Kimi k1.5
论文提出了Kimi k1.5, 一个基于强化学习训练的多模态推理模型。作者介绍了Kimi k1.5的训练方法,以及infra上的优化。作者的主要贡献如下:
- 作者发现,模型的上下文长度可以有效提升LLM的推理能力。
- 作者提出了基于online mirror descent的强化学习训练方法。
- 作者发现可以通过long context scaling和policy optimization来提升模型的推理能力。
- 作者提出了long2short的推理方法,可以有效提升short CoT模型的推理能力。
论文中包括两个模型,一个是k1.5 base model, 其是一个多模态大模型。另一个是Kimi-1.5 reasoning model(简称为k1.5),k1.5是基于kimi-1.5 base model, 通过强化学习训练得到的推理模型。
Model
base model
k1.5 base model是一个基于transformer的多模态大模型,论文没有给出详细的模型结构,只有如下的示意图

k1.5 base model的训练包括三个阶段:
- Vision-language pretraining stage: 这一阶段的目的是让模型拥有语言和视觉的表征能力。训练时,模型先在纯文本的数据上进行训练,然后提高加入图文交错的数据进行训练,直到训练数据中图文交错的数据占比达到30%。模型的更新方式为先冻结LLM更新visual tower, 然后解冻LLM更新所有参数。
- Vision-language cooldown stage: 这一阶段的目的是让模型保持多模态理解能力。作者发现,使用合成数据可以提高模型在这一阶段的表现。因此,作者使用闭源大语言模型,基于math, knowledge和code domain的pretraining data来合成了一些QA pair数据对,然后讲这些QA pair数据对加入到训练数据中。
- Long-context activation stage: 这一阶段的目的是让模型在长上下文的数据上进行训练,以提升模型在长上下文上的理解能力。这一阶段包含了40%的full attention data以及60%的partial attention data。其中,full attention data是基于真实数据和合成的QA以及summary数据得到的,partial attention data是在cooldown data找那个通过均匀采样得到的。这一阶段,模型的上下文长度从4096逐步增加到131072。
final Model
Kimi k1.5是基于k1.5 base model, 通过进一步训练得到的推理模型。k1.5的训练包括四个阶段:
- pretraining:这一步就是k1.5 base model的训练, 包括三个小阶段。前面已经介绍过了。
- vanilla SFT:这一步的目的是使得k1.5 base model具有指令跟随能力。对于non-reasoning任务,作者先使用人类标注产生一个seed dataset,然后基于seed dataset训练一个seed model,最后根据收集的prompt来使用seed model来生成回答。对于reasoning任务,作者使用了rejection sampling来扩展SFT数据集
- long-CoT SFT: 这一步的目的是让模型能够像人类一样进行推理,能够掌握最基本的推理策略,即:planning,evaluation,reflection和exploration。从而为RL训练提供一个良好的初始化。
- RL:这一步就是通过RL来提高模型的推理能力。我们在下一节中进行详细的介绍。
Training
RL
Problem Definition
给定一个训练数据集 , 其中 是问题, 是ground truth。我们希望找到一个模型 ,来解决这个问题。通常问题比较难,因此我们使用chain of thought(CoT)的方法来解决这个问题。具体做法就是让模型输出中间步骤 , 来连接问题 和答案 。其中, 是模型在第 步的推理结果,即 , 。
通常,我们还会使用一个reward model ,来评估模型输出的答案的质量。一个常用的reward model是基于答案的正确性来评估的,即 。这样,我们要求解的问题就变成了最大化中间步骤和最终答案的reward,即
Policy Optimization
作者使用了online policy mirror descent来解决上面提到的优化问题。在每个iteration中,存在一个reference model , 以及一个当前要更新的模型 。online policy mirror descent要解决的优化问题为:
其中, 是超参数,用于平衡reward和KL散度 .
上述问题有一个闭式解,即:
其中,
是归一化因子。在闭式解的表达式中,我们对两边取对数,得到:
这是最优策略满足的等式。作者这里使用了L2 loss来优化当前策略 ,即:
这里需要注意的一点是response 是基于reference model 生成的,而不再是基于当前策略 生成的。这是Kimi-1.5的RL训练和传统RL训练的一个不同点。这也是为什么k1.5说他是off-policy的原因。
接下来,我们就可以对上面的目标函数求梯度,我们将里层的函数展开为 的形式,然后对 求梯度,得到:
如果我们对每个问题,采样 个response ,那么我们可以近似上式中内部的期望,得到:
这里, 是 的估计值。作者提供了两种估计方法:
- 基于采样的 对 进行估计:
- 直接使用samples rewards的平均值来近似:
作者提到,第二种方法效果很好并且计算效率更高,因此作者在实验中使用了第二种方法。
训练时,作者每次从数据集中采样一个batch的样本,然后使用上述的梯度更新模型。模型参数更新完之后,作者将新的模型作为reference model,然后重复上述过程。
Remark 作者还探究了为什么不使用value network。作者认为,在强化学习中,value network通常用于评估当前状态的价值,但是在reasoning model中,训练的目的是让模型能够充分探索,以提高模型在不同任务中的泛化性。因此,作者认为使用value network可能会限制模型的探索能力。
Training Strategy
作者提出了两个提高采样效率的方法:
- Curriculum Sampling. 这种采样方式会将问题按照难度进行排序,然后按照难度从易到难进行采样。以逐步提高模型的推理能力。
- Prioritized Sampling.作者还采用了prioritized sampling来提高采样效率。也就是说,对于回答错误的问题,模型会进行更多的采样。
Infra
Training System

为了高效地进行RL训练,作者构建了一个iterative synchronous RL训练框架。框架如上图所示。框架的创新之处在于Partial Rollout,该方法可以更高效的处理复杂的推理轨迹。框架包含了以下几部分:
- rollout worker: 该部分负责生成推理轨迹。然后将生成的推理轨迹加入到replay buffer中。
- master: 管理data flow和replay buffer和train worker之间的通信。
- train worker: 根据获取的rollout轨迹更新模型。
- code execution service: 在代码相关任务中,该部分负责执行代码,并返回执行结果。
Partial Rollout:Partial Rollout的目的是为了整体的训练效率。其做法就是给定一个固定的outpu token budget,然后限制推理轨迹的长度。当长度超过token限制时,没有完成的部分就会被存入到replay buffer中,以供后续的训练使用。
Deployment Framework
根据前面的介绍,我们知道k1.5每个iteration的训练包括两步:
- inference phase: 基于Reference model进行采样,生成推理轨迹。
- training phase: 基于采样得到的推理轨迹,更新模型。
如果我们直接使用Megatron和vLLM来实现上述的训练和推理,那么会存在以下问题:
- Megatron和vLLM的并行策略可能并不一致,因此很难进行参数共享
- 在训练过程中,vLLM可能会保留一些GPU,这就导致了训练和推理的资源分配不均。
- 推理和训练的资源需求可能并不一致,无法动态调控显卡资源
因此,作者构建了一个hybrid deployment framework来解决上述问题,其框架如下图所示。

该框架的主要优势在于使用Kubernetes Sidecar containers来在一个pod中共享所有的GPU资源。这样就避免了资源分配不均的问题。
Data
Data Processing
- RL prompt set. 作者认为prompt的quality和diversity对RL训练至关重要。因此作者基于diverse coverage, balanced difficuty以及accurate evaluation来构建了一个RL prompt set。对于多样性,作者确保数据集覆盖多个domain。对于平衡难度,作者通过多次采样,根据通过率来给每个样本的难易程度打分。对于准确性,作者筛掉了多选题,正确题和证明题,确保模型能够生成正确的推理步骤。最后,作者还让模型进行猜测,如果模型猜测的正确率比较高,那么就认为该样本是easy-to-hack的,就会筛掉。
- Test Case Generation for Coding. 作者使用CYaRon来生成coding任务的测试用例。通过与Kimi k1.5结合,作者构建了一个包含323个测试用例的训练集。
- Reward modeling for Math. 作者使用了两种方法来提高reward model的准确性。第一个是classic RM,作者基于InstructGPT,构造了大约800K的数据训练了一个value-head based RM。模型会基于问题,参考答案和模型生成的答案来判断模型生成的答案是否正确。第二个是Chain of Thought RM,作者基于收集的800k CoT数据对kimi进行了finetune,然后对模型生成的推理步骤进行打分。最终发现,Chain of Thought RM的效果更好。因此,作者在RL训练中使用了Chain of Thought RM。
- Vision RL Data。 作者从三个方面构建了vision RL数据集:real-world data, synthetic visual reasoning data以及text-rendered data.
