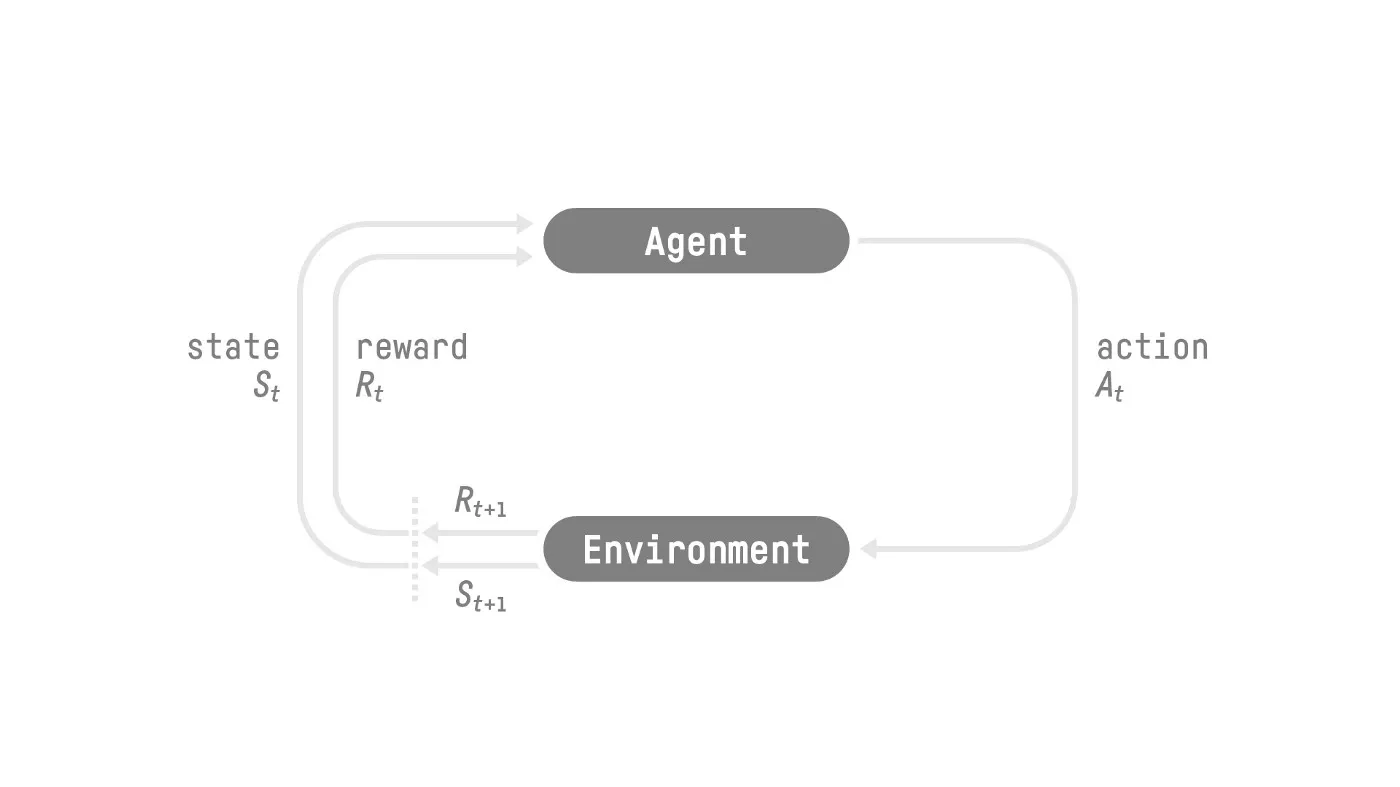
RL 的基本思想是通过与环境进行交互,获取奖励来进行学习
RL 的定义如下
强化学习是一个通过构建可以与环境进行交互的 agent 来解决控制和决策任务的学习框架,交互的方式为 agent 执行 action, 然后环境给予奖励
RL 的执行过程如下所示
RL 的数学建模依赖于 Markov decision process, 下面我们先介绍相关概念
一个 Markov decision process (MDP) 包含如下模块:
时间 t = 0 , 1 , … , T t=0,1,\dots,T t = 0 , 1 , … , T
状态 s t ∈ S ∪ { ⟨ t e r m ⟩ } s_t\in\mathcal{S}\cup\{\langle term\rangle\} s t ∈ S ∪ {⟨ t er m ⟩} S \mathcal{S} S
动作 a t ∈ A a_t\in\mathcal{A} a t ∈ A A \mathcal{A} A
奖励 r t ∈ R r_t\in\mathbb{R} r t ∈ R a t a_t a t
终止时间 T T T s T = ⟨ t e r m ⟩ s_T=\langle term\rangle s T = ⟨ t er m ⟩
初始状态分布 s o ∼ p 0 s_o\sim p_0 s o ∼ p 0
转换概率 (transition probability): r t , s t + 1 ∼ p ( ⋅ , ⋅ ∣ s t , a t ) r_t,s_{t+1}\sim p(\cdot,\cdot\mid s_t,a_t) r t , s t + 1 ∼ p ( ⋅ , ⋅ ∣ s t , a t )
轨迹 τ = ( s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , … , s T − 1 , a T − 1 , r T − 1 , s T ) \tau=(s_0,a_0,r_0,s_1,a_1,r_1,\dots,s_{T-1},a_{T-1}, r_{T-1}, s_T) τ = ( s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , … , s T − 1 , a T − 1 , r T − 1 , s T )
Markov property . t + 1 t+1 t + 1 t t t p ( s t + 1 ∣ s t , a t , … , a 0 , a 0 ) = p ( s t + 1 ∣ s t , a t ) p(s_{t+1}\mid s_t,a_t,\dots,a_0,a_0)=p(s_{t+1}\mid s_t,a_t) p ( s t + 1 ∣ s t , a t , … , a 0 , a 0 ) = p ( s t + 1 ∣ s t , a t ) p ( r t ∣ s t , a t , … , s 0 , a t ) = p ( r t ∣ s t , a t ) p(r_{t}\mid s_t,a_t,\dots,s_0,a_t)=p(r_t\mid s_t,a_t) p ( r t ∣ s t , a t , … , s 0 , a t ) = p ( r t ∣ s t , a t )
我们会对一些表达式进行简化:
当 r t r_t r t ( s t , a t ) (s_t,a_t) ( s t , a t ) r t = r ( s t , a t ) r_t=r(s_t,a_t) r t = r ( s t , a t )
我们假设状态转移函数是平稳的 (stationary), 即 p t ( r , s ′ ∣ s , a ) = p ( r , s ′ ∣ s , a ) p_t(r,s'\mid s,a)=p(r,s'\mid s,a) p t ( r , s ′ ∣ s , a ) = p ( r , s ′ ∣ s , a )
a t a_t a t π \pi π π \pi π s t s_t s t a t = π ( s t ) a_t=\pi(s_t) a t = π ( s t ) a t a_t a t π \pi π a t ∼ π ( ⋅ ∣ s t ) a_t\sim\pi(\cdot\mid s_t) a t ∼ π ( ⋅ ∣ s t ) 一般我们会使用一个神经网络来表示 π \pi π π = π θ \pi=\pi_\theta π = π θ θ \theta θ
我们可以将轨迹写为如下形式
p ( τ ∣ s 0 , π , p ) = p 0 ( s 0 ) ∏ i = 1 T − 1 π ( a t ∣ s t ) p ( r t , s t + 1 ∣ r t , s t ) p(\tau\mid s_0, \pi, p) = p_0(s_0)\prod_{i=1}^{T-1}\pi(a_t\mid s_t)p(r_t, s_{t+1}\mid r_t,s_t) p ( τ ∣ s 0 , π , p ) = p 0 ( s 0 ) i = 1 ∏ T − 1 π ( a t ∣ s t ) p ( r t , s t + 1 ∣ r t , s t ) state and observation
通常来说,state 包含了当前进行决策所需要的所有信息(环境信息,历史信息,agent 自身信息),这种情况下 MDP 的 Markov 性质成立。实际上 agent 获取的可能只是一部分信息,即 agent 获取的为 observation, 这种情况下 MDP 特化为 Partially Observable Markov Decision Process (POMDP), 此时我们的 Markov 性质就不再对 observation 成立,我们的问题也变的更加困难。
Takeaway
State 表示整个环境的完整表示,而 observation 则是环境的部分表示
对于 LLM 来说,我们可以获取历史状态的所有信息,因此我们可以将 RL for LLM 视作一个 MDP 问题。
action space
action space A \mathcal{A} A
episodic and continuing
根据任务的终止时间 T T T T = ∞ T=\infty T = ∞
除了 POMDP 之外,MDP 也有一些其他的推广形式:
non-stationary dynamics, 即不同时间步的状态转移函数不同
pre-determined terminal time T T T p T − 1 ( ⟨ t e r m ⟩ ∣ s T − 1 , a T − 1 ) = 1 p_{T-1}(\langle term\rangle\mid s_{T-1}, a_{T-1})=1 p T − 1 (⟨ t er m ⟩ ∣ s T − 1 , a T − 1 ) = 1 p t + 1 ( ⟨ t e r m ⟩ ∣ s t , a t ) = 0 p_{t+1}(\langle term\rangle\mid s_{t}, a_{t})=0 p t + 1 (⟨ t er m ⟩ ∣ s t , a t ) = 0 ∀ t ∈ [ T − 2 ] \forall t\in[T-2] ∀ t ∈ [ T − 2 ]
policy π t \pi_t π t
actions may depend on states, 即 a t ∈ A ( s t ) a_t\in\mathcal{A}(s_t) a t ∈ A ( s t )
由于 T T T E [ ∑ t = 0 T ⋅ ] ≠ ∑ t = 0 T E [ ⋅ ] \mathbb{E}[\sum_{t=0}^T\cdot]\neq\sum_{t=0}^T\mathbb{E}[\cdot] E [ ∑ t = 0 T ⋅ ] = ∑ t = 0 T E [ ⋅ ]
为了简化,我们一般会使用一个等价的,不会停止的 MDP:
the MDP never stops, 即 T = ∞ T=\infty T = ∞
s t ∈ S ∪ { ⟨ t e r m ⟩ } s_t\in\mathcal{S}\cup\{\langle term\rangle\} s t ∈ S ∪ {⟨ t er m ⟩} ⟨ t e r m ⟩ \langle term\rangle ⟨ t er m ⟩ absorbing state: 当 s t = ⟨ t e r m ⟩ s_t=\langle term\rangle s t = ⟨ t er m ⟩ r t = 0 , s t + 1 = ⟨ t e r m ⟩ r_t=0, s_{t+1}=\langle term\rangle r t = 0 , s t + 1 = ⟨ t er m ⟩ ⟨ t e r m ⟩ \langle term\rangle ⟨ t er m ⟩
π ( ⋅ ∣ ⟨ t e r m ⟩ ) \pi(\cdot\mid\langle term\rangle) π ( ⋅ ∣ ⟨ t er m ⟩)
RL 的最终目标为最大化累计奖励,称为 expected return, 这个目标基于reward hypothesis , 即所有的目标都可以被描述为最大化 expected return . 目标函数表达式如下
max π E s 0 ∼ p 0 π [ ∑ t = 0 T − 1 r t ] \max_{\pi}\quad \mathbb{E}_{s_0\sim p_0}^\pi\left[\sum_{t=0}^{T-1}r_t\right] π max E s 0 ∼ p 0 π [ t = 0 ∑ T − 1 r t ] 由于未来存在不确定性,我们会对这种不确定性施加惩罚,即时间越远,其对于当前的 reward 就越低,这其实就是经济学中的现值 (present value, PV), 因此我们实际上优化的目标函数是 expected discounted return:
max π E s 0 ∼ p 0 π [ ∑ t = 0 T − 1 γ t r t ] \max_{\pi}\quad \mathbb{E}_{s_0\sim p_0}^\pi\left[\sum_{t=0}^{T-1}\gamma^tr_t\right] π max E s 0 ∼ p 0 π [ t = 0 ∑ T − 1 γ t r t ] 这里 γ ∈ ( 0 , 1 ] \gamma \in (0, 1] γ ∈ ( 0 , 1 ]
G t = r t + γ r t + 1 + ⋯ + γ T − 1 − t r T − 1 = ∑ t ′ = t T − 1 γ t ′ − t r t ′ G_t = r_t +\gamma r_{t+1}+\cdots+\gamma^{T-1-t}r_{T-1}=\sum_{t'=t}^{T-1}\gamma^{t'-t}r_{t'} G t = r t + γ r t + 1 + ⋯ + γ T − 1 − t r T − 1 = t ′ = t ∑ T − 1 γ t ′ − t r t ′ G t G_t G t discounted return .
