Introduction
本文中关注的研究问题为:
给定一个 FLOPs budget, 如何平衡 model size 和 dataset size 之间的关系?
即,我们希望求解如下优化问题:
作者通过训练 400 多个模型,构建了对应的 scaling law.
已有工作如 Kaplan scaling law 已经发现模型参数和大语言模型表现之间的关系,一个结论就是计算最优并不代表达到最优的 loss. 在本文中,作者也有相同结论,但是作者认为大模型应该使用比 Kaplan scaling law 推荐的更多的 training token. 基于这个发现,作者训练了 Chinchilla (Hoffmann et al., 2022), 一个 70B 的 LLM, Chinchilla 相比 Gopher 表现有了大幅度的提升。
Scaling Law
Fix Model Size and Very Dataset Size
这个方法中,作者通过改变训练步数,来研究 FLOPs 与模型表现之间的关系,结果如下图所示
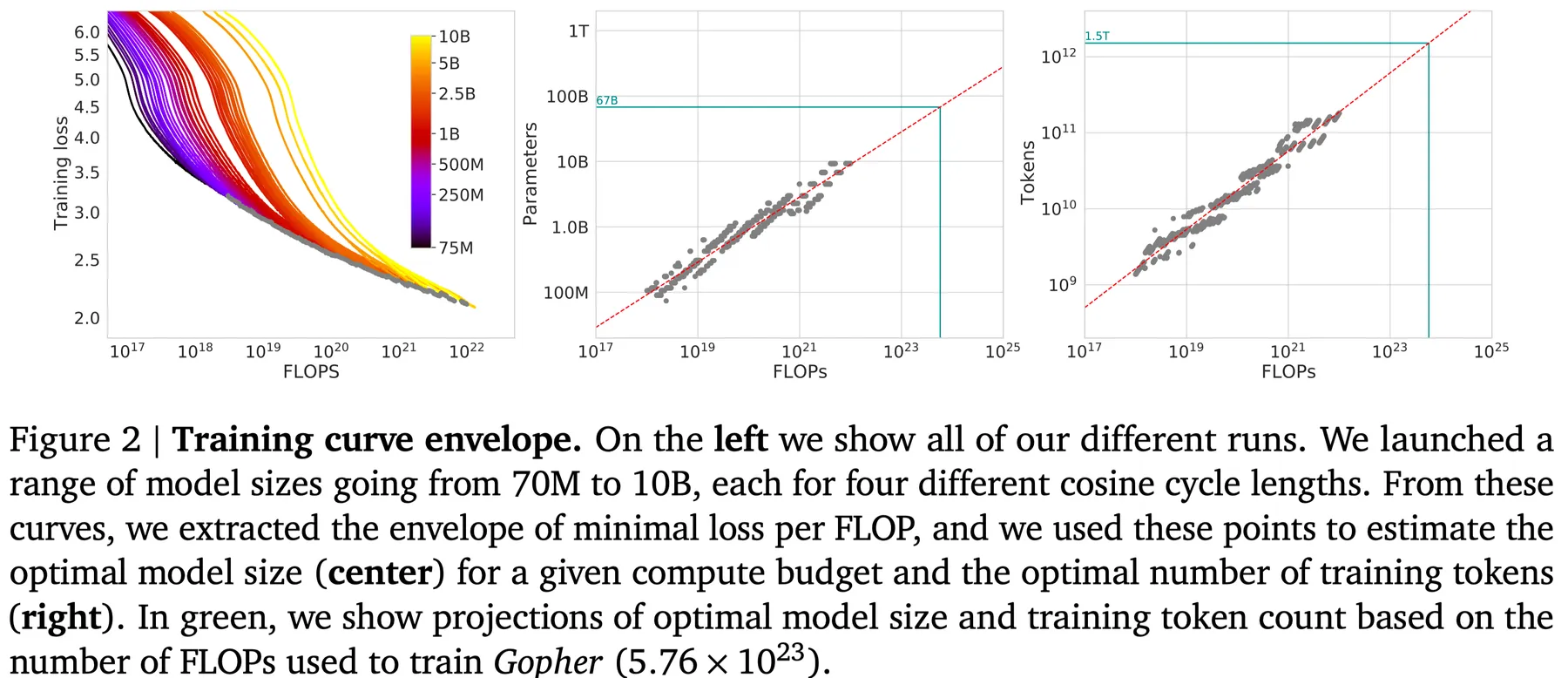
通过对实验结果进行拟合,作者发现存在关系 以及 , 拟合的结果为 .
IsoFLOPS Profiles
这个方法中,作者使用了不同的模型大小以及算力来构建最优模型参数量与算力之间的关系。作者给定 9 个算力配置,然后选取不同参数量的模型,训练的 token 数由算力和模型参数量决定,实验结果如下图所示
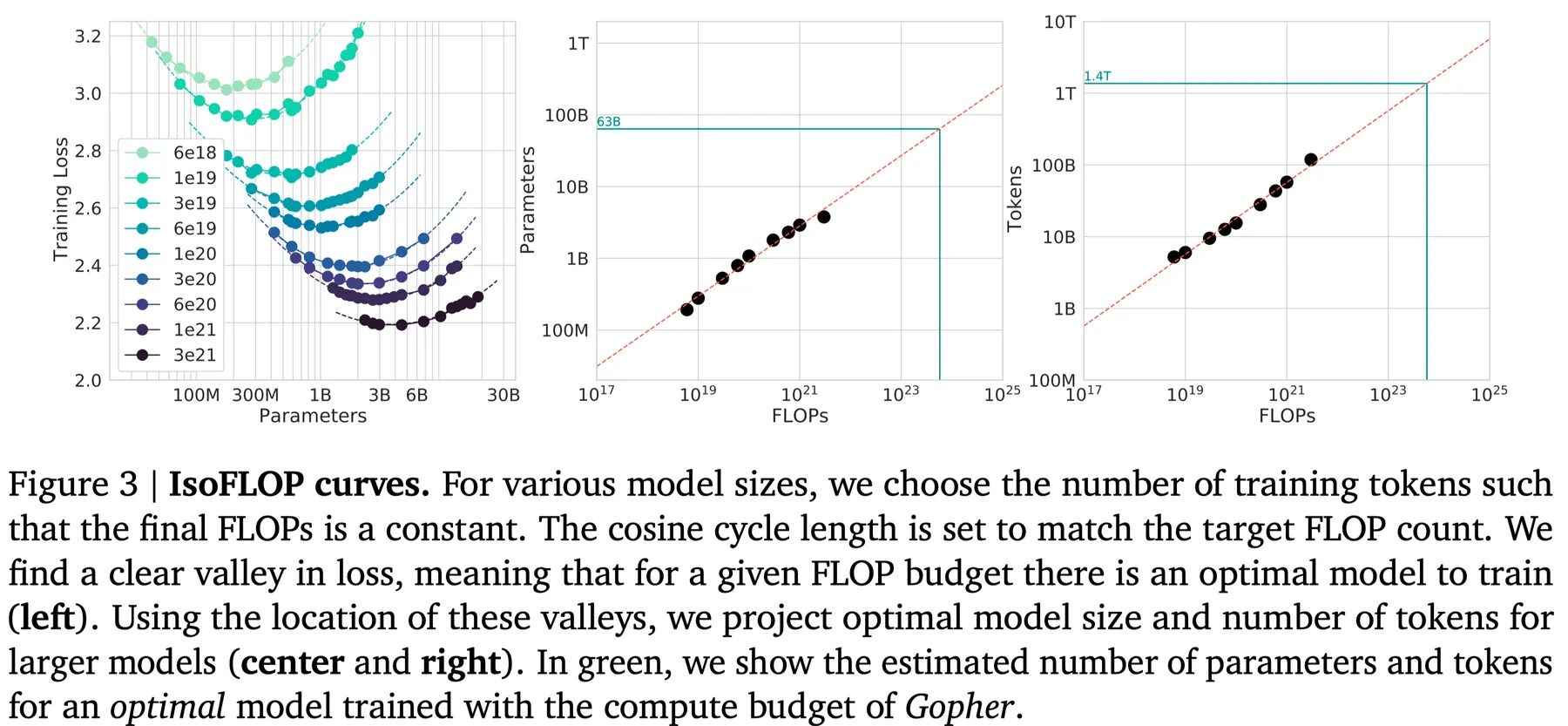
结果显示,不同大小的模型的表现 (loss) 随算力上升先下降后上升。因此给定算力,存在一个最优的 model size. 作者基于拟合出来的曲线得到了 Gopher 使用的算力配置下的最优 model size 和 training tokens. 同样的,作者得到 .
Fitting a Parametric Loss Function
这个方法中,作者对 进行建模,作者使用了如下的公式
第一项代表了建模的误差,第二项代表了数据集充分大损失与模型参数之间的关系,第三项代表了当模型充分训练时,损失与数据集大小之间的关系。
为了求解 , 作者基于训练收集到的数据 , 通过 L-BFGS 算法来最小化 Huber loss 进行求解,结果得到 .
