Fix Point Theorem, 即不动点定理,是泛函分析中的基本工具,被广泛应用于非线性函数的分析。
在介绍不动点定理之前,我们先介绍两个概念
首先是不动点的概念。
Definition: Fixed Point 对于函数 f : R n → R n f:\mathbb{R}^n\to\mathbb{R}^n f : R n → R n x ∗ ∈ R n x^*\in\mathbb{R}^n x ∗ ∈ R n
f ( x ∗ ) = x ∗ f(x^*)=x^* f ( x ∗ ) = x ∗ 则我们称 x ∗ x^* x ∗ f f f
接下来是 contraction mapping 的概念
Definition: Contraction Mapping 对于函数 f : R n → R n f:\mathbb{R}^n\to\mathbb{R}^n f : R n → R n γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ ∈ ( 0 , 1 )
∥ f ( x 1 ) − f ( x 2 ) ∥ ≤ γ ∥ x 1 − x 2 ∥ , ∀ x 1 , x 2 ∈ R n \|f(x_1)-f(x_2)\| \leq \gamma \|x_1-x_2\|,\forall\ x_1,x_2\in\mathbb{R}^n ∥ f ( x 1 ) − f ( x 2 ) ∥ ≤ γ ∥ x 1 − x 2 ∥ , ∀ x 1 , x 2 ∈ R n 则我们称 f f f ∥ ⋅ ∥ \|\cdot\| ∥ ⋅ ∥
接下来,我们介绍不动点定理
Theorem: Fixed Point Theorem 给定 equation x = f ( x ) x=f(x) x = f ( x ) f : R n → R n f:\mathbb{R}^n\to\mathbb{R}^n f : R n → R n f f f f f f
Existence: 存在 fixed point x ∗ ∈ R n x^*\in\mathbb{R}^n x ∗ ∈ R n f ( x ∗ ) = x ∗ f(x^*)=x^* f ( x ∗ ) = x ∗
Uniqueness: fixed point x ∗ x^* x ∗
Algorithm: 对任意 x 0 ∈ R n x^0\in\mathbb{R}^n x 0 ∈ R n x k + 1 = f ( x k ) x_{k+1}=f(x_k) x k + 1 = f ( x k ) { x k } k = 0 ∞ \{x_k\}_{k=0}^{\infty} { x k } k = 0 ∞ x ∗ x* x ∗
证明需要用到柯西列的概念。
Definition: Cauchy sequence 一个序列 x 1 , x 2 , … x_1,x_2,\dots x 1 , x 2 , … ϵ > 0 \epsilon>0 ϵ > 0 N > 0 N>0 N > 0
∥ x m − x n ∥ < ϵ , ∀ m , n > N . \|x_m-x_n\| <\epsilon,\forall m, n>N. ∥ x m − x n ∥ < ϵ , ∀ m , n > N .
柯西列的一个重要性质为柯西列一定是收敛列。
Proof: 我们首先证明由 x k = f ( x k = 1 ) x_k=f(x_{k=1}) x k = f ( x k = 1 ) { x k } k = 1 ∞ \{x_k\}_{k=1}^{\infty} { x k } k = 1 ∞ { x k } k = 1 ∞ \{x_k\}_{k=1}^{\infty} { x k } k = 1 ∞
注意到 f f f
∥ x k + 1 − x k ∥ = ∥ f ( x k ) − f ( x k − 1 ) ∥ ≤ γ ∥ x k − x k − 1 ∥ \|x_{k+1}-x_k\| = \|f(x_k)-f(x_{k-1})\|\leq \gamma \|x_k-x_{k-1}\| ∥ x k + 1 − x k ∥ = ∥ f ( x k ) − f ( x k − 1 ) ∥ ≤ γ ∥ x k − x k − 1 ∥ 迭代下去,我们就得到
∥ x k + 1 − x k ∥ ≤ γ ∥ x k − x k − 1 ∥ ≤ ⋯ ≤ γ k ∥ x 1 − x 0 ∥ \|x_{k+1}-x_k\|\leq \gamma \|x_k-x_{k-1}\|\leq\cdots\leq \gamma^k \|x_1-x_{0}\| ∥ x k + 1 − x k ∥ ≤ γ ∥ x k − x k − 1 ∥ ≤ ⋯ ≤ γ k ∥ x 1 − x 0 ∥ 现在我们证明序列 { x k } k = 1 ∞ \{x_k\}_{k=1}^{\infty} { x k } k = 1 ∞
∥ x m − x n ∥ = ∥ x m − x m − 1 + x m − 1 − ⋯ − x n + 1 + x n + 1 − x n ∥ ≤ ∑ i = n m − 1 ∥ x i + 1 − x i ∥ ≤ ∑ i = n m − 1 γ i ∥ x 1 − x 0 ∥ ≤ γ n 1 − γ ∥ x 1 − x 0 ∥ . \begin{aligned}
\|x_m-x_n\| &= \|x_m-x_{m-1}+x_{m-1}-\cdots-x_{n+1}+x_{n+1}-x_n\|\\
&\leq \sum_{i=n}^{m-1}\|x_{i+1}-x_i\|\\
&\leq \sum_{i=n}^{m-1}\gamma^i \|x_{1}-x_0\|\\
&\leq \frac{\gamma^n}{1-\gamma}\|x_{1}-x_0\|.
