Introduction
YaRN (Yet Another RoPE extentionN method) (Peng et al., 2026) 是23年9月EleutherAI等提出来的一个扩展LLM上下文长度的方法,后来被Qwen系列模型所应用。
Preliminary
作者首先回顾了一下RoPE, 具体内容请参见上一篇blog。并使用了 来表示RoPE:
其中 是多维旋转矩阵, , , 是一个超参数,RoPE中设置为 , 是对应的query/key projection layer的权重矩阵, 是输入的hidden states.
接下来,作者定义了两个新的变量:
scaling factor 假设预训练的上下文长度为 , 扩展的上下文长度为 , 则我们定义scaling factor 为
易知 .
wavelength 我们将 定义为 -th 维的RoPE embedding对应的 wavelength:
wavelength描述了对于第 个维度,RoPE旋转一周 () 所需要的上下文长度。
Unified Perspective on Related Work
基于 , 作者统一了已有的扩展上下文长度的方法,作者将不同的扩展方法使用一个通用函数 来表示,这里 和 分别代表了不同的长度外推方法所使用的变换。
Position Interpolation
Position Interpolation (PI) (Chen et al., 2023) 的核心思想在于,我们可以通过Interpolation,将超过预训练长度的文本给压缩到当前最大长度,以此来避免RoPE外推产生的问题,其对应的公式为
其中 为我们扩展之后的上下文长度, 为我们预训练的上下文长度。使用通用函数表示的话,我们有
NTK-aware Interpolation
PI的问题是,并没有考虑不同维度的wavelength。 基于NTK理论,DNN当输入维度比较低,且embedding缺少高频内容时,模型就会很难学习到高频信息。对应到RoPE里面,输入的token position id是低位信息(1维),而输出的RoPE是一个 维的复杂向量。因此,当输入token非常相似却距离非常近时,RoPE就会丢失高频的细节信息
因此,为了解决这个问题,作者对不同的维度使用了不同的缩放策略:维度比较小时,其缩放的更多,维度比较大是,其缩放的更少。
基于这个策略,作者提出了NTK-aware interpolation,其定义如下:
其中
实际中,这种方法会产生out-of-bound的值,因此最终结果会比PI要差一点,为了解决这个问题,一般会使用比 更大的scaling factor.
上式的推导基于一个简单的假设:我们希望最后一个维度的wavelength在scaling之后,是线性变化的,即 , 求解之后,我们就得到了上面的定义
PI 和NTK-aware interpolation的问题在于,我们对不同的维度的处理都是一样的。这类不在乎wavelength的方法被称为blind interpolation methods, 接下来要介绍的就是基于wavelength的方法,即target interpolation methods.
NTK-by-parts Interpolation
与NTK-aware interpolation, NTK-by-parts interpolation基于wavelength来考虑不同维度上所做的变换。
对于低维度,其 非常大,因此旋转一周所需要的上下文长度也非常大。实际上就导致某些维度的embedding并不是均匀分布的,(比如说只有 这个区间的embedding),这个时候,模型就只能访问到绝对位置信息,而访问不到相对位置信息。 另外,当我们对所有的维度都进行scale的时候,所有的token都会与彼此更加靠近,这损害了模型对于局部信息的获取能力。 基于这些认知,作者基于wavelength,对不同的维度分别进行处理:
- 如果wavelength远小于上下文长度 , 则我们不做任何处理