将结果带入带上面的表达式中,然后求出梯度为 0 的点,就得到
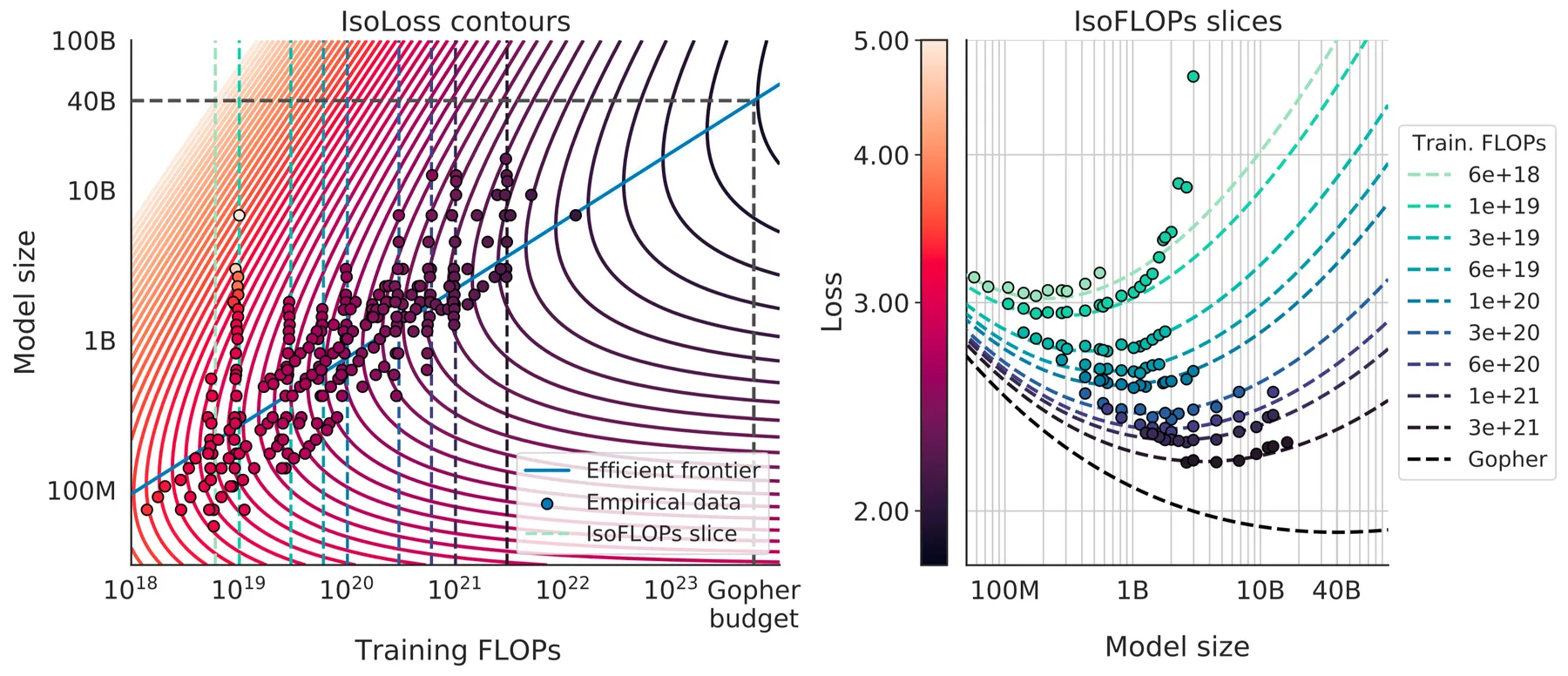
带入数值之后就得到 , . 作者对结果可视化如下图所示,左图是拟合曲线的 Contour plot, 右图对左图的一个切片
Optimal Model Scaling
作者将三种方法的结果以及 Kaplan scaling law 的结果总结放在下表中,作者假设 以及
| Approach | ||
|---|---|---|
| Kaplan | 0.73 | 0.26 |
| Approach 1 | 0.50 | 0.50 |
| Approach 2 | 0.49 | 0.51 |
| Approach 3 | 0.46 | 0.54 |
结果表明,三种方法的结论差不多:model size 和 dataset size 增长 debility 差不多。
作者因此给出来的不同模型大小所需要的算力以及 token, 结果如下表所示
| Parameters | Approach 1 | Approach 2 | Approach 3 | |||
|---|---|---|---|---|---|---|
| FLOPs | Tokens | FLOPs | Tokens | FLOPs | Tokens | |
| 400 M | 1.92e+19 | 8.0 B | 1.84e+19 | 7.7 B | 1.84e+19 | 7.7 B |
| 1 B | 1.21e+20 | 20.2 B | 1.20e+20 | 20.0 B | 1.20e+20 | 20.0 B |
| 10 B | 1.23e+22 | 205.1 B | 1.32e+22 | 219.5 B | 1.32e+22 | 219.5 B |
| 67 B | 5.76e+23 | 1.5 T | 6.88e+23 | 1.7 T | 6.88e+23 | 1.7 T |
| 175 B | 3.85e+24 | 3.7 T | 4.54e+24 | 4.3 T | 4.54e+24 | 4.3 T |
| 280 B | 9.90e+24 | 5.9 T | 1.18e+25 | 7.1 T | 1.18e+25 | 7.1 T |
| 520 B | 3.43e+25 | 11.0 T | 4.19e+25 | 13.4 T | 4.19e+25 | 13.4 T |
| 1 T | 1.27e+26 | 21.2 T | 1.59e+26 | 26.5 T | 1.59e+26 | 26.5 T |
| 10 T | 1.30e+28 | 216.2 T | 1.75e+28 | 292.0 T | 1.75e+28 | 292.0 T |
作者基于发现的 scaling law, 对已有模型进行了探究,发现现有的大模型都存在 under-training 的现象,结果如下图所示
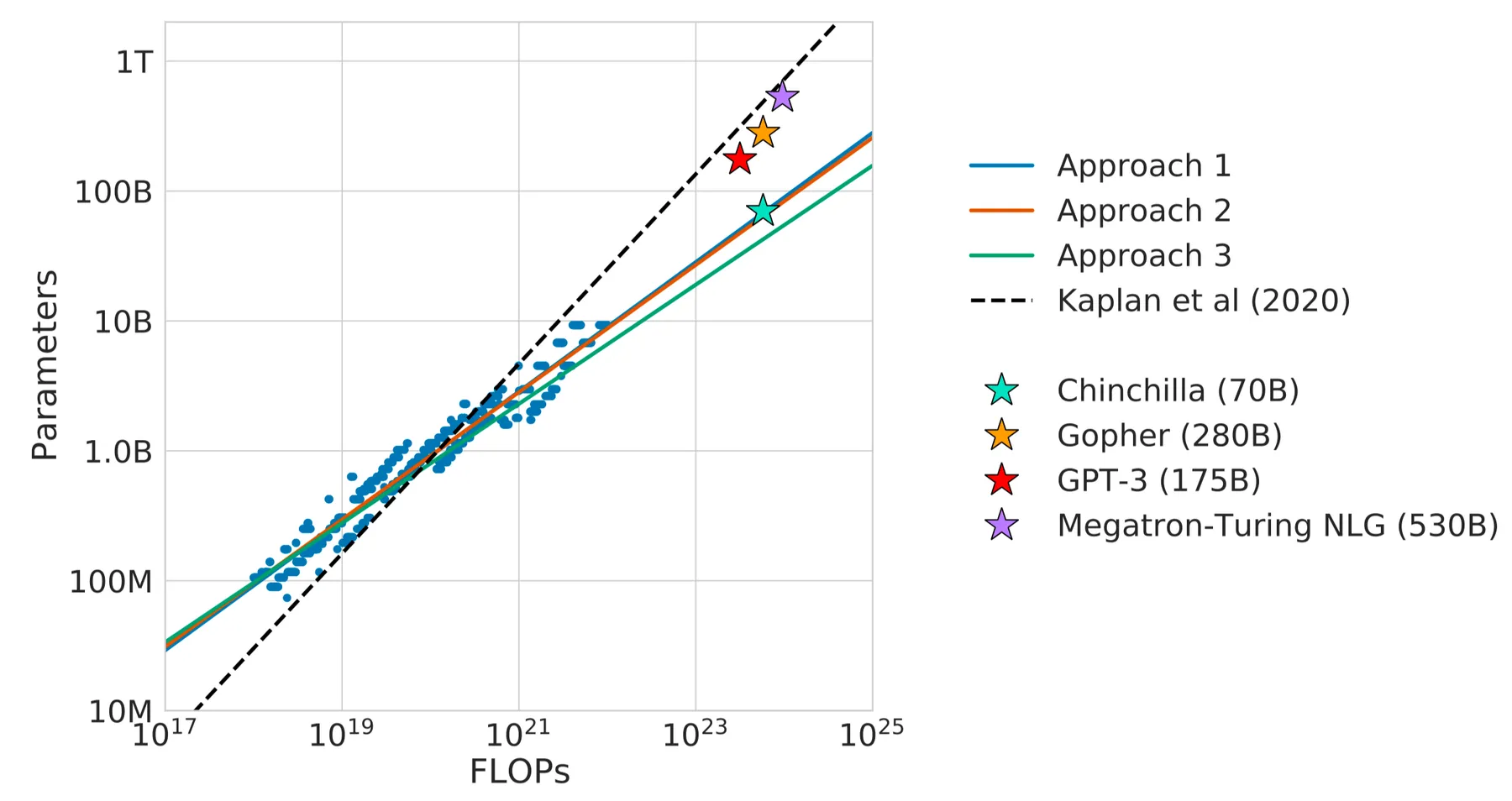
实验结果显示,现有的大模型的 size 应该更小(或者需要更大的算力)。作者最终的结论就是,现有的比较小的模型,需要更多的算力才能达到更好的表现。
Chinchilla
基于上一节的发现,作者提出了 Chinchilla, 一个 70B 的模型,训练使用了 1.4T token. 训练的数据集为 MassiveText 的扩展版本,训练使用的优化器为 AdamW, tokenizer 为 SentencePiece.