Dataset
- pretraining:其中,纯文本数据包括Engligh, Chinese, Code, math reasoning以及Knowledge这5个领域。多模态数据包括captioning, image-text interleaving, OCR, Knowledge以及QA数据集等。附录B介绍了数据集的来源和处理过程。
- SFT: vanilla SFT数据集包含1M的纯文本数据,其中包含500K的general QA数据,200K的coding数据,200K的数学和科学数据,5K的创作写作数据以及20K的长上下文任务(总结,QA,翻译和写作等)。作者还构建了1M的图文数据,包括chart理解,OCR,grounding,visual coding, visual reasoning以及visual aided math/science problems等
- long-CoT SFT:该阶段的数据基于refined RL prompt set,使用了prompt engineering来构建了一个少量但高质量的long-CoT数据集。用于将reasoning能力内化到模型中。
Long2short
为了降低推理成本,作者提出了long2short的推理方法。该方法通过将长上下文推理转化为短上下文推理,让模型能够更加高效的完成推理。作者尝试了几种方法来实现long2short:
- Model merging:将long-CoT模型和short-CoT模型进行合并,然后进行推理。这里采用的办法是对两个模型的权重取平均。
- shortest rejection sampling:通过对同一个问题进行多次采样(论文中每个问题采样8次),然后选择最短的,正确的推理步骤作为最终答案。
- DPO:通过对同一个问题进行多次采样,选择最短的正确的回答作为正样本,最长的回答作为负样本,然后使用DPO进行训练。
- Long2short RL:作者在RL阶段,选择一个在performance和token efficiency之间达到平衡的模型作为 base model,然后加入了一个long2short RL训练阶段。该阶段,作者加入了length penalty以及降低了maximum rollout length来鼓励模型生成更短的推理步骤。
Length penalty
Length penalty的目的是降低模型的overthinking和训练成本。作者加入了一个length reward,对于问题 和采样的回答 ,回答 的length定义为 length reward定义为:
其中
也就是说,当回答正确时,我们鼓励模型生成更长的推理步骤。反之,我们鼓励模型生成更短的推理步骤。
Experiments
- K1.5在long-CoT任务上的表现

- K1.5在Short-CoT任务上的表现

-
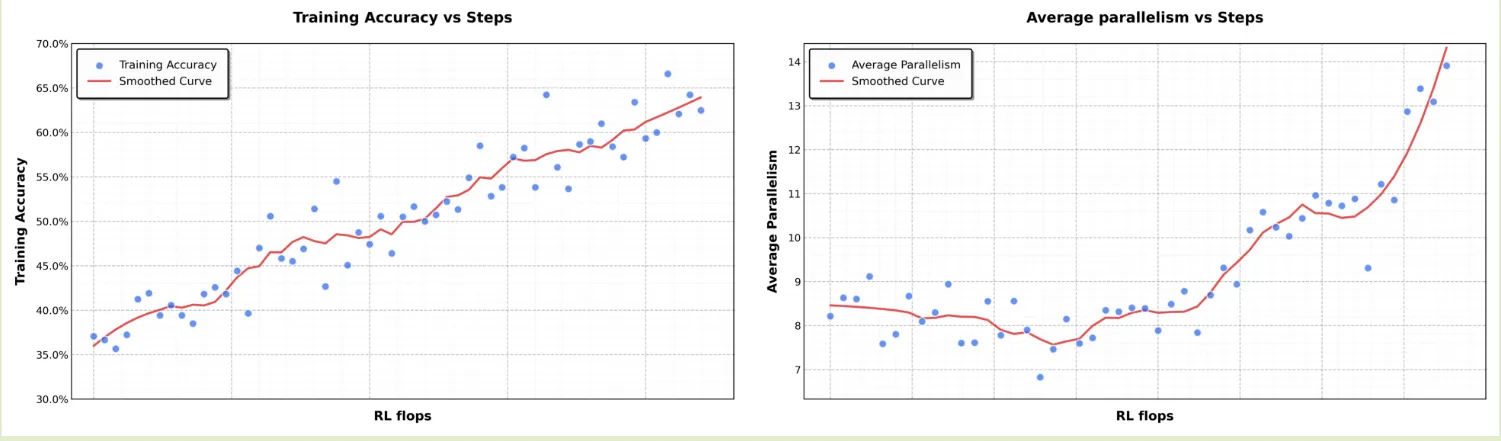
Long Context Scaling 作者在实验中还探究了上下文长度对模型推理能力的影响。作者针对几个模型进行了实验,结果在图5和图6里面。结果发现,随着上下文长度的增加,模型的推理能力会逐渐提升。
-
Long2short

Ablation study
- Scaling of model size and context length. 作者探究了模型大小和上下文长度对模型推理能力的影响,结果在图8里面。结果发现
- 小模型可以通过Long CoT来达到大模型的效果
- 大模型具有更高的token效率
- 理想情况下,使用具有更长上下文的大模型,可以同时达到更高的推理能力和更高的token效率,否则,使用上下文长度更长的小模型
- Effects of using negative gradients. 作者探究了使用负梯度对模型推理能力的影响。作者与ReST方法进行了对比,结果在图10里面。结果发现,ReST回到只模型产生更长的推理步骤。作者认为,选取合适的优化方法,可以有效提升模型的推理能力。
- Sampling strategies. 作者还探究了采样策略对模型推理能力的影响。作者与均匀采样进行了对比,结果在图9里面。结果发现,论文提出的采样策略可以有效提升模型的推理能力。
Kimi-K2.5
Kimi-K2.5 的核心有亮点:
- native multi-modal: 通过在预训练,SFT, RL 阶段使用多模态数据来提高模型的多模态能力
- agent: 通过并行 multi-agent 的方式来提高模型解决复杂问题的效率和能力
Architecture
Kimi K2.5 是一个标准的 ViT-MLP-LLM 架构,其中
- ViT, 基于 Kimi-VL 提出的 MoonViT, 并进行了改进, 参数量为 400M
- MLP, 基于 patch merger,
- LLM, 基于 Kimi-k2, 参数量为 1.02T-A32B
ViT 作者使用了 Kimi-VL 提出的 MoonViT, MoonViT 基于 SigLIP 提出的 SigLIP-SO-400M 开发得到,MoonViT 使用了 NaViT 来避免切分图片和使用不同精度图片进行训练。
在 MoonViT 的基础上,Kimi-K2.5 还进一步提出了 MoonViT-3D, 将 NaViT 的思想扩展到了 3D 用于提高模型的视频理解能力,具体做法为将连续 4 帧的视频展开为 1D sequence, 这样在图像上的注意力机制就可以无缝衔接到视频上了。并且,通过这种方式,我们可以让模型关注跨帧的信息(注意力在 4 帧的 token 之间进行),简化代码如下所示
# config.json temporal_merge_kernel_size
# kimi_k25_vision_processing.py split_video_chunks
video_chunk = frames[0:4]
patches = []
for frame in video_chunk:
patches.extend(split_into_patches(frame))
tokens = patches