注意
这里的期望 E s 0 ∼ p 0 π \mathbb{E}_{s_0\sim p_0}^\pi E s 0 ∼ p 0 π a t ∼ π ( ⋅ ∣ s t ) a_t\sim\pi(\cdot\mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t,s_{t+1})\sim p(\cdot,\cdot\mid s_t,a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t )
我们将 LLM 记为 p θ p_{\theta} p θ θ \theta θ x x x x x x y i y_i y i
y i ∼ p ( y ∣ y < i , x ) y_i \sim p(y\mid y_{<i}, x) y i ∼ p ( y ∣ y < i , x ) RL 和 LLM 的对应关系如下
注意到我们并没有对 environment 进行建模,我们可以这样进行理解:
LLM 中的 environment 仅仅是对 token 进行简单拼接
environment 承担了 reward model + 文本世界的功能,其中奖励由 reward model 给定或者人类反馈,且 environment 使用 <eos> 来标记终止条件
在本节中,我们介绍了 RL 的基本定义,RL 的核心在于其 Markov 性质。我们还介绍了 RL 中的核心假设,即所有的目标都可以使用 reward 量化。最后我们从 RL 的角度来对 LLM 进行建模
本节中,我们将要定义 value function, Q-function 以及这两个函数与 policy 之间的关系,这是我们介绍不同 RL 算法的基础
我们定义 Value function 如下:
V π ( s ) = E π [ G 0 ∣ s 0 = s ] V^{\pi}(s) = \mathbb{E}^{\pi}[G_0\mid s_0=s] V π ( s ) = E π [ G 0 ∣ s 0 = s ] value function 的具体含义为:agent 从当前状态 s s s π \pi π .
state-action value function, 或者 Q-value function 定义如下:
Q π ( s , a ) = E π [ G 0 ∣ s 0 = s , a 0 = a ] Q^{\pi}(s,a) = \mathbb{E}^{\pi}[G_0\mid s_0=s, a_0=a] Q π ( s , a ) = E π [ G 0 ∣ s 0 = s , a 0 = a ] 其具体含义为:agent 从当前状态 s s s a a a π \pi π .
注意
这里为了方便,我们令 V π ( ⟨ t e r m ⟩ ) = 0 V^{\pi}(\langle term\rangle)=0 V π (⟨ t er m ⟩) = 0 Q π ( ⟨ t e r m ⟩ , a ) = 0 , ∀ a ∈ A Q^{\pi}(\langle term\rangle,a)=0,\forall a\in\mathcal{A} Q π (⟨ t er m ⟩ , a ) = 0 , ∀ a ∈ A
由全概率公式,我们有
E [ G 0 ∣ s 0 = s ] = ∑ a ∈ A E [ G 0 ∣ s t = s , a 0 = a ] π ( a ∣ s 0 = s ) \mathbb{E}[G_0\mid s_0=s] = \sum_{a\in\mathcal{A}}\mathbb{E}\left[G_0\mid s_t=s, a_0=a\right]\pi(a\mid s_0=s) E [ G 0 ∣ s 0 = s ] = a ∈ A ∑ E [ G 0 ∣ s t = s , a 0 = a ] π ( a ∣ s 0 = s ) 即
V π ( s ) = E a 0 ∼ π ( ⋅ ∣ s 0 ) [ Q π ( s , a ) ] \boxed{V^{\pi}(s) = \mathbb{E}_{a_0\sim \pi(\cdot\mid s_0)}[Q^{\pi}(s,a)]} V π ( s ) = E a 0 ∼ π ( ⋅ ∣ s 0 ) [ Q π ( s , a )] 一般来说,我们会使用 value function 和 Q-value function 的如下递推性质:
V π ( s ) = E a 0 ∼ π ( ⋅ ∣ s ) , ( r 0 , s 0 ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] Q π ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) , a ′ ∼ π ( ⋅ ∣ s ′ ) [ r + γ Q π ( s ′ , a ′ ) ∣ s , a ] \boxed{
\begin{aligned}V^\pi(s) &= \mathbb{E}_{a_0\sim \pi(\cdot\mid s),\ (r_0,s_0)\sim p(\cdot,\cdot\mid s,a_0)}[r_0 + \gamma V^\pi(s_1)\mid s_0=s]\\
Q^\pi(s,a) &= \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a),\ a'\sim \pi(\cdot\mid s')}[r + \gamma Q^\pi(s',a')\mid s,a]
\end{aligned}} V π ( s ) Q π ( s , a ) = E a 0 ∼ π ( ⋅ ∣ s ) , ( r 0 , s 0 ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) , a ′ ∼ π ( ⋅ ∣ s ′ ) [ r + γ Q π ( s ′ , a ′ ) ∣ s , a ] 证明需要利用 Markov property:
V π ( s ) = E π [ r 0 + γ ∑ t = 1 T − 1 γ t − 1 r t ∣ s 0 = s ] = E π [ r 0 + γ G 1 ∣ s 0 = s ] = E a 0 ∼ π ( ⋅ ∣ s , ( r 0 , s 0 ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ E π [ r 0 + γ G 1 ∣ s 0 , a 0 , r 0 , s 1 ] ∣ s 0 = s ] = E a 0 ∼ π ( ⋅ ∣ s , ( r 0 , s 0 ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r 0 + γ E π [ G 1 ∣ s 1 ] ∣ s 0 = s ] = E a 0 ∼ π ( ⋅ ∣ s , ( r 0 , s 0 ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r 0 + γ V π [ s 1 ) ∣ s 0 = s ] \begin{aligned}
V^{\pi}(s) &= \mathbb{E}^{\pi}\left[r_0 + \gamma\sum_{t=1}^{T-1}\gamma^{t-1}r_t\mid s_0=s\right]\\
&= \mathbb{E}^{\pi}[r_0+\gamma G_1\mid s_0=s]\\
&= \mathbb{E}_{a_0\sim \pi(\cdot\mid s,\ (r_0,s_0)\sim p(\cdot,\cdot\mid s,a_0))}\left[\mathbb{E}^\pi[r_0 + \gamma G_1\mid s_0,a_0,r_0,s_1]\mid s_0=s\right]\\
&= \mathbb{E}_{a_0\sim \pi(\cdot\mid s,\ (r_0,s_0)\sim p(\cdot,\cdot\mid s,a_0))}\left[r_0 + \gamma \mathbb{E}^\pi[G_1\mid s_1]\mid s_0=s\right]\\
&= \mathbb{E}_{a_0\sim \pi(\cdot\mid s,\ (r_0,s_0)\sim p(\cdot,\cdot\mid s,a_0))}\left[r_0 + \gamma V^\pi[s_1)\mid s_0=s\right]
\end{aligned} V π ( s ) = E π [ r 0 + γ t = 1 ∑ T − 1 γ t − 1 r t ∣ s 0 = s ] = E π [ r 0 + γ G 1 ∣ s 0 = s ] = E a 0 ∼ π ( ⋅ ∣ s , ( r 0 , s 0 ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ E π [ r 0 + γ G 1 ∣ s 0 , a 0 , r 0 , s 1 ] ∣ s 0 = s ] = E a 0 ∼ π ( ⋅ ∣ s , ( r 0 , s 0 ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r 0 + γ E π [ G 1 ∣ s 1 ] ∣ s 0 = s ] = E a 0 ∼ π ( ⋅ ∣ s , ( r 0 , s 0 ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r 0 + γ V π [ s 1 ) ∣ s 0 = s ] 对于 Q π ( s , a ) Q^\pi(s,a) Q π ( s , a )
我们接下来介绍 RL 的核心:Bellman equation Theorem, 其阐述了策略 π \pi π
Theorem
令 π \pi π γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}|<\infty ∣ S ∣ < ∞ ∣ r ∣ ≤ R < ∞ , a . s . |r|\leq R<\infty, \mathrm{a.s.} ∣ r ∣ ≤ R < ∞ , a.s. π \pi π V π : S + → R V^\pi:\mathcal{S}^+\to\mathbb{R} V π : S + → R
V π ( s ) = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V ( s ′ ) ∣ s ] \boxed{
V^\pi(s) = \mathbb{E}_{a\sim \pi(\cdot\mid s),\ (r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V(s')\mid s\right]
} V π ( s ) = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V ( s ′ ) ∣ s ]
反之,如果存在函数 V : S + → R V:\mathcal{S}^+\to\mathbb{R} V : S + → R V = V π V=V^\pi V = V π
证明
由 V π V^\pi V π
∣ ∑ t = 0 ∞ γ t r t ∣ ≤ ∑ t = 0 ∞ γ t R = R 1 − γ < ∞ \left|\sum_{t=0}^{\infty}\gamma^tr_t\right|\leq \sum_{t=0}^\infty \gamma^t R=\frac{R}{1-\gamma}<\infty t = 0 ∑ ∞ γ t r t ≤ t = 0 ∑ ∞ γ t R = 1 − γ R < ∞ 因此,∑ t = 0 ∞ γ t r t \sum_{t=0}^{\infty}\gamma^tr_t ∑ t = 0 ∞ γ t r t
对于 V π ( s ) = E π [ G 0 ∣ s 0 = s ] V^\pi(s)=\mathbb{E}^{\pi}[G_0\mid s_0=s] V π ( s ) = E π [ G 0 ∣ s 0 = s ]
V π ( s ) = E π [ G 0 ∣ s 0 = s ] = E π [ r 0 + γ G 1 ∣ s 0 = s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ E π [ r 0 + γ G 1 ∣ s 0 , a 0 , r 0 , s ′ ] ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r 0 + γ E π [ G 1 ∣ s 0 , a 0 , r 0 , s ′ ] ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r 0 + γ E π [ G 1 ∣ s 1 ] ] = E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r 0 + V π ( s ′ ) ] \begin{aligned}
V^\pi(s)&=\mathbb{E}^{\pi}\left[G_0\mid s_0=s\right]\\
&= \mathbb{E}^{\pi}\left[r_0+\gamma G_1\mid s_0=s\right]\\
&=\mathbb{E}_{a\sim\pi(\cdot\mid s), (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[\mathbb{E}^\pi\left[r_0+\gamma G_1\mid s_0,a_0,r_0,s'\right]\right]\\
&= \mathbb{E}_{a\sim\pi(\cdot\mid s), (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r_0+\gamma\mathbb{E}^\pi\left[ G_1\mid s_0,a_0,r_0,s'\right]\right]\\
&= \mathbb{E}_{a\sim\pi(\cdot\mid s), (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r_0+\gamma\mathbb{E}^\pi\left[ G_1\mid s_1\right]\right]\\
&=\mathbb{E}_{a\sim\pi(\cdot\mid s'), (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r_0+V^{\pi}(s')\right]
\end{aligned} V π ( s ) = E π [ G 0 ∣ s 0 = s ] = E π [ r 0 + γ G 1 ∣ s 0 = s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ E π [ r 0 + γ G 1 ∣ s 0 , a 0 , r 0 , s ′ ] ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r 0 + γ E π [ G 1 ∣ s 0 , a 0 , r 0 , s ′ ] ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r 0 + γ E π [ G 1 ∣ s 1 ] ] = E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r 0 + V π ( s ′ ) ] 其中第 5 个等式为 Markov property.
最后,我们证明方程解的唯一性,假设存在函数 V : S + → R V:\mathcal{S}^+\to\mathbb{R} V : S + → R T π \mathcal{T}^\pi T π
( T π V ) ( s ) : = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V ( s ′ ) ∣ s ] (\mathcal{T}^\pi V)(s) := \mathbb{E}_{a\sim \pi(\cdot\mid s),\ (r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V(s')\mid s\right] ( T π V ) ( s ) := E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V ( s ′ ) ∣ s ] 我们证明该算子是一个 contraction mapping, 考虑范数 ∥ V ∥ ∞ = max s ∈ S ∣ V ( s ) ∣ \|V\|_\infty = \max_{s\in\mathcal{S}} |V(s)| ∥ V ∥ ∞ = max s ∈ S ∣ V ( s ) ∣
∣ ( T π V 1 ) ( s ) − ( T π V 2 ) ( s ) ∣ = ∣ E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ γ V 1 π ( s ′ ) − γ V 2 π ( s ′ ) ] ∣ ≤ γ E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ∣ V 1 π ( s ′ ) − V 2 π ( s ′ ) ∣ ≤ γ max s ′ ′ ∈ S ∣ V 1 ( s ′ ′ ) − V 2 ( s ′ ′ ) ∣ = γ ∥ V 1 − V 2 ∥ ∞ \begin{aligned}
\left|(\mathcal{T}^\pi V_1)(s)-(\mathcal{T}^\pi V_2)(s)\right| &= \left|\mathbb{E}_{a\sim\pi(\cdot\mid s'), (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[\gamma V_1^{\pi}(s')-\gamma V_2^{\pi}(s')\right]\right|\\
&\leq \gamma \mathbb{E}_{a\sim\pi(\cdot\mid s'), (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left|V_1^{\pi}(s')-V_2^{\pi}(s')\right|\\
&\leq \gamma \max_{s''\in\mathcal{S}}\left|V_1(s'')-V_2(s'')\right|\\
&= \gamma \left\|V_1-V_2\right\|_\infty
\end{aligned} ∣ ( T π V 1 ) ( s ) − ( T π V 2 ) ( s ) ∣ = E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ γ V 1 π ( s ′ ) − γ V 2 π ( s ′ ) ] ≤ γ E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ∣ V 1 π ( s ′ ) − V 2 π ( s ′ ) ∣ ≤ γ s ′′ ∈ S max ∣ V 1 ( s ′′ ) − V 2 ( s ′′ ) ∣ = γ ∥ V 1 − V 2 ∥ ∞ 上式对于任意 s ∈ S s\in\mathcal{S} s ∈ S
∥ T π V 1 − T π V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ \left\|\mathcal{T}^\pi V_1-\mathcal{T}^\pi V_2\right\|_\infty \leq \gamma \left\|V_1-V_2\right\|_\infty ∥ T π V 1 − T π V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ 由于 γ < 1 \gamma < 1 γ < 1 T π \mathcal{T}^\pi T π
根据不动点定理,已知 V π V^\pi V π V = V π V=V^\pi V = V π ■ \blacksquare ■
同理,我们可以推导出关于 Q-function 的 Bellman equation:
Theorem
令 π \pi π γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}|<\infty ∣ S ∣ < ∞ ∣ A ∣ < ∞ |\mathcal{A}|<\infty ∣ A ∣ < ∞ ∣ r ∣ ≤ R < ∞ , a . s . |r|\leq R<\infty, \mathrm{a.s.} ∣ r ∣ ≤ R < ∞ , a.s. π \pi π Q π : S + × A → R Q^\pi:\mathcal{S}^+\times\mathcal{A}\to\mathbb{R} Q π : S + × A → R
Q π ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) , a ′ ∼ π ( ⋅ ∣ s ′ ) [ r + γ Q ( s ′ , a ′ ) ∣ s , a ] \boxed{
Q^\pi(s, a) = \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a),\ a'\sim \pi(\cdot\mid s')}\left[r+\gamma Q(s', a')\mid s, a\right]
} Q π ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) , a ′ ∼ π ( ⋅ ∣ s ′ ) [ r + γ Q ( s ′ , a ′ ) ∣ s , a ]
反之,如果存在函数 Q : S + × A → R Q:\mathcal{S}^+\times\mathcal{A}\to\mathbb{R} Q : S + × A → R Q = Q π Q=Q^\pi Q = Q π
证明
证明与 value function 的证明基本类似,我们这里略过。
前面介绍了针对一般策略的 Bellman equation, 特别地,对于我们的目标最优策略,我们也可以而推导出对应的 Bellman equation.