模型配置如下表所示
| Model | Layers | Number Heads | Key/Value Size | dmodel | Max LR | Batch Size |
|---|---|---|---|---|---|---|
| Gopher 280B | 80 | 128 | 128 | 16384 | ||
| Chinchilla 70B | 80 | 64 | 128 | 8192 |
Ablation Study
learning rate schedule 作者还通过 ablation study 发现,cosine learning rate cycle length 应该和训练步数差不多,当 cycle length 太长时,模型表现会下降。
Optimizer 作者对比了 Adam 和 AdamW 的表现,结果发现,AdamW 的表现优于 Adam.
High Precision
训练时,作者使用了高精度也就是 float32 来保存梯度的状态,结果显示,不管是 Adam 还是 AdamW, 使用高精度都可以提高模型的表现
Comparison with Kaplan 作者还对比了 Chinchilla 和 Kaplan 的预测结果,如下图所示
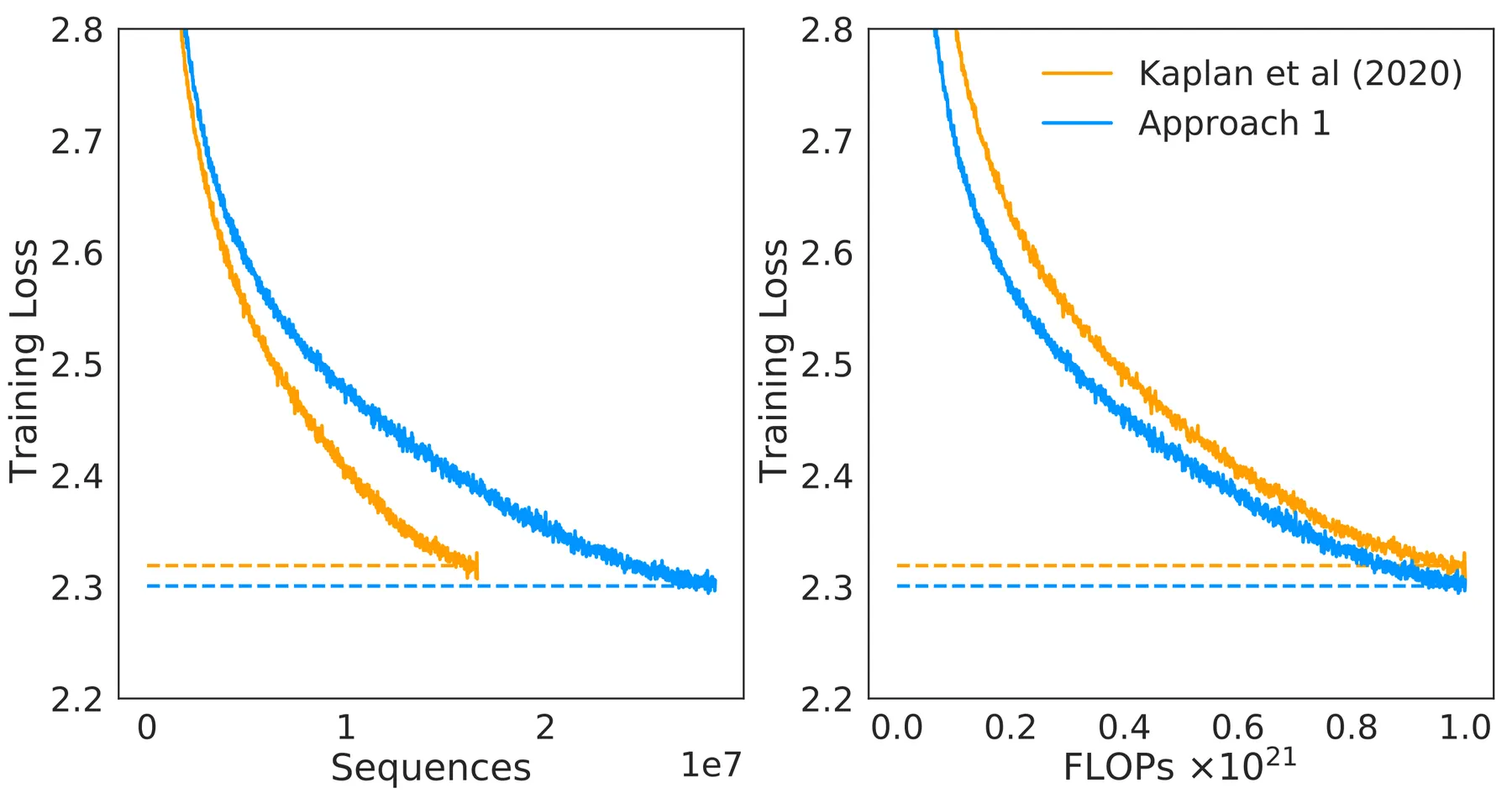
结果显示,基于 Chinchilla 预测得到的模型训练效果比 Kaplan 的更好。
Curvature of the FLOPs-frontier 作者发现,FLOP-minimal loss frontier 存在 curvature, 也就是小模型和大模型预测出来的曲线是不一样的,作者将结果展示在下图中
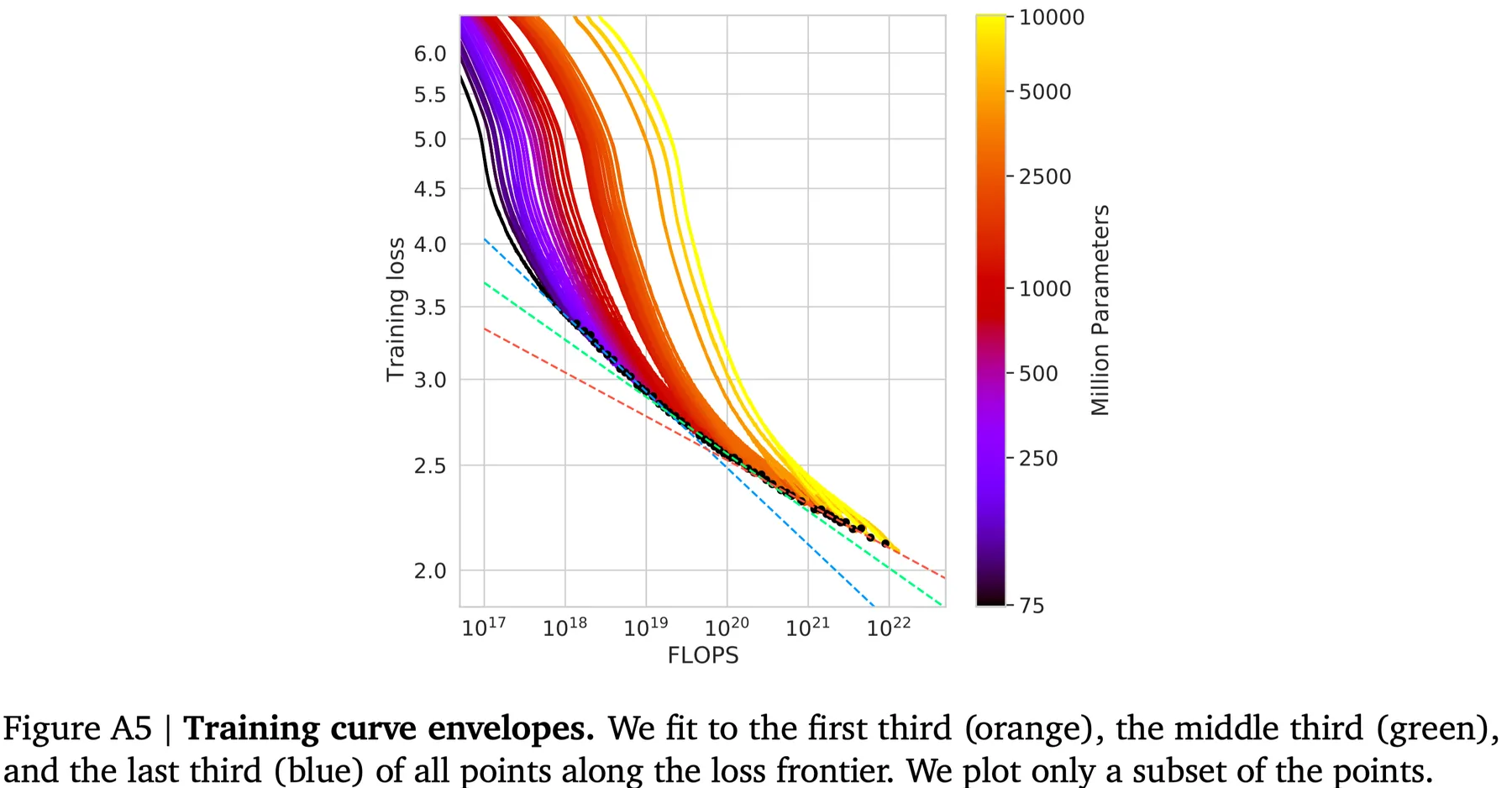
结果显示,从小模型拟合出来的结果比大模型拥有更高的算力使用效率,作者认为这是未来的一个研究方向。
Conclusion
本文中作者重新探究了针对 LLM 的 scaling law, 作者发现已有的大模型都存在 under-training 的现象,也就是说,模型需要更多的训练 token, 具体来讲,model size scaling 和 dataset scaling 应该处于同一水平。作者基于这个结论,提出了 Chinchilla, 一个 70B 的 LLM, 其表现超过了 280B 的 LLM.