\end{aligned} ∥ x m − x n ∥ = ∥ x m − x m − 1 + x m − 1 − ⋯ − x n + 1 + x n + 1 − x n ∥ ≤ i = n ∑ m − 1 ∥ x i + 1 − x i ∥ ≤ i = n ∑ m − 1 γ i ∥ x 1 − x 0 ∥ ≤ 1 − γ γ n ∥ x 1 − x 0 ∥. 从而,序列 { x k } k = 1 ∞ \{x_k\}_{k=1}^{\infty} { x k } k = 1 ∞
接下来,我们证明 x ∗ = lim k → ∞ x k x^*=\lim_{k\to\infty}x_k x ∗ = lim k → ∞ x k f ( x ) f(x) f ( x )
∥ f ( x k ) − x k ∥ = ∥ x k + 1 − x k ∥ ≤ γ k ∥ x 1 − x 0 ∥ → 0 , k → ∞ \|f(x_k)-x_k\| = \|x_{k+1}-x_k\|\leq \gamma^k\|x_1-x_0\| \to 0, k\to\infty ∥ f ( x k ) − x k ∥ = ∥ x k + 1 − x k ∥ ≤ γ k ∥ x 1 − x 0 ∥ → 0 , k → ∞ 我们有 lim k → ∞ f ( x k ) = lim k → ∞ x k \lim_{k\to\infty}f(x_k)=\lim_{k\to\infty}x_k lim k → ∞ f ( x k ) = lim k → ∞ x k f ( x ∗ ) = x ∗ f(x^*)=x^* f ( x ∗ ) = x ∗
然后,我们证明不动点唯一。假设还存在一个另外一个不动点 x ′ ≠ x ∗ x'\neq x^* x ′ = x ∗ f ( x ′ ) = x ′ f(x')=x' f ( x ′ ) = x ′
∥ x ′ − x ∗ ∥ = ∥ f ( x ′ ) − f ( x ′ ) ∥ ≤ γ ∥ x ′ − x ∗ ∥ \|x'-x^*\| = \|f(x')-f(x')\| \leq \gamma \|x'-x^*\| ∥ x ′ − x ∗ ∥ = ∥ f ( x ′ ) − f ( x ′ ) ∥ ≤ γ ∥ x ′ − x ∗ ∥ 由于 γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ ∈ ( 0 , 1 ) ∥ x ′ − x ∗ ∥ = 0 \|x'-x^*\|=0 ∥ x ′ − x ∗ ∥ = 0
最后,我们证明 x k + 1 = f ( x k ) x_{k+1}=f(x_k) x k + 1 = f ( x k )
∥ x ∗ − x n ∥ = lim m → ∞ ] ∥ x m − x n ∥ ≤ γ n 1 − γ ∥ x 1 − x 0 ∥ \|x^*-x_n\| = \lim_{m\to\infty}]\|x_m-x_n\| \leq \frac{\gamma^n}{1-\gamma}\|x_1-x_0\| ∥ x ∗ − x n ∥ = m → ∞ lim ] ∥ x m − x n ∥ ≤ 1 − γ γ n ∥ x 1 − x 0 ∥ 因为 γ < 1 \gamma <1 γ < 1
entropy 定义
H ( P ) = − ∑ i = 1 V P ( x i ) log P ( x i ) \mathcal{H}(P) = -\sum_{i=1}^V P(x_i)\log P(x_i) H ( P ) = − i = 1 ∑ V P ( x i ) log P ( x i ) 这里 [ x 1 , … , x V ] [x_1,\dots,x_V] [ x 1 , … , x V ] V V V P ( x i ) P(x_i) P ( x i ) i i i lm_head 之后输出一个 l o g i t s ∈ R b × s × V \mathrm{logits}\in\mathbb{R}^{b\times s\times V} logits ∈ R b × s × V P ( x i ) P(x_i) P ( x i )
P ( x ) = s o f t m a x ( l o g i t s ) = [ exp ( l o g i t s 1 ) ∑ j V exp ( l o g i t s j ) , … , exp ( l o g i t s V ) ∑ j V exp ( l o g i t s j ) ] P(x) = \mathrm{softmax}(\mathrm{logits})=\left[\frac{\exp(\mathrm{logits}_1)}{\sum_j^V\exp(\mathrm{logits}_j)},\dots,\frac{\exp(\mathrm{logits}_V)}{\sum_j^V\exp(\mathrm{logits}_j)}\right] P ( x ) = softmax ( logits ) = [ ∑ j V exp ( logits j ) exp ( logits 1 ) , … , ∑ j V exp ( logits j ) exp ( logits V ) ] 我们对 P ( x i ) P(x_i) P ( x i )
log P ( x i ) = log exp ( l o g i t s i ) ∑ j V exp ( l o g i t s j ) = l o g i t s i − log ∑ j V exp ( l o g i t s j ) \log P(x_i) = \log\frac{\exp(\mathrm{logits}_i)}{\sum_j^V\exp(\mathrm{logits}_j)} = \mathrm{logits}_i - \log \sum_j^V\exp(\mathrm{logits}_j) log P ( x i ) = log ∑ j V exp ( logits j ) exp ( logits i ) = logits i − log j ∑ V exp ( logits j ) 将上面这个表达式带入到 entropy 定义中得到
H ( P ) = − ∑ i = 1 V P ( x i ) ( l o g i t s i − log ∑ j V exp ( l o g i t s j ) ) = − ∑ i = 1 V P ( x i ) l o g i t s i + ∑ i = 1 V P ( x i ) log ∑ j V exp ( l o g i t s j ) = log ∑ j V exp ( l o g i t s j ) − ∑ i = 1 V P ( x i ) l o g i t s i = l o g s u m e x p ( l o g i t s ) − ∑ i = 1 V ( s o f t m a x ( l o g i t s ) ⋅ l o g i t s ) \begin{aligned}
\mathcal{H}(P) &= -\sum_{i=1}^VP(x_i)\left(\mathrm{logits}_i - \log \sum_j^V\exp(\mathrm{logits}_j)\right)\\
&=-\sum_{i=1}^VP(x_i)\mathrm{logits}_i+\sum_{i=1}^VP(x_i)\log \sum_j^V\exp(\mathrm{logits}_j)\\
&= \log \sum_j^V\exp(\mathrm{logits}_j)- \sum_{i=1}^VP(x_i)\mathrm{logits}_i\\
&= \boxed{\mathrm{logsumexp}(\mathrm{logits}) - \sum_{i=1}^V(\mathrm{softmax}(\mathrm{logits})\cdot \mathrm{logits})}
\end{aligned} H ( P ) = − i = 1 ∑ V P ( x i ) ( logits i − log j ∑ V exp ( logits j ) ) = − i = 1 ∑ V P ( x i ) logits i + i = 1 ∑ V P ( x i ) log j ∑ V exp ( logits j ) = log j ∑ V exp ( logits j ) − i = 1 ∑ V P ( x i ) logits i = logsumexp ( logits ) − i = 1 ∑ V ( softmax ( logits ) ⋅ logits ) verl 中的代码实现 为
Entropy in Verl def entropy_from_logits (logits: torch.Tensor) -> torch.Tensor: """Calculate Shannon entropy from unnormalized logits. Computes H(p) = -sum(p * log(p)) using the numerically stable formula: entropy = logsumexp(logits) - sum(softmax(logits) * logits) Args: logits: Unnormalized log-probabilities of shape (..., vocab_size). Returns: torch.Tensor: Entropy values with shape (...,), one per distribution. """ pd = torch.nn.functional.softmax(logits, dim =- 1 ) entropy = torch.logsumexp(logits, dim =- 1 ) - torch.sum(pd * logits, dim =- 1 ) return entropy
实际运算过程中,由于 batch size 和 vocabulary size 都比较大,因此计算时可能会导致峰值显存占用过高。为了解决这个问题,我们可以使用 chunking 策略来分块计算
Optimized Entropy calculation in Verl def entropy_from_logits_with_chunking (logits: torch.Tensor, chunk_size: int = 2048 ) -> torch.Tensor: """Memory-efficient entropy calculation using chunked processing. Computes entropy by processing the batch in chunks to reduce peak memory usage. Useful for large batch sizes or when memory is constrained. Args: logits: Unnormalized log-probabilities of shape (batch_size, vocab_size). chunk_size: Number of samples to process at once. Defaults to 2048. Returns: torch.Tensor: Entropy values with shape (batch_size,). Note: Converts chunks to float32 for numerical stability during computation. """ entropy = torch.zeros(logits.shape[ 0 ], device = logits.device) for i in range ( 0 , logits.shape[ 0 ], chunk_size): logits_chunk = logits[i : i + chunk_size].float() pd_chunk = torch.nn.functional.softmax(logits_chunk, dim =- 1 ) entropy_chunk = torch.logsumexp(logits_chunk, dim =- 1 ) - torch.sum(pd_chunk * logits_chunk, dim =- 1 ) entropy[i : i + chunk_size] = entropy_chunk return entropy
最大似然估计,即MLE (maximum likelihood estimation), 是一个估计参数分布的方法,其核心思想是:模型的参数,应该让观察样本出现的概率最大。
假设我们有一个参数分布 p ( x ∣ θ ) p(x\mid \theta) p ( x ∣ θ ) θ \theta θ p ( x ∣ θ ) p(x\mid \theta) p ( x ∣ θ ) i . i . d . i.i.d. i . i . d . X = { x 1 , … , x n } X=\{x_1,\dots,x_n\} X = { x 1 , … , x n }
似然函数 (likelihood function) 定义为给定数据 X X X
L ( θ ∣ X ) = P ( X ∣ θ ) \mathcal{L}(\theta\mid X) = P(X\mid \theta) L ( θ ∣ X ) = P ( X ∣ θ ) 由于 X = { x 1 , … , x n } X=\{x_1,\dots,x_n\} X = { x 1 , … , x n } i . i . d . i.i.d. i . i . d .
