47,000 条样本
- Stage 2.3: Iterative Alignment, 解决重复性输出或者 logic error 问题,基于 MPO (Wang et al., 2025a) 算法
Discussion
作者讨论了两点关键发现:
- reasoning 和 non-reasoning 的数据可以互相促进彼此的表现,这与 ERNIE 4.5 的发现一致。
- 作者认为通过 mix-mode 的训练,模型在简单和复杂任务上的表现都可以提升,因此作者使用了混合数据来进行训练,结果发现效果很好。
作者认为 keye-VL 仍然存在以下问题
- 并没有优化 video encoder 或者是改进 video encoding 的策略
- Keye-VL 的视觉感知能力有进一步的提升空间,其 “reasoning with image” 能力依然落后于领先的 reasoning model
- 使用一个额外的 MLLM 作为 reward model 会极大消耗算力,如何构建一个更可靠更高效的 reward model 需要进一步探索。
- Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., … Lin, J. (2025). Qwen2.5-VL Technical Report. https://arxiv.org/abs/2502.13923
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations. https://openreview.net/forum?id=YicbFdNTTy
- Meng, F., Du, L., Liu, Z., Zhou, Z., Lu, Q., Fu, D., Han, T., Shi, B., Wang, W., He, J., Zhang, K., Luo, P., Qiao, Y., Zhang, Q., & Shao, W. (2025). MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning. https://arxiv.org/abs/2503.07365
- Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., & Guo, D. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. https://arxiv.org/abs/2402.03300
- Shazeer, N. (2020). GLU Variants Improve Transformer. https://arxiv.org/abs/2002.05202
- Team, K. K., Yang, B., Wen, B., Liu, C., Chu, C., Song, C., Rao, C., Yi, C., Li, D., Zang, D., Yang, F., Zhou, G., Peng, H., Ding, H., Huang, J., Cao, J., Chen, J., Hua, J., Ouyang, J., … Zhang, Z. (2025). Kwai Keye-VL Technical Report. https://arxiv.org/abs/2507.01949
- Wang, W., Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Zhu, J., Zhu, X., Lu, L., Qiao, Y., & Dai, J. (2025a). Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization. https://arxiv.org/abs/2411.10442 back: 1, 2
- Wang, W., Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Zhu, J., Zhu, X., Lu, L., Qiao, Y., & Dai, J. (2025b). Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization. https://arxiv.org/abs/2411.10442
- Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., … Qiu, Z. (2025). Qwen3 Technical Report. https://arxiv.org/abs/2505.09388
- Zhai, X., Mustafa, B., Kolesnikov, A., & Beyer, L. (2023). Sigmoid Loss for Language Image Pre-Training. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 11941–11952. 10.1109/ICCV51070.2023.01100 back: 1, 2
Keye-VL 1.5
基于 Keye-VL, 快手在 25年9月 提出了 Keye-VL 1.5 (Yang et al., 2025), Keye-VL-1.5 相比于 Keye-VL 主要做了三点改进:
- 在架构上,使用了 Slow-Fast Video Encoding
- 在预训练阶段,使用多个 stage 来提升模型的长上下文能力
- 在 post-training 阶段,进一步提高模型的 reasoning 能力和 alignment 表现
Architecture
Keye-VL 1.5 的架构与 Keye-VL 一致, Keye-VL 1.5 主要做出的改进点为针对视频的 encoding 方式。
之前的工作如 Qwen2.5-VL 使用 3D convolution 来 merge 相邻的两帧,Seed1.5-VL (Guo et al., 2025) 采用了 Dynamic Frame-Resolution Sampling 技巧,来根据 budget 和处理的任务来动态调整采样率 (frame) 和每一帧的图片精度 (resolution).