Introduction
OpenAI 提出了针对decoder only LLM的scaling law (Kaplan et al., 2020).
作者首先就总结了本文的发现,主要有以下几点:
- 损失与模型的 scale , 即除开 embedding 的模型参数,数据集大小以及算力强相关,与 model shape 比如 depth 或者 width 关系不大
- scaling law 是非常光滑的,意味着 scaling law 是一个可预测的模型
- overfitting 普遍存在,当参数和数据集大小同时增加时,模型的表现会增加,但是当其中一个量固定时,提升就比较小。并且当我们将模型参数提升 8 倍时,我们只需要将数据集的大小提升 5 倍就可以避免过拟合
- 训练的损失函数曲线与 model size 无关,因此我们可以预测给定大小模型的表现
- 模型在测试集和训练集上的表现高度相关,因此我们可以基于训练集的损失来预测模型的表现
- 大模型比小模型拥有更高的 sample efficiency, 即更小的训练步数就可以达到相同的表现
- convergence 不能说明一切,我们可以通过 early-stopping 来提高算力使用效率,避免模型花费过多的算力在较小的提升上
- 最优的 batch size 与 loss 呈一个 power law 的关系
Notation
| Symbol | Notation |
|---|---|
| cross entropy loss | |
| non-embedding parametters | |
| batch size | |
| number of training steps | |
| estimate of total training compute | |
| dataset size in tokens | |
| critical batch size | |
| estimate of the minimum compute to reach a given value of loss | |
| estimate of the minimum steps to reach a given value of loss | |
| power-law exponents for the scaling law of loss | |
| hidden size of the model |
为了简便,后续未经特殊说明,我们说模型参数均指的是 non-embedding 的参数
Scaling Law Overview
- 当数据集 足够大时,损失与模型参数大小 之间的关系为
- 给定模型参数大小 , 损失与数据集大小 之间的关系为
- 给定足够大的数据集 和最优模型大小 时,损失与算力 之间的关系为
作者在不同大小的数据集,算力,模型大小下进行了测试,结果发现 scaling 与模型的 shape, transformer 的超参数之间的关系比较小。 等决定了当我们 scale up 数据及大小,模型大小和算力时损失的变化情况。比如当我们将模型参数提升至 2 倍时,模型的损失会降低至原来的 .
基于发现 1 和 2, 作者发现当我们将模型的 size 提升至原来的 2 倍时,模型的数据集大小应该提升至原来的 倍,具体关系为 .
作者使用了一个统一的公式来描述损失与数据及大小和模型参数大小之间的关系
- 当数据集充分大时,损失与模型参数大小以及更新步数 的关系如下
这里 , , 是估计出来的最小优化步数
- 最优的 batch size 与损失函数之间的关系如下
- 给定算力 且无其他限制时,模型参数,数据及大小,batch size 和更新参数与算力之间的关系如下