L ( θ ∣ X ) = ∏ i = 1 n p ( x i ∣ θ ) \mathcal{L}(\theta\mid X) = \prod_{i=1}^n p(x_i\mid \theta) L ( θ ∣ X ) = i = 1 ∏ n p ( x i ∣ θ ) 这样我们的优化目标就是
θ M L E ∗ = arg max θ L ( θ ∣ X ) = arg max θ ∏ i = 1 n p ( x i ∣ θ ) = arg max θ log ∏ i = 1 n p ( x i ∣ θ ) = arg max θ ∑ i = 1 n log p ( x i ∣ θ ) \begin{aligned}
\theta_{MLE}^* &= \arg\max_{\theta} \mathcal{L}(\theta\mid X)\\
&= \arg\max_{\theta} \prod_{i=1}^n p(x_i\mid \theta)\\
&= \arg\max_{\theta} \log\prod_{i=1}^n p(x_i\mid \theta)\\
&=\arg\max_{\theta} \sum_{i=1}^n \log p(x_i\mid \theta)\\
\end{aligned} θ M L E ∗ = arg θ max L ( θ ∣ X ) = arg θ max i = 1 ∏ n p ( x i ∣ θ ) = arg θ max log i = 1 ∏ n p ( x i ∣ θ ) = arg θ max i = 1 ∑ n log p ( x i ∣ θ ) 即
θ M L E ∗ = arg max θ ∑ i = 1 n log p ( x i ∣ θ ) \theta_{MLE}^* = \arg\max_{\theta} \sum_{i=1}^n \log p(x_i\mid \theta) θ M L E ∗ = arg θ max i = 1 ∑ n log p ( x i ∣ θ ) KL divergence 用于衡量概率分布 Q ( x ) Q(x) Q ( x ) P ( x ) P(x) P ( x ) Q ( x ) Q(x) Q ( x ) P ( x ) P(x) P ( x )
连续概率分布的KL divergence的定义如下
D K L ( P ∣ ∣ Q ) = ∫ P ( x ) log ( P ( x ) Q ( x ) ) d x D_{KL}(P\mid\mid Q) =\int P(x)\log\left(\frac{P(x)}{Q(x)}\right)dx D K L ( P ∣∣ Q ) = ∫ P ( x ) log ( Q ( x ) P ( x ) ) d x 离散概率分布的KL divergence定义如下
D K L ( P ∣ ∣ Q ) = ∑ x P ( x ) log ( P ( x ) Q ( x ) ) D_{KL}(P\mid\mid Q) = \sum_{x} P(x)\log\left(\frac{P(x)}{Q(x)}\right) D K L ( P ∣∣ Q ) = x ∑ P ( x ) log ( Q ( x ) P ( x ) ) KL divergence有两个关键性质:
非负性:D K L ( P ∣ ∣ Q ) ≥ 0 D_{KL}(P\mid\mid Q)\geq0 D K L ( P ∣∣ Q ) ≥ 0 D K L ( P ∣ ∣ Q ) = 0 D_{KL}(P\mid\mid Q)=0 D K L ( P ∣∣ Q ) = 0 P ( x ) = Q ( x ) P(x)=Q(x) P ( x ) = Q ( x ) x x x
非对称性: 一般情况下,D K L ( P ∣ ∣ Q ) ≠ D K L ( Q ∣ ∣ P ) D_{KL}(P\mid\mid Q)\neq D_{KL}(Q\mid\mid P) D K L ( P ∣∣ Q ) = D K L ( Q ∣∣ P )
我们假设 p d a t a ( x ) p_{data}(x) p d a t a ( x ) X X X θ \theta θ p ( x ∣ θ ) p(x\mid \theta) p ( x ∣ θ ) p d a t a ( x ) p_{data}(x) p d a t a ( x )
θ K L = arg min θ D K L ( p d a t a ( x ) ∣ ∣ p ( x ∣ θ ) ) \theta_{KL} = \arg\min_{\theta}D_{KL}(p_{data}(x)\mid\mid p(x\mid \theta)) θ K L = arg θ min D K L ( p d a t a ( x ) ∣∣ p ( x ∣ θ )) 我们将上面的式子进行展开得到
θ K L ∗ = arg min θ D K L ( p d a t a ( x ) ∣ ∣ p ( x ∣ θ ) ) = arg min θ ∫ p d a t a ( x ) p d a t a ( x ) p ( x ∣ θ ) d x = arg min θ ∫ p d a t a ( x ) log p d a t a ( x ) d x − ∫ p d a t a ( x ) log p ( x ∣ θ ) d x = arg min θ − ∫ p d a t a ( x ) log p ( x ∣ θ ) d x = arg max θ ∫ p d a t a ( x ) log p ( x ∣ θ ) d x \begin{aligned}
\theta_{KL}^* &= \arg\min_{\theta}D_{KL}(p_{data}(x)\mid\mid p(x\mid \theta))\\
&= \arg\min_{\theta} \int p_{data}(x)\frac{p_{data}(x)}{p(x\mid \theta)} dx\\
&= \arg\min_{\theta}\int p_{data}(x)\log p_{data}(x) dx - \int p_{data}(x)\log p(x\mid \theta)dx \\
&= \arg\min_{\theta} - \int p_{data}(x)\log p(x\mid \theta)dx \\
&= \arg\max_{\theta} \int p_{data}(x)\log p(x\mid \theta)dx
\end{aligned} θ K L ∗ = arg θ min D K L ( p d a t a ( x ) ∣∣ p ( x ∣ θ )) = arg θ min ∫ p d a t a ( x ) p ( x ∣ θ ) p d a t a ( x ) d x = arg θ min ∫ p d a t a ( x ) log p d a t a ( x ) d x − ∫ p d a t a ( x ) log p ( x ∣ θ ) d x = arg θ min − ∫ p d a t a ( x ) log p ( x ∣ θ ) d x = arg θ max ∫ p d a t a ( x ) log p ( x ∣ θ ) d x 实际上,真实的数据分布 p d a t a ( x ) p_{data}(x) p d a t a ( x ) p d a t a ( x ) p_{data}(x) p d a t a ( x ) X = { x 1 , … , x n } ∼ p d a t a ( x ) X=\{x_1,\dots,x_n\}\sim p_{data}(x) X = { x 1 , … , x n } ∼ p d a t a ( x )
基于大数定律,我们有