- 如果wavelength等于或者大于上下文长度 , 则我们使用NTK-aware interpolation 进行处理
- 对于中间的其他维度,我们进行了一个trade off
作者定义了一个ratio 来描述原始上下文长度 和 wavelength 之间的关系
基于这个ratio,我们可以定义上面的三种处理方式对应的权重
其中, 是超参数, , 分别代表了上面的第1种,第2种情况。
最后,NTK-by-parts interpolation的定义如下
作者通过实验发现,在LLaMA上, 和 是一个比较好的选择
Dynamic NTK Interpolation
在实际中,一个经常遇到的场景就是sequence length会从1逐步上升到最大上下文长度,比如说inference的时候。对于这种情况,我们有两种解决方法:
- 在整个inference周期中,RoPE的scaling factor都设置为 , 其中 是扩展后的上下文长度
- 在每次foward的过程汇总,都更新sclaing factor , 这里 是当前sequence的长度
作者发现,方案1在sequence长度小于 的时候性能会下降,并且当上下文长度超过 时,性能下降的更快。 但是,方案2可以让模型的性能下降曲线更平缓。因此,作者将这种inference-time方法称为 Dynamic Scaling method, 当其与NTK-aware方法结合时,就得到了 Dynamic NTK interpolation
作者通过实验发现,Dynamic NTK interpolation在 时,效果非常好
YaRN
在YaRN中,作者针对Dynamic NTK interpolation做了进一步改进,也就是在计算attention softmax时,加入了一个温度参数 , 这样attention的计算就变成了
作者发现,通过这种scaling的方式,YaRN可以在不改变代码的前提下,更改attention的机制。并且,其不增加训练和推理的cost
作者将YaRN定义为结合了NTK-by-parts interpolation和上述scaling技巧的方法
对于LLaMA,作者推荐使用如下参数:
实验结果如下
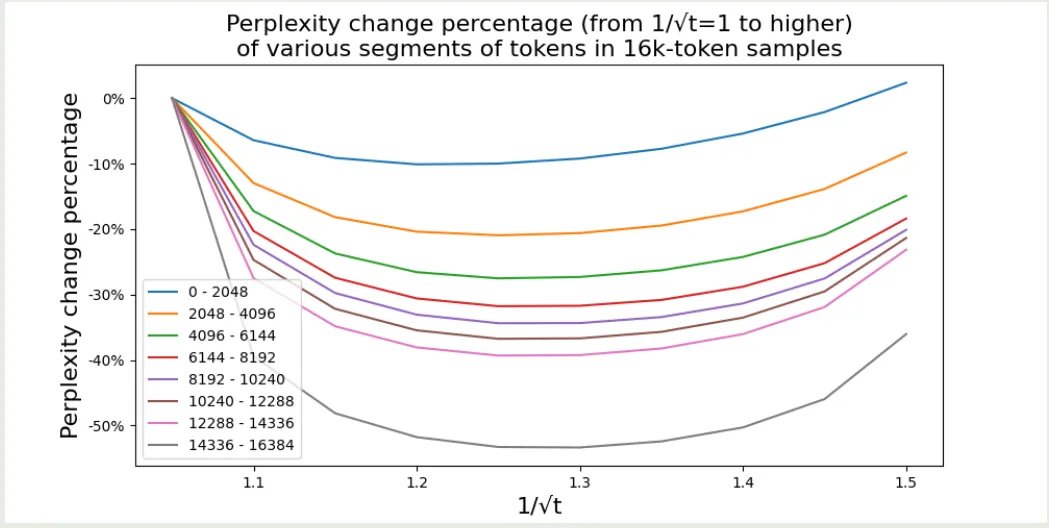
作者发现:
- 对于合适的 , 扩展上下文之后,perplexity会变的更好
- 最好的 对于不同的位置和样本提升都是一样的
Evaluation
实验结果如下
| Extension Method | Trained Tokens | Context Window | Evaluation Context Window Size | |||||
|---|---|---|---|---|---|---|---|---|
| 2048 | 4096 | 6144 | 8192 | 10240 | ||||
| PI (s = 2) | 1B | 8k | 3.92 | 3.51 | 3.51 | 3.34 | 8.07 | |
| NTK ( = 20k) | 1B | 8k | 4.20 | 3.75 | 3.74 | 3.59 | 6.24 | |
| YaRN (s = 2) | 400M | 8k | 3.91 | 3.50 | 3.51 | 3.35 | 6.04 |
可以看到,YaRN使用的数据更少,并且当模型扩展到10240的时候,其表现下降的最慢,这说明了YaRN在扩展上下文长度时的有效性
原始RoPE,dynamic-PI和dynamic-YaRN的对比
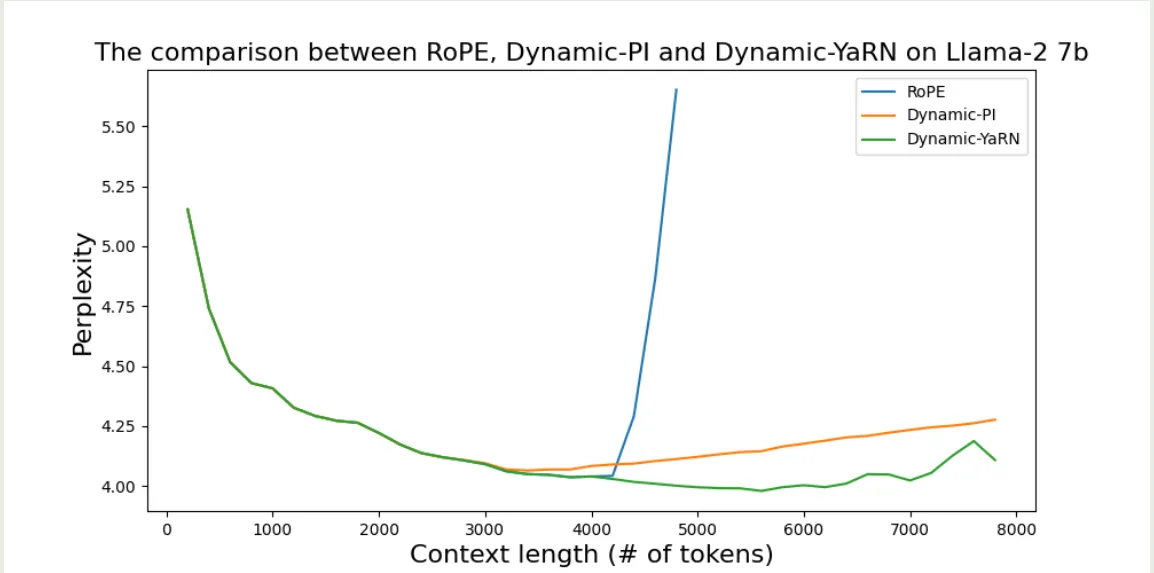
可以看到,RoPE的上下文扩展能力很差,Dynamic-YaRN的表现最好。
Code
YaRN的实现在HuggingFace/src/transformers/modeling_rope_utils.py 里的 _compute_yarn_parameters 函数里,其返回 inv_freq 以及 attention_factor 两个量,前者代表了 , 后者代表 .