首先我们定义最优策略如下
Definition
如果策略 π ∗ \pi^* π ∗
V π ∗ ( s ) ≥ V π ( s ) , ∀ s ∈ S + , ∀ π V^{\pi^*}(s)\geq V^{\pi}(s), \forall s\in\mathcal{S}^+, \forall \pi V π ∗ ( s ) ≥ V π ( s ) , ∀ s ∈ S + , ∀ π
则我们称策略 π ∗ \pi^* π ∗ optimal policy . 对应的 V π ∗ V^{\pi^*} V π ∗ Q π ∗ Q^{\pi^*} Q π ∗ optimal value function 以及 optimal Q-function , 我们简记为 V ∗ = V π ∗ V^*=V^{\pi^*} V ∗ = V π ∗ Q ∗ = Q π ∗ Q^*=Q^{\pi^*} Q ∗ = Q π ∗ s s s V ∗ V^* V ∗ Q ∗ Q^* Q ∗
V ∗ ( s ) = max a ∼ π ∗ Q ∗ ( s , a ) V^*(s) = \max_{a\sim\pi^*} Q^*(s, a) V ∗ ( s ) = a ∼ π ∗ max Q ∗ ( s , a ) 证明
我们先证明左边小于右边,再证明右边小于左边。
V ∗ ( s ) = E a 0 ∼ π ∗ ( ⋅ ∣ s 0 ) [ Q ∗ ( s , a ) ] ≤ E a 0 ∼ π ∗ ( ⋅ ∣ s 0 ) [ max a ∼ π ∗ Q ∗ ( s , a ) ] = max a ∼ π ∗ Q ∗ ( s , a ) V^*(s) =\mathbb{E}_{a_0\sim \pi^*(\cdot\mid s_0)}[Q^*(s,a)]\leq \mathbb{E}_{a_0\sim \pi^*(\cdot\mid s_0)}[\max_{a\sim\pi^*}Q^*(s,a)] = \max_{a\sim\pi^*} Q^*(s, a) V ∗ ( s ) = E a 0 ∼ π ∗ ( ⋅ ∣ s 0 ) [ Q ∗ ( s , a )] ≤ E a 0 ∼ π ∗ ( ⋅ ∣ s 0 ) [ a ∼ π ∗ max Q ∗ ( s , a )] = a ∼ π ∗ max Q ∗ ( s , a ) 其次,令 a ∗ ∈ arg max a Q ∗ ( s , a ) a^*\in\arg\max_{a}Q^*(s,a) a ∗ ∈ arg max a Q ∗ ( s , a ) π ′ \pi' π ′ π ′ ( a ∗ ∣ s ) = 1 \pi'(a^*\mid s)=1 π ′ ( a ∗ ∣ s ) = 1
max a Q ∗ ( s , a ∗ ) = Q π ′ ( s , a ∗ ) = V π ′ ( s ) ≤ V ∗ ( s ) \max_aQ^*(s,a^*) = Q^{\pi'}(s,a^*)=V^{\pi'}(s)\leq V^*(s) a max Q ∗ ( s , a ∗ ) = Q π ′ ( s , a ∗ ) = V π ′ ( s ) ≤ V ∗ ( s ) 这样,我们就证明了上面的等式。■ \blacksquare ■
Theorem
假设 γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}|<\infty ∣ S ∣ < ∞ ∣ A ∣ < ∞ |\mathcal{A}|<\infty ∣ A ∣ < ∞ ∣ r ∣ ≤ R < ∞ , a . s . |r|\leq R<\infty, \mathrm{a.s.} ∣ r ∣ ≤ R < ∞ , a.s. V π : S + → R V^\pi:\mathcal{S}^+\to\mathbb{R} V π : S + → R Bellman optimality equation :
V ∗ ( s ) = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] \boxed{
V^*(s) = \max_{a\in\mathcal{A}}\mathbb{E}_{\ (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r+\gamma V^*(s')\mid s, a\right]
} V ∗ ( s ) = a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s , a ]
反之,如果存在函数 V : S + → R V:\mathcal{S}^+\to\mathbb{R} V : S + → R V = V ∗ V=V^* V = V ∗
π ∗ ( s ) = arg max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] = arg max a ∈ A Q ∗ ( s , a ) \pi^*(s) = \arg\max_{a\in\mathcal{A}}\mathbb{E}_{\ (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r+\gamma V^*(s')\mid s, a\right]=\arg\max_{a\in\mathcal{A}} Q^*(s,a) π ∗ ( s ) = arg a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] = arg a ∈ A max Q ∗ ( s , a )
是一个 optimal deterministic policy.
证明
我们首先证明存在性,我们定义
( T ∗ V ) ( s ) : = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V ( s ′ ) ∣ s , a ] (\mathcal{T}^* V)(s) := \max_{a\in\mathcal{A}}\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V(s')\mid s, a\right] ( T ∗ V ) ( s ) := a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V ( s ′ ) ∣ s , a ] 我们证明 T ∗ V \mathcal{T}^*V T ∗ V
∣ ( T ∗ V 1 ) ( s ) − ( T ∗ V 2 ) ( s ) ∣ = ∣ max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V 1 ( s ′ ) ∣ s , a ] − max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V 2 ( s ′ ) ∣ s , a ] ∣ ≤ max a ∈ A ∣ E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V 1 ( s ′ ) ∣ s , a ] − E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V 2 ( s ′ ) ∣ s , a ] ∣ = max a ∈ A ∣ E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ γ V 1 ( s ′ ) − V 2 ( s ′ ) ∣ s , a ] − E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V 2 ( s ′ ) ∣ s , a ] ∣ ≤ γ max a ∈ A ∣ E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ V 1 π ( s ′ ) − V 2 π ( s ′ ) ∣ s , a ] ∣ ≤ γ max a ∈ A E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ ∣ V 1 π ( s ′ ) − V 2 π ( s ′ ) ∣ ∣ s , a ] ≤ γ max a ∈ A max s ′ ′ ∈ S ∣ V 1 ( s ′ ′ ) − V 2 ( s ′ ′ ) ∣ = γ ∥ V 1 − V 2 ∥ ∞ \begin{aligned}
\left|(\mathcal{T}^* V_1)(s)-(\mathcal{T}^* V_2)(s)\right| &= \left|\max_{a\in\mathcal{A}}\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V_1(s')\mid s, a\right]- \max_{a\in\mathcal{A}}\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V_2(s')\mid s, a\right]\right|\\
&\leq \max_{a\in\mathcal{A}}\left|\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V_1(s')\mid s, a\right]- \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V_2(s')\mid s, a\right]\right|\\
&= \max_{a\in\mathcal{A}}\left|\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[\gamma V_1(s')-V_2(s')\mid s, a\right]- \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V_2(s')\mid s, a\right]\right|\\
&\leq \gamma \max_{a\in\mathcal{A}}\left|\mathbb{E}_{a\sim\pi(\cdot\mid s'), (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[V_1^{\pi}(s')-V_2^{\pi}(s')\mid s,a\right]\right|\\
&\leq \gamma \max_{a\in\mathcal{A}}\mathbb{E}_{a\sim\pi(\cdot\mid s'), (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[\left|V_1^{\pi}(s')-V_2^{\pi}(s')\right|\mid s,a\right]\\
&\leq \gamma \max_{a\in\mathcal{A}}\max_{s''\in\mathcal{S}}\left|V_1(s'')-V_2(s'')\right|\\
&= \gamma \left\|V_1-V_2\right\|_\infty
\end{aligned} ∣ ( T ∗ V 1 ) ( s ) − ( T ∗ V 2 ) ( s ) ∣ = a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V 1 ( s ′ ) ∣ s , a ] − a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V 2 ( s ′ ) ∣ s , a ] ≤ a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V 1 ( s ′ ) ∣ s , a ] − E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V 2 ( s ′ ) ∣ s , a ] = a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ γ V 1 ( s ′ ) − V 2 ( s ′ ) ∣ s , a ] − E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V 2 ( s ′ ) ∣ s , a ] ≤ γ a ∈ A max E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ V 1 π ( s ′ ) − V 2 π ( s ′ ) ∣ s , a ] ≤ γ a ∈ A max E a ∼ π ( ⋅ ∣ s ′ ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ ∣ V 1 π ( s ′ ) − V 2 π ( s ′ ) ∣ ∣ s , a ] ≤ γ a ∈ A max s ′′ ∈ S max ∣ V 1 ( s ′′ ) − V 2 ( s ′′ ) ∣ = γ ∥ V 1 − V 2 ∥ ∞ 这里第一个不等式我们使用了结论
∣ max s v ( s ) − max s u ( s ) ∣ ≤ max s ∣ u ( s ) − v ( s ) ∣ \left|\max_s v(s)-\max_s u(s)\right|\leq \max_s|u(s)-v(s)| s max v ( s ) − s max u ( s ) ≤ s max ∣ u ( s ) − v ( s ) ∣ 上式对于任意 s ∈ S s\in\mathcal{S} s ∈ S
∥ T ∗ V 1 − T ∗ V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ \left\|\mathcal{T}^* V_1-\mathcal{T}^* V_2\right\|_\infty \leq \gamma \left\|V_1-V_2\right\|_\infty ∥ T ∗ V 1 − T ∗ V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ 由于 γ < 1 \gamma < 1 γ < 1 T ∗ \mathcal{T}^* T ∗
根据不动点定理,T ∗ \mathcal{T}^* T ∗ V ∗ V^* V ∗
接下来,我们定义 π ∗ \pi^* π ∗
π ∗ ( s ) = arg max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] \pi^*(s) = \arg\max_{a\in\mathcal{A}}\mathbb{E}_{\ (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r+\gamma V^*(s')\mid s, a\right] π ∗ ( s ) = arg a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] 此时,我们有
V ∗ ( s ) = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] = E a ∼ π ∗ ( s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s ] = E π ∗ [ r 0 + γ V ∗ ( s 1 ) ∣ s 0 = s ] = E π ∗ [ r 0 + γ E π ∗ [ r 1 + γ V ∗ ( s 2 ) ∣ s 0 = s 1 ] ∣ s 0 = s ] = E π ∗ [ r 0 + γ E π ∗ [ r 1 + γ V ∗ ( s 2 ) ∣ s 0 = s 1 , r 0 ] ∣ s 0 = s ] = E π ∗ [ E π ∗ [ r 0 + γ ( r 1 + γ V ∗ ( s 2 ) ) ∣ s 0 = s 1 , r 0 ] ∣ s 0 = s ] = E π ∗ [ r 0 + γ r 1 + γ 2 V ∗ ( s 2 ) ∣ s 0 = s ] = E π ∗ [ r 0 + γ r 1 + γ 2 r 2 + ⋯ ∣ s 0 = s ] = V π ∗ ( s ) \begin{aligned}
V^*(s) &= \max_{a\in\mathcal{A}}\mathbb{E}_{\ (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r+\gamma V^*(s')\mid s, a\right]\\
&= \mathbb{E}_{a\sim\pi^*(s),\ (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r+\gamma V^*(s')\mid s\right]\\
&= \mathbb{E}^{\pi^*}\left[r_0+\gamma V^*(s_1)\mid s_0=s\right]\\
&= \mathbb{E}^{\pi^*}\left[r_0+\gamma \mathbb{E}^{\pi^*}\left[r_1+\gamma V^*(s_2)\mid s_0=s_1\right]\\\mid s_0=s\right]\\
&= \mathbb{E}^{\pi^*}\left[r_0+\gamma \mathbb{E}^{\pi^*}\left[r_1+\gamma V^*(s_2)\mid s_0=s_1, r_0\right]\\\mid s_0=s\right]\\
&= \mathbb{E}^{\pi^*}\left[\mathbb{E}^{\pi^*}\left[r_0+\gamma (r_1+\gamma V^*(s_2))\mid s_0=s_1, r_0\right]\\\mid s_0=s\right]\\
&= \mathbb{E}^{\pi^*}\left[r_0+\gamma r_1+\gamma^2 V^*(s_2)\mid s_0=s\right]\\
&= \mathbb{E}^{\pi^*}\left[r_0+\gamma r_1+\gamma^2r_2+\cdots\mid s_0=s\right]\\
&= V^{\pi^*}(s)
