Adam
Adam 是一个针对高维参数空间的一阶优化器,Adam 基于 gradient 的一阶和二阶信息为不同的参数安排不同的学习率。 Adam 的来源是 adaptive moment estimation. Adam 主要是结合了 AdaGrad 和 RMSProp 两个算法的优点。
Adam 与 RMSProp 的区别在于:
- RMSProp 在 rescaled gradient 上进行 momentum 的计算然后更新,而 Adam 直接使用一阶和二阶矩来进行估计
- RMSProp 没有 bias-correction 项
Adam 的主要优势为:
- 参数更新的量级与 gradient 的 scaling 无关
- 步长被 stepsize 超参数限制
- 不要求目标函数 stationary
- 对于稀疏梯度 work 的比较好
- 优化器自带 annealing
Algorithm
Adam 的算法如下图所示

我们优化的目标函数如下
这里 一般是一个神经网络。我们记 在 处的梯度为 .
算法运行时,会更新梯度 以及梯度二阶矩 的 exponential moving average. 超参数 负责控制 exponential decay rates. 这里 和 分别是一阶动量(均值)和二阶动量(未中心化的 variance)的估计。由于 和 的初始化都是 0, 因此他们会引入 bias, 作者在后续通过修正解决了这个问题。
假设 , 如果除了当前时刻 之外,之前所有时刻的梯度 , 此时
修正后的一阶和二阶矩分别为
当 足够大的时候, , 此时
如果之前所有时刻的梯度不全为 0, 则依据 Cauchy-Schwarz 不等式,我们有 . 令 , , 则我们有
此时,我们有
因此,
从而我们有
实际上, 可以理解为一个 trust region, 可以用来保证当前更新的参数不会离原始参数太远。
作者定义 signal-noise ratio (SNR) 为
当 SNR 较小时,说明此时的不确定性比较大,因此 也比较小。这就避免了模型朝错误的方向更新。也就是automatic annealing.
还对 gradient 的 scaling 有不变的性质,这是因为,
Bias Correction
上一节提到,Adam 算法的初始化是存在 bias 的,作者在本届就对齐进行了分析。令 为目标函数 的梯度,我们希望估计其二阶动量的期望.令 分别为 处的梯度估计,其中 是对应时刻梯度的分布。令 , 在 时刻,我们有
我们希望计算 与 之间的关系,我们有
其中当 为 stationary 时,, 否则我们可以通过控制 来让 past gradient 保持在一个较小的规模。最后,我们剩下的就是 , 这也是我们在算法中进行修正的地方。
对于一阶动量 的修正也是同理。
Convergence Analysis
作者在本节中使用了 online learning framework 来分写 Adam 的收敛性。给定一系列 convex cost function . 在 时刻,我们的目标是基于上一个 cost function 来预测 .
作者在这里使用 regret 来分析,记 为 时刻最优的参数对应的 cost function, regret 定义为
其中,
则我们有如下的结论
Theorem 1 假设
- 函数 的梯度是有界的,即 , 对任意 都成立
- 中任意两个参数的距离都是有界的,即 , 对任意 都成立
- 满足 令 , , , 则我们有
结果说明,当我们的 data feature 稀疏且梯度有界时我们有
以及
实际上,对于 Adam 以及 Adamgrad,这个上界可以优化到 .
最终,我们可以证明 Adam 的收敛性
Corollary 1 假设
- 函数 的梯度是有界的,即 , 对任意 都成立
- 中任意两个参数的距离都是有界的,即 , 对任意 都成立 则对 , 我们有
Experiment
作者在 logistic regression, MLP, CNN 等三种模型架构上进行了实验。
Conclusion
作者在本文中提出了 Adam optimizer, 一个基于 AdaGrad 和 RMSProp 优点的优化器,作者通过理论验证了 Adam 的收敛性,然后通过实验验证了 Adam 的有效性。
作者提出了一个针对 Adam 优化器的 weight decay 方法
Introduction
作者首先回顾了动态梯度算法如 AdaGrad, RMSProp, Adam 的进展。已有工作表明动态梯度算法的泛化性要比 SGD with momentum 要差。作者在本文中探究了在 SGD 和 Adam 中使用 L2 regularization 和 weight decay 对最终模型表现的影响。结果表明,模型泛化性较差的原因在于对于 Adam, L2 regularization 的效果要比 SGD 差。
作者有如下发现:
- L2 regularization 和 weight decay 不等价。在 SGD 中,L2 regularization 是等价的,但是在 Adam 中这个结论不成立。具体来说,L2 regularization 对历史参数的惩罚要小于 weight decay
- L2 regularization 对 Adam 效果提升有效
- weight decay 对于 SGD 和 AdamW 都很有效,在 SGD 中,weight decay 与 L2 regularization 等价
- 最优的 weight decay 取决于 batch, batch 越大,最优的 weight decay 越小
- 通过 learning rate scheduler 可以进一步提高 Adam 的表现
作者在本文中的主要贡献是通过解耦梯度更新中的 weight decay 来提高 Adam 的 regularization.
