Introduction
当我们在硬件上运行算法时,我们的算法效率取决于三个因素:
- 计算机的计算效率,也就是每秒可执行的操作数 (OPs/s)
- 数据移动效率,也就是每秒可传输的 bytes (bytes/s)
- 需要的内存空间 (bytes)
通过分析这三个因素,我们可以给出一个计算的上下界
Arithmetic Intensity
首先,我们要回答的第一个问题是,运行时间意味着什么?为什么实际运行时间比理想时间要更多?
容易知道,实际的运行时间由三部分组成
Computation 首先,运行时间与我们的算法和 GPU 设备相关,在深度学习中,我们的算法通常由 FLOPs 决定,GPU 决定了算法的运行时间:
Communication within a chip 其次,运行时间还受加载数据的速度的影响,在执行计算之前,我们需要先把数据从 HBM 加载到对应的 core 上,因此,加载数据的速度也会影响最终运行时间。我们将加载数据的速度称之为 HBM bandwidth.
Communication between chips 最后,当我们在多个 GPU 上运行模型时,我们还需要在 GPU 之间进行通信,相关的通信手段如下表所示 (intra node 代表同一台服务器,inter node 代表不同服务器),我们将 GPU 的通信速度称之为 Network bandwidth.
| Method | Data Path | BandWith | Use cases | |
|---|---|---|---|---|
| Intra Node | NVLink | Direct GPU-to-GPU | 1.8 Tb/s (B200) | TP |
| NVSwith | all-to-all | 900 GB/s-1.8T b/s | full mesh sync in DGX | |
| GPUDirect P2P | Direct over PCIe Bus | 32-128 GB/s | small clusters withou NVLink | |
| Shared Memory | GPU -> CPU RAM -> GPU | 20-50 GB/s | Fallback when P2P is disabled | |
| Inter Node | InfiniBand | GPU -> NIC -> IB Switch | 200-400 Gbps | Large scale LLM training |
| GPU Direct RDMA | GPU -> NIC -> Network | Same as NIC speed | Bypassing CPU for network sync | |
| RoCE (v2) | RAME over Ethernet | 100-400 Gbps | Cost-effective Ethernet clusters | |
| TCP/IP sockets | GPU -> CPU -> Kernel -> Net | < 100 Gbps | Standard networking |
我们将 GPU 的通信 (intra-node 和 inter-node) 效率定义如下
通常来说,我们可以通过计算 - 通信重叠来降低整体的运行时间,比如说 DeepSeek-V3 等模型提出的优化方法, 此时理论上的最小运行时间就是 和 之间的最大值。另一方面,如果我们不做任何优化,则理论上最大运行时间就是 和 之和。我们定义对应的 bound 如下
注意到
也就是最大运行时间最多为最小运行时间的两倍。因此,我们一般直接优化 .
如果我们假设我们可以完全达到计算 - 通信重叠,则:
- 当 时, 我们完全利用了 GPU 的资源,因为此时运行时间受硬件的计算效率约束,我们将其称之为 compute bound
- 当 时, 此时运行时间受硬件的通信效率影响,GPU 的(计算)利用率不完全,我们将其称为 communication bound
为了评估一个算法时 compute bound 还是 communication bound, 我们可以使用 arithmetic intensity 来进行评估。我们先分析 single GPU 的情况,再分析 multi GPU 的情况
Single GPU
Arithmetic Intensity 一个算法的 arithmetic intensity 定义为算法通信所需要的 FLOPs 和所需要的 bytes 之比:
arithmetic intensity 衡量了一个算法的 FLOPs per bytes, 当 arithmetic intensity 比较高时,说明 , 此时 GPU 的利用效率较高,反之则说明 GPU 出现了空置的情况。这两种情况的交叉点由 GPU 的 Peak arithmetic intensity 决定:
这里 就是 GPU 达到 peak FLOPs 时对应的 arithmetic intensity.