其中
实验的结果为 , , . 也就是说,当我们提升算力时,提升模型的参数大小带来的收益是最高的。
Background
首先,transformer 的参数量通过计算可以得到
这里 是 hidden size, 是 layer 个数, 是 MLP 的 hidden size, 这里我们 假设 . 计算时我们丢掉了 bias 以及 LayerNorm 的参数量。具体计算过程见 LLM parameter analysis
transformer 一次前向计算的 operations 数量大概为
这里 是输入的 token 长度。
由于反向传播所需要的 FLOPs 是前向传播两倍,因此 transformer 的计算量为
具体计算过程见 LLM FLOPs analysis。也就是说,对于参数量为 的 transformer model, 每个 token 所需要的 FLOPs 为
Empirical Results and Basic Power Laws
Transformer Shape and Hyper-parameter Independence
作者基于 , 在保持总参数量 不变的情况下,分别调整 , 和 number of attention heads 的个数 (变化 用于维持总参数量不变),结果如下图所示
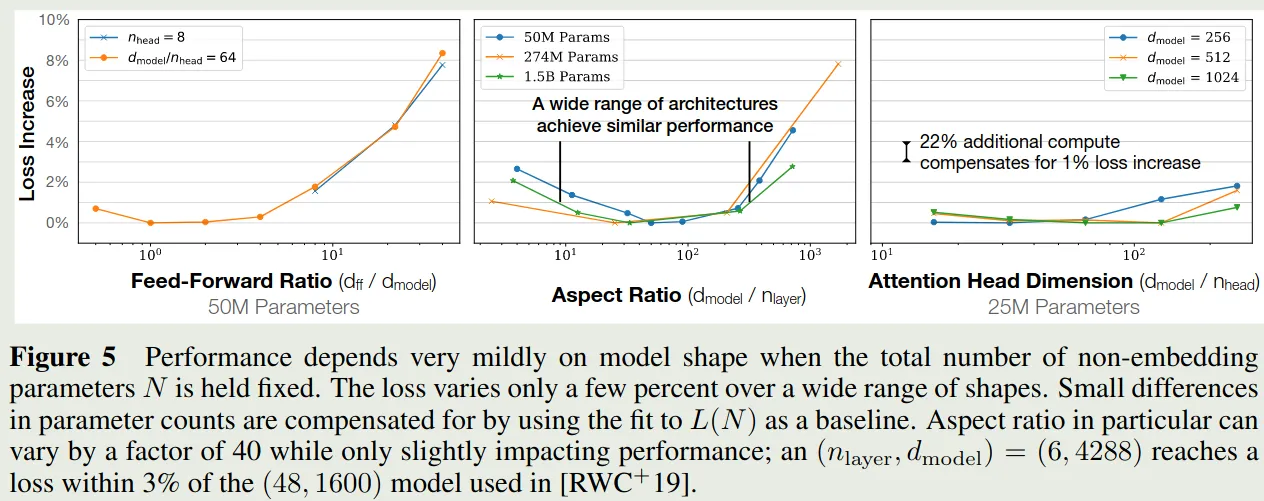
实验结果发现,损失对于 , , 都比较 robust, 说明模型的损失对模型的 shape 依赖性比较低。
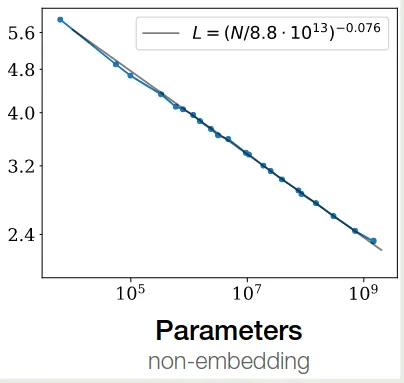
Non-embedding Parameter Count
作者探究了以下 model size 对损失的影响,作者使用了不同的 和 , 然后训练得到的损失情况如下图所示
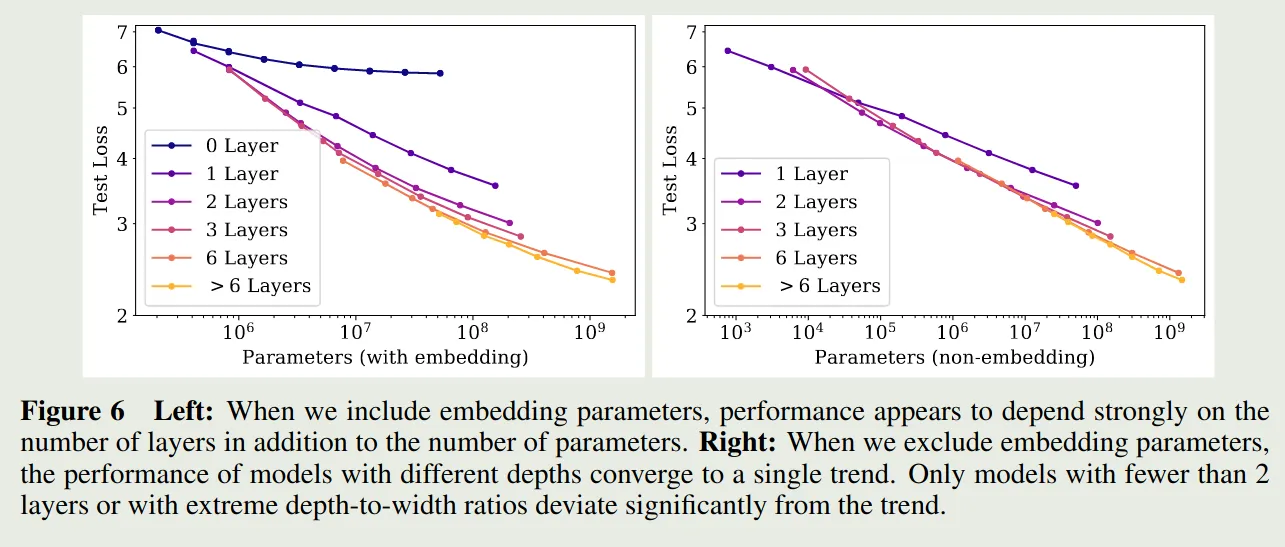
作者发现,当包含 embedding parameter 时,损失不仅依赖于模型参数量,还依赖于 layer 层数 , 但是当我们排除 embedding parameter 时,模型的损失便与 layer 层数 关系不大。这个趋势可以用以下模型来表示
最终拟合的曲线如下图所示
Comparing to LSTMs and Universal Transformers
作者比较了 LSTM 和 Transformer 结构的损失,结果如下图所示
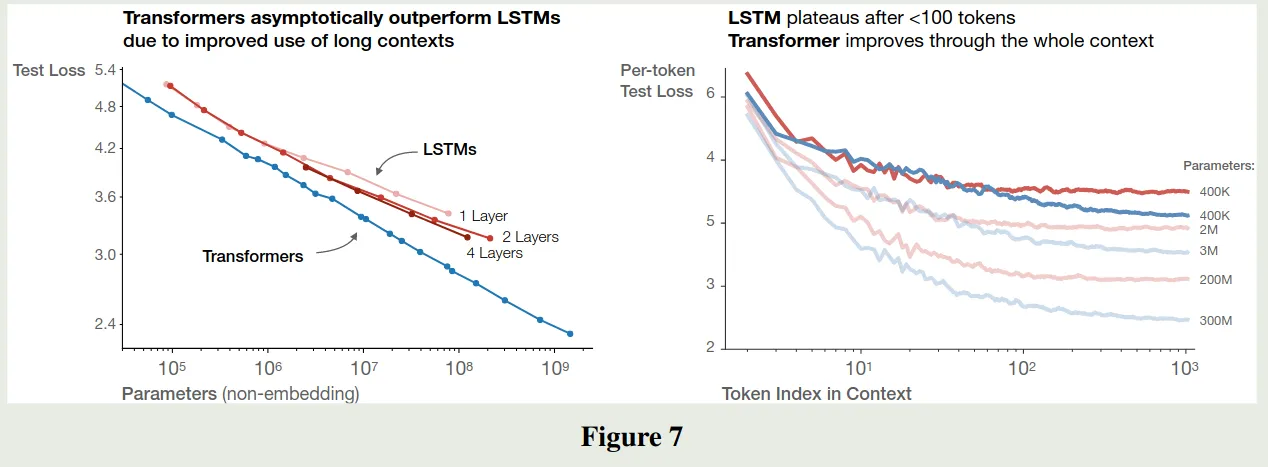
可以看到,transformer 比 LSTM 拥有更强的学习能力, LSTM 架构对于 early context 表现比较好,但是随着 context 增加,LSTM 的表现逐渐弱于 transformer. 即 transformer 的长上下文能力强于 LSTM 架构。
Generalization Among Data Distributions
模型是在 WebText2 数据集上训练的,作者进一步在其他数据集上评估了以下模型的泛化性,结果如下图所示
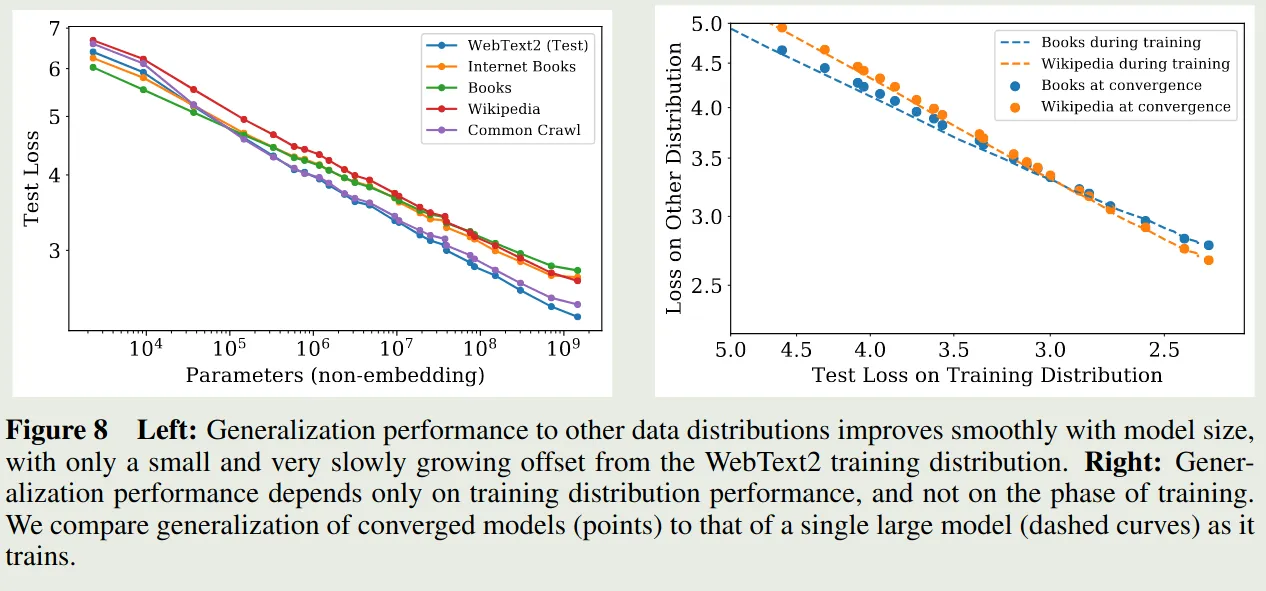
结果发现,模型在其他数据集上的泛化性很好。并且,模型的泛化性能仅与训练阶段的表现相关(validation loss),而与训练阶段(是否收敛)无关。
作者还评估了 model depth 对模型泛化性的影响,结果如下图所示
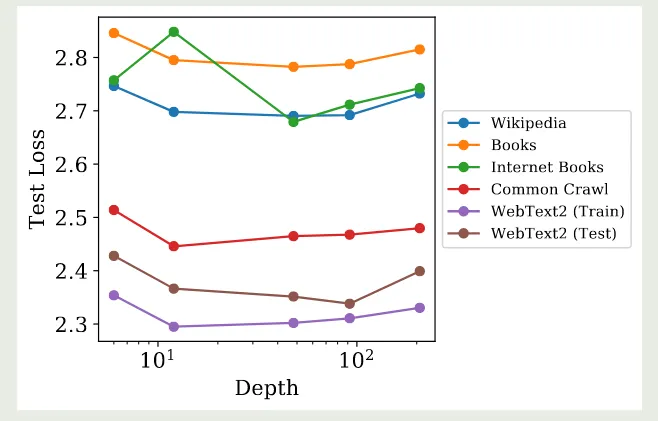
实验结果显示,model depth 对模型泛化性基本没有影响。