1 n ∑ i = 1 n log p ( x i ∣ θ ) = E x ∼ p d a t a [ log p ( x ∣ θ ) ] = ∫ p d a t a ( x ) log p ( x ∣ θ ) d x , n → ∞ \frac{1}{n}\sum_{i=1}^n\log p(x_i\mid \theta)=\mathbb{E}_{x\sim p_{data}}[\log p(x\mid \theta)] = \int p_{data}(x)\log p(x\mid \theta)dx, n\to \infty n 1 i = 1 ∑ n log p ( x i ∣ θ ) = E x ∼ p d a t a [ log p ( x ∣ θ )] = ∫ p d a t a ( x ) log p ( x ∣ θ ) d x , n → ∞ 这样,最大似然估计就与最小化KL divergence构建起了联系:
θ M L E ∗ = arg max θ ∑ i = 1 n log p ( x i ∣ θ ) = arg max θ ∫ p d a t a ( x ) log p ( x ∣ θ ) d x = θ K L ∗ , n → ∞ . \begin{aligned}
\theta_{MLE}^*&=\arg\max_{\theta} \sum_{i=1}^n \log p(x_i\mid \theta)\\
&= \arg\max_{\theta} \int p_{data}(x)\log p(x\mid \theta)dx\\
&= \theta_{KL}^*, n\to\infty.
\end{aligned} θ M L E ∗ = arg θ max i = 1 ∑ n log p ( x i ∣ θ ) = arg θ max ∫ p d a t a ( x ) log p ( x ∣ θ ) d x = θ K L ∗ , n → ∞. 也就是说,当采样样本足够多的时候,最大似然估计和最小KL divergence是等价的。
我们简单推导一下 SigLip (Zhai et al., 2023 ) 中的损失函数与 cross entropy loss 之间的关系。
假设我们想要解决一个二分类问题,即标签 y ∈ { 0 , 1 } y\in\{0, 1\} y ∈ { 0 , 1 }
L ( x , y ) = − [ y log ( σ ( z ) ) + ( 1 − y ) log ( 1 − σ ( z ) ) ] \mathcal{L}(x, y) = -[y\log (\sigma(z)) + (1-y)\log (1-\sigma(z))] L ( x , y ) = − [ y log ( σ ( z )) + ( 1 − y ) log ( 1 − σ ( z ))] 这里 z = f θ ( x ) z=f_\theta(x) z = f θ ( x ) f θ f_\theta f θ σ ( ⋅ ) \sigma(\cdot) σ ( ⋅ )
σ ( z ) : = 1 1 + e − z \sigma(z) := \frac{1}{1 + e^{-z}} σ ( z ) := 1 + e − z 1 我们可以推导出关于 sigmoid function 的如下性质
σ ( − z ) = 1 1 + e z = e − z 1 + e − z = 1 − 1 1 + e − z = 1 − σ ( z ) \sigma(-z) = \frac{1}{1 + e^{z}} = \frac{e^{-z}}{1 + e^{-z}} = 1 - \frac{1}{1 + e^{-z}} = 1- \sigma(z) σ ( − z ) = 1 + e z 1 = 1 + e − z e − z = 1 − 1 + e − z 1 = 1 − σ ( z ) 接下来,我们把 σ ( − z ) = 1 − σ ( z ) \sigma(-z)=1-\sigma(z) σ ( − z ) = 1 − σ ( z )
L ( x , y ) = − [ y log ( σ ( z ) ) + ( 1 − y ) log ( σ ( − z ) ) ] \mathcal{L}(x, y) = -[y\log (\sigma(z)) + (1-y)\log (\sigma(-z))] L ( x , y ) = − [ y log ( σ ( z )) + ( 1 − y ) log ( σ ( − z ))] 注意到 y ∈ { 0 , 1 } y\in\{0, 1\} y ∈ { 0 , 1 }
L ( x , y ) = { − log ( σ ( − z ) ) , if y = 0 − log ( σ ( z ) ) , otherwise \mathcal{L}(x, y) = \begin{cases}
-\log (\sigma(-z)), &\text{ if } y=0\\
-\log (\sigma(z)), &\text{ otherwise}
\end{cases} L ( x , y ) = { − log ( σ ( − z )) , − log ( σ ( z )) , if y = 0 otherwise 注意到损失函数的结果非常相似,因此我们可以尝试使用统一的表达式来表达两种情况,也就是说,我们希望找到一个函数 g g g
L ( x , y ) = − log ( σ ( g ( y ) z ) ) \mathcal{L}(x, y) = -\log(\sigma(g(y)z)) L ( x , y ) = − log ( σ ( g ( y ) z )) 其中 g g g g ( 0 ) = − 1 g(0)=-1 g ( 0 ) = − 1 g ( 1 ) = 1 g(1)=1 g ( 1 ) = 1 g ( y ) = 2 y − 1 g(y)=2y-1 g ( y ) = 2 y − 1
L ( x , y ) = − log [ σ ( ( 2 y − 1 ) z ) ] \mathcal{L}(x, y) = -\log\left[\sigma((2y-1)z)\right] L ( x , y ) = − log [ σ (( 2 y − 1 ) z ) ] 我们再来回顾 SigLip 中的损失函数:
L ( { x , y } i = 1 N ) = − 1 N ∑ i = 1 N ∑ j = 1 N log 1 1 + exp [ z i j ( − t x i ⋅ y j + b ) ] \mathcal{L}(\{\bm{x}, \bm{y}\}_{i=1}^N)=-\frac{1}{N}\sum_{i=1}^N\sum_{j=1}^N\log \frac{1}{1+\exp\left[z_{ij}(-t\bm{x}_i\cdot \bm{y_j}+b)\right]} L ({ x , y } i = 1 N ) = − N 1 i = 1 ∑ N j = 1 ∑ N log 1 + exp [ z ij ( − t x i ⋅ y j + b ) ] 1 其中 t , b t, b t , b z i j = 1 z_{ij}=1 z ij = 1 i = j i=j i = j z i j = − 1 z_{ij}=-1 z ij = − 1
注意到 z i j = 2 I i = j − 1 z_{ij}=2\mathbb{I}_{i=j}-1 z ij = 2 I i = j − 1
Zhai, X., Mustafa, B., Kolesnikov, A., & Beyer, L. (2023). Sigmoid Loss for Language Image Pre-Training. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , 11941–11952. 10.1109/ICCV51070.2023.01100 softmax 函数用于将 K K K K K K e x e^x e x
s o f t m a x : R K → ( 0 , 1 ) K s o f t m a x ( z ) = [ e z 1 ∑ j = 1 K e z j , … , e z K ∑ j = 1 K e z j ] \begin{aligned}
\mathrm{softmax}:\mathbb{R}^K&\to (0,1)^K\\