# modeling_kimi_k25.py Learnable2DInterpPosEmbDivided_fixed
positions = spatial_embedding + temporal_embedding
# modeling_kimi_k25.py MoonViT3dEncoder
output = transformer(tokens + positions)
最后,在进入 MLP 之前,作者还对每个 temporal chunk 内的特征进行 pooling 操作,将时序长度压缩到了原来的 1/4, 进而提高模型可处理的视频长度。
# modeling_kimi_k25.py tpool_patch_merger
def tpool_patch_merger(
x: torch.Tensor,
grid_thws: torch.Tensor,
merge_kernel_size: tuple[int, int] = (2, 2),
) -> list[torch.Tensor]:
d_model = x.size(-1)
outputs = []
pre_sum = 0
for t, h, w in grid_thws.tolist():
# Get the current sequence
seq = x[pre_sum:pre_sum + t * h * w]
# Reshape along self.merge_kernel_size and concat to the last dimension
kernel_height, kernel_width = merge_kernel_size
new_height, new_width = h // kernel_height, w // kernel_width
reshaped_seq = seq.view(t, new_height, kernel_height, new_width,
kernel_width, d_model)
reshaped_seq = reshaped_seq.permute(0, 1,
3, 2, 4, 5).contiguous().mean(
dim=0) # temporal pooling
padded_seq = reshaped_seq.view(new_height * new_width,
kernel_height * kernel_width, -1)
outputs.append(padded_seq)
pre_sum += t * h * w
return outputs
MLP MLP 使用了 PatchMerger, 用于减少视觉 token 个数,这个方案在之前的 Qwen-VL 系列里已经得到了应用。
LLM LLM 基于 Kimi-k2 的 MoE 模型,总参数为 1T, 激活参数为 32B
Data
Pre-training
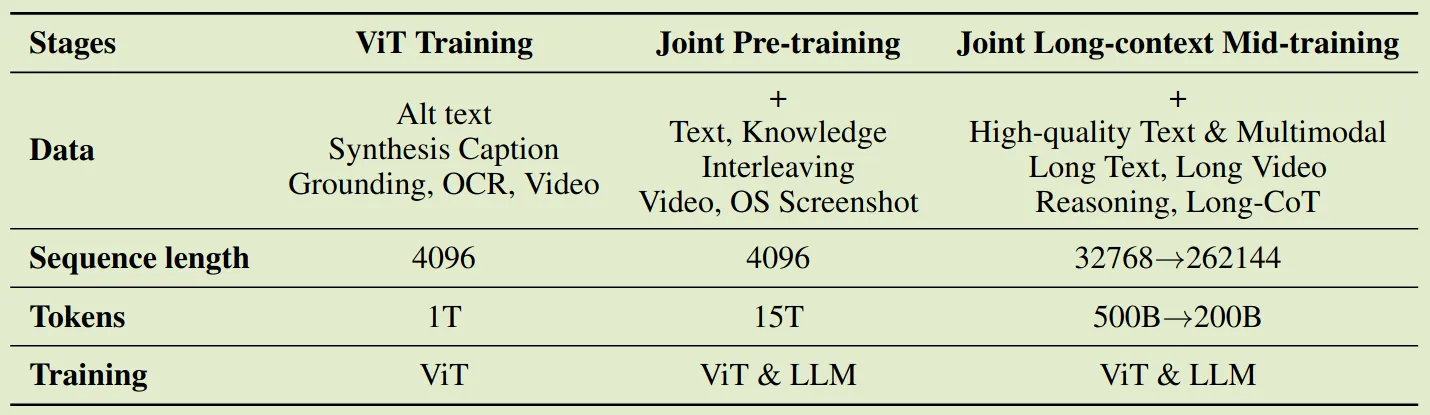
预训练阶段一共使用了 15T token, 分为了三个阶段:
- ViT-training: 单独训练 ViT, 实际用了 image caption, grounding, ocr, video 等数据进行训练,训练方式采用了类似 InternVL 的方式,即通过 cross entropy loss 来与一个清凉话的 LLM 进行对齐,这个阶段训练使用了 1T token, 然后作者使用了一个非常短的 stage 来更新 MLP 用于对齐 ViT 和 Kimi-K2
- Joint pre-training: 训练所有参数,长下文长度为 4K, 使用了 15T token. 这里主要强调了提升代码数据的比例
- Long context mid-training: 使用 YARN 来提高模型的上下文长度
最终预训练阶段 recipe 如下所示
Native Multimodal pre-training 在 Joint pre-training stage, Kimi-K2.5 还采用了一个与 InternVL3 类似的策略,即在预训练一开始直接使用多模态数据进行预训练。
传统的多模态大模型往往基于一个比较成熟的 LLM backbone 来完成多模态大模型的训练,但是其问题在于成熟的 LLM 其表示空间会收敛到语言模态上,多模态信息的迁移能力比较差。InternVL3 虽然也是 native multimodal pre-training, 但是其仍然依赖于成熟的 LLM. Kimi K2.5 则是使用预训练阶段的 Kimi K2 作为 backbone 来避免表示空间的塌缩,在训练一开始即直接加入少量多模态数据来保持模型的多模态能力。
作者探究了预训练阶段不同的数据对比,试验结果如下图所示
| Vision Injection Timing | Vision-Text Ratio | Vision Knowledge | Vision Reasoning | OCR | Text Knowledge | Text Reasoning | Code | |
|---|---|---|---|---|---|---|---|---|
| Early | 0% | 10%:90% | 25.8 | 43.8 | 65.7 | 45.5 | 58.5 | 24.8 |
| Mid | 50% | 20%:80% | 25.0 | 40.7 | 64.1 | 43.9 | 58.6 | 24.0 |
| Late | 80% | 50%:50% | 24.2 | 39.0 | 61.5 | 43.1 | 57.8 | 24.0 |
结果显示,在训练早期加入少部分的多模态数据可以有效提高模型的表现。
Post-training
Post-training 分为了 SFT 和 RL, SFT 阶段作者使用了合成的高质量数据,主要提升模型的交互式推理能力以及工具调用能力。为了解决传统 VLM 工具调用能力比较差且扩展性差的问题,Kimi-k2.5 提出了 Zero-Vision SFT, 其核心思想模型在预训练阶段已经完成了多模态对齐,因此我们可以仅使用纯文本 SFT 数据来激活 VLM 的视觉 agent 能力,具体做法就是将所有图像操作通过 IPython 的代码进行代理操作,这样视觉工具的调用就编程了程序化的图像处理指令。