Performance with Data Size and Compute
作者探究了损失与 dataset size 之间的关系。作者固定一个模型,然后当 test loss 不再下降时停止训练,结果发现 test loss 与 dataset size 之间存在如下关系
拟合结果如下图所示
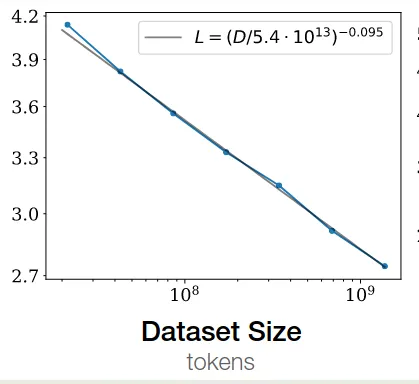
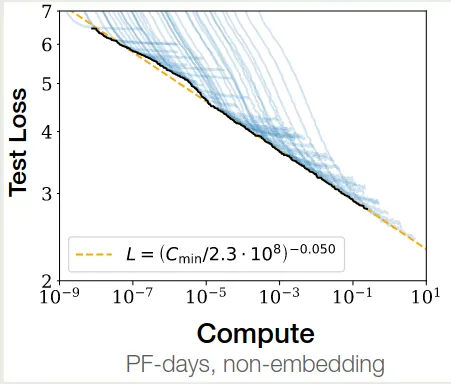
接下来,基于前面计算的结果,我们有 , 这里 是 batch size, 是训练步数。给定 , 作者使用不同大小的模型进行训练,batch size 保持不懂,训练步数设置为 ,实验结果显示损失与算力 之间满足如下关系
拟合结果如下图所示
作者进一步探究了 sample efficiency 与 model size 之间的关系,实验结果如下图所示
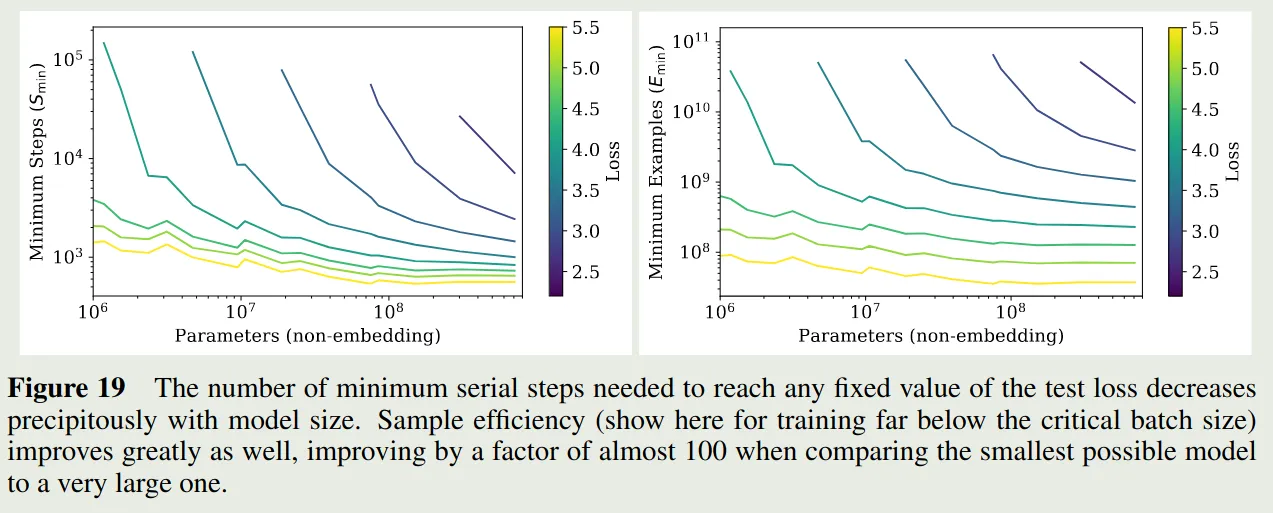
结果显示,随着 model size 增加,sample efficiency 也在增加
Charting the Infinite Data Limit and Overfitting
作者在本节探讨了同时变化 和 对损失变化的影响。
Proposed Equation
作者基于三个原则进行建模:
- 改变 vocabulary size 或者 tokenization 会 rescale loss
- 固定 并且令 , 则最终损失应该接近 . 反之固定 , 令 , 最终损失应该接近
- 在 处应该是可解析的
基于以上三条原则,将模型选择为如下形式
作者基于不同配置进行训练,基于实验结果你和得到的参数如下
| Parameter | ||||
|---|---|---|---|---|
| Value | 0.076 | 0.103 |
接下来,作者探究了模型的过拟合程度,作者定义如下 metric
带入 定义就得到
通过测试不同的模型,作者发现 的值在 左右,将实验结果带入到上面的公式就得到
也就是说对于参数量为 的模型,需要 data size 才能避免过拟合。
Scaling Laws with Model Size and Training time
作者在本节构建了损失函数与 model size 以及训练时间的 scaling law
Adjustment for Training at Critical Batch Size
已有结论说明,存在一个 critical batch size , 当 batch size 接近 时,增加 batch size 对计算效率影响比较小,但是当 batch size 大于 时,带来的提升比较小。另一方面,batch size 会影响梯度的噪声程度。因此,训练步数 和处理的样本数 应该满足:
这里 是达到损失 所需要的最小训练步数,而 是最小的训练样本数量。
作者的实验结果如下
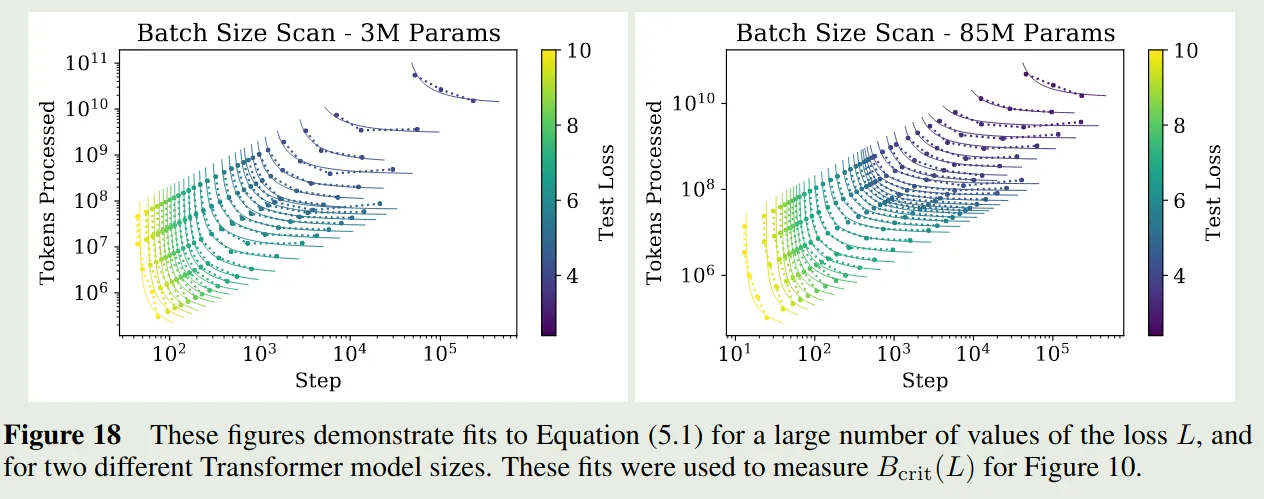
作者将 critical batch size 定义为
使用 critical batch size 进行训练可以在计算效率和算力之间达到一个平衡。
作者基于上面的实验结果探究了 critical batch size 和 model performance 之间的关系,实验结果如下图所示
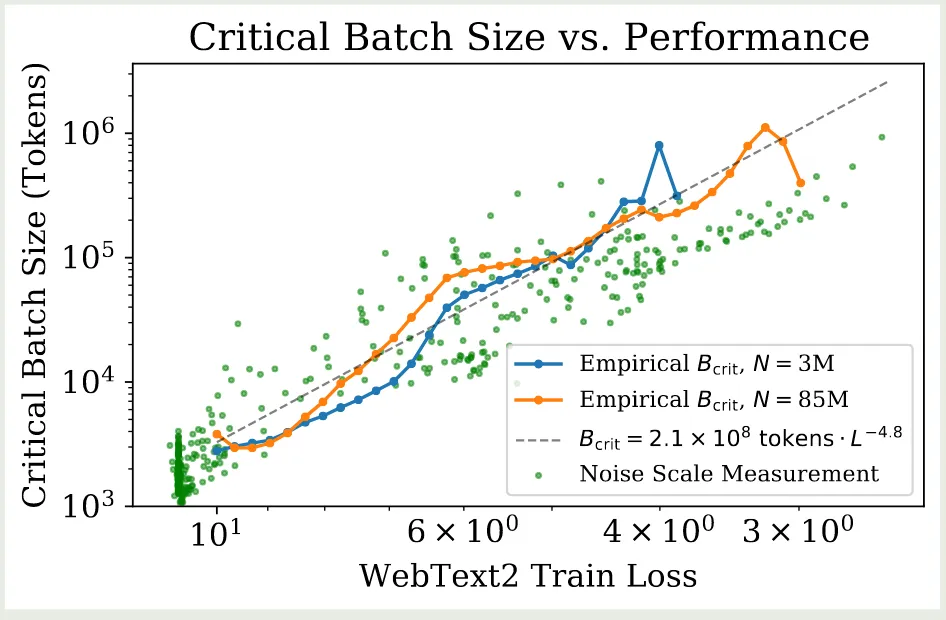
可以看到,critical batch size 与 model size 的关系不大,仅与损失 有关。作者通过以下模型拟合 critical batch size:
这里 , .