\mathrm{softmax}(\mathbf{z}) &=\left[\frac{e^{z_1}}{\sum_{j=1}^Ke^{z_j}},\dots,\frac{e^{z_K}}{\sum_{j=1}^Ke^{z_j}}\right]
\end{aligned} softmax : R K softmax ( z ) → ( 0 , 1 ) K = [ ∑ j = 1 K e z j e z 1 , … , ∑ j = 1 K e z j e z K ] softmax 的第一个性质是 shift invariance, 即
s o f t m a x ( z + c ) = s o f t m a x ( z ) \mathrm{softmax}(\mathbf{z}+c) = \mathrm{softmax}(\mathbf{z}) softmax ( z + c ) = softmax ( z ) 证明比较容易:
s o f t m a x ( z + c ) i = e z i + c ∑ j = 1 K e z j + c = e c e z i e c ∑ j = 1 K e z j = e z i ∑ j = 1 K e z j = s o f t m a x ( z ) i , i = 1 , … , K \mathrm{softmax}(\mathbf{z}+c)_i = \frac{e^{z_i+c}}{\sum_{j=1}^Ke^{z_j+c}} = \frac{e^ce^{z_i}}{e^c\sum_{j=1}^Ke^{z_j}} = \frac{e^{z_i}}{\sum_{j=1}^Ke^{z_j}}=\mathrm{softmax}(\mathbf{z})_i,\ i=1,\dots,K softmax ( z + c ) i = ∑ j = 1 K e z j + c e z i + c = e c ∑ j = 1 K e z j e c e z i = ∑ j = 1 K e z j e z i = softmax ( z ) i , i = 1 , … , K 向量输入下 Softmax 函数的 Jacobian 矩阵推导
设输入为向量 z = [ z 1 , z 2 , … , z d ] ⊤ ∈ R d \mathbf{z} = [z_1, z_2, \dots, z_d]^\top \in \mathbb{R}^d z = [ z 1 , z 2 , … , z d ] ⊤ ∈ R d a = [ a 1 , a 2 , … , a d ] ⊤ ∈ R d \mathbf{a} = [a_1, a_2, \dots, a_d]^\top \in \mathbb{R}^d a = [ a 1 , a 2 , … , a d ] ⊤ ∈ R d
a j = softmax ( z ) j = e z j ∑ k = 1 d e z k a_j = \text{softmax}(\mathbf{z})_j = \frac{e^{z_j}}{\sum_{k=1}^d e^{z_k}} a j = softmax ( z ) j = ∑ k = 1 d e z k e z j 记分母(归一化因子)为 S = ∑ k = 1 d e z k S = \sum_{k=1}^d e^{z_k} S = ∑ k = 1 d e z k a j = e z j / S a_j = e^{z_j}/S a j = e z j / S
我们分两种情况计算 ∂ a j ∂ z k \frac{\partial a_j}{\partial z_k} ∂ z k ∂ a j
当 j = k j = k j = k a j a_j a j z j z_j z j
∂ a j ∂ z j = ∂ ∂ z j ( e z j S ) = e z j S − e z j e z j S 2 = e z j S ( 1 − e z j S ) = a j ( 1 − a j ) \frac{\partial a_j}{\partial z_j} = \frac{\partial}{\partial z_j} \left( \frac{e^{z_j}}{S} \right) = \frac{e^{z_j}S-e^{z_j}e^{z_j}}{S^2}=\frac{e^{z_j}}{S}\left(1-\frac{e^{z_j}}{S}\right)=a_j(1-a_j) ∂ z j ∂ a j = ∂ z j ∂ ( S e z j ) = S 2 e z j S − e z j e z j = S e z j ( 1 − S e z j ) = a j ( 1 − a j ) 当 j ≠ k j \neq k j = k a j a_j a j z k z_k z k
∂ a j ∂ z k = ∂ ∂ z k ( e z j S ) = 0 ⋅ S − e z j e z k S 2 = − e z j e z k S = − a j a j \frac{\partial a_j}{\partial z_k} = \frac{\partial}{\partial z_k} \left( \frac{e^{z_j}}{S} \right) = \frac{0\cdot S-e^{z_j}e^{z_k}}{S^2}=-\frac{e^{z_j}e^{z_k}}{S}=-a_ja_j ∂ z k ∂ a j = ∂ z k ∂ ( S e z j ) = S 2 0 ⋅ S − e z j e z k = − S e z j e z k = − a j a j 综合以上两种情况,Jacobian 矩阵 J \mathbf{J} J
J = diag ( a ) − a a ⊤ \mathbf{J} = \text{diag}(\mathbf{a}) - \mathbf{a} \mathbf{a}^\top J = diag ( a ) − a a ⊤ softmax 是 argmax 的 smooth approximation, 所以实际上 softmax 指的是 “soft argmax”. 为了证明这一点,我们首先定义如下函数
s o f t m a x ( z ; τ ) = s o f t m a x ( z / τ ) = [ e z 1 / τ ∑ j = 1 K e z j / τ , … , e z K / τ ∑ j = 1 K e z j / τ ] \mathrm{softmax}(\mathbf{z};\tau) =\mathrm{softmax}(\mathbf{z}/\tau)=\left[\frac{e^{z_1/\tau}}{\sum_{j=1}^Ke^{z_j/\tau}},\dots,\frac{e^{z_K/\tau}}{\sum_{j=1}^Ke^{z_j/\tau}}\right] softmax ( z ; τ ) = softmax ( z / τ ) = [ ∑ j = 1 K e z j / τ e z 1 / τ , … , ∑ j = 1 K e z j / τ e z K / τ ] 易知, s o f t m a x ( z ) = s o f t m a x ( z ; 1 ) \mathrm{softmax}(\mathbf{z})=\mathrm{softmax}(\mathbf{z};1) softmax ( z ) = softmax ( z ; 1 ) s o f t m a x \mathrm{softmax} softmax
我们定义 smooth approximation 为
Definition