在 RL 阶段,作者基于 Kimi-k1.5 提出的策略优化算法加入了一个 token-level clipping 机制来减少 off-policy divergence, 目标函数如下所示
其中 是针对每个回答 的采样次数, 是一个 batch 里总的 token 个数, 为超参数, 是对 normalization 的估计,这里采用了 Kimi-K1.5 的 mean reward, 即 . 这里的 clipping 机制与 PPO 不同的地方在于针对 log-ratio 进行 clipping, 而不依赖于 advantage 的计算。最终训练时使用了 Moonlight 的 MuonClip 算法
对于 reward 的设计,Kimi-k2.5 也使用了基于规则和基于 reward model 的方式,前者针对答案可验证的任务,后者针对开放式的任务。
作者还构建了 length penalty 来提高模型的推理效率,作者发现 Kimi-k1.5 和 Kimi-k2 中的 length penalty 虽然可以生成更准确的 reasoning chain, 但是其很难泛化到更高的算力. 为了解决这个问题,作者提出了 Toggle 策略,即在 inference-time scaling 和 budget-constrained optimization 两种模式之间进行切换优化,对应的 reward 定义为
其中 都是超参数。budget 基于正确回答的长度的 p 分位得到:
两种模式每隔 个 iteration 切换一次:
- phase 0: budget limited phase, 训练模型在给定 token budget 下解决问题,减少 reasoning chain 长度
- phase 1: scaling phase, 训练模型使用更多的算力来解决更复杂的问题,提高模型的智能程度
作者评估 Toogle 策略得到的结果如下所示
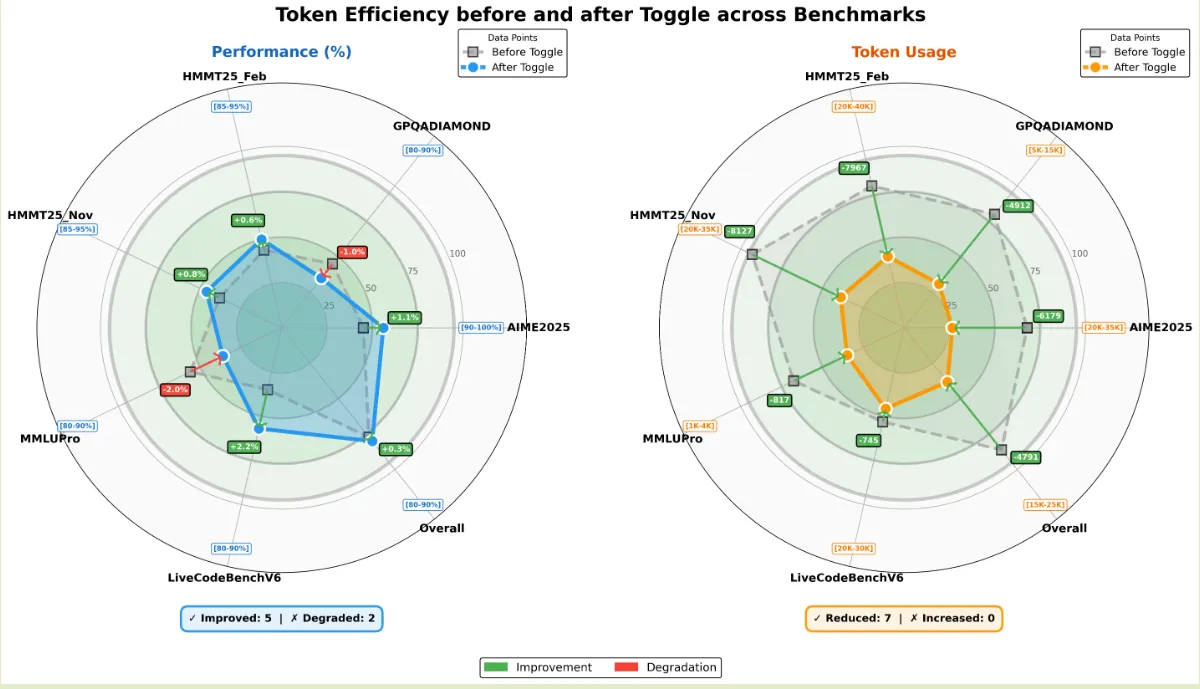
结果现实,使用 toggle 策略之后,模型的输出长度减少了 30% 左右,且模型的表现并没有明显下降。作者还发现,一些重复的 pattern 也随之降低,且 toggle 策略的泛化程度更高。
在 Zero-Vision SFT 的基础上,Kimi-k2.5 使用了 Joint multimodal RL 训练策略。现有的多模态 RL 存在的问题为:模型很容易忽略视觉输入而过度依赖于纯文本进行推理。为了解决这个问题,作者构建了需要视觉理解才能得到答案的任务来提高模型对于视觉信息的利用程度,这些任务覆盖三个 domain:
- visual grounding and counting: 定位和计数
- chart and document understanding: 图表文档理解
- vision-critical STEM problems: 需要图片来完成求解的数学物理问题
作者在 visual RL 之后评估了模型的表现,发现模型在 MMLU-Pro, GPQA-Diamond 等任务上的表现都有了提升,作者认为 visual RL 可以在不损害模型纯文本能力的情况下提高模型跨模态的泛化性
Agent Swarm
Kimi-k2.5 的另一个重大改进为使用并行机制来提高模型的 agent 能力。传统的 agent 往往序列执行 reasoning, tool-use, 这限制了模型处理复杂任务的能力,Kimi-k2.5 通过 Agent Swarm 和 Parallel Agent Reinforcement Learning (PARL) 来解决这个问题,其核心思想就是并行,框架图如下所示
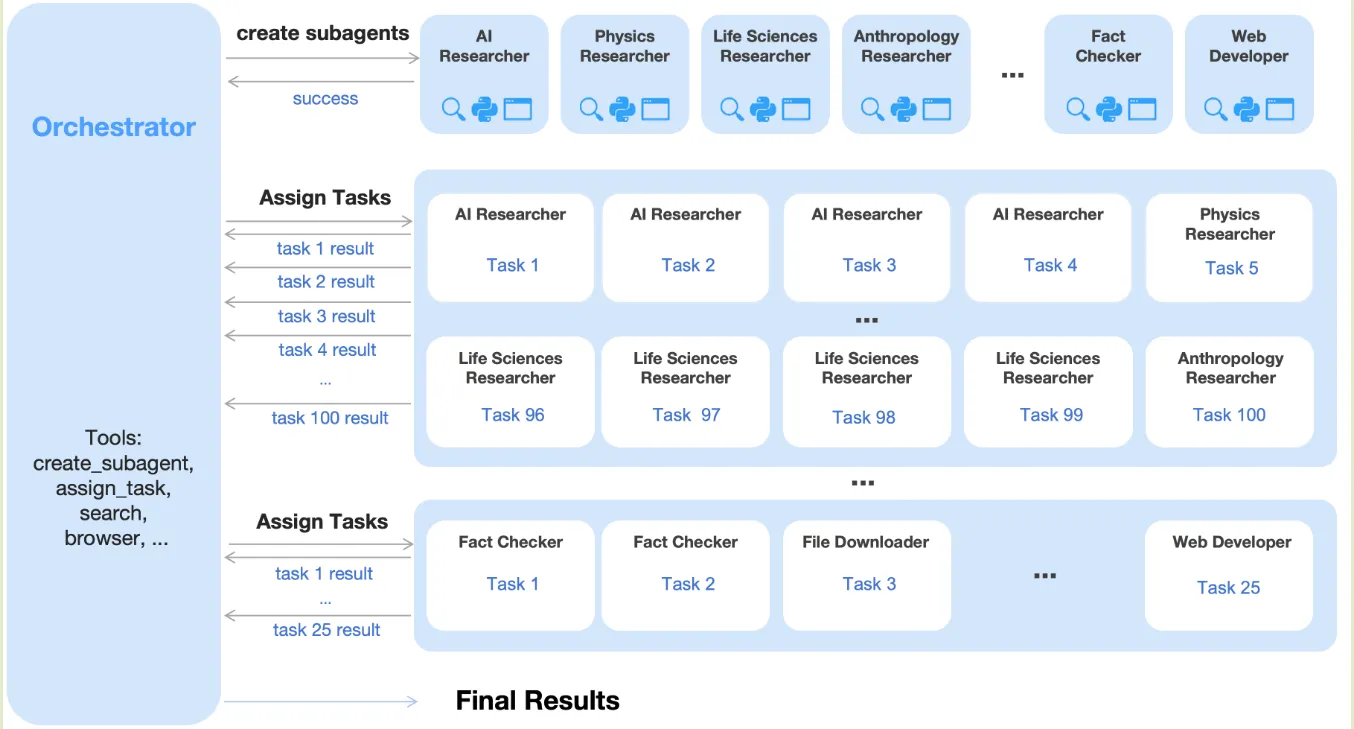
agent swarm 架构包含了一个 orchestrator 和若干个 subagent, 为了解决 agent swarm 的 reward 比较难以设置的问题,PARL 构建了三个不同 level 的 reward
其中 评估了 solution 的质量, 则是避免并行模式崩塌,从 multi-agent 崩塌为 single agent, 则是评估模型的完成性。超参数 随训练逐渐降为 0 来提高模型整体的表现。
作者还提出了使用 critical steps 来评估 parallel agent 的计算时间消耗,其计算公式如下
其中 为一个 episode 的时间, 为 orchestrator 在第 步的运行时间, 为第 i 个 subagent 的运行时间。
为了提高模型的并行能力,作者构建了一批广度优先搜索和深度优先搜索的数据,通过这些数据的构建,我们可以提高 orchestrator 的并行调用能力。
最终,PARL 的表现如下所示
Infra
Kimi-k2.5 的 infra 基于 Kimi-k2, 作者主要强调了 decouple encoder process (DEP) 这一改进。之前的工作将 vision encoder 和 text embedding 都做为 PP 的第一个 stage, 但是由于 vision encoder 对不同输入的处理时间不同,这个 stage 的算历和内存分配随输入变化比较大。为了解决这个问题,作者提出了 DEP, 包含三个 stage 来提高训练效率:
- balanced vision forward: 由于 vision encoder 比较小 (400M), 因此作者将 vision encoder 复制到所有 GPU 上,然后根据负载来将 visual data 分配到不同的 GPU 上进行处理,这个阶段不保存中间激活值,处理完毕之后所有的结果作为 PP Stage0 的输入
- backbone training: 正常进行训练,与 LLM 的训练优化一致
- vision recomputation & backward: 这个阶段,我们重新计算 vision encoder 的 forward pass, 然后再对 vision encoder 进行反向传播
通过 DEP, Kimi-k2.5 的训练效率达到了 Kimi-k2 的 90%.