def get_mscale(scale):
if scale <= 1:
return 1.0
return 0.1 * math.log(scale) + 1.0
def find_correction_dim(num_rotations, dim, base, max_position_embeddings):
"""Inverse dimension formula to find the dimension based on the number of rotations"""
return (dim * math.log(max_position_embeddings / (num_rotations * 2 * math.pi))) / (2 * math.log(base))
def find_correction_range(low_rot, high_rot, dim, base, max_position_embeddings):
"""Find dimension range bounds based on rotations"""
low = math.floor(find_correction_dim(low_rot, dim, base, max_position_embeddings))
high = math.ceil(find_correction_dim(high_rot, dim, base, max_position_embeddings))
return max(low, 0), min(high, dim - 1)
def linear_ramp_factor(min, max, dim):
if min == max:
max += 0.001 # Prevent singularity
linear_func = (torch.arange(dim, dtype=torch.float32) - min) / (max - min)
ramp_func = torch.clamp(linear_func, 0, 1)
return ramp_func
class YaRNRotaryEmbedding(nn.Module):
def __init__(self, config):
beta_fast = config.get("beta_fast") or 32
beta_slow = config.get("beta_slow") or 1
dim = config["head_dim"]
factor = config.max_position_embeddings / original_max_position_embeddings
pos_freqs = base ** (torch.arange(0, dim, 2) / dim)
inv_freq_extrapolation = 1.0 / pos_freqs
inv_freq_interpolation = 1.0 / (factor * pos_freqs)
low, high = find_correction_range(beta_fast, beta_slow, dim, base, original_max_position_embeddings)
# Get n-dimensional rotational scaling corrected for extrapolation
inv_freq_extrapolation_factor = 1 - linear_ramp_factor(low, high, dim // 2)
inv_freq = (inv_freq_interpolation * (1 - inv_freq_extrapolation_factor) + inv_freq_extrapolation * inv_freq_extrapolation_factor)
attention_factor = get_mscale(factor)
def forward(self, x, position_ids):
...