作者的主要 motivation 是提升 Adam 表现,让其可以和 SGD with momentum 相比
Method
Weight decay 的定义如下
其中 是 weight decay rate, 是第 个 batch 的梯度, 是学习率。
首先,对于标准的 SGD 来说,weight decay 与 L2 regularization 等价
Proposition 1 对于标准的 SGD 来说,对损失函数 执行 weight decay (公式 )与对损失函数 执行梯度下降算法是等价的,这里 。
证明比较简单,只需要写出损失函数的梯度下降更新公式即可。
基于这个结论,大部分优化算法都将 L2 regularization 和 weight decay 看做是等价的。但实际上,这个结论对于 adaptive gradient 方法来说是不成立的。结论如下
Proposition 2 令 为一个 optimizer, 其目标函数为 , 当不考虑 weight decay 时,梯度更新过程为 . 当考虑 weight decay 时,梯度更新过程为 . 如果 , 则不存在 , 使得 在优化目标函数 时,不考虑 weight decay 的梯度更新与 在优化目标函数 时,考虑 weight decay 的梯度更新等价。
证明比较简单,只需要写出两个目标函数对应的梯度更新公式即可。
作者通过分析发现,在 adaptive gradient 方法中,对于 L2 regularization,梯度和 regularization 是打包在一起考虑的。而 weight decay 是分开考虑的。这就导致了对于梯度比较大的权重,L2 regularization 的学习率较小,从而 regularization 效应减弱。而 weight decay 中,这种效应则不存在。因此 weight decay 的 regularization 效应更强。
作者通过这个分析,给出了一个 weight decay 与 L2 regularization 相等的条件
Proposition 3 令 为一个 optimizer, 其目标函数为 , 当不考虑 weight decay 时,梯度更新过程为 . 当考虑 weight decay 时,梯度更新过程为 . 如果 (), 则 在优化目标函数
时,不考虑 weight decay 的梯度更新与 在优化目标函数 时,考虑 weight decay 的梯度更新等价。
上面的结论显示,对于比较大的 preconditioner , 其在相比于 L2 regularization 被 regularized 的效应更强。
为了解耦这两个参数,作者提出了 SGDW 算法,其 weight decay 和梯度更新同时进行,算法如下图所示

在算法中,为了支持同时给 和 做 scheduling, 作者提出了一个 scaling factor , 由用户定义的 scheduler SetScheduleMultiplier(t) 决定。此时,针对 SGD with momentum 的 weight decay 与 L2 regularization 是等价的
同理,我们也可以对 Adam 算法实行同样的操作,算法如下图所示

Conclusion
作者在本文中分析了 adaptive gradient 方法中 L2 regularization 与 weight decay 的不一致性。基于分析,作者提出了 SGDW 和 AdamW 两个优化算法。
Muon (MomentUm Orthogonalized by Newton-Schulz) 是一个针对二维神经网络的优化器,它基于 SGD-momentum 改进,增加了一个 Newton-Schulz 的后处理步骤
Method
Newton-Schulz (NS) 的目的是用一个正交矩阵近似一个给定矩阵,即
也就是说,NS iteration 将 SDG-moment 的更新矩阵替换为了“最近的” semi-orthogonal matrix. 这等价于将更新矩阵替换为 , 其中 是更新矩阵的 SVD 分解。
[!tip] 作者观察到,对于 SGD-momentum 和 Adam 来说,其在基于 transformer 的神经网络里有非常高的 condition number, 也就是 optimizer 仅在少数几个方向上进行优化。作者认为,通过正交化,可以有效提高模型在其他方向上的更新速度,进而提高模型表现
Newton-Schulz
作者提到,正交化矩阵的方法有很多,比如 SVD 分解,但是其问题是非常慢,还有 Coupled Newton iteration, 但是其精度要求非常高,必须要在 float32 以上。
作者因此使用了 Newton-Schulz iteration.