给定一个 target loss , 当 batch size 时,作者定义最小训练步数为
给定 target loss 和 model size , 当 batch size 时,作者定义最小算力为
Performance with Model Size and Compute
作者使用如下公式来探究损失与 model size 和 computer 之间的关系
拟合结果如下表所示
| Parameter | ||||
|---|---|---|---|---|
| Value | 0.077 | 0.76 |
基于这个拟合结果,作者得到了下图的结果
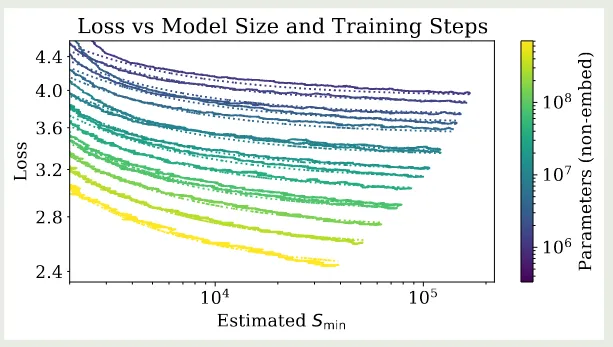
作者还使用了不同的可视化方式,如下图所示
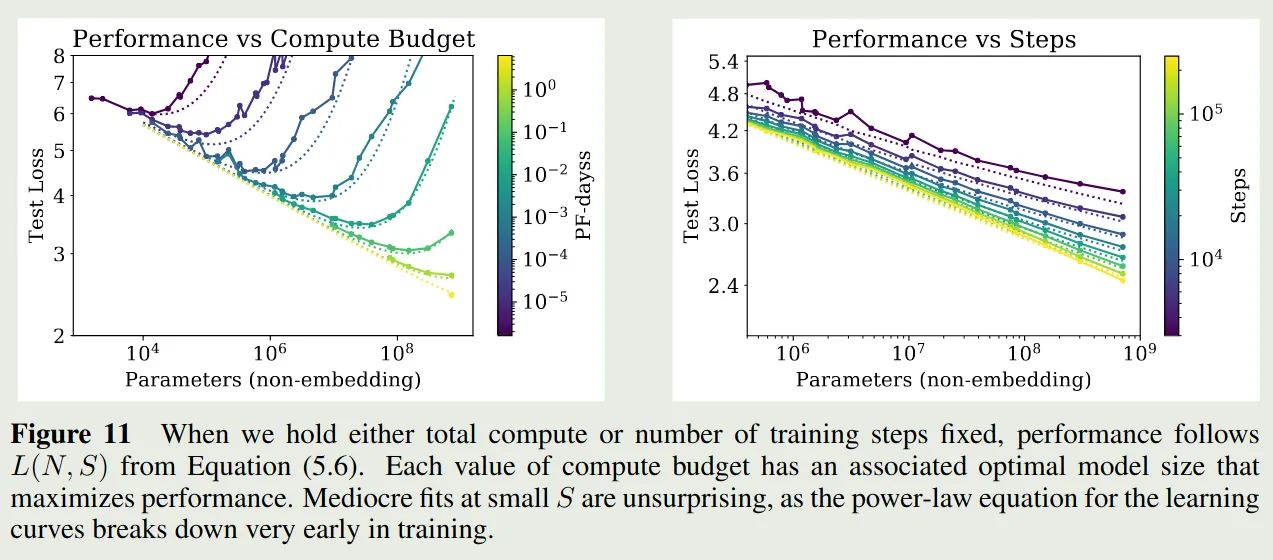
实验结果显示,上面的公式拟合的很好。
Lower Bound on Early Stopping step
作者还探究了以下 early step 与模型大小以及数据集之间的关系,作者通过分析得到如下结果
其中 是在充分大数据集上的收敛损失。作者对实验结果进行了拟合,结果如下图所示
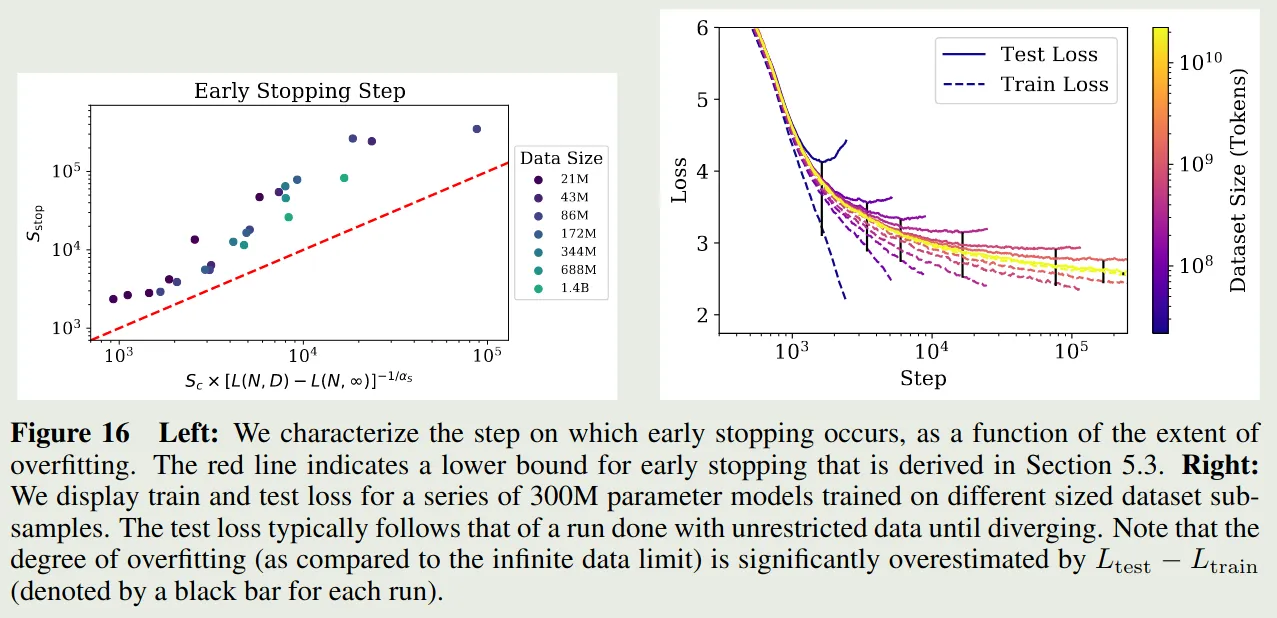
Optimal Allocation of the Compute Budget
作者在本节探究了最优算力与 model size 和训练数据 之间的关系
Optimal Performance and Allocations
作者首先基于
绘制了如下曲线图
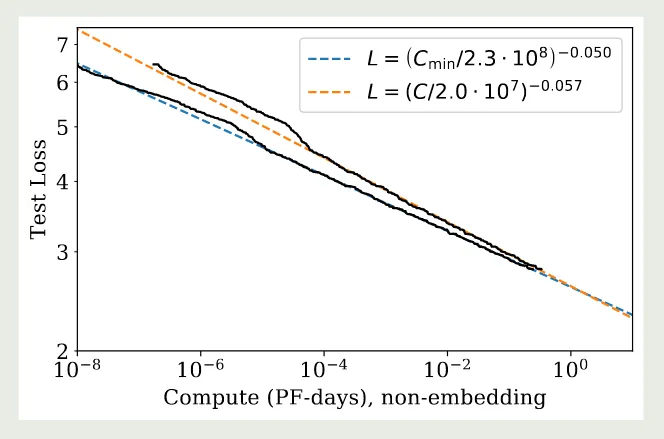
作者发现,相比于 loss 与算力 之间的关系,使用 进行拟合效果更好。
接下来,作者基于 进一步探究了给定算力如何决定最优的 model size . 其实验结果如下图所示
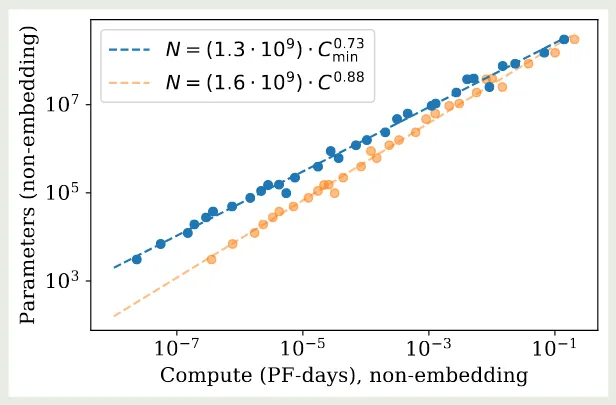
实验结果显示,model size 和算力之间有如下关系
作者进一步探究了对于非最优模型大小与算力之间的关系,作者先构建了如下的关系
对应的示意图为
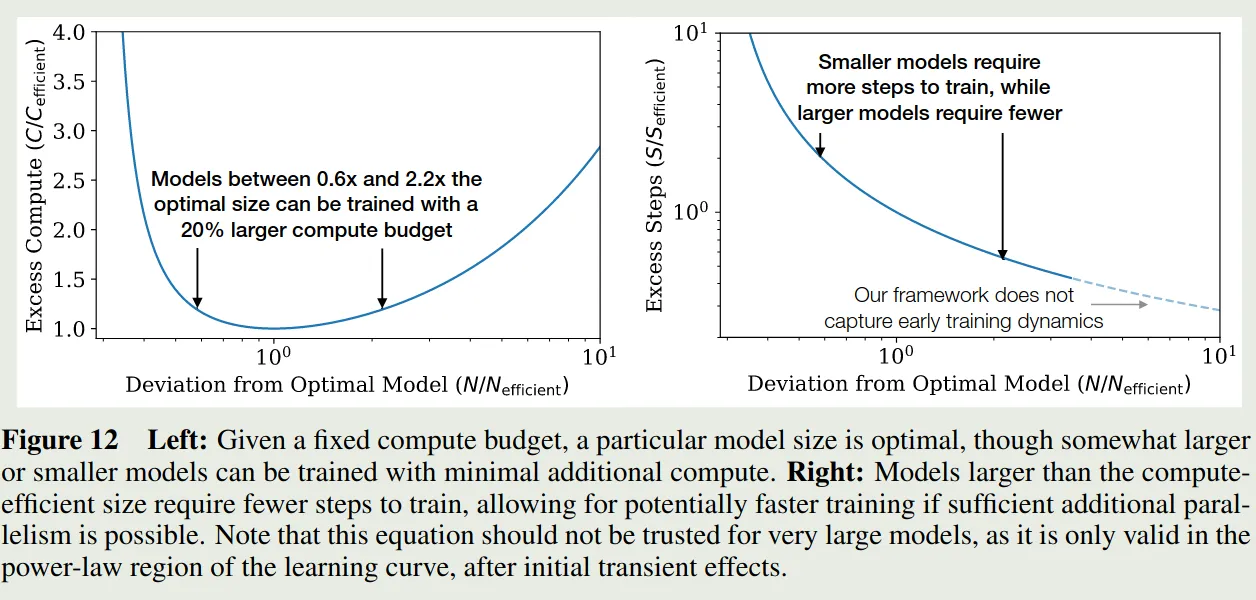
实现结果发现,大小为最优模型的 倍只需要额外 的算力。作者强调,这个实验结果对于超大模型不一定适用。
作者进一步推导了 和 之间的关系,由于 , 且我们前面已经有 和 , 因此 我们有
以及
拟合的结果如下图所示