Experiments
首先是 Kimi-k2.5 在 general & reasoning 类任务上的表现,可以看到,Kimi-k2.5 超过了 DeeoSeek-V3.2 的表现,
| Benchmark | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 (xhigh) | Gemini 3 Pro | DeepSeek-V3.2 |
|---|---|---|---|---|---|
| HLE-Full | 30.1 | 30.8 | 34.5 | 37.5 | 25.1† |
| HLE-Full w/ tools | 50.2 | 43.2 | 45.5 | 45.8 | 40.8† |
| AIME 2025 | 96.1 | 92.8 | 100 | 95.0 | 93.1 |
| HMMT 2025 (Feb) | 95.4 | 92.9* | 99.4 | 97.3* | 92.5 |
| IMO-AnswerBench | 81.8 | 78.5* | 86.3 | 83.1* | 78.3 |
| GPQA-Diamond | 87.6 | 87.0 | 92.4 | 91.9 | 82.4 |
| MMLU-Pro | 87.1 | 89.3* | 86.7* | 90.1 | 85.0 |
| SimpleQA Verified | 36.9 | 44.1 | 38.9 | 72.1 | 27.5 |
| AdvancedIF | 75.6 | 63.1 | 81.1 | 74.7 | 58.8 |
| LongBench v2 | 61.0 | 64.4* | 54.5* | 68.2* | 59.8* |
接下来是模型在 coding 任务上的表现
| Benchmark | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 (xhigh) | Gemini 3 Pro | DeepSeek-V3.2 |
|---|---|---|---|---|---|
| SWE-Bench Verified | 76.8 | 80.9 | 80.0 | 76.2 | 73.1 |
| SWE-Bench Pro (public) | 50.7 | 55.4* | 55.6 | - | - |
| SWE-Bench Multilingual | 73.0 | 77.5 | 72.0 | 65.0 | 70.2 |
| Terminal Bench 2.0 | 50.8 | 59.3 | 54.0 | 54.2 | 46.4 |
| PaperBench (CodeDev) | 63.5 | 72.9* | 63.7* | - | 47.1 |
| CyberGym | 41.3 | 50.6 | - | 39.9* | 17.3* |
| SciCode | 48.7 | 49.5 | 52.1 | 56.1 | 38.9 |
| OIBench (cpp) | 57.4 | 54.6* | - | 68.5* | 54.7* |
| LiveCodeBench (v6) | 85.0 | 82.2* | - | 87.4* | 83.3 |
在 agent 任务上的表现
| Benchmark | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 (xhigh) | Gemini 3 Pro | DeepSeek-V3.2 |
|---|---|---|---|---|---|
| BrowseComp | 60.6 | 37.0 | 65.8 | 37.8 | 51.4 |
| BrowseComp (w/ ctx manage) | 74.9 | 57.8 | - | 59.2 | 67.6 |
| BrowseComp (Agent Swarm) | 78.4 | - | - | - | - |
| WideSearch | 72.7 | 76.2* | - | 57.0 | 32.5* |
| WideSearch (Agent Swarm) | 79.0 | - | - | - | - |
| DeepSearchQA | 77.1 | 76.1* | 71.3* | 63.2* | 60.9* |
| FinSearchCompT2&T3 | 67.8 | 66.2* | - | 49.9 | 59.1* |
| Seal-0 | 57.4 | 47.7* | 45.0 | 45.5* | 49.5* |
| GDPVal-AA | 41.0 | 45.0 | 48.0 | 35.0 | 34.0 |
| OSWorld-Verified | 63.3 | 66.3 | 8.6 | 20.7 | - |
| WebArena | 58.9 | 63.4 | - | - | - |
多模态表现
| Benchmark | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 (xhigh) | Gemini 3 Pro | Qwen3-VL-235B-A22B |
|---|---|---|---|---|---|
| Image | |||||
| MMMU-Pro | 78.5 | 74.0 | 79.5* | 81.0 | 69.3 |
| MMMU (val) | 84.3 | 80.7 | 86.7* | 87.5* | 80.6 |
| CharXiv (RQ) | 77.5 | 67.2* | 82.1 | 81.4 | 66.1 |
| MathVision | 84.2 | 77.1* | 83.0 | 86.1* | 74.6 |
| MathVista (mini) | 90.1 | 80.2* | 82.8* | 89.8* | 85.8 |
| SimpleVQA | 71.2 | 69.7* | 55.8* | 69.7* | 56.8* |
| WorldVQA | 46.3 | 36.8 | 28.0 | 47.4 | 23.5 |
| ZeroBench | 9 | 3* | 9* | 8* | 4* |
| ZeroBench w/ tools | 11 | 9* | 7* | 12* | 3* |
| BabyVision | 36.5 | 14.2 | 34.4 | 49.7 | 22.2 |
| BLINK | 78.9 | 68.8* | - | 78.7* | 68.9 |
| MMVP | 87.0 | 80.0* | 83.0* | 90.0* | 84.3 |
| OmniDocBench 1.5 | 88.8 | 87.7* | 85.7 | 88.5 | 82.0* |
| OCRBench | 92.3 | 86.5* | 80.7* | 90.3* | 87.5 |
| InfoVQA (test) | 92.6 | 76.9* | 84* | 57.2* | 89.5 |
| Video | |||||
| VideoMMMU | 86.6 | 84.4* | 85.9 | 87.6 | 80.0 |
| MMVU | 80.4 | 77.3* | 80.8* | 77.5* | 71.1 |
| MotionBench | 70.4 | 60.3 | 64.8 | 70.3 | - |
| Video-MME | 87.4 | 66.0* | 86.0* | 88.4* | 79.0 |
| LongVideoBench | 79.8 | 67.2* | 76.5* | 77.7* | 65.6* |
| LVBench | 75.9 | 57.3 | - | 73.5* | 63.6 |
我们这里基于模型在不同类别任务上的排名来进行可视化,结果如下
从结果可以看出,Kimi-K2.5 的 agent 能力达到了 SOTA 级别,其多模态能力也比较强。
与 DeepSeek-V3.2 一样,作者也对比了不同模型的推理效率,结果如下图所示
可以看到,相比与 Kimi-K2, Kimi-K2.5 通过在 RL 层面进行优化,降低了输出长度,但是相比与 DeepSeel-V3.2 和 Gemini3.0 Pro 之间还存在一定差距。
Kimi-k2
Kimi-k2 是一个总参数为 1T, 激活参数为 32B 的 MoE 大语言模型,模型使用 15.5T token 进行训练,optimizer 使用了 MuonClip. 作者主要关注模型的 agent 能力
作者首先强调现在 LLM 发展主要是 Agentic Intelligence, 也就是让模型自主感知,规划,思考和与环境交互。
基于这个目标,作者就提出了 Kimi K2, 一个 1.04T 总参数,32B 激活参数的 MoE 模型,用于解决实现 agent Intelligence 中遇到的问题。作者主要进行了三点改进:
- MuonClip, 一个基于 Muon 的优化算法,来提高 Kimi K2 对 token 的利用效率以及提高训练的稳定性
- 大规模的 agentic 数据合成 pipeline: 作者构建了一个用于合成工具调用,agent 数据的 pipeline
- 通用的 RL 框架,作者将 RLVR 和 self-critic rubric reward mechanism 结合起来,用于提升模型的表现
Architecture
Kimi-K2 的架构与 DeepSeek-V3 相似,配置如下表所示
| 指标 | DeepSeek-V3 | Kimi K2 | |
|---|---|---|---|
| # Layers | 61 | 61 | = |
| Total Parameters | |||
| Activated Parameters | |||
| Experts (total) | 256 | 384 | |
| Experts Active per Token | 8 | 8 | = |
| Shared Experts | 1 | 1 | = |
| Attention Heads | 128 | 64 | |
| Number of Dense Layers | 3 | 1 | |
| Expert Grouping | Yes | No | - |
与 DeepSeek-V3 相比,模型主要进行了以下改动:
- 作者认为提高专家的稀疏性,可以有效提高模型表现。因此作者将专家个数提升了 50%.
- 为了降低模型在 inference 阶段的算力开销,作者将 attention heads 的个数降低了 50%.