\end{aligned} V ∗ ( s ) = a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] = E a ∼ π ∗ ( s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V ∗ ( s ′ ) ∣ s ] = E π ∗ [ r 0 + γ V ∗ ( s 1 ) ∣ s 0 = s ] = E π ∗ [ r 0 + γ E π ∗ [ r 1 + γ V ∗ ( s 2 ) ∣ s 0 = s 1 ] ∣ s 0 = s ] = E π ∗ [ r 0 + γ E π ∗ [ r 1 + γ V ∗ ( s 2 ) ∣ s 0 = s 1 , r 0 ] ∣ s 0 = s ] = E π ∗ [ E π ∗ [ r 0 + γ ( r 1 + γ V ∗ ( s 2 )) ∣ s 0 = s 1 , r 0 ] ∣ s 0 = s ] = E π ∗ [ r 0 + γ r 1 + γ 2 V ∗ ( s 2 ) ∣ s 0 = s ] = E π ∗ [ r 0 + γ r 1 + γ 2 r 2 + ⋯ ∣ s 0 = s ] = V π ∗ ( s ) 即 V ∗ = V π ∗ V^*=V^{\pi^*} V ∗ = V π ∗
现在我们证明 π ∗ \pi^* π ∗ π \pi π
V π ≤ V ∗ = T ∗ ( V π ) ≤ ( T ∗ ) 2 ( V π ) ≤ ⋯ ≤ ( T ∗ ) k ( V π ) → V ∗ = V π ∗ V^\pi \leq V^*= \mathcal{T}^*(V^\pi)\leq ( \mathcal{T}^*)^2(V^\pi) \leq\cdots\leq (\mathcal{T}^*)^k(V^\pi) \to V^*=V^{\pi^*} V π ≤ V ∗ = T ∗ ( V π ) ≤ ( T ∗ ) 2 ( V π ) ≤ ⋯ ≤ ( T ∗ ) k ( V π ) → V ∗ = V π ∗ 这里第一个等式是 Bellman equation, 第一个不等式是由于下面的 Lemma,最后的极限使用了不动点定理。因此我们有 V π ≤ V ∗ V^\pi\leq V^* V π ≤ V ∗ π ∗ \pi^* π ∗ V ∗ V^* V ∗ ■ \blacksquare ■
Lemma
令 π \pi π T π \mathcal{T}^\pi T π T ∗ \mathcal{T}^* T ∗ V : S + → R V:\mathcal{S}^+\to\mathbb{R} V : S + → R
T π ( V ) ≤ T ∗ ( V ) \mathcal{T}^\pi(V) \leq \mathcal{T}^*(V) T π ( V ) ≤ T ∗ ( V )
进一步,对任意 U : S + → R U:\mathcal{S}^+\to\mathbb{R} U : S + → R V : S + → R V:\mathcal{S}^+\to\mathbb{R} V : S + → R U ≤ V U\leq V U ≤ V
T ∗ ( U ) ≤ T ∗ ( V ) \mathcal{T}^*(U) \leq \mathcal{T}^*(V) T ∗ ( U ) ≤ T ∗ ( V ) 证明
T π ( V ) ( s ) = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V ( s ′ ) ∣ s ] ≤ E a ∼ π ( ⋅ ∣ s ) [ max a ′ E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ ) [ r + γ V ( s ′ ) ∣ s ] ] = max a ′ E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ ) [ r + γ V ( s ′ ) ∣ s ] = T ∗ ( V ) \begin{aligned}
\mathcal{T}^\pi(V)(s) &= \mathbb{E}_{a\sim \pi(\cdot\mid s),\ (r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V(s')\mid s\right]\\
&\leq \mathbb{E}_{a\sim \pi(\cdot\mid s)}\left[\max_{a'} \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a')}\left[r+\gamma V(s')\mid s\right]\right]\\
&= \max_{a'} \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a')}\left[r+\gamma V(s')\mid s\right]\\
&= \mathcal{T}^*(V)
\end{aligned} T π ( V ) ( s ) = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V ( s ′ ) ∣ s ] ≤ E a ∼ π ( ⋅ ∣ s ) [ a ′ max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ ) [ r + γ V ( s ′ ) ∣ s ] ] = a ′ max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ ) [ r + γ V ( s ′ ) ∣ s ] = T ∗ ( V ) 其次,令 a ∗ ∈ arg max a E [ r + γ U ( s ′ ) ] a^*\in\arg\max_{a}\mathbb{E}[r+\gamma U(s')] a ∗ ∈ arg max a E [ r + γ U ( s ′ )]
T ∗ ( U ) ( s ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ ) ) [ r + γ U ( s ′ ) ∣ s ] ≤ E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ ) ) [ r + γ V ( s ′ ) ∣ s ] ≤ max a E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ ) ) [ r + γ V ( s ′ ) ∣ s ] = T ∗ ( V ) \begin{aligned}
\mathcal{T}^*(U)(s) &= \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a'))}\left[r+\gamma U(s')\mid s\right]\\
&\leq \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a'))}\left[r+\gamma V(s')\mid s\right]\\
&\leq \max_a\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a'))}\left[r+\gamma V(s')\mid s\right]\\
&= \mathcal{T}^*(V)
\end{aligned} T ∗ ( U ) ( s ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ )) [ r + γ U ( s ′ ) ∣ s ] ≤ E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ )) [ r + γ V ( s ′ ) ∣ s ] ≤ a max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ′ )) [ r + γ V ( s ′ ) ∣ s ] = T ∗ ( V ) 证毕。 ■ \blacksquare ■
对于 Q-function, 我们也有类似结论
Theorem
假设 γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}|<\infty ∣ S ∣ < ∞ ∣ A ∣ < ∞ |\mathcal{A}|<\infty ∣ A ∣ < ∞ ∣ r ∣ ≤ R < ∞ , a . s . |r|\leq R<\infty, \mathrm{a.s.} ∣ r ∣ ≤ R < ∞ , a.s. Q ∗ : S + × A → R Q^*:\mathcal{S}^+\times\mathcal{A}\to\mathbb{R} Q ∗ : S + × A → R Bellman optimality equation :
Q ∗ ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ max a ′ ∈ A Q ∗ ( s ′ , a ′ ) ∣ s , a ] \boxed{
Q^*(s, a) = \mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a)}\left[r+\gamma \max_{a'\in\mathcal{A}}Q^*(s', a')\mid s, a\right]
} Q ∗ ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ a ′ ∈ A max Q ∗ ( s ′ , a ′ ) ∣ s , a ]
反之,如果存在函数 Q : S + × A → R Q:\mathcal{S}^+\times\mathcal{A}\to\mathbb{R} Q : S + × A → R Q = Q ∗ Q=Q^* Q = Q ∗
证明
证明与 value function 类似,我们这里略过。
首先第一类算法就是根据 Bellman optimality equation 构造得到的 iteration methods. 由前面的分析,我们知道,函数
( T ∗ V ) ( s ) : = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V ( s ′ ) ∣ s , a ] (\mathcal{T}^* V)(s) := \max_{a\in\mathcal{A}}\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V(s')\mid s, a\right] ( T ∗ V ) ( s ) := a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V ( s ′ ) ∣ s , a ] 是一个 contraction mapping, 因此我们可以构造函数序列
V , T ∗ V , ( T ∗ ) 2 V , ⋯ , V, \mathcal{T}^* V, (\mathcal{T}^*)^2 V,\cdots, V , T ∗ V , ( T ∗ ) 2 V , ⋯ , 由不动点定理,我们知道这个序列收敛到 V ∗ V^* V ∗
V k + 1 = T ∗ V k V k + 1 ( s ) = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V k ( s ′ ) ∣ s , a ] π k + 1 ( s ) = arg max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V k ( s ′ ) ∣ s , a ] \begin{aligned}
V^{k+1}&=\mathcal{T}^* V^k\\
V^{k+1}(s) &= \max_{a\in\mathcal{A}}\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V^k(s')\mid s, a\right]\\
\pi^{k+1}(s) &= \arg\max_{a\in\mathcal{A}}\mathbb{E}_{\ (r,s')\sim p(\cdot,\cdot\mid s,a_0)}\left[r+\gamma V^k(s')\mid s, a\right]
\end{aligned} V k + 1 V k + 1 ( s ) π k + 1 ( s ) = T ∗ V k = a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V k ( s ′ ) ∣ s , a ] = arg a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) [ r + γ V k ( s ′ ) ∣ s , a ] 类似地,我们还可以得到 Q-value iteration algorithm
Q k + 1 = T ∗ Q k Q k + 1 ( s ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ max a ′ ∈ A Q k ( s ′ , a ′ ) ∣ s , a ] π k + 1 ( s ) = arg max a ∈ A Q k ( s , a ) \begin{aligned}
Q^{k+1} &=\mathcal{T}^*Q^k\\
Q^{k+1}(s) &=\mathbb{E}_{(r,s')\sim p(\cdot,\cdot\mid s,a)}\left[r+\gamma \max_{a'\in\mathcal{A}}Q^k(s', a')\mid s, a\right]\\
\pi^{k+1}(s) &= \arg\max_{a\in\mathcal{A}}Q^k(s,a)
\end{aligned} Q k + 1 Q k + 1 ( s ) π k + 1 ( s ) = T ∗ Q k = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ a ′ ∈ A max Q k ( s ′ , a ′ ) ∣ s , a ] = arg a ∈ A max Q k ( s , a ) 这一节我们讨论如何评估 (evaluate) 一个 policy. 要评估一个 policy π \pi π V π V^\pi V π
注意到
V π ( s ) = E π [ ∑ t = 0 T − 1 γ t r t ∣ s 0 = s ] V^\pi(s) = \mathbb{E}^\pi\left[\sum_{t=0}^{T-1}\gamma^tr_t\mid s_0=s\right] V π ( s ) = E π [ t = 0 ∑ T − 1 γ t r t ∣ s 0 = s ] 我们可以利用 Monte Carlo (MC) 方法来进行估计,即从 s 0 = s s_0=s s 0 = s N N N
{ s , a 0 ( i ) , r 0 ( i ) , … , a T ( i ) − 1 ( i ) , r T ( i ) − 1 ( i ) , s T ( i ) ( i ) } , i = 1 , … , N \{s, a_0^{(i)},r_0^{(i)},\dots,a_{T^{(i)}-1}^{(i)},r_{T^{(i)}-1}^{(i)}, s^{(i)}_{T^{(i)}}\}, i=1,\dots,N { s , a 0 ( i ) , r 0 ( i ) , … , a T ( i ) − 1 ( i ) , r T ( i ) − 1 ( i ) , s T ( i ) ( i ) } , i = 1 , … , N 然后我们使用样本平均来近似期望
V π ( s ) = E π [ ∑ t = 0 T − 1 γ t r t ∣ s 0 = s ] ≈ 1 N ∑ i = 1 N ∑ t = 0 T ( i ) − 1 γ t r t ( i ) V^\pi(s) = \mathbb{E}^\pi\left[\sum_{t=0}^{T-1}\gamma^tr_t\mid s_0=s\right]\approx \frac{1}{N}\sum_{i=1}^N\sum_{t=0}^{T^{(i)}-1}\gamma^tr_t^{(i)} V π ( s ) = E π [ t = 0 ∑ T − 1 γ t r t ∣ s 0 = s ] ≈ N 1 i = 1 ∑ N t = 0 ∑ T ( i ) − 1 γ t r t ( i ) 如果 S \mathcal{S} S s ∈ S s\in\mathcal{S} s ∈ S V π V^\pi V π
当 S \mathcal{S} S V ϕ V_\phi V ϕ V π V^\pi V π
min ϕ L ( ϕ ) = E s ∼ p 0 [ 1 2 ( V ϕ ( s ) − V π ( s ) ) 2 ] \min_{\phi} \mathcal{L}(\phi) =\mathbb{E}_{s\sim p_0}\left[\frac12\left(V_\phi(s)-V^\pi(s)\right)^2\right] ϕ min L ( ϕ ) = E s ∼ p 0 [ 2 1 ( V ϕ ( s ) − V π ( s ) ) 2 ] 对上面的目标函数求导得到
∇ ϕ L ( ϕ ) = E s ∼ p 0 [ ( V ϕ ( s ) − V π ( s ) ) ∇ ϕ V ϕ ( s ) ] = E s ∼ p 0 [ ( V ϕ ( s ) − E π [ ∑ t = 0 T − 1 γ t r t ∣ s 0 = s ] ) ∇ ϕ V ϕ ( s ) ] = E s ∼ p 0 [ E π [ ( V ϕ ( s ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ V ϕ ( s ) ∣ s 0 = s ] ] = E s ∼ p 0 π [ ( V ϕ ( s ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ V ϕ ( s ) ∣ s 0 = s ] \begin{align}
\nabla_\phi \mathcal{L}(\phi) &= \mathbb{E}_{s\sim p_0}\left[\left(V_\phi(s)-V^\pi(s)\right)\nabla_\phi V_\phi(s)\right]\\
&= \mathbb{E}_{s\sim p_0}\left[\left(V_\phi(s)- \mathbb{E}^\pi\left[\sum_{t=0}^{T-1}\gamma^tr_t\mid s_0=s\right]\right)\nabla_\phi V_\phi(s)\right]\\
&=\mathbb{E}_{s\sim p_0}\left[\mathbb{E}^\pi\left[\left(V_\phi(s)- \sum_{t=0}^{T-1}\gamma^tr_t\right)\nabla_\phi V_\phi(s)\mid s_0=s\right]\right]\\
&= \mathbb{E}_{s\sim p_0}^\pi\left[\left(V_\phi(s)- \sum_{t=0}^{T-1}\gamma^tr_t\right)\nabla_\phi V_\phi(s)\mid s_0=s\right]\\