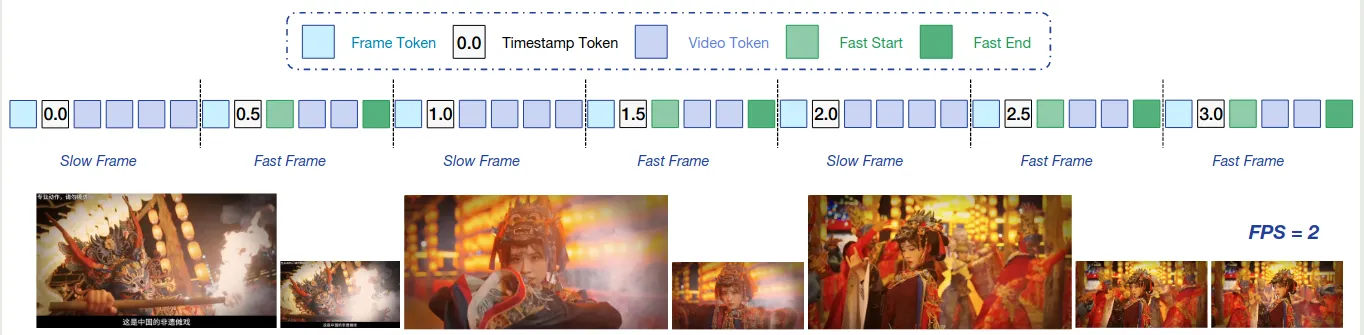
作者认为这些方法比较难进行泛化,因而提出了 SlowFast video encoding strategy:
- Slow Pathway: 空间信息丰富(high resolution),时间信息简略 (low number of frames)
- Fast Pathway: 时间信息丰富(high number of frames),空间信息简略 (low resolution)
为了区分 slow/fast frames, 作者提出了一个基于 patch similarity 的 metric:
- 第一帧始终定义为 slow frame
- 接下来的每一帧,如果其和上一帧的相似度超过 , 则定义为 fast frame; 反之则定义为 slow frame.
得到 slow/fast frames 之后,作者将 fast-frame 的 token budget 限制为 slow frame token budget 的 来平衡时间信息以及空间信息。 接下来,作者使用二分搜索来决定 slow frame 的 token budget. 为了区分 slow frame 和 fast frame 的 token, 作者使用了特殊的 token 来进行分离。
最终的处理结果如下图所示
Data
Pre-training
预训练的数据和 Keye-VL 基本一致,我们主要介绍改进的点
对于 Image caption 数据,作者认为这批数据可能会损害模型的指令跟随和 reasoning 能力,因此作者对数据进行了增广,主要是调整了数据的格式:
- QA, 数据格式为
<image, caption, [eos], question, answer> - reverse QA, 数据格式为
<image, question, answer, [eos], caption> - instruction following: 随机给一批数据作为输入,然后让模型基于特定 image 输出 caption
OCR 数据在 Keye-VL 的基础上加入了两点:
- Structured Document and Code Understanding: 基于 markdown 和 HTML 等数据来获取 code OCR 数据
- Instruction Following OCR: 基于特定指令进行 OCR
对于 grounding 数据,作者进一步加入了 temporal grounding 数据,作者首先使用 TEMPURA 来将短视频分割成若干个 video clips. 然后作者使用 SOTA MLLM 来过滤数据,最后作者基于 Gemini2.5 来生成对应的 QA.
Post-training
SFT 阶段使用了 7.5M 多模态 QA 样本进行训练。
MPO 阶段的数据相比 Keye-VL 有所减少,包含:
- 250K 开源样本
- 150K 纯文本数据
- 26K 人类标注数据
训练时数据分布为 video: images: text = 24:50:26.
作者构建了一个 5 部的自动化数据生成 pipeline, 步骤如下:
- Multi-Source Data Collection and Enhancement:收集数据
- Multi-Path Reasoning Generation with Confidence Quantification: 基于 confidence 来挑选数据
- Comprehensive Two-Level Quality Assessment: 基于答案和过程的正确性来提高数据质量
- Human-in-the-Loop Quality Enhancement: 对于中等质量的数据请人类进一步进行标注
- Dynamic Quality Scoring and Data Utilization Strategy: 对数据进行打分,高质量数据进行上采样
alignment 数据包括:
- instruction following:25 类硬约束,20 类软约束,数据包括 17K 多模态数据和 23K 纯文本数据,奖励包括 rule-based reward 和 generative reward
- reasoning: 12K 数学和逻辑推理数据
- RAG: 提高模型的搜索能力,作者使用 GSPO 算法进行训练
Training
Pre-training
预训练和 Keye-VL 一样,包含 3 个 stage.