令 是 SGD-momentum 更新矩阵的 SVD 分解,则基于系数 的 NS iteration 定义如下:
也就是说,如果我们定义五次多项式函数 , 然后执行 次 NS iteration, 则我们得到 , 其中 代表 复合 次。
为了保证 NS iteration 收敛到 , 我们必须保证两点:
- 的值,也就是 的奇异值必须在区间 上
- 必须满足 , , .
为了满足第一个条件,我们可以对 进行 rescale, 即 , rescale 不影响最终的结果,即 .
对于 , 我们有很多选择,比如我们定义 就得到如下结果
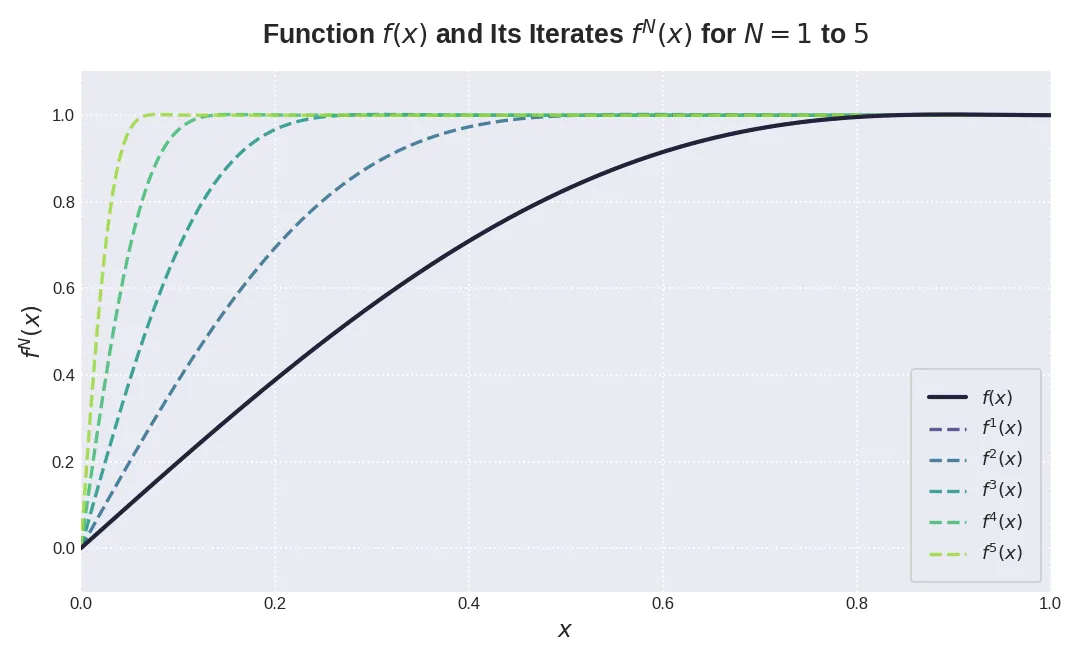
Coefficient Optimization
尽管 已经满足了第二个条件,但是我们还是想进一步优化,优化的方向主要有两个:
- 让 尽可能大,这是因为 控制了较小奇异值的收敛速率。
- 对于所有的 , 我们希望 , . 这样 NS iteration 的结果与 不会相差太远。
作者发现, 可以设置为 而不影响 Muon optimizer 的收敛性。因此,作者的目标现在是
作者通过 ad-hoc gradient 方法求解得到一组数值解为 , 作者将这组数值应用于 Muon optimizer 中。迭代结果如下图,可以看到,当 时,函数变得更加陡峭。
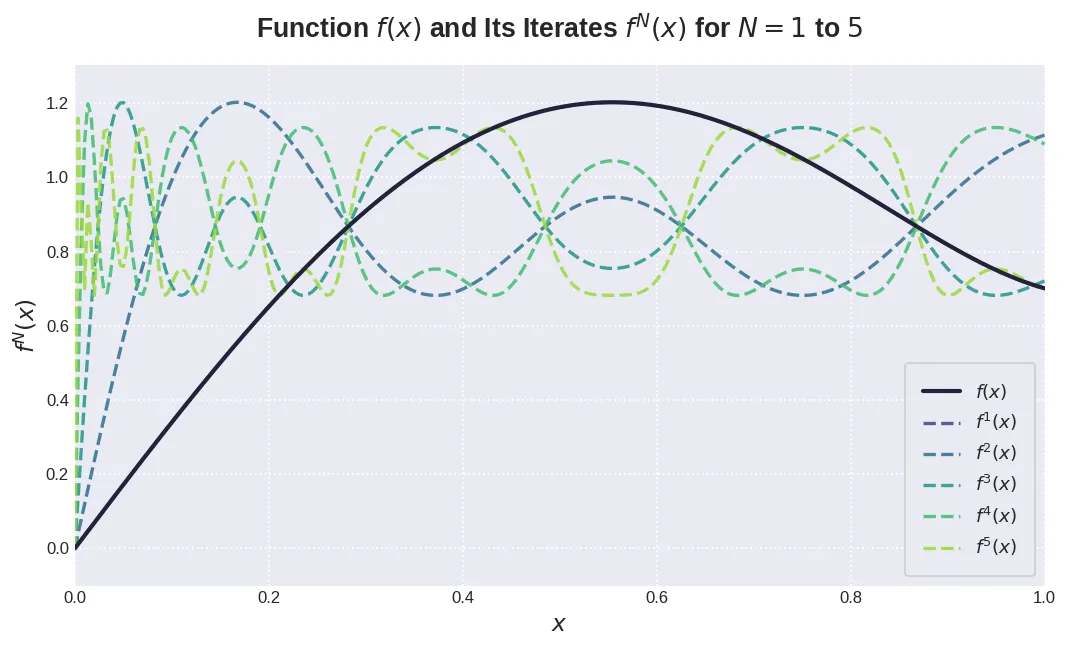
实验中,作者发现,仅需迭代五次,最终的结果就 work 的很好。作者还尝试了不同的多项式,结果发现并没有太大的提升。
Algorithm
最终,Muon Optimizer 的算法如下