不同 GPU Tensor Core 对应的 intensity 如下所示
| GPU | Generation | bandwidth | peak BF16 Tensor Core | intensity |
|---|---|---|---|---|
| V100 | Volta | 300 GB/s | 125 TFLOPs/s | 427 |
| A100 | Amper | 1,935 GB/s | 156 TFLOPs/s | 83 |
| H100 | Hopper | 3.35TB/s | 495 TFLOPs/s | 147 |
| H200 | Hopper | 4.8TB/s | 495 TFLOPs/s | 147 |
| B200 | Blackwell | 576 TB/s | 2250 TFLOPs/s | 3.9 |
Example 假设我们使用 BF16 精度计算两个长度为 的向量的内积,计算时的流程如下:
- 从 HBM 中加载两个向量,通信量为
- 计算两个向量内积,需要 次乘法和 次加法
- 将结果写回 HBM, 通信量为 .
从而内积的 intensity 为
也就是说,内积的 arithmetic intensity 最大为 , 说明这是一个 memory-bound operation.
接下来,我们可以对 communication-bound 和 compute-bound 进行可视化,如下图所示
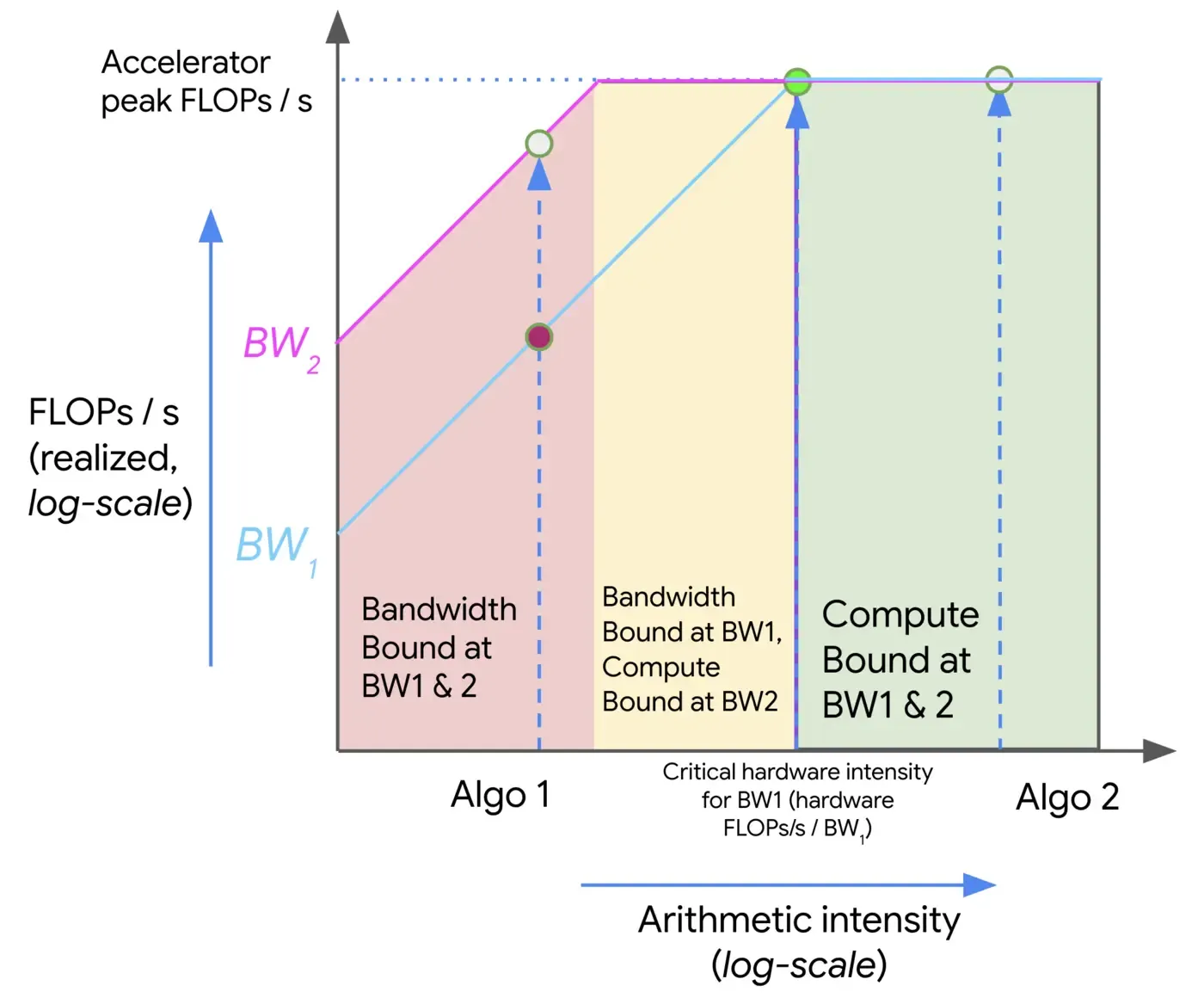
这里我们展示了两个算法 Algo 1 和 Algo 2 的 arithmetic intensity, 当 intensity 较小(小于硬件的 intensity)是,算法为 communication bound, 随着 intensity 增加,算法逐渐由 communication bound 过渡到 compute bound. 上面这个模型被称为 Roofline model, 其展示了算法计算效率与硬件之间的关系。
为了提高算法计算效率,我们可以通过提升算法的 arithmetic intensity 或者提高 memory bandwith.
Example