\end{align} ∇ ϕ L ( ϕ ) = E s ∼ p 0 [ ( V ϕ ( s ) − V π ( s ) ) ∇ ϕ V ϕ ( s ) ] = E s ∼ p 0 [ ( V ϕ ( s ) − E π [ t = 0 ∑ T − 1 γ t r t ∣ s 0 = s ] ) ∇ ϕ V ϕ ( s ) ] = E s ∼ p 0 [ E π [ ( V ϕ ( s ) − t = 0 ∑ T − 1 γ t r t ) ∇ ϕ V ϕ ( s ) ∣ s 0 = s ] ] = E s ∼ p 0 π [ ( V ϕ ( s ) − t = 0 ∑ T − 1 γ t r t ) ∇ ϕ V ϕ ( s ) ∣ s 0 = s ] 这样,我们可以结合 SGD 与 MC 来近似 V π V^\pi V π
Algorithm: Value function approximation with MC while not converged:
s 0 ∼ p 0 s_0\sim p_0 s 0 ∼ p 0 t = 0 t=0 t = 0 while s t ≠ ⟨ t e r m ⟩ s_t\neq \langle term\rangle s t = ⟨ t er m ⟩
a t ∼ π ( ⋅ ∣ s t ) a_t\sim \pi(\cdot\mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t,s_{t+1})\sim p(\cdot,\cdot\mid s_t,a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) t ← t + 1 t\gets t+1 t ← t + 1
Set T = t T=t T = t
g = ( V ϕ ( s 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ V ϕ ( s 0 ) g=\left(V_\phi(s_0)- \sum_{t=0}^{T-1}\gamma^tr_t\right)\nabla_\phi V_\phi(s_0) g = ( V ϕ ( s 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ V ϕ ( s 0 ) Update ϕ \phi ϕ g g g
Temporal difference (TD) learning 通过相邻两步的转换关系来近似函数。注意到,
V π ( s ) = E π [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] V^\pi(s) =\mathbb{E}^\pi[r_0 + \gamma V^\pi(s_1)\mid s_0=s] V π ( s ) = E π [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] 与前面的方法类似,我们先采样然后使用 MC 来进行估计
V π ( s ) = E π [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] ≈ 1 N ∑ i = 1 N ( r 0 ( i ) + γ V π ( s 1 ( i ) ) ) V^\pi(s) =\mathbb{E}^\pi[r_0 + \gamma V^\pi(s_1)\mid s_0=s]\approx \frac{1}N\sum_{i=1}^N\left(r_0^{(i)} + \gamma V^\pi(s_1^{(i)})\right) V π ( s ) = E π [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] ≈ N 1 i = 1 ∑ N ( r 0 ( i ) + γ V π ( s 1 ( i ) ) ) 同样的,当 S \mathcal{S} S
min ϕ L ( ϕ ) = E s ∼ p 0 [ 1 2 ( V ϕ ( s ) − V π ( s ) ) 2 ] \min_{\phi} \mathcal{L}(\phi) =\mathbb{E}_{s\sim p_0}\left[\frac12\left(V_\phi(s)-V^\pi(s)\right)^2\right] ϕ min L ( ϕ ) = E s ∼ p 0 [ 2 1 ( V ϕ ( s ) − V π ( s ) ) 2 ] 对应的梯度为
∇ ϕ L ( ϕ ) = E s ∼ p 0 π [ ( V ϕ ( s ) − r 0 − γ V π ( s 1 ) ) ∇ ϕ V ϕ ( s ) ∣ s 0 = s ] \nabla_\phi \mathcal{L}(\phi) =\mathbb{E}_{s\sim p_0}^\pi\left[\left(V_\phi(s)- r_0-\gamma V^\pi(s_1)\right)\nabla_\phi V_\phi(s)\mid s_0=s\right] ∇ ϕ L ( ϕ ) = E s ∼ p 0 π [ ( V ϕ ( s ) − r 0 − γ V π ( s 1 ) ) ∇ ϕ V ϕ ( s ) ∣ s 0 = s ] 但是,这里存在的问题在于,我们使用了 V π ( s 1 ) V^\pi(s_1) V π ( s 1 ) V ϕ V_\phi V ϕ
∇ ϕ L ( ϕ ) ≈ E s ∼ p 0 π [ ( V ϕ ( s ) − r 0 − γ V ϕ ( s 1 ) ) ∇ ϕ V ϕ ( s ) ∣ s 0 = s ] \nabla_\phi \mathcal{L}(\phi) \approx \mathbb{E}_{s\sim p_0}^\pi\left[\left(V_\phi(s)- r_0-\gamma V_\phi(s_1)\right)\nabla_\phi V_\phi(s)\mid s_0=s\right] ∇ ϕ L ( ϕ ) ≈ E s ∼ p 0 π [ ( V ϕ ( s ) − r 0 − γ V ϕ ( s 1 ) ) ∇ ϕ V ϕ ( s ) ∣ s 0 = s ] 这样,我们结合 TD 和 GSD 的算法就变成了
Algorithm: Value function approximation with TD (not correct) while not converged:
s 0 ∼ p 0 s_0\sim p_0 s 0 ∼ p 0 a 0 ∼ π ( ⋅ ∣ s 0 ) a_0\sim\pi(\cdot\mid s_0) a 0 ∼ π ( ⋅ ∣ s 0 ) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) (r_0,s_1)\sim p(\cdot, \cdot\mid s_0,a_0) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 )
y = { r 0 + γ V ϕ ( s 1 ) , if s 1 ≠ ⟨ t e r m ⟩ r 0 otherwise y=\begin{cases}
r_0+\gamma V_\phi(s_1),& \text{if } s_1\neq \langle term\rangle\\
r_0 & \text{otherwise}
\end{cases} y = { r 0 + γ V ϕ ( s 1 ) , r 0 if s 1 = ⟨ t er m ⟩ otherwise
g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) g=(V_{\phi}(s_0)- y)\nabla_\phi V_{\phi}(s_0) g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) Update ϕ \phi ϕ g g g
接下来,我们需要关注如何计算 g g g g = ( V ϕ ( s ) − r 0 − γ V ϕ ( s 1 ) ) ∇ ϕ V ϕ ( s ) g=\left(V_\phi(s)- r_0-\gamma V_\phi(s_1)\right)\nabla_\phi V_\phi(s) g = ( V ϕ ( s ) − r 0 − γ V ϕ ( s 1 ) ) ∇ ϕ V ϕ ( s )
pred = V_phi(s0) target = r + gamma * V_phi(s1) td_error = pred - target loss = 0.5 * td_error ** 2 loss.backward() 可以看到,我们实际上求的梯度是
∇ ϕ [ 1 2 ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ ) ) ) 2 ] = ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ ) ) ( ∇ ϕ V ϕ ( s ) − ∇ ϕ V ϕ ( s ′ ) ) \nabla_\phi\left[\frac12\left(V_\phi(s)-(r+\gamma V_\phi(s'))\right)^2\right]=(V_\phi(s)-(r+\gamma V_\phi(s'))(\nabla_\phi V_\phi(s)-\nabla_\phi V_\phi(s')) ∇ ϕ [ 2 1 ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ )) ) 2 ] = ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ )) ( ∇ ϕ V ϕ ( s ) − ∇ ϕ V ϕ ( s ′ )) 这显然与 g g g
为了解决这个问题,我们需要使用 stop-gradient 的技巧来避免 V ϕ ( s ′ ) V_\phi(s') V ϕ ( s ′ )
1 2 ( V ϕ ( s ) − ( r + γ s g [ V ϕ ( s ′ ) ] ) ) 2 \frac12\left(V_\phi(s)-(r+\gamma\ \mathrm{sg}[V_\phi(s')])\right)^2 2 1 ( V ϕ ( s ) − ( r + γ sg [ V ϕ ( s ′ )]) ) 2 其中 s g [ ⋅ ] \mathrm{sg}[\cdot] sg [ ⋅ ]
s g [ x ] = { x forward pass 0 backward pass \mathrm{sg}[x] = \begin{cases}
x &\text{forward pass}\\
0 &\text{backward pass}
\end{cases} sg [ x ] = { x 0 forward pass backward pass 这样其梯度就是
∇ ϕ [ 1 2 ( V ϕ ( s ) − ( r + γ s g [ V ϕ ( s ′ ) ] ) ) 2 ] = ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ ) ) ∇ ϕ V ϕ ( s ) = g \nabla_\phi\left[\frac12\left(V_\phi(s)-(r+\gamma\ \mathrm{sg}[V_\phi(s')])\right)^2\right]=(V_\phi(s)-(r+\gamma V_\phi(s'))\nabla_\phi V_\phi(s)=g ∇ ϕ [ 2 1 ( V ϕ ( s ) − ( r + γ sg [ V ϕ ( s ′ )]) ) 2 ] = ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ )) ∇ ϕ V ϕ ( s ) = g 对应的 python 代码为
pred = V_phi(s0) target = r + gamma * V_phi(s1) td_error = pred - target.detach() # sop gradient operator loss = 0.5 * td_error ** 2 loss.backward() 最终,我们的算法实现为
Algorithm: Value function approximation with TD while not converged:
s 0 ∼ p 0 s_0\sim p_0 s 0 ∼ p 0 a 0 ∼ π ( ⋅ ∣ s 0 ) a_0\sim\pi(\cdot\mid s_0) a 0 ∼ π ( ⋅ ∣ s 0 ) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) (r_0,s_1)\sim p(\cdot, \cdot\mid s_0,a_0) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 )
y = { r 0 + γ s g [ V ϕ ( s 1 ) ] , if s 1 ≠ ⟨ t e r m ⟩ r 0 otherwise y=\begin{cases}
r_0+\gamma\, \mathrm{sg}[V_\phi(s_1)],& \text{if } s_1\neq \langle term\rangle\\
r_0 & \text{otherwise}
\end{cases} y = { r 0 + γ sg [ V ϕ ( s 1 )] , r 0 if s 1 = ⟨ t er m ⟩ otherwise
g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) g=(V_{\phi}(s_0)- y)\nabla_\phi V_{\phi}(s_0) g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) Update ϕ \phi ϕ g g g
上述这种做法其实是 semi-gradient methods, 这类方法在参数更新时,只计算部分梯度的方法。虽然这种方法牺牲了严格的梯度下降性质,但是其能够保证更好的表现。
我们可以进一步推广 TD 到多步的场景,注意到
V π ( s ) = E π [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] = E π [ r 0 + γ E π [ r 1 + γ V π ( s 1 ) ∣ s 1 ] ∣ s 0 = s ] = E π [ E π [ r 0 + γ r 1 + γ 2 V π ( s 2 ) ∣ s 1 ] ∣ s 0 = s ] \begin{align}
V^\pi(s) &=\mathbb{E}^\pi[r_0 + \gamma V^\pi(s_1)\mid s_0=s]\\
&=\mathbb{E}^\pi[r_0 + \gamma \mathbb{E}^\pi[r_1 + \gamma V^\pi(s_1)\mid s_1]\mid s_0=s]\\
&= \mathbb{E}^\pi[\mathbb{E}^\pi[r_0 + \gamma r_1 + \gamma^2 V^\pi(s_2) \mid s_1] \mid s_0=s]
\end{align} V π ( s ) = E π [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] = E π [ r 0 + γ E π [ r 1 + γ V π ( s 1 ) ∣ s 1 ] ∣ s 0 = s ] = E π [ E π [ r 0 + γ r 1 + γ 2 V π ( s 2 ) ∣ s 1 ] ∣ s 0 = s ] 由重期望定理(Law of Total Expectation):
E π [ E π [ X ∣ s 1 ] ∣ s 0 = s ] = E π [ X ∣ s 0 = s ] \mathbb{E}^\pi[\mathbb{E}^\pi[X \mid s_1] \mid s_0=s] = \mathbb{E}^\pi[X \mid s_0=s] E π [ E π [ X ∣ s 1 ] ∣ s 0 = s ] = E π [ X ∣ s 0 = s ] 因此:
V π ( s ) = E π [ r 0 + γ r 1 + γ 2 V π ( s 2 ) ∣ s 0 = s ] V^\pi(s) = \mathbb{E}^\pi[r_0 + \gamma r_1 + \gamma^2 V^\pi(s_2) \mid s_0=s] V π ( s ) = E π [ r 0 + γ r 1 + γ 2 V π ( s 2 ) ∣ s 0 = s ] 重复这个过程 k 次,得到 k 步展开:
V π ( s ) = E π [ ∑ i = 0 k − 1 γ i r i + γ k V π ( s k ) ∣ s 0 = s ] \begin{align} V^\pi(s) &= \mathbb{E}^\pi\left[\sum_{i=0}^{k-1} \gamma^i r_i + \gamma^k V^\pi(s_k) \mid s_0=s\right] \end{align} V π ( s ) = E π [ i = 0 ∑ k − 1 γ i r i + γ k V π ( s k ) ∣ s 0 = s ] 现在,我们可以基于 k-step transition 构建目标函数
min ϕ L ( ϕ ) = E s ∼ p 0 [ 1 2 ( V ϕ ( s ) − ( ∑ i = 0 k − 1 γ i r i + γ k V π ( s k ) ) ) 2 ] \min_{\phi} \mathcal{L}(\phi) =\mathbb{E}_{s\sim p_0}\left[\frac12\left(V_\phi(s)-\left(\sum_{i=0}^{k-1} \gamma^i r_i + \gamma^k V^\pi(s_k)\right)\right)^2\right] ϕ min L ( ϕ ) = E s ∼ p 0 2 1 ( V ϕ ( s ) − ( i = 0 ∑ k − 1 γ i r i + γ k V π ( s k ) ) ) 2 使用前面分析的方法,我们就可以写出类似的算法
Algorithm: Value function approximation with k-step TD while not converged:
s 0 ∼ p 0 s_0\sim p_0 s 0 ∼ p 0 t = 0 t=0 t = 0 T = ∞ T=\infty T = ∞ for t = 0 , … , k − 1 t=0,\ldots,k-1 t = 0 , … , k − 1