其中, NewtonSchulz5 算法伪代码定义如下
def newtonschulz5(G, steps=5, eps=1e-7):
assert G.ndim=2
a, b, c = (3.4445, -4.7750, 2.0315)
X = G.bfloat16()
X /= (X.norm() + eps)
if G.size(0) > G.size(1):
X = X.T
for _ in range(steps):
A = X @ X.T
B = b * A + c * A @ A
X = a * X + B @ X
if G.size(0) > G.size(1):
X = X.T
return X
Analysis
本节作者分析了以下 Muon 的内存占用和算力开销。
在 NS iteration 之前,Muon optimizer 和 SGD-moment 是一样的。
对于 的矩阵(假设 ), 首先 NS iteration 会进行转置,NS iteration 的每一步需要 FLOPs, 其中括号前面的系数 代表精度。因此,Muon 相比于 SGD momentum 需要的额外 FLOPs 为 , 其中 是迭代次数。
使用 baseline 进行一次训练(前向 + 后向),所需要的 FLOPS 为 , 其中 是 batch size. 因此,Muon 的 FLOP 开销至多为 , 其中 是模型的 hidden size, 是 batch size, 是 NS iteration 的步数。
作者分别基于 nanoGPT 和 LLaMA-405B 进行验证,结果发现,Muon optimizer 带来的额外开销不足 .