return cos, sin
实际的transformers代码中,Qwen使用的还是默认的RoPE,在inference时如果我们需要扩展上下文,可以通过修改config的形式:
from transformers import pipeline
model_name_or_path = "Qwen/Qwen3-8B"
generator = pipeline(
"text-generation",
model_name_or_path,
torch_dtype="auto",
device_map="auto",
model_kwargs={
"max_position_embeddings": 131072,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768,
},
}
)
Introduction
RoPE ABF (Xiong et al., 2024) 提出了通过提高 base frequency 来解决 attention decay 问题
RoPE 已经成为了大多数 LLM 使用的 position encoding 范式,但是,RoPE 与 LLM long context 之间的关系还没有被探索清楚。在本文中,作者就探究了 base frequency 与 LLM context capability 之间的关系,并给出了一个达到指定上下文长度所需要的 base frequency 的 lower bound.
Method
首先作者回顾了 attention 与 RoPE 的定义, 关键就是 RoPE 这部分,如下所示
这里 就是 base frequency, 作者总结不同模型的 base frequency 配置如下表所示
| Model | Llama-7B | Llama2-7B | Llama3-8B | Mistral-7B | Baichuan2-7B |
|---|---|---|---|---|---|
| Base frequency | 10,000 | 10,000 | 500,000 | 1,000,000 | 10,000 |
| Context length | 2048 | 4096 | 8192 | 32,768 | 4,096 |
接下来,作者回顾了 YARN. 其核心思想在于,预训练阶段所有可能的 都见过,才能保证模型的 OOD 表现
作者认为 base frequency 的设置应该满足两个条件:
- The closer token gets more attention: 当前的 token 应该给邻近的 token 更高的注意力
- The similar token gets more attention: 当前的 token 应该给相似的 token 更高的注意力
在 RoPE 中,作者已经给出了 与相对距离 之间的关系。因此第一个性质已经满足了。
接下来,作者分析了相似 token 的性质,作者定义 token 的相似性如下:
这里 代表了相似的 token, 而 是一个随机 token. 作者给出的结论如下
Theorem 假设 独立同分布,它们的标准差为 , 则对于 , 是一个随机变量满足 , 则我们有
作者定义 , 作者认为给定 , 模型的上下文长度 满足
也就是说,base frequency 决定了 LLM 的上下文长度。作者给出了不同的上下文长度对应的 base frequency 如下表所示
| Context Len. | 1k | 2k | 4k | 8k | 16k | 32k | 64k | 128k | 256k | 512k | 1M |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Lower Bound | 4.3e3 | 1.6e4 | 2.7e4 | 8.4e4 | 3.1e5 | 6.4e5 | 2.1e6 | 7.8e6 | 3.6e7 | 6.4e7 | 5.1e8 |
总的来说,远距离衰减性保证了模型会更关注邻近的 token, 而相似 token 保证了模型能够区分出真正有意义的 token.