Sparsity Scaling Law 作者首先构建了基于 Muon 的 sparsity law, 这里 sparsity 定义为激活专家个数与总专家个数之比,即:
作者在小规模上的实验结果如下图所示
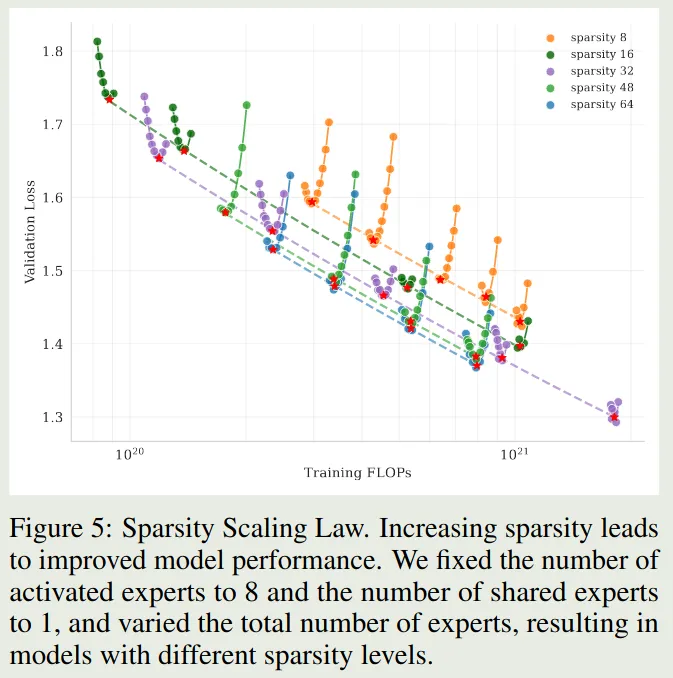
Observation 实验结果表明,在相同算力(激活专家个数)下,模型的表现随 sparsity 提高而增加。
但是,进一步提高 sparsity, 会让 infra 变的难以优化,因此在 Kimi-K2 里,将 sparsity 定义为 .
Number of attention heads 作者还分析了探究了 attention heads 的最优配置。DeepSeek-V3 将 attention heads 的个数设置为 layers 层数的 2 倍,来提高带宽利用率以及提高计算效率。但是,当上下文长度增加之后,attention head 变成了 computational bound. 作者对比了不同配置模型的表现,实验结果如下:
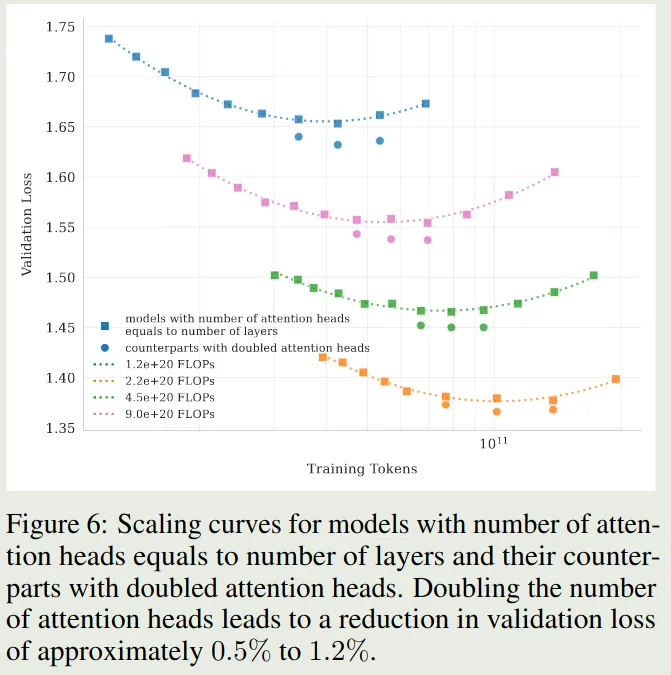
Observation 实验结果表明,使用双倍 attention head 带来的收益是比较小的,只有 到 左右
因此,作者在 Kimi-K2 中,奖 attention head 的个数设置为 .
Data
Kimi-K2 主要强调了 token efficiency, 即每个 token 对模型表现提升的贡献。token efficiency 越高,说明每个 token 对最终模型的贡献也就越高
相比于 Kimi-k1.5, Kimi-K2 使用了一个 rephrasing pipeline, 来提高高质量 token 的利用率,作者在 knowledge 和 mathematics domain 上进行了实验。
最终,Kimi-K2 的预训练数据包括了 15.5T token, 主要覆盖 Web text, code, mathmatics 以及 Knowledge 四个 domain. 大部分的数据处理与 Kimi-k1.5 相同。
Knowledge Data Rephrasing 作者构建了一个 synthetic rephrasing 框架来提高 knowledge token 的利用率,框架主要包含以下几个模块:
- Style and perspective-diverse prompting: 作者构建了一系列 prompt, 来让 LLM 从多个角度和风格来重新表述原始文本
- Chunk-wise auto-regressive generation: 为了保持模型在长文档中的 coherence 以及避免信息损失,作者使用了一个 chunk-based rewriting 策略,也就是对每个 chunk 分别进行改写,然后将它门汇总在一起
- Fidelity verification: 作者对原始文本和改写文本进行了 fidelity 检查来保证语义的一致性。
作者对比了以下三个设置对模型在 SimpleQA benchmark 上表现的影响,这三个设置分别是:
- 原始数据集训练 10 epoch
- 改写数据一次,然后训练 10 epoch
- 改写数据一次,训练 1 epoch
实验结果如下表所示
| # Rephrasings | # Epochs SimpleQA | Accuracy |
|---|---|---|
| 0 (raw wiki-text) | 10 | 23.76 |
| 1 | 10 | 27.39 |
| 10 | 1 | 28.94 |
可以看到,改写的策略可以有效提高模型在 SimpleQA benchmark 上的表现
Math Data Rephrasing 对于数学相关数据,作者基于 SwallowMath, 将数据改写成了学习笔记 (learning-note) 的风格。然后,作者还将其他语言的高质量文本翻译为英文。
Recall 个人认为,数据改写在一定程度上也算是合成数据,对于合成数据这一块,微软提出的 phi 系列是一个比较好的参考
MuonClip Optimizer
Kimi-K2 使用了 Muon optimizer, 之前的实验结果说明了在相同的 compute budget 下,Muon optimizer 的表现超过了 AdamW. 也就是说,Muon optimizer 更加高效。
但是,Muon optimizer 的问题是训练不稳定。为了解决这个问题,作者提出了 QK-clip, 一个 weight clipping 机制,来显示约束 attention logits. QK-clip 的机制是当输出的 logits 超过某一个阈值之后,就对齐进行截断。