作者发信啊,使用 Nesterov-style momentum 可以比普通的 SGD-momentum 效果更好,因此作者在 muon 中使用了前者。
作者还发现,对于 QKV layer,分别进行优化效果会更好。
Experiments
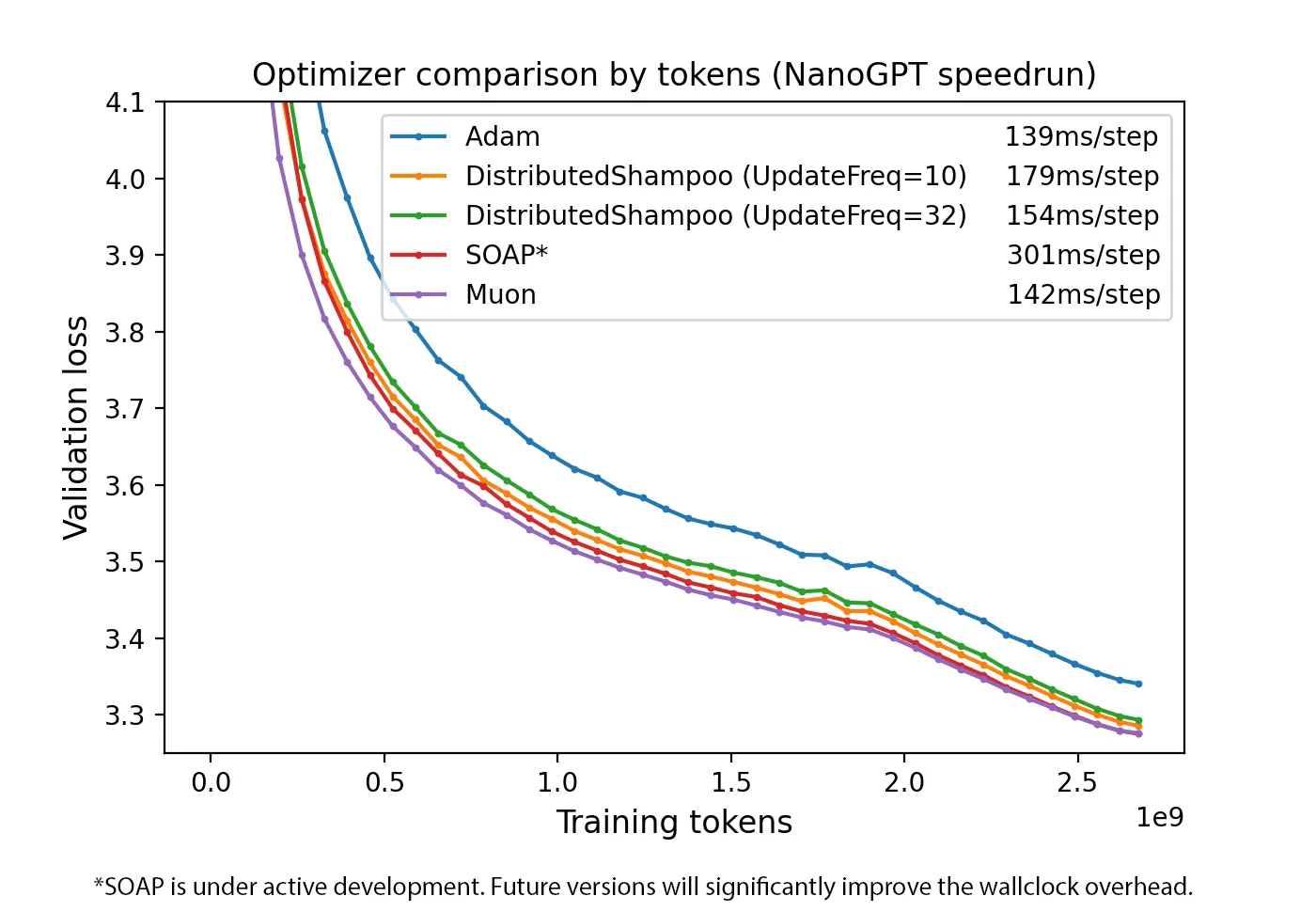
Limitation and Future Work
Muon 仅被设计用于优化 2D 参数(因为涉及矩阵计算),其余的参数仍然需要 AdamW 等优化器参与。
作者认为未来的工作有:
- 能否 scale up Muon Optimizer
- 分布式优化
- 在 fine-tuning 和 RL 阶段使用 Muon Optimizer
Conclusion
作者提出了 Muon optimizer,该优化器在 nanoGPT speedrun 上取得了 SOTA 的结果,作者详细介绍了优化器的工作原理。
Moonlight
Kimi 提出了 Moonlight, 一个基于 Muon optimizer 训练得到的 16B-A3B MoE LLM. 作者详细介绍了如何 scale up muon optimizer.
Introduction
Muon 验证了 Muon optimizer 在小语言模型 nanoGPT 上的表现,但是对于更大规模 LLM 的表现,尚未有人探究。因此 Kimi 就希望在大规模 LLM 上验证 Muon optimizer 的表现。作者主要进行了两点改进:
- 加入 weight decay
- 调整了不同参数更新的 scale
基于改进后的 Muon optimizer, 其训练效率相比于 AdamW 提升了 2 倍。作者基于 Muon Optimizer 训练得到了 Moonlight, 一个 16B-A3B 的 MoE LLM.