a t ∼ π ( ⋅ ∣ s t ) a_t\sim\pi(\cdot\mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t,s_{t+1})\sim p(\cdot, \cdot\mid s_t,a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t )
y = ∑ t = 0 k − 1 γ t r t + γ k s g [ V ϕ ( s k ) ] y=\sum_{t=0}^{k-1}\gamma^tr_t+\gamma^k \mathrm{sg}[V_\phi(s_k)] y = ∑ t = 0 k − 1 γ t r t + γ k sg [ V ϕ ( s k )] g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) g=(V_{\phi}(s_0)- y)\nabla_\phi V_{\phi}(s_0) g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) Update ϕ \phi ϕ g g g
一般来说,我们会令 k = 5 k=5 k = 5
TD 本质上一种 bootstrapping, 当需要使用 V π V^\pi V π V ϕ V_\phi V ϕ
MC 需要完整的一次采样,但是 TD 可以通过 bootstrap 提高采样效率。
当 V ϕ V_\phi V ϕ V π V^\pi V π
对于 Q-function, 我们也可以设计类似的算法。
对于 MC, 我们有
Q π ( s , a ) = E π [ ∑ t = 0 T − 1 γ t r t ∣ s 0 = s , a 0 = a ] ≈ 1 N ∑ i = 1 N ∑ t = 0 T ( i ) − 1 γ t r t ( i ) Q^{\pi}(s,a) = \mathbb{E}^{\pi}\left[\sum_{t=0}^{T-1}\gamma^tr_t\mid s_0=s, a_0=a\right]\approx \frac1N\sum_{i=1}^N\sum_{t=0}^{T^{(i)}-1}\gamma^tr_t^{(i)} Q π ( s , a ) = E π [ t = 0 ∑ T − 1 γ t r t ∣ s 0 = s , a 0 = a ] ≈ N 1 i = 1 ∑ N t = 0 ∑ T ( i ) − 1 γ t r t ( i ) 当使用模型来近似时,我们的目标函数为
min ϕ L ( ϕ ) = E s ∼ p 0 , a ∼ π ( ⋅ ∣ s ) [ 1 2 ( Q ϕ ( s , a ) − Q π ( s , a ) ) 2 ] \min_{\phi} \mathcal{L}(\phi) =\mathbb{E}_{s\sim p_0, a\sim\pi(\cdot\mid s)}\left[\frac12\left(Q_\phi(s,a)-Q^\pi(s,a)\right)^2\right] ϕ min L ( ϕ ) = E s ∼ p 0 , a ∼ π ( ⋅ ∣ s ) [ 2 1 ( Q ϕ ( s , a ) − Q π ( s , a ) ) 2 ] 对应的梯度
∇ ϕ L ( ϕ ) = E s ∼ p 0 π [ ( Q ϕ ( s 0 , a 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ Q ϕ ( s 0 , a 0 ) ] \nabla_\phi \mathcal{L}(\phi)= \mathbb{E}_{s\sim p_0}^\pi\left[\left(Q_\phi(s_0,a_0)-\sum_{t=0}^{T-1}\gamma^tr_t\right)\nabla_\phi Q_\phi(s_0,a_0)\right] ∇ ϕ L ( ϕ ) = E s ∼ p 0 π [ ( Q ϕ ( s 0 , a 0 ) − t = 0 ∑ T − 1 γ t r t ) ∇ ϕ Q ϕ ( s 0 , a 0 ) ] 下面是对应的算法
MC
Algorithm: Q function approximation with MC while not converged:
s 0 ∼ p 0 s_0\sim p_0 s 0 ∼ p 0 a 0 ∼ π ( ⋅ ∣ s 0 ) a_0\sim\pi(\cdot\mid s_0) a 0 ∼ π ( ⋅ ∣ s 0 ) t = 0 t=0 t = 0 while s t ≠ ⟨ t e r m ⟩ s_t\neq \langle term\rangle s t = ⟨ t er m ⟩
a t ∼ π ( ⋅ ∣ s t ) a_t\sim \pi(\cdot\mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t,s_{t+1})\sim p(\cdot,\cdot\mid s_t,a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) t ← t + 1 t\gets t+1 t ← t + 1
Set T = t T=t T = t
g = ( Q ϕ ( s 0 , a 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ Q ϕ ( s 0 , a 0 ) g=\left(Q_\phi(s_0,a_0)-\sum_{t=0}^{T-1}\gamma^tr_t\right)\nabla_\phi Q_\phi(s_0,a_0) g = ( Q ϕ ( s 0 , a 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ Q ϕ ( s 0 , a 0 ) Update ϕ \phi ϕ g g g
1-step Q-function TD learning
Algorithm: Q function approximation with TD while not converged:
s 0 ∼ p 0 s_0\sim p_0 s 0 ∼ p 0 a 0 ∼ π ( ⋅ ∣ s 0 ) a_0\sim\pi(\cdot\mid s_0) a 0 ∼ π ( ⋅ ∣ s 0 ) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) (r_0,s_1)\sim p(\cdot, \cdot\mid s_0,a_0) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) a 1 ∼ π ( ⋅ ∣ s 1 ) a_1\sim\pi(\cdot\mid s_1) a 1 ∼ π ( ⋅ ∣ s 1 )
y = { r 0 + γ s g [ Q ϕ ( s 1 , a 1 ) ] , if s 1 ≠ ⟨ t e r m ⟩ r 0 otherwise y=\begin{cases}
r_0+\gamma\, \mathrm{sg}[Q_\phi(s_1,a_1)],& \text{if } s_1\neq \langle term\rangle\\
r_0 & \text{otherwise}
\end{cases} y = { r 0 + γ sg [ Q ϕ ( s 1 , a 1 )] , r 0 if s 1 = ⟨ t er m ⟩ otherwise
g = ( Q ϕ ( s 0 , a 0 ) − y ) ∇ ϕ Q ϕ ( s 0 , a 0 ) g=\left(Q_\phi(s_0,a_0)-y\right)\nabla_\phi Q_\phi(s_0,a_0) g = ( Q ϕ ( s 0 , a 0 ) − y ) ∇ ϕ Q ϕ ( s 0 , a 0 ) Update ϕ \phi ϕ g g g
k-step Q-function TD learning
Algorithm: Q function approximation with k-step TD while not converged:
s 0 ∼ p 0 s_0\sim p_0 s 0 ∼ p 0 t = 0 t=0 t = 0 T = ∞ T=\infty T = ∞ for t = 0 , … , k − 1 t=0,\ldots,k-1 t = 0 , … , k − 1
a t ∼ π ( ⋅ ∣ s t ) a_t\sim\pi(\cdot\mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t,s_{t+1})\sim p(\cdot, \cdot\mid s_t,a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t )
y = ∑ t = 0 k − 1 γ t r t + γ k s g [ Q ϕ ( s k , a k ) ] y=\sum_{t=0}^{k-1}\gamma^tr_t+\gamma^k \mathrm{sg}[Q_\phi(s_k,a_k)] y = ∑ t = 0 k − 1 γ t r t + γ k sg [ Q ϕ ( s k , a k )] g = ( Q ϕ ( s 0 , a 0 ) − y ) ∇ ϕ Q ϕ ( s 0 , a 0 ) g=(Q_{\phi}(s_0,a_0)- y)\nabla_\phi Q_{\phi}(s_0,a_0) g = ( Q ϕ ( s 0 , a 0 ) − y ) ∇ ϕ Q ϕ ( s 0 , a 0 ) Update ϕ \phi ϕ g g g
介绍完 policy evaluation 之后,我们可以设计针对 policy 的 policy iteration 算法,其基本思想是交替进行 policy evaluation 和 policy improvement.
Compute V π k and Q π k π k + 1 ( s ) = arg max a ∈ A E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V π k ( s ′ ) ∣ s , a ] \begin{align}
&\text{Compute }V^{\pi^k} \text{ and }Q^{\pi^k}\tag{Policy evaluation}\\
&\pi^{k+1}(s) = \arg\max_{a\in\mathcal{A}}\mathbb{E}_{a\sim \pi(\cdot\mid s),\ (r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V^{\pi^k}(s')\mid s,a\right]\tag{Policy improvement}
\end{align} Compute V π k and Q π k π k + 1 ( s ) = arg a ∈ A max E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V π k ( s ′ ) ∣ s , a ] ( Policy evaluation ) ( Policy improvement ) policy iteration 算法的正确性如下
Theorem
考虑上面的 policy iteration 算法,假设 γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}|<\infty ∣ S ∣ < ∞ ∣ A ∣ < ∞ |\mathcal{A}|<\infty ∣ A ∣ < ∞ ∣ r ∣ ≤ R < ∞ , a . s . |r|\leq R<\infty, \mathrm{a.s.} ∣ r ∣ ≤ R < ∞ , a.s.
V π k + 1 ≥ V π k , k = 1 , 2 , … V^{\pi^{k+1}}\geq V^{\pi^k},k=1,2,\dots V π k + 1 ≥ V π k , k = 1 , 2 , …
并且,存在 K ∈ N K\in\mathbb{N} K ∈ N V π k = V ∗ V^{\pi^k}=V^* V π k = V ∗
证明
由于 V π k + 1 , V π k V^{\pi^{k+1}}, V^{\pi^k} V π k + 1 , V π k
V π k + 1 = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r k + 1 + γ V π k + 1 ( s ′ ) ∣ s ] V π k = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r k + γ V π k ( s ′ ) ∣ s ] \begin{align}
V^{\pi^{k+1}} &= \mathbb{E}_{a\sim \pi(\cdot\mid s),\ (r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r^{k+1}+\gamma V^{\pi^{k+1}}(s')\mid s\right]\\
V^{\pi^{k}} &= \mathbb{E}_{a\sim \pi(\cdot\mid s),\ (r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r^k+\gamma V^{\pi^{k}}(s')\mid s\right]
\end{align} V π k + 1 V π k = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r k + 1 + γ V π k + 1 ( s ′ ) ∣ s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r k + γ V π k ( s ′ ) ∣ s ] 因为
π k + 1 ( s ) = arg max a ∈ A E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 ) ) [ r + γ V π k ( s ′ ) ∣ s , a ] \pi^{k+1}(s) = \arg\max_{a\in\mathcal{A}}\mathbb{E}_{a\sim \pi(\cdot\mid s),\ (r,s')\sim p(\cdot,\cdot\mid s,a_0))}\left[r+\gamma V^{\pi^k}(s')\mid s,a\right] π k + 1 ( s ) = arg a ∈ A max E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a 0 )) [ r + γ V π k ( s ′ ) ∣ s , a ] 我们有
r + γ V π k + 1 ( s ′ ) ≥ r + γ V π k ( s ′ ) r+\gamma V^{\pi^{k+1}}(s') \geq r+\gamma V^{\pi^k}(s') r + γ V π k + 1 ( s ′ ) ≥ r + γ V π k ( s ′ ) 从而 V π k + 1 ≥ V π k V^{\pi^{k+1}}\geq V^{\pi^k} V π k + 1 ≥ V π k ■ \blacksquare ■
value-based methods 的 motivation 就是给当前策略 π \pi π
当 state space 太大或者连续的 state space 时,我们前面的方法就不适用了,我们需要使用模型 V ϕ V_{\phi} V ϕ V π V^{\pi} V π
J ( ϕ ) = E s [ 1 2 ( V π ( s ) − V ϕ ( s ) ) 2 ] J(\phi) = \mathbb{E}_{s}\left[\frac12\left(V^{\pi}(s)-V_{\phi}(s)\right)^2\right] J ( ϕ ) = E s [ 2 1 ( V π ( s ) − V ϕ ( s ) ) 2 ]
Remark
这里我们假设 s ∈ S s\in\mathcal{S} s ∈ S
我们可以使用随机梯度下降法来进行求解,目标函数的梯度为
∇ ϕ J ( ϕ ) = − E s [ ( V π ( s ) − V ϕ ( s ) ) ∇ ϕ V ϕ ( s ) ] \nabla_\phi J(\phi)=-\mathbb{E}_{s}[(V^{\pi}(s)-V_{\phi}(s))\nabla_\phi V_{\phi}(s)] ∇ ϕ J ( ϕ ) = − E s [( V π ( s ) − V ϕ ( s )) ∇ ϕ V ϕ ( s )] 从而随机梯度下降法的形式为
ϕ k + 1 = ϕ k − α k ∇ ϕ J ( ϕ ) ≈ ϕ k + α k ( V π ( s ) − V ϕ ( s ) ) ∇ ϕ V ϕ ( s ) \phi_{k+1} = \phi_k - \alpha_k\nabla_\phi J(\phi)\approx \phi_k + \alpha_k(V^{\pi}(s)-V_{\phi}(s))\nabla_\phi V_{\phi}(s) ϕ k + 1 = ϕ k − α k ∇ ϕ J ( ϕ ) ≈ ϕ k + α k ( V π ( s ) − V ϕ ( s )) ∇ ϕ V ϕ ( s ) 但是现在我们需要计算 V π ( s ) V^{\pi}(s) V π ( s )
第一种方法是使用 MC 来进行近似,即
V π ( s ) = E π [ G 0 ∣ s 0 = s ] ≈ G 0 V^{\pi}(s)= \mathbb{E}^{\pi}[G_0\mid s_0=s]\approx G_0 V π ( s ) = E π [ G 0 ∣ s 0 = s ] ≈ G 0 第二种方法是使用 TD learning 来近似
V π ( s ) ≈ r t + γ V ϕ ( s t + 1 ) V^{\pi}(s) \approx r_t + \gamma V_{\phi}(s_{t+1}) V π ( s ) ≈ r t + γ V ϕ ( s t + 1 ) 与上一节一样,DQA 实际上就是针对 optimal policy 应用 TD learning,我们目标函数为
policy-based methods 的 motivation 很好理解,我们想要找到一个 optimal policy, 那我们就采集一些数据,通过一些方法来不停改进当前策略 π \pi π
根据采样数据所使用 policy 的不同,policy-based methods 一般会被分为两类:
on-policy: 采集数据的 policy 和训练更新的 policy 一致
off-policy: 采集数据的 policy 和训练更新的 policy 不一致
这两者的核心区别在于:我们更新模型所使用的数据是否由当前模型产生?如果回答是,则说明算法是 On-policy, 反之则说明是 Off-policy.