接下来我们来看一下矩阵计算的 intensity, 我们仍然假设在 BF16 精度下进行计算,假设输入矩阵为 以及 , 则输出为 . 计算过程为:
- 从 HBM 中加载 和 , 通信量为 bytes
- 计算矩阵乘法,计算量为 FLOPs
- 将结果写回到 HBM, 通信量为 .
因此对应的 intensity 为
假设 (在 LLM 中这个假设一般成立),我们有
因此我们就可以通过调整 (batch size) 来将算法从 memory-bound 转换为 compute bound.
Multi GPU
在 multi GPU 的场景下,我们需要关注 GPU 之间通信的效率,一般来说,GPU 之间效率要远小于 GPU 内部通信效率,下面是不同 GPU 的内部通信(HBM bandwidth) 和 GPU 之间通信效率对比
| GPU | Generation | HBM Type | HBM bandwidth | NVLink Generation | NVLink Bandwidth |
|---|---|---|---|---|---|
| V100 | Volta | HBM2 | 300 GB/s | 2.0 | 300 GB/s |
| A100 | Amper | HBM2e | 1,935 GB/s | 3.0 | 600 GB/s |
| H100 | Hopper | HBM3 | 3.35TB/s | 4.0 | 900 GB/s |
| H200 | Hopper | HBM3e | 4.8TB/s | 4.0 | 900 GB/s |
| B200 | Blackwell | HBM3e | 576 TB/s | 5.0 | 1800 GB/s |
Example 我们考虑一个分布式矩阵乘法,假设我们有两个 GPU, 计算精度为 BF16, 矩阵 以及 分别被切分为相同大小存储在这两个 GPU 上,此时,计算流程为:
- 在 GPU0/GPU1 上,分别从对应的 HBM 中加载 以及
- 在 GPU0/GPU1 上,分别计算对应的矩阵乘法 和 , 计算量为 .
- 将 GPU1 的结果 通信传输到 GPU0 上,通信量为 .
- 对结果进行相加,. 计算量为 .