作者主要作出了三点贡献:
- 探究了 weight decay 在 scaling Muon 时的作用
- 分布式 Muon optimizer 的实现
- 验证了 Muon optimizer 的 scaling law
Method
Background
作者首先介绍了一下 Muon optimizer, 给定步数 , 参数矩阵 , momentum , 学习率 以及目标函数 , Muon optimizer 的更新方式如下:
这里 是 gradient 的 momentum, 初始化为 . 在上面的更新公式中,Newton-Schulz 的作用是求解 . 令 为 SVD 分解, 我们有
这是一个半正交矩阵,即 .
Newton-Schulz 迭代的具体公式如下:
其中,normalization 是为了保证 Newton-Schulz 的收敛性。 是三个超参数,在 Muon 中设置为 .
Scaling up Muon
作者发现,尽管 Muon 在小规模场景下 work 的很好,但是大规模性场景下的收益就非常有限了。作者发现,这是因为模型的参数以及每一层输出的 RMS 变得很大,这可能会影响模型的性能。因此,作者就和 AdamW 一样使用 weight dacay 来避免这个问题,即
作者通过实验对比了 AdamW, vanilla Muon 和 Muon w/ weigth decay 三者的表现,实验结果如下图所示
实验结果显示,尽管 vanilla Muon 手链最快,但是由于其权重增长很快,因此最后模型的表现不如 AdamW 和 Muon w/ weigth decay.
接下来,作者分析了以下更新矩阵的 Root Mean Square (RMS), 结论是 Muon optimizer 的 RMS 与参数矩阵的形状相关:
Lemma For a full-rank matrix parameter of shape , its theoretical Muon update RMS is .
证明如下:通过 Newton-Schulz 迭代,我们得到 , 其中 是 SVD 分解,我们有
其中, , 这样就完成了证明。
而 Adam 和 AdamW 的 RMS 都在 附近。作者认为 RMS 也会影响模型表现:
- 当 过大时,如 dense MLP matrix, 其更新就会变得很小,限制了模型的表现
- 当 过小时,如 GQA 中的 KV head 或者 DeepSeek-V3 中的 MLA, 更新又会变得很大,导致训练不稳定。
因此,作者就提出了一个 rescaling 的技巧,来消除 Muon optimizer 的影响。
作者通过实验发现,AdamW 的 RMS 通常在 左右,因此,作者将 Muon optimizer 的更新设置如下
基于这个改变, Muon 和 AdamW 可以共享学习率以及 weight decay 参数。
Distributed Muon
ZeRO-1 天然适合 AdamW, 因为 AdamW 都是 element-wise 进行计算的。但是 Muon 则需要梯度矩阵的全部信息。因此,作者就针对 ZeRO-1 进行适配, 提出了 Distributed Muon, 分布式版本将优化器的状态进行切分,然后加入了两个额外的操作:
- DP gather: 将 ZeRO-1 切分的梯度矩阵 gather 为一个完整的矩阵
- Calculate Full Update: 对完整的梯度矩阵执行 Newton-Schulz 迭代
最终,Distributed Muon 的算法如下图所示

最后,作者分析了一下 distributed Muon 和 distributed AdamW 的内存和算力占用:
- 内存开销:Muon 只有一阶矩,而 AdamW 有二阶矩,因此 Muon 的额外内存开销为 AdamW 的一半。
- 通信开销:对于 ZeRO-1,通信开销来源于三个过程:All-Gather 参数 用于前向传播, Reduce-Scatter 梯度 用于反向传播, All-Gather 更新后的参数 用于下一轮的前向传播。AdamW 不引入额外通信,所以其每个参数的通信量为 , 分别代表 和 的通信量。而 Muon 则需要额外的一次通信来得到 full matrix, 因此每个参数通信量为 , 分别代表 和 full matrix. 也就是说,分布式 Muon 的通信量最高为 AdamW 的 倍。实际上由于我们使用 multiple DP, 这个比例会更接近于 .
- latency:Distributed Muon 相比于 AdamW latency 更高,这是因为 Muon 需要进行 DP gather 以及计算 Newton-Schulz 迭代。但实际上,latency 很小,因为 Newton-Schulz 迭代只需要迭代 5 次,并且 optimizer 的 end-to-end latency 相比于 forward-backward 过程是可以忽略的。一些额外的技巧也可以降低 latency.