如果 lim τ → 0 + s o f t m a x ( z ; τ ) = 1 arg max ( z ) \lim_{\tau\to0^+}\mathrm{softmax}(\mathbf{z};\tau)=\mathbb{1}_{\arg\max(\mathbf{z})} lim τ → 0 + softmax ( z ; τ ) = 1 a r g m a x ( z ) s o f t m a x ( ⋅ ; τ ) \mathrm{softmax}(\cdot;\tau) softmax ( ⋅ ; τ ) arg max \arg\max arg max s o f t m a x ( ⋅ ) \mathrm{softmax}(\cdot) softmax ( ⋅ ) arg max \arg\max arg max arg max ( z ) = arg max k z k \arg\max(\mathbf{z})=\arg\max_k z_k arg max ( z ) = arg max k z k 1 ∈ { 0 , 1 } K \mathbb{1}\in\{0,1\}^K 1 ∈ { 0 , 1 } K 1 arg max ( z ) [ i ] = 1 \mathbb{1}_{\arg\max(\mathbf{z})}[i]=1 1 a r g m a x ( z ) [ i ] = 1 z i = max j z j z_i=\max_jz_j z i = max j z j
我们下面来进行证明。我们不妨假设最大值唯一,其 index 为 m m m z m = max i z i z_m = \max_i z_i z m = max i z i
s o f t m a x ( z ; τ ) = s o f t m a x ( z − z m ; τ ) = [ e ( z 1 − z m ) / τ ∑ j = 1 K e ( z j − z m ) / τ , … , e ( z K − z m ) / τ ∑ j = 1 K e ( z j − z m ) / τ ] \mathrm{softmax}(\mathbf{z};\tau) = \mathrm{softmax}(\mathbf{z}-z_m;\tau) =\left[\frac{e^{(z_1-z_m)/\tau}}{\sum_{j=1}^Ke^{(z_j-z_m)/\tau}},\dots,\frac{e^{(z_K-z_m)/\tau}}{\sum_{j=1}^Ke^{(z_j-z_m)/\tau}}\right] softmax ( z ; τ ) = softmax ( z − z m ; τ ) = [ ∑ j = 1 K e ( z j − z m ) / τ e ( z 1 − z m ) / τ , … , ∑ j = 1 K e ( z j − z m ) / τ e ( z K − z m ) / τ ] 此时,我们有
lim τ → 0 + s o f t m a x ( z ; τ ) i = { 1 , if i = m 0 , otherwise \lim_{\tau\to0^+}\mathrm{softmax}(\mathbf{z};\tau)_i = \begin{cases}
1, &\text{if }i = m\\
0, &\text{otherwise}
\end{cases} τ → 0 + lim softmax ( z ; τ ) i = { 1 , 0 , if i = m otherwise 当最大值不唯一的时候,我们记 I = { i ∈ [ K ] ∣ z i = max j z j } \mathcal{I} = \{i\in[K]\mid z_i=\max_j z_j\} I = { i ∈ [ K ] ∣ z i = max j z j } s o f t m a x ( ⋅ ; τ ) \mathrm{softmax}(\cdot;\tau) softmax ( ⋅ ; τ )
lim τ → 0 + s o f t m a x ( z ; τ ) i = { 1 / ∣ I ∣ , if i ∈ I 0 , otherwise \lim_{\tau\to0^+}\mathrm{softmax}(\mathbf{z};\tau)_i = \begin{cases}
1/|\mathcal{I}|, &\text{if }i \in \mathcal{I}\\
0, &\text{otherwise}
\end{cases} τ → 0 + lim softmax ( z ; τ ) i = { 1/∣ I ∣ , 0 , if i ∈ I otherwise 因此,我们就证明了 softmax 是 argmax 函数的 smooth approximation.
我们前面介绍了 s o f t m a x ( z ; τ ) \mathrm{softmax}(\mathbf{z};\tau) softmax ( z ; τ ) τ \tau τ T T T T T T
我们前面已经证明了后者,现在我们来证明一下前者,证明思路也很简单,T → + ∞ T\to+\infty T → + ∞ e x / T → 1 e^{x/T}\to 1 e x / T → 1
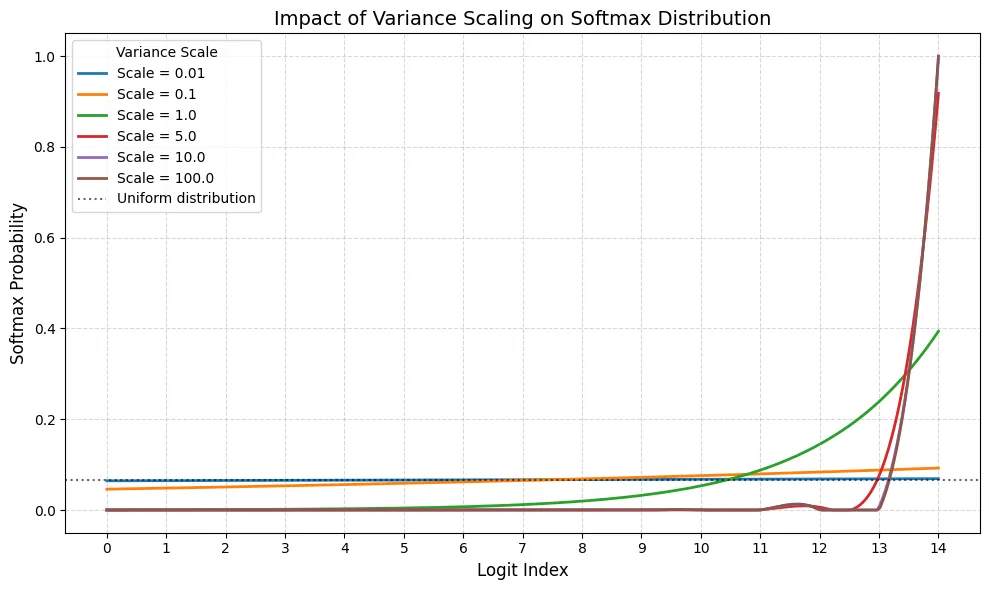
lim τ → + ∞ s o f t m a x ( z ; τ ) i = 1 K , i = 1 , … , K \lim_{\tau\to+\infty}\mathrm{softmax}(\mathbf{z};\tau)_i =\frac1K,\ i=1,\dots,K τ → + ∞ lim softmax ( z ; τ ) i = K 1 , i = 1 , … , K 下面是可视化的代码以及结果
Impact of temperature on softmax import numpy as np import matplotlib.pyplot as plt from scipy.interpolate import make_interp_spline def softmax (x): e_x = np.exp(x - np.max(x)) return e_x / e_x.sum() num_elements = 15 indices = np.arange(num_elements) logits = np.linspace( - 3.5 , 3.5 , num_elements) scales = [ 0.01 , 0.1 , 1.0 , 5.0 , 10.0 , 100.0 ] plt.figure( figsize = ( 10 , 6 )) for s in scales: probs = softmax(logits * s) x_smooth = np.linspace(indices.min(), indices.max(), 300 ) spl = make_interp_spline(indices, probs, k = 3 ) y_smooth = np.clip(spl(x_smooth), 0 , None ) # Clip to ensure no negative artifacts plt.plot(x_smooth, y_smooth, label = f 'Scale = { s } ' , linewidth = 2 ) uniform_prob = 1.0 / len (indices) plt.axhline( y = uniform_prob, color = 'black' , linestyle = ':' , alpha = 0.6 , label = f 'Uniform distribution' ) plt.xticks(indices) plt.xlabel( 'Logit Index' , fontsize = 12 ) plt.ylabel( 'Softmax Probability' , fontsize = 12 ) plt.title( 'Impact of Variance Scaling on Softmax Distribution' , fontsize = 14 ) plt.legend( title = "Variance Scale" ) plt.grid( True , linestyle = '--' , alpha = 0.5 ) plt.tight_layout() plt.show()
可以看到,当 variance 比较小的时候,输出的分布接近于均匀分布,而 variance 越大,输出的分布越接近 One-hot 分布。