此时,我们的 intensity 为 (注意这里计算时间除以 2 代表我们使用两张 GPU 因而效率翻倍了)
可以看到,此时决定性因素在于 而不是 , 这对于我们实现并行算法至关重要
我们在本文中介绍 strong scaling 和 weak scaling
Parallel Performance
给定一个算法,Parallel speedup 定义为在一个处理器上的运行时间 和使用 个处理器的运行时间 之比,即
直觉上,使用的处理器越多,我们所花费的时间越少,并且理想情况下,我们的时间应该随 增加而线性减少。但实际上,我们并不能实现 倍加速,因此,我们使用 efficiency 来评估我们的并行效率:
我们可以将 efficiency 理解为处理器做有用功的时间比例。
Amdahl’s Law
我们可以将一个算法或者程度的运行时间分为可并行部分以及不可并行部分,可并行部分可以运行在多个处理器上,而不可并行部分只能在一个处理器上运行。
我们将算法运行的时间分为并行部分 和串行部分 , 我们有
当我们使用 个处理器时,我们只能减少可并行部分的运行时间 , 并且由于我们使用了并行算法,我们还可能会产生额外的并行开销,记为 , 则我们有
如果我们假设 , 则我们可以得到
这个等式称为 Amdahl’s law. 它说明一个算法通过并行的 speedup 取决于能够被并行的那部分,即 . 比如硕,如果 , 则不论我们使用多少处理器,我们最多只能得到 倍的加速。
注意到 Amdahl’s law 假设我们的算法要处理的任务不随处理器数量而变化,这种 scaling 被称为 strong scaling.
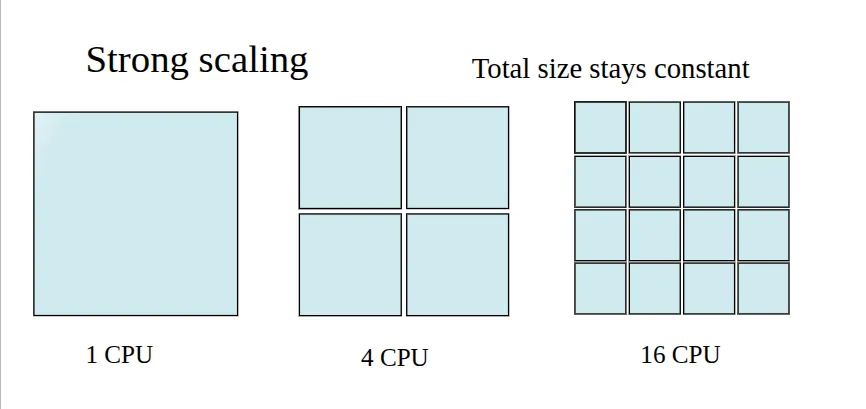
Gustafson’s Law
但是在某些情况下,我们希望使用更多的处理器来处理更大的问题,这种 scaling 被称为 weak scaling, 其示意图如下所示
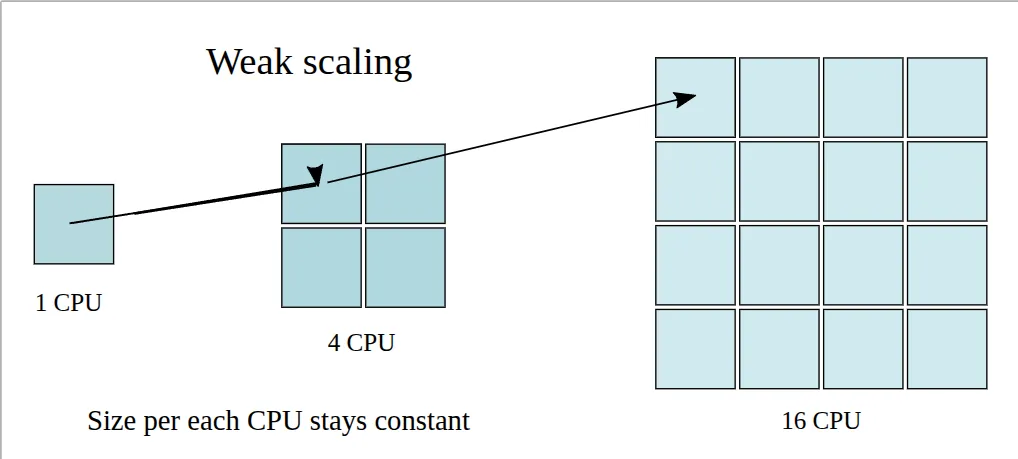
在这种场景下,随着 增大,问题的规模增长,使得并行运行时间保持不变,此时在单个处理器场景下我们并行与串行部分的比例仍然不变,如果我们要处理 倍工作量的问题,则我们的串行总时间为
由于并行运行时间不变,我们可以将运行时间表示为
此时我们的 speedup 为