on-policy 和 off-policy 对比
我们的目标仍然是最大化累计奖励,目标函数为
max π J ( θ ) = E s 0 ∼ p 0 [ V π θ ( s 0 ) ] = E s 0 ∼ p 0 π θ [ ∑ t = 0 T − 1 γ t r t ] \max_{\pi}\mathcal{J}(\theta)=\mathbb{E}_{s_0\sim p_0}\left[V^{\pi_\theta}(s_0)\right]=\mathbb{E}_{s_0\sim p_0}^{\pi_\theta}\left[\sum_{t=0}^{T-1}\gamma^tr_t\right] π max J ( θ ) = E s 0 ∼ p 0 [ V π θ ( s 0 ) ] = E s 0 ∼ p 0 π θ [ t = 0 ∑ T − 1 γ t r t ] 我们首先将采集到的轨迹数据 τ \tau τ
τ = ( s 0 , a 0 , r 0 , … , s T − 1 , a T − 1 , r T − 1 , s T ) \tau = (s_0,a_0,r_0,\dots,s_{T-1}, a_{T-1}, r_{T-1}, s_T) τ = ( s 0 , a 0 , r 0 , … , s T − 1 , a T − 1 , r T − 1 , s T ) τ \tau τ
p θ ( τ ) = p 0 ( s 0 ) ∏ t = 0 T − 1 p ( r t , s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) p_\theta(\tau) = p_0(s_0)\prod_{t=0}^{T-1} p(r_t,s_{t+1}\mid s_t,a_t)\pi_\theta(a_t\mid s_t) p θ ( τ ) = p 0 ( s 0 ) t = 0 ∏ T − 1 p ( r t , s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) 我们使用 cumulative return 的定义,就得到
J ( θ ) = E s 0 ∼ p 0 π [ ∑ t = 0 T − 1 γ t r t ] = E s 0 ∼ p 0 , a t ∼ π θ ( ⋅ ∣ s t ) , ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) π [ ∑ t = 0 T − 1 γ t r t ] = E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ] \mathcal{J}(\theta)=\mathbb{E}_{s_0\sim p_0}^\pi\left[\sum_{t=0}^{T-1}\gamma^tr_t\right] = \mathbb{E}_{s_0\sim p_0,a_t\sim\pi_\theta(\cdot\mid s_t), (r_t,s_{t+1})\sim p(\cdot,\cdot\mid s_t,a_t)}^\pi\left[\sum_{t=0}^{T-1}\gamma^tr_t\right] = \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\right] J ( θ ) = E s 0 ∼ p 0 π [ t = 0 ∑ T − 1 γ t r t ] = E s 0 ∼ p 0 , a t ∼ π θ ( ⋅ ∣ s t ) , ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) π [ t = 0 ∑ T − 1 γ t r t ] = E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ] 此时,目标函数的梯度为
∇ θ J ( θ ) = ∇ θ E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ] = ∑ τ G 0 ( τ ) ∇ θ p θ ( τ ) = ∑ τ p θ ( τ ) G 0 ( τ ) ∇ θ log p θ ( τ ) = E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log p θ ( τ ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) G 0 ( τ ) ] \begin{align}
\nabla_\theta \mathcal{J}(\theta)&=\nabla_\theta\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\right]\\
&= \sum_\tau G_0(\tau)\nabla_\theta p_\theta(\tau)\\
&= \sum_\tau p_\theta(\tau)G_0(\tau) \nabla_\theta \log p_\theta(\tau)\\
&= \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\nabla_\theta \log p_\theta(\tau)\right]\\
&= \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)G_0(\tau)\right]
\end{align} ∇ θ J ( θ ) = ∇ θ E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ] = τ ∑ G 0 ( τ ) ∇ θ p θ ( τ ) = τ ∑ p θ ( τ ) G 0 ( τ ) ∇ θ log p θ ( τ ) = E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log p θ ( τ ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) G 0 ( τ ) ] 这里我们使用了如下不等式
∇ θ p θ ( τ ) = p θ ( τ ) ∇ θ log p θ ( τ ) \nabla_\theta p_\theta(\tau)=p_\theta(\tau)\nabla_\theta \log p_\theta(\tau) ∇ θ p θ ( τ ) = p θ ( τ ) ∇ θ log p θ ( τ ) 以及
∇ θ log p θ ( τ ) = ∇ θ log [ p 0 ( s 0 ) ∏ t = 0 T − 1 p ( r t , s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) ] = ∑ t = 0 T − 1 log π θ ( a t ∣ s t ) \nabla_\theta \log p_\theta(\tau) = \nabla_\theta \log \left[p_0(s_0)\prod_{t=0}^{T-1} p(r_t,s_{t+1}\mid s_t,a_t)\pi_\theta(a_t\mid s_t)\right] = \sum_{t=0}^{T-1}\log\pi_\theta(a_t\mid s_t) ∇ θ log p θ ( τ ) = ∇ θ log [ p 0 ( s 0 ) t = 0 ∏ T − 1 p ( r t , s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) ] = t = 0 ∑ T − 1 log π θ ( a t ∣ s t ) 一些教材上还有另一种表达形式,使用了 Q-function, 即
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] \nabla_\theta \mathcal{J}(\theta) = \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)Q^\pi(s_t,a_t)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] 我们可以对其进行证明,证明需要用到 Expectation 中的全概率公式。注意到
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] = ∑ t = 0 T − 1 E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] = ∑ t = 0 T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ∣ τ : t ] ] = ∑ t = 0 T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∣ τ : t ] ] = ∑ t = 0 T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∣ s t , a t ] ] = ∑ t = 0 T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] \begin{align}
\nabla_\theta \mathcal{J}(\theta)&=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}G_0(\tau)\nabla_\theta \log \pi_\theta(a_t\mid s_t)\right]\\
&= \sum_{t=0}^{T-1}\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\nabla_\theta \log\pi_\theta(a_t\mid s_t)\right]\\
&=\sum_{t=0}^{T-1}\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\nabla_\theta \log\pi_\theta(a_t\mid s_t)\mid \tau_{:t}\right]\right]\\
&=\sum_{t=0}^{T-1}\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[\nabla_\theta \log\pi_\theta(a_t\mid s_t)\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\mid \tau_{:t}\right]\right]\\
&=\sum_{t=0}^{T-1}\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[\nabla_\theta \log\pi_\theta(a_t\mid s_t)\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\mid s_t,a_t\right]\right]\\
&=\sum_{t=0}^{T-1}\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[\nabla_\theta \log\pi_\theta(a_t\mid s_t)Q^\pi(s_t,a_t)\right]
\end{align} ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] = t = 0 ∑ T − 1 E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] = t = 0 ∑ T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ∣ τ : t ] ] = t = 0 ∑ T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∣ τ : t ] ] = t = 0 ∑ T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∣ s t , a t ] ] = t = 0 ∑ T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] 这里第三个等式使用了全概率公式,第四个等式是因为 ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log\pi_\theta(a_t\mid s_t) ∇ θ log π θ ( a t ∣ s t ) τ : t \tau_{:t} τ : t
令
g ^ : = ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) G 0 ( τ ) \hat{g} := \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)G_0(\tau) g ^ := t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) G 0 ( τ ) 则 g ^ \hat{g} g ^ ∇ θ J ( θ ) \nabla_\theta \mathcal{J}(\theta) ∇ θ J ( θ )
基于 MC 思想,我们可以得到最简单的 policy gradient algorithm, 也就是 REINFORCE 算法
\begin{algorithm} \caption{Policy Gradient with MC (REINFORCE)} \begin{algorithmic} \STATE initial policy parameters $\theta_0$. \FOR {$k=0,1,\dots$} \STATE Sample $M$ trajectories $\{\tau_i\}$ according to policy $\pi_{\theta_k}$ \STATE estimate the gradient via MC: $$ \hat{g}=\frac{1}{M}\sum_{i=1}^M\sum_{t=0}^{T_i-1}\nabla_\theta\log\pi_{\theta_k}(a_t\mid s_t)G_0(\tau_i) $$ \STATE update $\theta_k$ using $\hat{g}$ with an optimizer \ENDFOR \end{algorithmic} \end{algorithm} g g g ∇ θ J ( θ ) \nabla_\theta \mathcal{J}(\theta) ∇ θ J ( θ ) g g g g g g
我们有如下等式
E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ∑ t = 0 T − 1 r ( s t ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ( ∑ t = 0 T − 1 r ( s t ) − b ( s t ) ) ] \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\sum_{t=0}^{T-1}r(s_t)\right] = \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\left(\sum_{t=0}^{T-1}r(s_t)-b(s_t)\right)\right] E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) t = 0 ∑ T − 1 r ( s t ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) ( t = 0 ∑ T − 1 r ( s t ) − b ( s t ) ) ] 其中 b b b b b b
E τ ∼ ( p 0 , π θ , p ) [ b ( s t ) ∇ θ log p θ ( a t ∣ s t ) ] = 0 \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[b(s_t)\nabla_\theta \log p_\theta(a_t\mid s_t)\right]=0 E τ ∼ ( p 0 , π θ , p ) [ b ( s t ) ∇ θ log p θ ( a t ∣ s t ) ] = 0 注意到
E τ ∼ ( p 0 , π θ , p ) [ b ( s t ) ∇ θ log p θ ( a t ∣ s t ) ] = E s 0 ∼ p 0 [ b ( s t ) E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ] ] = E s 0 ∼ p 0 [ b ( s t ) ∑ a ∇ θ π θ ( a ∣ s ) ] = E s 0 ∼ p 0 [ b ( s t ) ∇ θ ∑ a π θ ( a ∣ s ) ] = E s 0 ∼ p 0 [ b ( s t ) ∇ θ 1 ] = 0 \begin{align}
\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[b(s_t)\nabla_\theta \log p_\theta(a_t\mid s_t)\right] &= \mathbb{E}_{s_0\sim p_0}\left[b(s_t)\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\right]\right]\\
&= \mathbb{E}_{s_0\sim p_0}\left[b(s_t)\sum_{a}\nabla_\theta \pi_\theta(a\mid s)\right]\\
&= \mathbb{E}_{s_0\sim p_0}\left[b(s_t)\nabla_\theta \sum_{a}\pi_\theta(a\mid s)\right]\\
&= \mathbb{E}_{s_0\sim p_0}\left[b(s_t)\nabla_\theta 1\right]\\
&=0
\end{align} E τ ∼ ( p 0 , π θ , p ) [ b ( s t ) ∇ θ log p θ ( a t ∣ s t ) ] = E s 0 ∼ p 0 [ b ( s t ) E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ] ] = E s 0 ∼ p 0 [ b ( s t ) a ∑ ∇ θ π θ ( a ∣ s ) ] = E s 0 ∼ p 0 [ b ( s t ) ∇ θ a ∑ π θ ( a ∣ s ) ] = E s 0 ∼ p 0 [ b ( s t ) ∇ θ 1 ] = 0 因此,我们就得到了如上结论。■ \blacksquare ■
我们将 b ( s t ) b(s_t) b ( s t ) baseline .