实际在训练的过程中,作者发现 Distributed Muon 相比于 AdamW 并没有太明显的 latency.
Experiments
Scaling Law of Muon
作者分析了一下 Muon Optimizer 的 scaling law, 实验结果如下图所示
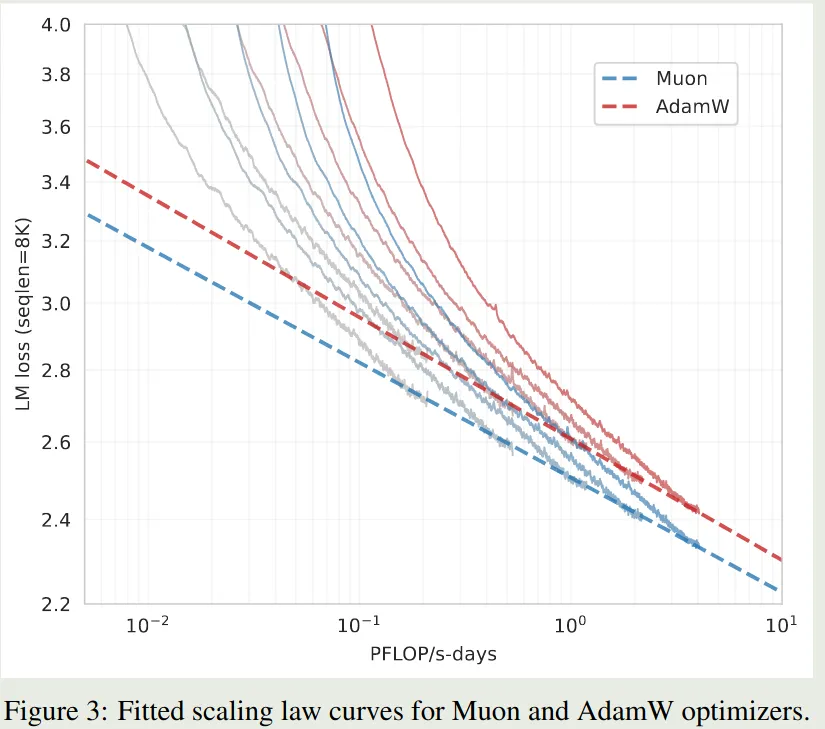
实验结果表明,在最优设置下,Muon Optimizer 只需要 的 FLOPs 就可以达到 AdamW 的表现
Pretraining with Muon
作者分贝使用 AdamW 和 Muon 训练模型,然后评测了以下模型在不同 benchmark 上的表现,结果如下图所示
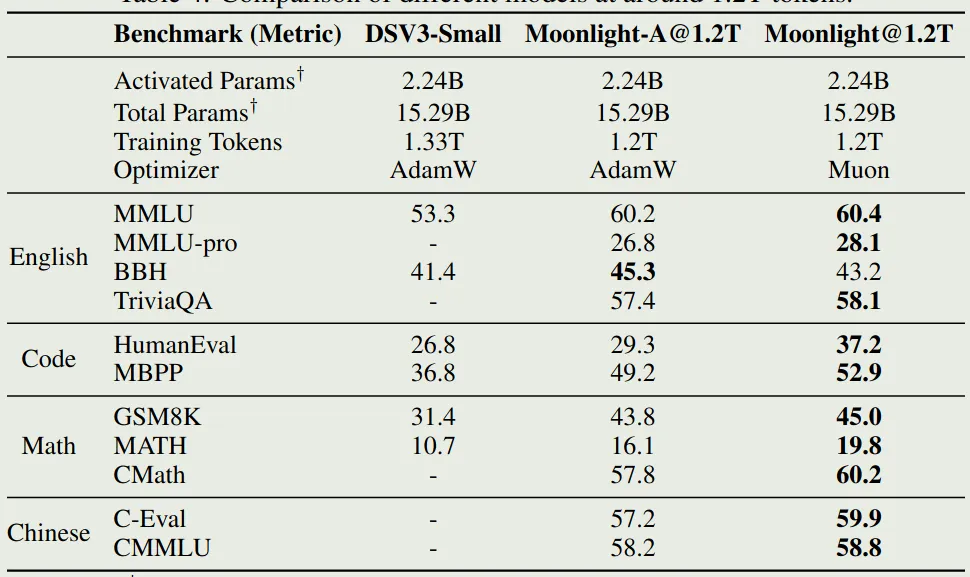
可以看到,在相同的设置下,Muon optimizer 的表现更好。
Dynamics of Singular Spectrum
Muon optimizer 的核心思想就是让比较难更新的方向也能被更新到,本节作者就探究了 Muon 是否满足这个性质,作者对参数矩阵进行 SVD 分解,然后定义 SVD entropy 如下
作者对 SVD entropy 可视化如下
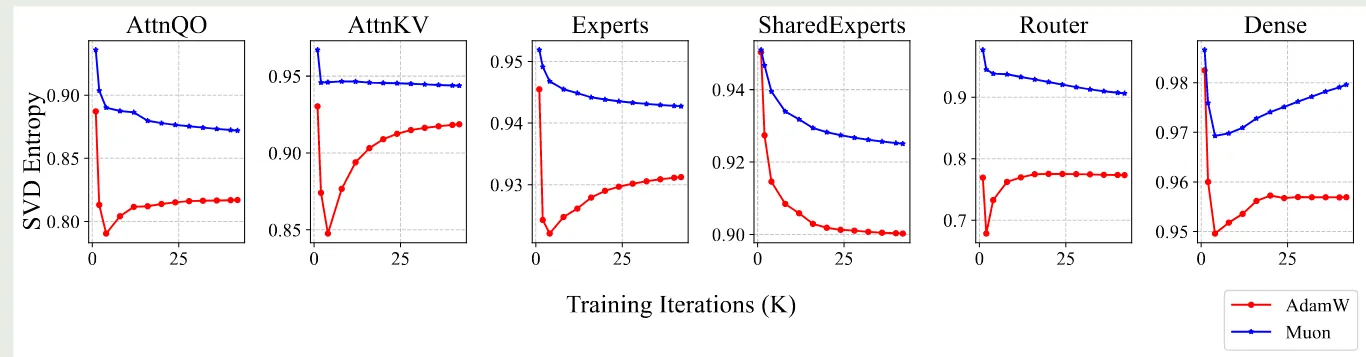
可以看到,Muon optimizer 的 SVD entropy 比 AdamW 更大,这说明 AdamW 的更新方向更多更广,验证了 Muon optimizer 的核心思想