Experiments
作者首先分析了 base frequency 在 fine-tuning 阶段对模型上下文能力的影响,实验结果如下图所示
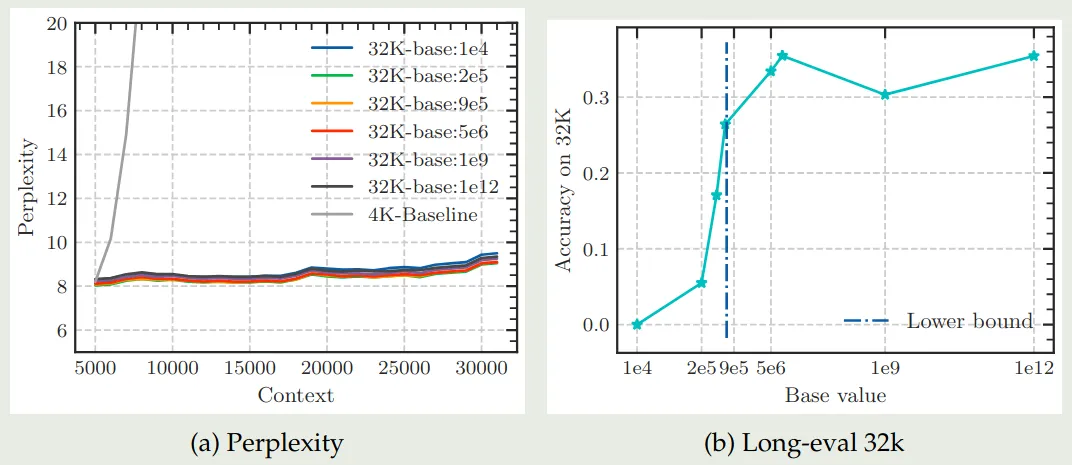
从实验结果可以看到,当 base frequency 低于阈值时,模型的表现急剧下降。
作者进一步探讨了 base frequency 对于模型 pre-training 阶段的影响,结果也是一样的,即非常小的 base frequency 会限制模型的 context 能力,结果下图所示 (三行分别代表了 base frequency 为 1e2, 1e4 和 1e6 的情况)
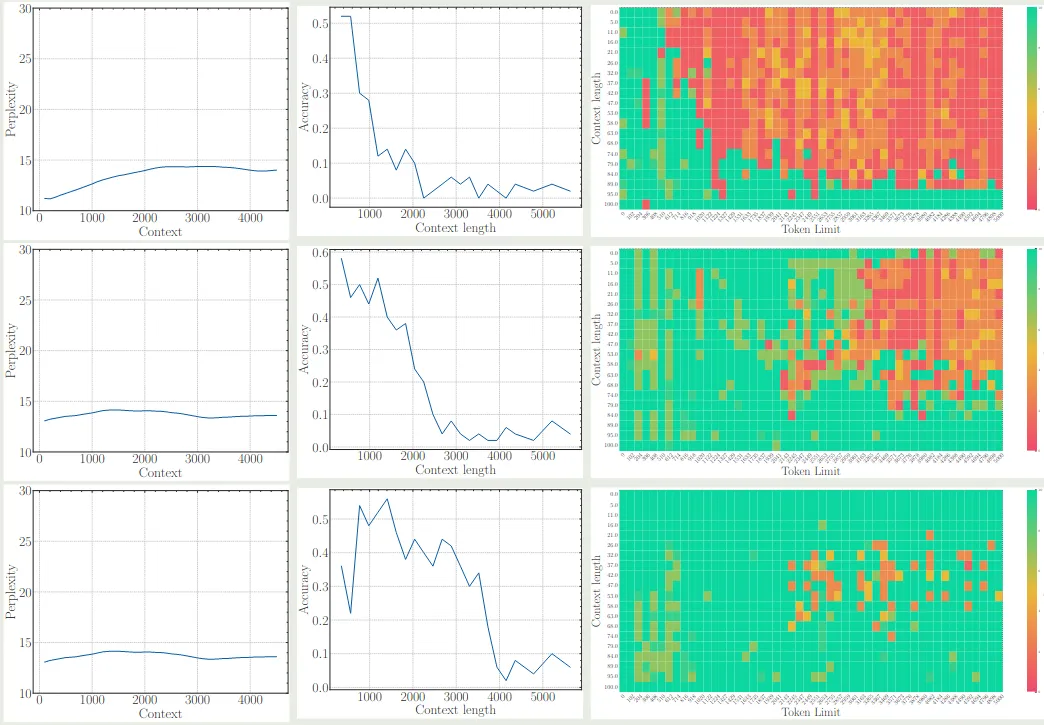
可以看到,尽管 perplexity 都差不多,但是使用更大的 base frequency 其长上下文能力明显更好。
作者进一步分析了为什么较小的 base frequency 会影响模型的长上下文能力。作者认为较小的 base frequency 会导致 接近于 0, 从而模型难以区分随机 token 和相似 token, 这样模型只能依赖于邻近 token 进行学习,这样就限制了模型的长上下文能力
作者还进一步对比了提高 base frequency 与 Interpolation 两种做法,实验结果如下表所示
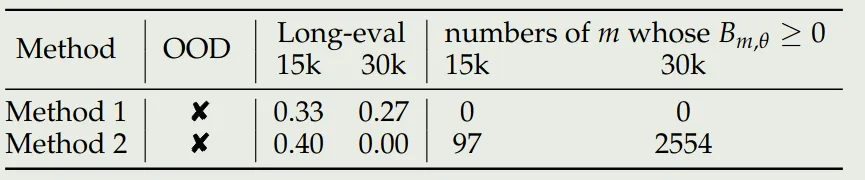
实验结果说明,Interpolation 在上下文超过 30K 之后,其 的 次数显著增加,表明了其和上下文能力之间的关系。
Conclusion
作者在本文中,探究了 RoPE 中 base frequency 与 LLM 上下文能力之间的关系,发现了提高模型的上下文能力需要关注 RoPE 的 base frequency 超参数,并给出了对应的 lower bound. 作者通过实验验证了这个观点。
作者提出了 StreamingLLM, 一个基于 attention sink 来提高 sliding window attention 在超长上下文场景下表现的方法。
Introduction
已有的基于 softmax attention 的架构的问题在于很难扩展到长上下文的场景,主要原因有两点:
- KV cache 会随着序列长度增加而商城,从而提高 decoding 的 latency
- 序列长度超过预训练的 context length 之后,模型表现会急剧下降
为了解决这个问题,已有的方法可以分为三类:
- length extrapolation: 使用 RoPE 或者 AliBi 等方法来扩展 LLM 的 context length, 这类方法的问题是扩展的上下文长度仍然有限,对于 streaming 的场景作用有限
- context window attention: 扩展 LLM 的上下文长度,如 flash attention (Dao et al., 2022) 等来降低 attention 的计算和内存开销。这类方法也是只在有限的上下文场景下 work
- Improving LLMs’ Utilization of Long Text: 更好利用长上下文的数据
基于已有的工作的发现,作者提出了本文研究的核心问题:
如何在不损失模型表现和效率的情况下,提高模型在无限长上下文场景下的表现。
为了解决这个问题,作者首先分析了 sliding window attention 的不足,作者发现,sliding window attention 在超过 KV cache size 之后,表现也会急剧下降。作者通过实验发现,sliding window attention 表现急剧下降的原因在于 attention sink, 也就是模型损失了对于初始 token 的关注,从而导致模型表现下降。
基于 attention sink, 作者设计了 StreamingLLM, 用于提高 sliding window attention 在长上下文场景下的表现,结果发现,模型的表现有了大幅度的提升。
作者还进一步在预训练阶段加入了 sink token 充当初始 token, 进一步提高模型的表现。
Method
Attention Sink
作者首先探究了一下 softmax attention 以及 sliding window attention 性能下降的节点,实验结果如下图所示

可以看到,softmax attention 性能急剧下降的节点为 pre-training 的 context length; 而 sliding window attention 性能急剧下降的节点为 KV cache size.