每个 head 的 attention 的计算公式如下
其中, 是 hidden size, 分别是 query, key, value, 定义如下:
这里 是模型可学习的参数。
作者定义每个 head 的 max logit 如下:
最简单的做法就是直接进行截断,也就是
其中 , 这里 是所有 head 对应 的最大值。
但是,实际中,作者发现只有少部分 head 会出现 logits 爆炸现象。为了提高计算效率,作者针对每个 head 单独进行 scaling, 也就是 . 对于 MLA 架构,作者仅在 unshared 模块使用 clipping:
- 以及 , scaling factor 为
- , scaling factor 为
最后,作者将 Muon, weight decay, RMS matching 和 QK-clip 汇总在一起,得到 Kimi-k2 使用的 MuonClip optimizer, 算法如下所示:

接下来,作者对比了以下 Muon 和 MuonClip 两个优化器的表现,作者分别使用这两个优化器训练 53B-A9B 的 MoE 模型,实验结果如下
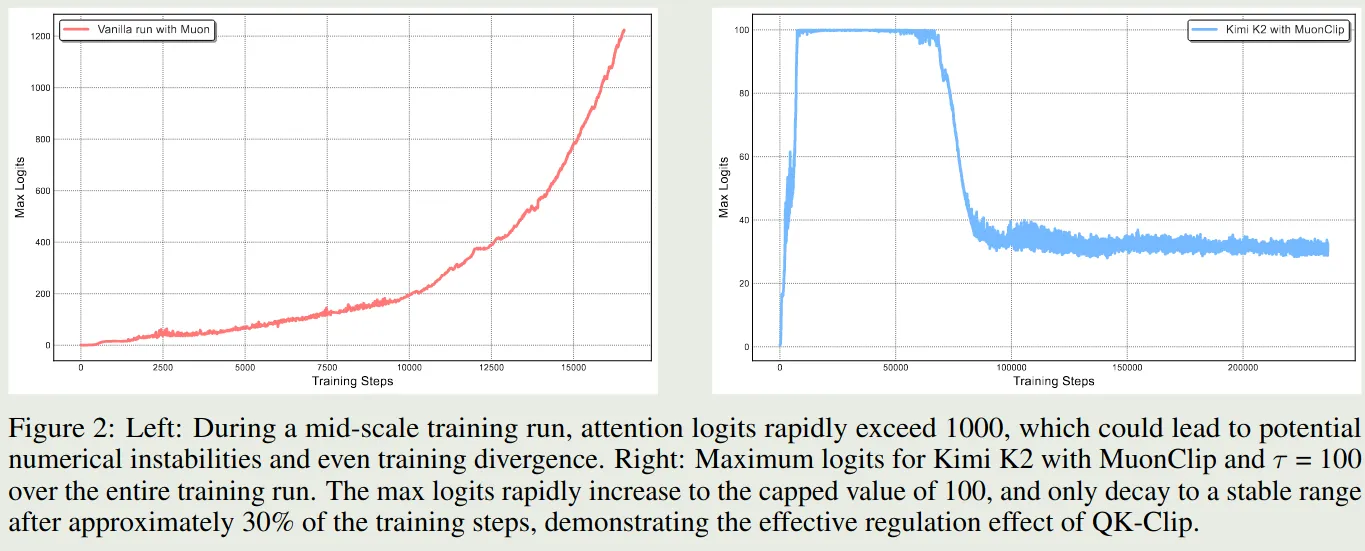
实验结果表明,Muon 优化器在 1000 步左右就出现了 logits 爆炸的现象,但是 MuonClip 通过优化可以避免这个问题。作者还发现,MuonClip 可以减少 loss spike 的产生,整体的 loss 变化情况如下图所示
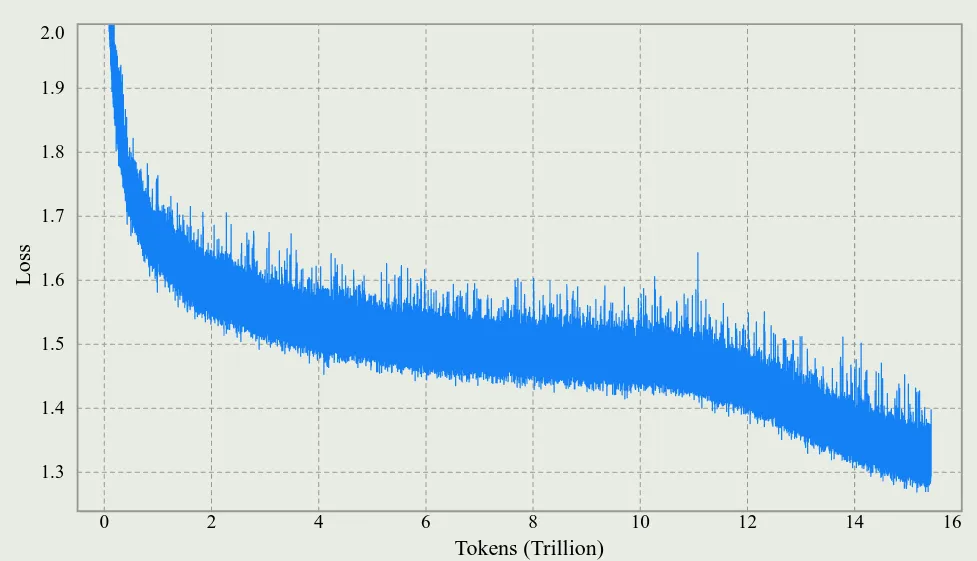
作者还在附录中说明 QK-clip 并不影响最终的收敛性,并且,为了尽可能减少对模型训练的干扰,作者发现,仅在训练初期 QK-clip 被激活:
- 在初始的 70, 000 步里,有 12.7% 的 attention heads 至少触发了一次 QK-clip, 并且将它们的 S_\max 降到了 100 以下
- 接下来的 70, 000 步里,QK-clip 就不再被激活
Infra
Kimi-k2 使用了 16-way 的 PP, 16-way 的 EP 以及 ZeRO-1 Data Parallelism. 具体流程如下
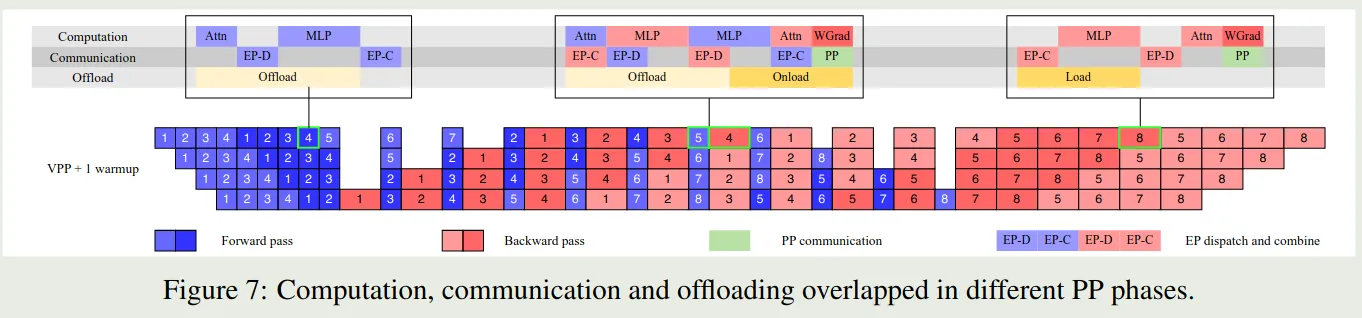
作者发现通过增加 warm-up mircro-batches, 我们可以有效重叠 EP 的 all-to-all communication 以及 computation. 但是,对于 [[DualPipe]], 其要求双倍的存储来保存参数和梯度,并且提高 PP 粒度会引入更多的 bubble, 因此 Kimi-K2 没有使用 DualPipe.
为了减少 [[1F1B]] 的 PP 通信开销,作者在反向传播的过程中同时进行 PP 通信,来进一步重合通信与计算。
作者还发现,使用更小的 EP group 可以提高整体的训练速度,因此作者将 EP 设置为 16.
作者发现,剩余的 GPU 内存不足以存放 MoE 的 activation, 因此作者采取了三个办法解决这个问题:
- Selective recomputation: 作者对 LayerNorm, SwiGLU, MLA 的 up-projection 和 MoE 的 down-projections 等进行重新计算。
- FP8 storage for insentive activations: 作者使用了 FP8 精度来存储 MoE up-projections 以及 SwiGLU. 作者发现使用 FP8 进行计算可能会导致性能下降,因此作者并没有使用 FP8 进行计算。
- Activation CPU offload: 作者将其余的 activation 放在 CPU RAM 上,在 1F1B 的过程中,作者再进行加载
Training Recipe
模型上下文长度为 4096, 使用 MuonClip 进行优化,使用 WSD lr Scheduler.weight decay 为 0.1, global batch size 为 67M tokens.
预训练结束之后,作者加入了一个 long-context activation stage. 这个阶段,作者使用了 400B 的 4K 上下文的 token 和 60B 的 32K 上下文的 60B token. 最后作者使用 YARN 将模型上下文长度扩展到 128K.