- 前两个 stage,作者将模型的上下文限制为 8K, 使用了 Zero-2 (Rajbhandari et al., 2020) 来减少内存开销。
- 在 stage 3, 作者将模型的上下文从 8K 扩展到 128K, 对应的 base frequency 从 1M 提升到 8M. 训练数据包括长视频,长文本和大规模图片。作者将优化策略调整为 Zero-1, 并使用 CP (Liu et al., 2024) 和 PP (Huang et al., 2019) 来支持 long-context 的训练。
Post-training
Post-training 包含以下阶段:
- SFT+MPO: SFT 阶段的数据包括 R1-Reward 和 MMPR, 训练之后作者还是用比较短的 good response 来避免产生较长的回答, 7.5M multimodal QA samples.
- reward model training: 使用 SFT 和 RL 两个阶段进行训练
- LongCoT code-start: 初步激活模型的 reasoning 能力
- General RL:
- RLVR: 使用了 GSPO 算法来进行训练,在训练过程中,作者采取了 progressive hint sampling 方式,也就是提供不同程度的 hint 来提高模型的训练效率。为了进一步提高模型的表现,作者采用了一个和 Seed1.5-VL 一样的迭代式训练策略,即反复进行 SFT 和 RL 来降低训练成本,提高训练效率。
- alignment RL: 提高模型的 instruction following, format adherence, preference alignment 表现
Experiments
消融实验结果如下所示:
- 提高 SFT 训练数据可以有效提高模型在数学推理,逻辑推理和 OCR 任务上的表现
- MPO 可以在 SFT 基础上进一步提高模型的表现
- Long CoT cold start 可以有效提高模型的 reasoning 表现
- alignment RL 可以在保持模型 reasoning 能力的同时提高模型的指令跟随能力
- 通过 rejection sampling,模型的表现有了进一步的提升
model merging 对模型表现的影响:
- model merging 可以有效提高模型在 special domain 上的表现,并且还可以维持模型的通用能力
- expert model 训练时间过长会影响最终 merge model 的表现
- expert mode 训练的学习率应该要设置比较小
- Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., Fan, H., Wang, J., Jiang, J., Wang, J., Chen, J., Huang, J., Lei, K., Yuan, L., Luo, L., Liu, P., Ye, Q., Qian, R., Yan, S., … Song, Z. (2025). Seed1.5-VL Technical Report. https://arxiv.org/abs/2505.07062
- Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, M. X., Chen, D., Lee, H., Ngiam, J., Le, Q. V., Wu, Y., & Chen, Z. (2019). GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism. https://arxiv.org/abs/1811.06965
- Liu, H., Zaharia, M., & Abbeel, P. (2024). RingAttention with Blockwise Transformers for Near-Infinite Context. The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=WsRHpHH4s0
- Rajbhandari, S., Rasley, J., Ruwase, O., & He, Y. (2020). ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. https://arxiv.org/abs/1910.02054
- Yang, B., Wen, B., Ding, B., Liu, C., Chu, C., Song, C., Rao, C., Yi, C., Li, D., Zang, D., Yang, F., Zhou, G., Zhang, G., Shen, H., Peng, H., Ding, H., Wang, H., Fan, H., Ju, H., … Zhang, Z. (2025). Kwai Keye-VL 1.5 Technical Report. https://arxiv.org/abs/2509.01563
Keye-VL 2.0
快手在 26 年 6月提出了 Keye-VL 2.0 (Team et al., 2026), 一个 30B-A3B 的 开源 MoE 多模态大模型,模型亮点为 long-video understanding 以及 agentic intelligence.
Keye-VL 2.0 进行了如下改进:
- 架构上,使用了 DSA [@DSA] 来降低 KV cache 占用和支持 256K 的上下文
- 训练上,作者提出了 Cross-Modal Multi-teacher On policy distillation (MOPD) 和 Context-RL, Video RL 避免灾难性遗忘。
Architecture
架构如下:
- vision encoder: 和 KeyeVL1.5 一样,使用了插值来处理绝对位置编码,使用 2D RoPE 和 sequence packing
- LLM: Qwen3-A30B-A3B-Thinking-2507
- MLP: patch merger
- attention: DSA [@DSA] + GQA [@GQA], topK=2048.