接下来,作者分析了一下不同 layer 的 attention 分布情况,如下图所示
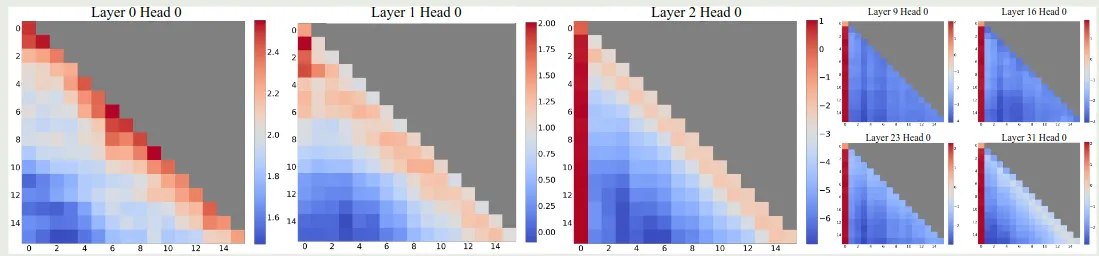
可以看到,初始的 2 层 layer 里 attention logits 的分布比较均匀。但是在后续的 layer 里,第一个 token 的权重都大幅度上升。
作者分析原因认为,sliding window attention 在超过 KV cache size 之后性能急剧下降的主要原因是初始 token 不再参与 softmax 的计算,这导致了 softmax 的计算出现了比较大的变化,从而模型的表现开始下降。
为了探究初始 token 对最终模型表现的影响因素是语义层面还是位置层面的,作者将初始的 token 替换为 \n, 并比较了模型的表现,结果如下表所示
| Llama-2-13B | PPL (↓) |
|---|---|
| 0 + 1024(Window) | 5158.07 |
| 4 + 1020 | 5.40 |
| 4”\n”+1020 | 5.60 |
可以看到,把初始的四个 token 替换为 \n, 并不影响模型最终的表现,这说明是初始 token 的位置信息在发挥作用。
作者接下来探究了一下模型架构的影响,实验结果如下表所示
| Cache Config | 0+2048 | 1+2047 | 2+2046 | 4+2044 | 8+2040 |
|---|---|---|---|---|---|
| Falcon-7B | 17.90 | 12.12 | 12.12 | 12.12 | 12.12 |
| MPT-7B | 460.29 | 14.99 | 15.00 | 14.99 | 14.98 |
| Pythia-12B | 21.62 | 11.95 | 12.09 | 12.09 | 12.02 |
| Cache Config | 0+4096 | 1+4095 | 2+4094 | 4+4092 | 8+4088 |
| Llama-2-7B | 3359.95 | 11.88 | 10.51 | 9.59 | 9.54 |
可以看到,不同的模型架构都存在这个问题,这说明 sliding window attention 的影响与架构无关。并且,作者认为,使用初始 4 个 token 就可以有效的避免模型的性能下降,进一步增加初始 token 的数量不会有进一步提升。
作者分析 attention sink 出现的原因在于,
- 初始的 token 对于后续所有的 token 都是可见的,因此其会携带一些信息
- 在预训练阶段,模型并没有一个一致的初始 token 来标注起始信息,这导致模型会默认使用第一个 token 来储存一些信息。
为了解决这个问题,作者就提出了缓存初始 token 的方法,具体做法就是,在 sliding window attention 的基础上,我们还会加上初始 token 的信息,作者展示示意图如下所示
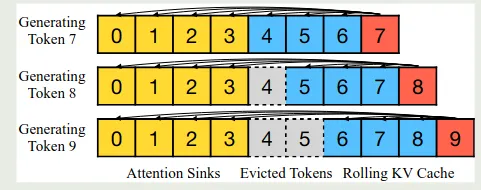