在 attention 的计算过程中,我们也有 softmax 函数,为了在 softmax 过程中避免 variance 的影响,现在会在计算 softmax 之前加入 normalization layer 来提前进行归一化。见 QK-norm .
由于 e x e^x e x
l o g s u m e x p ( z ) = log ( ∑ i = 1 K e z i ) \mathrm{logsumexp}(\mathbf{z}) = \log \left(\sum_{i=1}^K e^{z_i}\right) logsumexp ( z ) = log ( i = 1 ∑ K e z i ) softmax 函数与 logsumexp 函数的关系如下
s o f t m a x ( z ) = exp log ( e z ∑ j = 1 K e z j ) = exp ( z − log ( ∑ i = 1 K e z i ) ) = exp ( z − l o g s u m e x p ( z ) ) \begin{aligned}
\mathrm{softmax}(\mathbf{z}) &=\exp\log\left(\frac{e^{\mathbf{z}}}{\sum_{j=1}^Ke^{z_j}}\right)\\
&= \exp\left(\mathbf{z} - \log\left(\sum_{i=1}^K e^{z_i}\right)\right)\\
&= \exp(\mathbf{z} - \mathrm{logsumexp}(\mathbf{z}))
\end{aligned} softmax ( z ) = exp log ( ∑ j = 1 K e z j e z ) = exp ( z − log ( i = 1 ∑ K e z i ) ) = exp ( z − logsumexp ( z )) 考虑前面提到的 e x e^x e x
s o f t m a x ( z ) = s o f t m a x ( z − c ) = exp ( ( z − c ) − l o g s u m e x p ( z − c ) ) \mathrm{softmax}(\mathbf{z}) = \mathrm{softmax}(\mathbf{z}-c) = \exp((\mathbf{z}-c) - \mathrm{logsumexp}(\mathbf{z}-c)) softmax ( z ) = softmax ( z − c ) = exp (( z − c ) − logsumexp ( z − c )) 这里我们使用了前面推导出来的 shift invariance 性质。对应的代码实现如下:
def softmax (x: torch.Tensor, dim: int = - 1 ) -> torch.Tensor: x = x - x.max( dim = dim, keepdim = True ).values log_sum_exp = torch.log(torch.sum(torch.exp(x), dim = dim, keepdim = True )) return torch.exp(x - log_sum_exp) TODO
注意到我们在计算 softmax 时,需要加载 z \mathbf{z} z z \mathbf{z} z (Rabe & Staats, 2021 ) 算法,后续 flash attention (Dao et al., 2022 ) 应用了 online softmax 算法来减少 attention 计算时内存访问开销。
我们介绍两种 online softmax 思路,一个是 element-wise online-softmax, 另一个是 block-wise online-softmax
假设当前遍历到第 k k k
当前最大值 m k = max ( x 1 , … , x k ) m_k = \max(x_1,\dots,x_k) m k = max ( x 1 , … , x k )
部分分母 d k = ∑ j = 1 k exp ( x j − m k ) d_k = \sum_{j=1}^k\exp(x_j-m_k) d k = ∑ j = 1 k exp ( x j − m k )
加入新元素 x k + 1 x_{k+1} x k + 1
如果 x k + 1 < m k x_{k+1}<m_k x k + 1 < m k d k + 1 = d k + exp ( x k + 1 − m k ) d_{k+1}=d_k+\exp(x_{k+1}-m_k) d k + 1 = d k + exp ( x k + 1 − m k )
如果 x k + 1 > m k x_{k+1}>m_k x k + 1 > m k
m k + 1 = x k + 1 m_{k+1}=x_{k+1} m k + 1 = x k + 1 旧分母需要乘以 exp ( m k − m k + 1 ) \exp(m_k-m_{k+1}) exp ( m k − m k + 1 ) d k + 1 = d k exp ( m k − m k + 1 ) + exp ( m k + 1 − m k + 1 ) d_{k+1}=d_k\exp(m_k-m_{k+1}) + \exp(m_{k+1}-m_{k+1}) d k + 1 = d k exp ( m k − m k + 1 ) + exp ( m k + 1 − m k + 1 )
算法形式为:
Algorithm: Element-wise online softmax Input : [ x 1 , … , x N ] ∈ R N [x_1,\dots,x_N]\in\mathbb{R}^N [ x 1 , … , x N ] ∈ R N
Initialization : m = − ∞ , d = 0 m=-\infty, d=0 m = − ∞ , d = 0
For k = 1 , … , N k=1,\dots,N k = 1 , … , N
If x k < m x_{k}<m x k < m
d = d + exp ( x k − m ) d = d + \exp(x_{k}-m) d = d + exp ( x k − m )
Else
d = d exp ( m − x k ) + 1 d=d\exp(m-x_k) + 1 d = d exp ( m − x k ) + 1 m = x k m=x_{k} m = x k
For k = 1 , … , N k=1,\dots,N k = 1 , … , N
O i = exp ( x k − m ) / d O_i = \exp(x_k-m)/d O i = exp ( x k − m ) / d Return O O O
代码
Element-wise online softmax import numpy as np def online_softmax (x): m = - np.inf d = 0.0 for val in x: if val > m: d = d * np.exp(m - val) + 1.0 m = val else : d += np.exp(val - m) # compute result = [] for val in x: result.append(np.exp(val - m) / d) return np.array(result) x = np.array([ 1 , 2 , 3 , 4 , 5 ]) softmax_online = online_softmax(x) softmax_std = np.exp(x - np.max(x)) / np.sum(np.exp(x - np.max(x))) print ( "Max difference:" , np.max(np.abs(softmax_online - softmax_std)))