SFT
数据的构建主要是基于:
- prompt 的多样性
- Response 的质量
作者构建了一系列的数据生成 pipeline, 然后使用 Kimi-k1.5 来生成多样化的回答,最后再进行质量评估和过滤。这里,作者主要介绍了一下 tool-use 数据的构建
受 ACEBench 启发,作者构建了一个模仿真实世界 tool-use 的数据合成 pipeline. pipeline 如下图所示
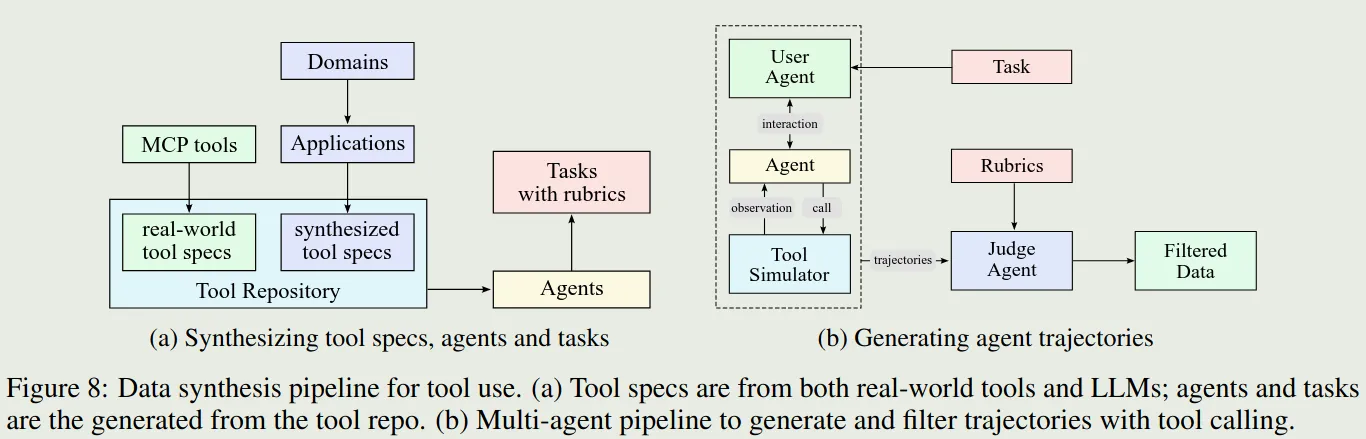
pipeline 主要包含三个阶段:
- tool spec generation: 作者基于 MCP tools 和 self-evolved 的数据合成策略来构建 tool repository. MCP tools 包括 3000+ 的 tools,合成了 20,000 个 tools
- Agent and task generation: 作者还用不同的 system prompt 以及不同的 tools combination 来构建对应的 agent. 然后对不同的 agent, 作者构建了对应的成功标准均,工具调用模式以及评估方式
- Trajectory generation: 作者首先构建不同风格的 LLM, 然后作者使用一个 simulator 来执行 tool call 并给予反馈。
最后,作者对数据进行了过滤。
作者还加入了 coding 以及软件工程等任务相关数据来进一步提高模型的 agent 能力
RL
RL 与 Kimi-K1.5 差不多。作者进一步提高了 RL 阶段的算力并做出了亮点改进:
- 作者构建了类似 Gym 的框架,用于扩展 RL 的能力
- 作者加入了更多 RLVR 的任务
Data 数据主要包括以下几类:
- Math, STEM and logical tasks: 数据构建的原则为多样化和中等难度
- Instruction following: 作者基于 hybrid rule verification 和 multi-source instruction generation 来合成复杂的指令跟随数据
- Faithfulness: 作者训练了一个 judge model 来提供 reward
- Coding & Software Engineering: 作者从开源数据收集并合成了代码相关数据
- Safety. 提高模型的安全性,防止 jailbreak
Reward 作者使用了 self-critique rubric reward 的奖励机制。
首先,对于 Kimi-k2 的回答,作者会使用另一个 kimi-k2 作为 critic,基于三个方面进行排序:
- core rubric: AI 的核心价值观
- prescriptive rubric: 避免 reward hacking
- human-annotated rubric: 特定的上下文
在训练的过程中,critic 也会基于 verifiable signals 进行 refine
RL training RL 的训练目标与 Kimi-k1.5 相同
其中 是 sample response 的平均奖励。
作者做了以下几点改进来提高模型在不同 domain 上的表现:
- Budget control: 作者针对不同任务分别设置了最大 token 限制,模型超过这个限制会受到惩罚。猜测应该是 length penalty 或者类似 Qwen3 一样,直接中断思考过程输出最终答案
- PTX loss: 作者使用了 PTX loss 来提高模型对于高质量数据的利用率以及降低模型的过拟合
- Temperature Decay: 作者发现,训练后期保持较高的采样温度会影响模型的表现,因此作者设置了一个 schedule, 来逐步降低采样温度。
RL Infra
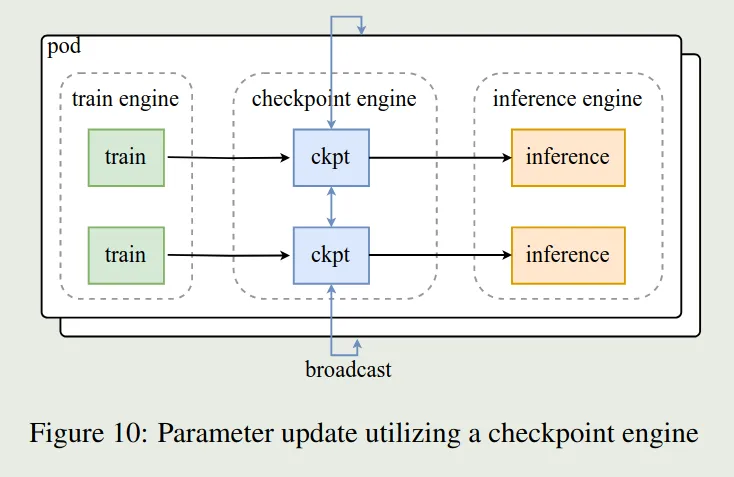
RL infra 与 Kimi-k1.5 类似。主要包含三个模块。其中 train engine 和 inference engine 两者互相切换,一个 engine 进行 training 的时候,另一个 engine 就进行 inference, 为了提高 engine 切换的效率,作者使用了 checkpoint engine 来传输更新后的参数。
Evaluation
模型评估结果如下图所示
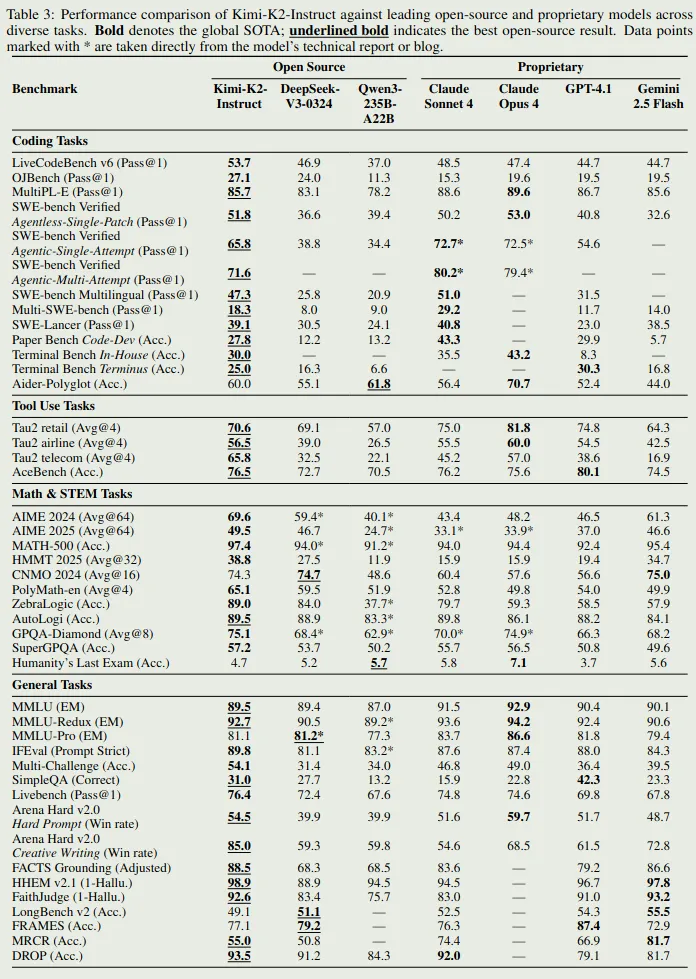
评估结果显示,模型在 coding 和通用任务上的表现仅次于 Claude 4, 大部分 benchmark 上都是第二名甚至是 sota.
Conclusion
作者在本文中提出了 Kimi-K2, 一个总参数为 1B 的 MoE 大语言模型。作者在架构,数据和优化器上进行了创新。并且通过 post-training 显著提高了模型的 agent 以及 tool-use 能力
作者发现模型主要存在的问题有:
- reasoning 任务过难或者 tool 的定义不清晰的时候,模型会使用很多 token
- 有时候工具调用可能会降低模型的表现
- 模型在 agentic coding 任务上的能力需要进一步提升