也就是说,我们初始 token 始终会参与计算(论文中初始 token 数量为 4),然后我们会维持一个大小为 3 的 KV cache 队列来进行最终 sliding window attention 的计算,这样,每次计算 attention 的时候,我们就会使用 这么多的 token 来计算 attention. 作者对比了不同 attention 的计算方式,如下图所示
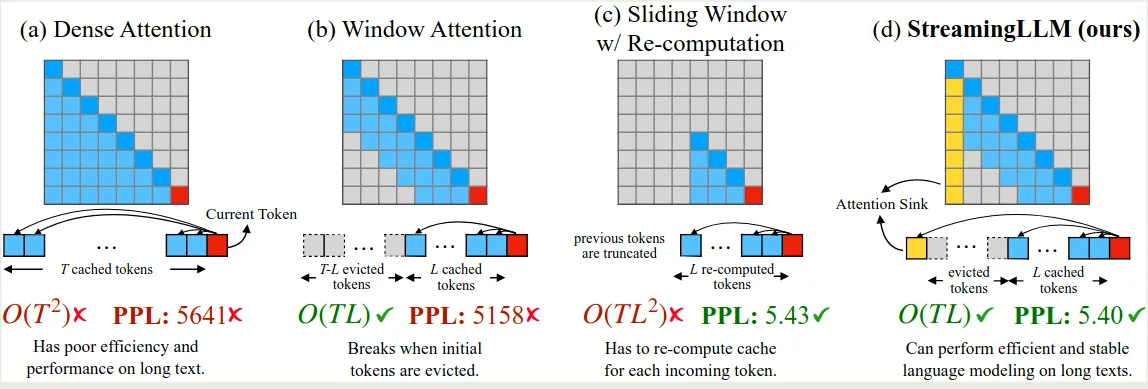
前面是在 inference 阶段进行优化的,作者现在进一步探究在 pre-training 阶段加入 attention sink 参与训练对模型表现的影响。
[[softmax-off-by-one]] 提出了我们应该加入一个 zero sink token, 其计算公式如下
这里 是输入的序列。我们可以将 sink token 视为一个 key 以及 value 都是 0 向量的特殊 token.
在本文中,作者使用了一个可学习的 sink token. 作者对比了原始 softmax attention, 使用 zero sink attention, learnable sink attention 三种方法的表现,结果如下表所示
| Cache Config | 0+1024 | 1+1023 | 2+1022 | 4+1020 |
|---|---|---|---|---|
| Vanilla | 27.87 | 18.49 | 18.05 | 18.05 |
| Zero Sink | 29214 | 19.90 | 18.27 | 18.01 |
| Learnable Sink | 1235 | 18.01 | 18.01 | 18.02 |
可以看到 zero sink 仍然需要一部分初始 token 来维持模型的表现。作者在论文中推荐使用 learnable sink.
Experiments
作者首先验证了 StreamlingLLM 在不同架构上的表现,结果如下图所示

实验结果显示,StreamingLLM 可以扩展到 4M 的上下文
接下来,作者探究了以下在 Pretraining 阶段加入 learnable sink token 对模型表现的影响,结果如下图所示
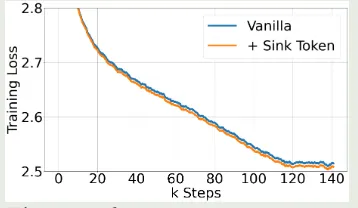
可以看到,加入 sink token 之后对模型的表现没有显著影响。并且,模型在下游任务上的表现与标准的 softmax attention 表现差不多。
作者还对 StreamlingLLM 进行了可视化,结果如下图所示

作者进一步评估了 StreamingLLM 在下游任务上的表现,我们主要关注一下 ARC 上的表现,结果如下图所示
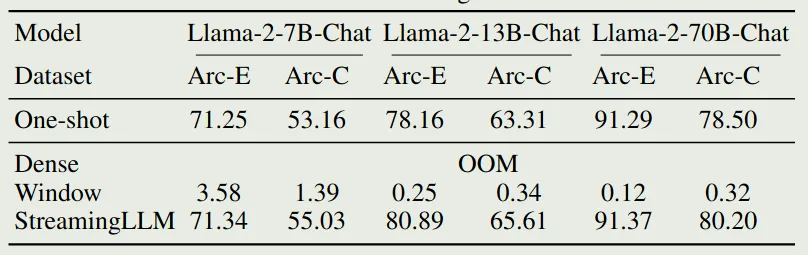
可以看到,full attention 出现了 OOM error, 而 sliding window attention 虽然避免了 OOM 的问题,但是其表现非常差。而 StreamingLLM 则进一步提高了 Sliding Window attention 的表现。
Conclusion
作者在本文中提出了 StreamingLLM, 一个在 Sliding window attention 中加入 sink token 来避免超过 cache size 之后模型表现急剧下降的问题。作者详细介绍了 attention sink 现象以及解决方法。