假设我们的输入被分为若干个 block, 即 z = [ z 1 ; … , z n ] ∈ R K \mathbf{z}=[\mathbf{z}^1;\dots,\mathbf{z}^n]\in\mathbb{R}^K z = [ z 1 ; … , z n ] ∈ R K z i ∈ R K / n \mathbf{z}^i\in\mathbb{R}^{K/n} z i ∈ R K / n K m o d n = 0 K\mod n=0 K mod n = 0
对于 z ∈ R K \mathbf{z}\in\mathbb{R}^K z ∈ R K
m ( z ) = max i z i , f ( z ) = [ e z 1 − m ( z ) , … , e z K − m ( z ) ] , ℓ ( z ) = ∑ i f ( z ) i , s o f t m a x ( z ) = f ( z ) ℓ ( z ) m(\mathbf{z}) = \max_i z_i,\ f(\mathbf{z}) = [e^{z_1-m(\mathbf{z})},\dots,e^{z_K-m(\mathbf{z})}], \ \ell(\mathbf{z})=\sum_if(z)_i, \ \mathrm{softmax}(\mathbf{z}) = \frac{f(\mathbf{z})}{\ell(\mathbf{z})} m ( z ) = i max z i , f ( z ) = [ e z 1 − m ( z ) , … , e z K − m ( z ) ] , ℓ ( z ) = i ∑ f ( z ) i , softmax ( z ) = ℓ ( z ) f ( z ) 对于 z = [ z 1 ; … , z n ] ∈ R K \mathbf{z}=[\mathbf{z}^1;\dots,\mathbf{z}^n]\in\mathbb{R}^K z = [ z 1 ; … , z n ] ∈ R K
m i ( z ) = max ( [ z 1 ; … ; z i ] ) = max ( m i − 1 ( z ) , m ( z i ) ) ℓ i ( z ) = ∑ j = 1 i f ( z j ) = exp ( m i − 1 ( z ) − m i ( z ) ) ℓ ( z i − 1 ) + exp ( z i − m i ( z ) ) \begin{aligned}
m_i(\mathbf{z}) &= \max([\mathbf{z}^1;\dots;\mathbf{z}^i]) = \max(m_{i-1}(\mathbf{z}),m(\mathbf{z}^i))\\
\ell_i(\mathbf{z}) &= \sum_{j=1}^if(\mathbf{z}^j) = \exp(m_{i-1}(\mathbf{z}) - m_i(\mathbf{z}))\ell(\mathbf{z}^{i-1}) + \exp(\mathbf{z}^i-m_i(\mathbf{z}))
\end{aligned} m i ( z ) ℓ i ( z ) = max ([ z 1 ; … ; z i ]) = max ( m i − 1 ( z ) , m ( z i )) = j = 1 ∑ i f ( z j ) = exp ( m i − 1 ( z ) − m i ( z )) ℓ ( z i − 1 ) + exp ( z i − m i ( z )) 因此,如果我们额外记录 m ( x ) m(x) m ( x ) ℓ ( x ) \ell(x) ℓ ( x ) m i ( z ) m_i(\mathbf{z}) m i ( z ) ℓ i ( z ) \ell_i(\mathbf{z}) ℓ i ( z )
Block-wise online softmax import numpy as np def online_softmax (x, block_size = 2 ): n = len (x) num_blocks = (n + block_size - 1 ) // block_size global_max = - np.inf global_d = 0.0 blocks = [] for i in range (num_blocks): start = i * block_size end = min (start + block_size, n) block = x[start: end] blocks.append(block) local_max = np.max(block) local_d = np.sum(np.exp(block - local_max)) if local_max > global_max: global_d = global_d * np.exp(global_max - local_max) + local_d global_max = local_max else : global_d += local_d * np.exp(local_max - global_max) # compute result = np.zeros(n) idx = 0 for block in blocks: block_probs = np.exp(block - global_max) / global_d result[idx: idx + len (block)] = block_probs idx += len (block) return result
优势:
数值稳定:局部缩放,再对齐全局
内存高效:可以流式处理,不必存储全量数据
并行:不同块可以并行计算,最后合并
时间复杂度 O ( n ) O(n) O ( n )
References
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Re, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In A. H. Oh, A. Agarwal, D. Belgrave, & K. Cho (Eds.), Advances in Neural Information Processing Systems . https://openreview.net/forum?id=H4DqfPSibmx Rabe, M. N., & Staats, C. (2021). Self-attention does not need O (n 2) memory. arXiv Preprint arXiv:2112.05682 . https://arxiv.org/pdf/2112.05682 首先我们给出估计 (estimator) 的概念:
给定一个随机变量 X ∼ p X\sim p X ∼ p x 1 , … , x n ∼ p x_1,\dots,x_n\sim p x 1 , … , x n ∼ p X X X x 1 , … , x n x_1,\dots,x_n x 1 , … , x n X X X u ( x 1 , … , x n ) u(x_1,\dots,x_n) u ( x 1 , … , x n )
u ( x 1 , … , x n ) = 1 n x i u(x_1,\dots,x_n) = \frac{1}{n}x_i u ( x 1 , … , x n ) = n 1 x i 来估计均值 E [ X ] \mathbb{E}[X] E [ X ]
注意到,我们的估计 u u u x 1 , … , x n x_1,\dots,x_n x 1 , … , x n x 1 , … , x n x_1,\dots,x_n x 1 , … , x n u ( X 1 , … , X n ) u(X_1,\dots,X_n) u ( X 1 , … , X n )
Definition: Unbiased Estimator 如果说
E [ u ( X 1 , … , X n ) ] = X \mathbb{E}[u(X_1,\dots,X_n)]=X E [ u ( X 1 , … , X n )] = X 则我们说 u ( X 1 , … , X n ) u(X_1,\dots,X_n) u ( X 1 , … , X n ) X X X
TODO