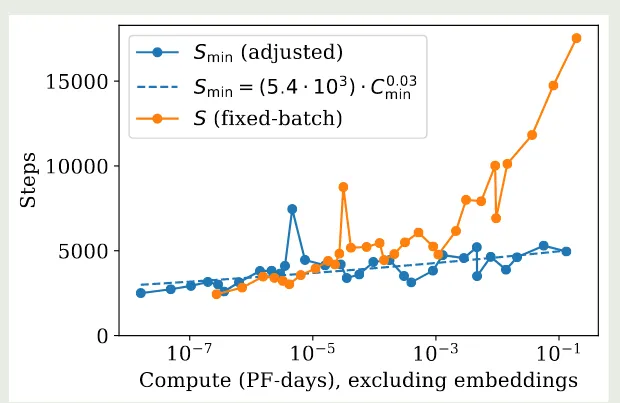
因此,基于上面的结果,当我们增加算力时,我们的主要精力应该放在增加模型大小和提高 batch size 上,而训练步数基本可以保持不变。
Another way of Derivation
作者还给出了另一种建模 的方式,即从 中进行推导,作者将 和 的表达式带入到 然后求解最小值就得到
其中
这和前面的结果基本是吻合的,进一步进行推导得到
这个结果也和上面的差不多。
Contradiction and a Conjecture
作者发现,尽管拟合的 scaling law 曲线非常好,但是由于自然语言不可能达到 zero entropy, 因此该曲线最终一定会失效。作者基于更大的模型进行了实验,结果发现,模型在某一点开始就比预测的损失曲线下降的更慢。作者认为这是因为 transformer 模型已经达到了 maximal performance 导致的。
通过前面的分析,我们发现 比 下降的快,因此两者必然在某一点相交。
在前面的章节中,我们基于以下关系来决定数据集大小
这里我们利用了 的结果
另一方面,我们有
可以看到,基于训练最优导出的数据集大小相比于拟合出来的数据集大小,实际上存在过拟合。
作者进一步分析出了 和 这两条曲线的交点,结果得到
作者认为出现这种原因有以下几种情况:
- 给出了自然语言的 entropy 的一个估计,因此当模型充分大之后,模型可能已经获取到了数据中的所有知识
- 可以作为数据集噪声的一个量化表现,其衡量了数据集的质量
Learning Rate Schedule
附录中,作者还探究了 learning rate 与损失之间的关系,作者使用了不同 learning rate schedule 对模型损失的影响,结果如下图所示
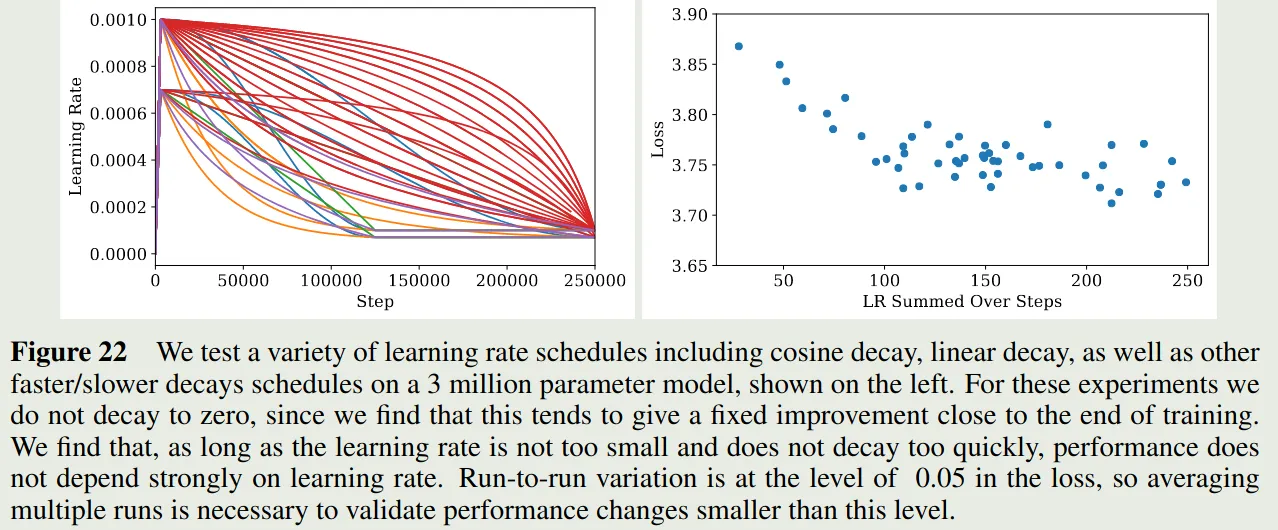
实验结果显示,只要 learning rate 下降的不会太快,模型的表现基本上差不太多。
作者基于实验结果得到了学习率和模型参数之间的关系如下
也就是说,小模型用比较大的学习率,大模型用较小的学习率。
Conclusion
作者在本文中训练了大量不同配置的大模型,然后构建了损失(损失)与模型参数,数据及大小以及算力之间的关系。实验结果发现,损失与架构和优化参数之间的关系比较小,主要由模型参数量决定,更大的模型拥有更高的采样效率。
作者认为,本文的局限在于损失函数不一定能够反应模型在其他语言任务上的表现。