SFT with Muon
作者还在 SFT 阶段验证了 Muon optimizer 的有效性。实验结果如下图所示
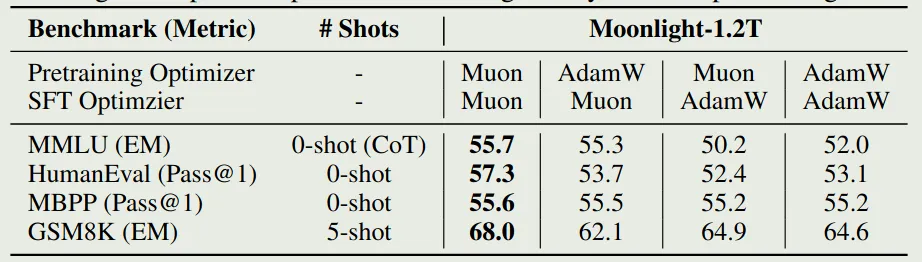
结论主要有两个:
- 预训练阶段与 SFT 阶段使用不同的优化器时,模型表现没有明显区别
- SFT 阶段使用 Muon 可以达到与 AdamW 差不多的表现,但是最好还是在 pre-training 阶段使用 Muon
Conclusion
作者探究了如何 scale up Muon Optimizer. 通过改进,作者在 16B-A3B 的 MoE LLM 上验证了 Muon Optimizer 的性能。实验结果发现,Muon Optimizer 的训练效率比 AdamW 提升了 2 倍左右。
作者提出了三个未来可行的研究方向:
- 目前 Muon 只能针对 2D 参数进行优化,其他参数仍然依赖于 AdamW 优化器,是否可以使用 Muon 优化所有参数?
- Muon optimizer 可以理解是 spectral norm 下的 steepest descent 方法,如何将其扩展到 Schatten norm 是一个可以研究的方向
- 实验里提到,预训练和 SFT 阶段使用不同的 optimizer, 表现不是最优的,如何解决这个因为不同 optimizer 导致的性能差距是一个需要解决的问题。