Data
- Stage 0: ViT continual pre-training, 500B tokens, 包括 DataComp, LAION, CC12M, PD12M, COCO
- Stage 1: image caption data, image-text interleaved data
- Stage 2: 通过 recaption 和 remake 来提高数据集质量
- Stage 3: Image-text data, pure-text data
post-training: 500B tokens, 40% pure text data, 包括 Text NLP, Video, Perception, Reasoning, Agent 和 Long context data
Visual encoding
对不同的数据使用了相同的处理方式:
- image: 按照动态分辨率图片进行处理
- video: 加入 explicit timestamp, 作者认为这种 frame-as-image 的方式可以简化视觉信息处理方式,作者根据不同的视频来动态分配最大 token 数量
Training
Pre-training
Pre-training 包含 4 个 stage:
- 仅训练 projector
- 全量微调,32K 上下文,1T tokens
- 全量微调,64K 上下文,加入 OCR, VQA 等下游任务数据,2T tokens
- 全量微调,256K 上下文, long video, multi-page
Post-training
包括以下几个阶段:
- SFT: 使用了通用的指令跟随数据和 reasoning CoT 数据
- RL: 训练不同的专家模型,算法为 GSPO (Zheng et al., 2025)
- Synthetic-Data RL: 基于图片编辑数据完成找不同
- General RL: reward 包括 format reward, outcome reward, process reward 和 ContextRL reward
- Specialized RL: 训练 Grounding, spatial understanding, math reasoning, counting 和 OCR expert
- Video RL: 31K video samples
- Agentic RL: Coding RL, Tool use RL, Search RL
- MOPD: 使用 13 个 teacher 来进行 MOPD.
MOPD
给定 prompt , 学生模型 on policy 输出
对于状态 , 选择的 teacher 提供 token-level feedback, 作者使用了 segmented prompt-response re-tokenization (SPRR) 来对齐选择的教师模型 和学生模型的概率。 作者使用了 overlap set 来提供更稳健的 feedback (Li et al., 2026), 首先,作者定义 topK overlap set 为
当 不为空时, raw advantage 定义为
其中
通过在 overlap 上进行蒸馏,我们可以避免计算非常低概率 token 的概率值。 最后,学生模型的训练目标为
其中 是 valid response-token mask.
Infra
在预训练阶段,作者提出了 ExtraIO, 将数据处理作为一个独立的服务,避免数据处理称为训练的瓶颈。
并且,作者对 ViT 和 LLM 使用了不同的 sharding 策略,吧 ViT 模型的计算和显存开销摊分到不同的 GPU 上
针对动态分辨率图片/不同长度视频输入,作者设计了两级动态均衡:
- 多模态 token 级: 每个 ViT 处理的数据不按照样本数量分,而是按照视觉 token 的实际总量分,确保 ViT 各个 GPU 工作量一致
- LLM 样本级:根据序列的实际长度进行重排和对齐,确保 LLM 各个阶段的 token 总数尽可能一致
对于 DSA, 作者使用了 FlashInfer 和 TileLang 来实现加速。
- Li, Y., Zuo, Y., He, B., Zhang, J., Xiao, C., Qian, C., Yu, T., ang Huan-Gao, Yang, W., Liu, Z., & Ding, N. (2026). Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe. https://arxiv.org/abs/2604.13016
- Team, K. K., Wen, B., Liu, C., Song, C., Rao, C., Zhang, G., Li, H., Fan, H., Ju, H., Chen, J., Chen, J., Yuan, J., Yang, K., Jiang, K., Gai, K., Zhou, L., Nie, N., Na, S., Zhang, T., … Zhang, R. (2026). Kwai Keye-VL-2.0 Technical Report. https://arxiv.org/abs/2606.10651
- Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y., Men, R., Yang, A., Zhou, J., & Lin, J. (2025). Group Sequence Policy Optimization. https://arxiv.org/abs/2507.18071