Reward to go 的基本思想是,对于时刻 t t t s 0 , r 0 , … , r t − 1 s_0,r_0,\dots,r_{t-1} s 0 , r 0 , … , r t − 1 b ( s t ) b(s_t) b ( s t )
b ( s t ) = ∑ k = 0 t γ k r k b(s_t) = \sum_{k=0}^{t}\gamma^k r_k b ( s t ) = k = 0 ∑ t γ k r k 此时,我们的 policy gradient 为
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ∑ k = t T − 1 r ( s k ) ] \nabla_\theta \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\sum_{k=t}^{T-1}r(s_{k})\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) k = t ∑ T − 1 r ( s k ) ] 对应的 REINFORCE 算法改进版本为
\begin{algorithm} \caption{Policy Gradient with MC and reward to go (REINFORCE)} \begin{algorithmic} \STATE initial policy parameters $\theta_0$. \FOR {$k=0,1,\dots$} \STATE Sample $M$ trajectories $\{\tau_i\}$ according to policy $\pi_{\theta_k}$ \STATE estimate the gradient via MC: $$ \hat{g}=\frac{1}{M}\sum_{i=1}^M\nabla_\theta\log\pi_{\theta_k}(a_t\mid s_t)\gamma^tG_t(\tau_i) $$ \STATE update $\theta_k$ using $\hat{g}$ with an optimizer \ENDFOR \end{algorithmic} \end{algorithm} 我们可以从理论上推导出最优 baseline.
Lemma
令 s s s a a a w ( s , a ) w(s,a) w ( s , a ) Q ( s , a ) Q(s,a) Q ( s , a ) b ( s ) b(s) b ( s )
b ∗ = arg min b ( ⋅ ) E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ( s ) ) 2 ] b^* = \arg\min_{b(\cdot)} \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b(s)\right)^2\right] b ∗ = arg b ( ⋅ ) min E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ( s ) ) 2 ] 其中
b ∗ ( s ) = E a ∣ s [ w 2 ( s , a ) Q ( s , a ) ∣ s ] E a ∣ s [ w 2 ( s , a ) ∣ s ] b^*(s) = \frac{\mathbb{E}_{a\mid s}\left[w^2(s,a)Q(s,a)\mid s\right]}{\mathbb{E}_{a\mid s}\left[w^2(s,a)\mid s\right]} b ∗ ( s ) = E a ∣ s [ w 2 ( s , a ) ∣ s ] E a ∣ s [ w 2 ( s , a ) Q ( s , a ) ∣ s ] 证明
E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ( s ) ) 2 ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) + b ∗ ( s ) − b ( s ) ) 2 ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] + E a , s [ w 2 ( s , a ) ( b ∗ ( s ) − b ( s ) ) 2 ] + 2 E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] + E a , s [ w 2 ( s , a ) ( b ∗ ( s ) − b ( s ) ) 2 ] ≥ E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] \begin{align}
\mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b(s)\right)^2\right]&= \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)+b^*(s)-b(s)\right)^2\right]\\
&= \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)^2\right]+\mathbb{E}_{a,s}\left[w^2(s,a)\left(b^*(s)-b(s)\right)^2\right]\\
&+2\mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)\left(b^*(s)-b(s)\right)\right]\\
&= \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)^2\right]+\mathbb{E}_{a,s}\left[w^2(s,a)\left(b^*(s)-b(s)\right)^2\right]\\
&\geq \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)^2\right]
\end{align} E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ( s ) ) 2 ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) + b ∗ ( s ) − b ( s ) ) 2 ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] + E a , s [ w 2 ( s , a ) ( b ∗ ( s ) − b ( s ) ) 2 ] + 2 E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] + E a , s [ w 2 ( s , a ) ( b ∗ ( s ) − b ( s ) ) 2 ] ≥ E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] 其中第三个等式用到了
E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = E s [ E a ∣ s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] ∣ s ] = E s [ ( E a ∣ s [ w 2 ( s , a ) Q ( s , a ) ∣ s ] − E a ∣ s [ w 2 ( s , a ) ∣ s ] b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = 0 \begin{align}
\mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)\left(b^*(s)-b(s)\right)\right]&= \mathbb{E}_{s}\left[\mathbb{E}_{a\mid s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)\left(b^*(s)-b(s)\right)\right]\mid s\right]\\
&= \mathbb{E}_{s}\left[\left(\mathbb{E}_{a\mid s}\left[w^2(s,a)Q(s,a)\mid s\right] - \mathbb{E}_{a\mid s}\left[w^2(s,a)\mid s\right]b^*(s)\right)\left(b^*(s)-b(s)\right)\right]\\
&=0
\end{align} E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = E s [ E a ∣ s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] ∣ s ] = E s [ ( E a ∣ s [ w 2 ( s , a ) Q ( s , a ) ∣ s ] − E a ∣ s [ w 2 ( s , a ) ∣ s ] b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = 0 证毕。■ \blacksquare ■
基于上述引理,我们可以得到关于 baseline invariance 中的最优 basline:
b ∗ ( s ) = E a t ∼ π θ ( ⋅ ∣ s t ) [ ( ∇ θ log π θ ( a t ∣ s t ) ) 2 Q π θ ( s , a ) ∣ s ] E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ) 2 ∣ s ] b^*(s) =\frac{\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[(\nabla_\theta\log\pi_\theta(a_t\mid s_t))^2Q^{\pi_\theta}(s,a)\mid s\right]}{\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[\nabla_\theta\log\pi_\theta(a_t\mid s_t))^2\mid s\right]} b ∗ ( s ) = E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ) 2 ∣ s ] E a t ∼ π θ ( ⋅ ∣ s t ) [ ( ∇ θ log π θ ( a t ∣ s t ) ) 2 Q π θ ( s , a ) ∣ s ] 理论上我们可以使用 b ∗ ( s t ) b^*(s_t) b ∗ ( s t ) b ∗ ( s ) b^*(s) b ∗ ( s ) ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta\log\pi_\theta(a_t\mid s_t) ∇ θ log π θ ( a t ∣ s t )
b ( s ) = E a t ∼ π θ ( ⋅ ∣ s t ) [ Q π θ ( s , a ) ∣ s ] E a t ∼ π θ ( ⋅ ∣ s t ) [ 1 ∣ s ] = V π θ ( s ) b(s) = \frac{\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[Q^{\pi_\theta}(s,a)\mid s\right]}{\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[1\mid s\right]} = V^{\pi_\theta}(s) b ( s ) = E a t ∼ π θ ( ⋅ ∣ s t ) [ 1 ∣ s ] E a t ∼ π θ ( ⋅ ∣ s t ) [ Q π θ ( s , a ) ∣ s ] = V π θ ( s ) b ( s ) = V π θ ( s ) b(s)=V^{\pi_\theta}(s) b ( s ) = V π θ ( s )
我们将 b ( s ) = V π θ ( s ) b(s)=V^{\pi_\theta}(s) b ( s ) = V π θ ( s )
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ( Q π θ ( s t , a t ) − V π θ ( s t ) ) ] \nabla_\theta \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\left(Q^{\pi_\theta}(s_t,a_t)-V^{\pi_\theta}(s_t)\right)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) ( Q π θ ( s t , a t ) − V π θ ( s t ) ) ] 我们定义
A π θ ( s t , a t ) : = Q π θ ( s t , a t ) − V π θ ( s t ) A^{\pi_\theta}(s_t,a_t) := Q^{\pi_\theta}(s_t,a_t)-V^{\pi_\theta}(s_t) A π θ ( s t , a t ) := Q π θ ( s t , a t ) − V π θ ( s t ) 为 a t a_t a t s t s_t s t advantage . 注意到 V π θ ( s t ) V^{\pi_\theta}(s_t) V π θ ( s t ) π θ \pi_\theta π θ a t a_t a t π θ \pi_\theta π θ
如果 A π θ ( s t , a t ) > 0 A^{\pi_\theta}(s_t,a_t) >0 A π θ ( s t , a t ) > 0 a t a_t a t π θ \pi_\theta π θ
反之如果 A π θ ( s t , a t ) < 0 A^{\pi_\theta}(s_t,a_t) <0 A π θ ( s t , a t ) < 0 a t a_t a t π θ \pi_\theta π θ
实际场景下,由于 V π θ ( s t ) V^{\pi_\theta}(s_t) V π θ ( s t )
A ^ π θ ( s t , a t ) : = Q π θ ( s t , a t ) − V ϕ ( s t ) \hat{A}^{\pi_\theta}(s_t,a_t) := Q^{\pi_\theta}(s_t,a_t)-V^{\phi}(s_t) A ^ π θ ( s t , a t ) := Q π θ ( s t , a t ) − V ϕ ( s t ) 来代替。
对于最优策略 π ∗ \pi^* π ∗
A π ∗ ( s t , a t ) : = Q π ∗ ( s t , a t ) − V π ∗ ( s t ) ≤ 0 A^{\pi^*}(s_t,a_t) := Q^{\pi^*}(s_t,a_t)-V^{\pi^*}(s_t)\leq 0 A π ∗ ( s t , a t ) := Q π ∗ ( s t , a t ) − V π ∗ ( s t ) ≤ 0 证明也很简单,注意到 V π ∗ ( s t ) = max a Q π ∗ ( s t , a t ) V^{\pi^*}(s_t)=\max_{a}Q^{\pi^*}(s_t,a_t) V π ∗ ( s t ) = max a Q π ∗ ( s t , a t )
最后,我们的 REINFORCE 算法改进如下
\begin{algorithm} \caption{Policy Gradient with MC and value function (REINFORCE)} \begin{algorithmic} \STATE initial policy parameters $\theta_0$. \FOR {$k=0,1,\dots$} \STATE Sample $M$ trajectories $\{\tau_i\}$ according to policy $\pi_{\theta_k}$ \STATE estimate the gradient via MC: $$ \hat{g}=\frac{1}{M}\sum_{i=1}^M\nabla_\theta\log\pi_{\theta_k}(a_t\mid s_t)\gamma^t(Q^{\pi_\theta}(s_t,a_t)-V^{\phi}(s_t)) $$ \STATE update $\theta_k$ using $\hat{g}$ with an optimizer \ENDFOR \end{algorithmic} \end{algorithm} 我们在前面介绍了不同的降低 variance 的方法,但是我们还没有在理论上回答为什么可以降低 variance, 本节我们将基于 Rao-Blackwell theorem 来回答这个问题
Theorem
令 X X X Y Y Y I ^ 1 ( X , Y ) \hat{I}_1(X,Y) I ^ 1 ( X , Y ) I I I
I = E X Y [ I ^ 1 ( X Y ) ] I = \mathbb{E}_{XY}[\hat{I}_1(XY)] I = E X Y [ I ^ 1 ( X Y )] 令 I ^ 2 ( Y ) = E X ∣ Y [ I ^ 1 ( X , Y ) ∣ Y ] \hat{I}_2(Y)=\mathbb{E}_{X\mid Y}[\hat{I}_1(X,Y)\mid Y] I ^ 2 ( Y ) = E X ∣ Y [ I ^ 1 ( X , Y ) ∣ Y ] I ^ 2 \hat{I}_2 I ^ 2 I I I
v a r [ I ^ 2 ] ≤ v a r [ I ^ 1 ] \mathrm{var}[\hat{I}_2]\leq\mathrm{var}[\hat{I}_1] var [ I ^ 2 ] ≤ var [ I ^ 1 ] I ^ 2 \hat{I}_2 I ^ 2 I ^ 1 ( X , Y ) \hat{I}_1(X,Y) I ^ 1 ( X , Y ) Rao-Blackwellized estimator .
证明
由 Expectation 中的 law of total expectation, 我们有
E X Y [ I ^ 2 ( X Y ) ] = E Y [ E X ∣ Y [ I ^ 1 ( X , Y ) ∣ Y ] ] = E X Y [ I ^ 1 ( X Y ) ] = I \mathbb{E}_{XY}[\hat{I}_2(XY) ]=\mathbb{E}_{Y}[\mathbb{E}_{X\mid Y}[\hat{I}_1(X,Y)\mid Y]]=\mathbb{E}_{XY}[\hat{I}_1(XY) ]=I E X Y [ I ^ 2 ( X Y )] = E Y [ E X ∣ Y [ I ^ 1 ( X , Y ) ∣ Y ]] = E X Y [ I ^ 1 ( X Y )] = I 其次,我们有
v a r [ I ^ 2 ] = E Y [ ( I − I ^ 2 ( Y ) ) 2 ] = E Y [ ( E X ∣ Y [ I − I ^ 1 ( X , Y ) ∣ Y ] ) 2 ] ≤ E Y [ ( E X ∣ Y [ ( I − I ^ 1 ( X , Y ) ) 2 ∣ Y ] ) ] = E Y [ ( I − I ^ 1 ( X , Y ) ) 2 ] = v a r [ I ^ 1 ] \begin{align}
\mathrm{var}[\hat{I}_2]&=\mathbb{E}_{Y}[(I-\hat{I}_2(Y))^2]\\
&= \mathbb{E}_{Y}[\left(\mathbb{E}_{X\mid Y}\left[I-\hat{I}_1(X,Y)\mid Y\right]\right)^2]\\
&\leq\mathbb{E}_{Y}[\left(\mathbb{E}_{X\mid Y}\left[(I-\hat{I}_1(X,Y))^2\mid Y\right]\right)]\\
&= \mathbb{E}_{Y}[(I-\hat{I}_1(X,Y))^2]\\
&=\mathrm{var}[\hat{I}_1]
\end{align} var [ I ^ 2 ] = E Y [( I − I ^ 2 ( Y ) ) 2 ] = E Y [ ( E X ∣ Y [ I − I ^ 1 ( X , Y ) ∣ Y ] ) 2 ] ≤ E Y [ ( E X ∣ Y [ ( I − I ^ 1 ( X , Y ) ) 2 ∣ Y ] ) ] = E Y [( I − I ^ 1 ( X , Y ) ) 2 ] = var [ I ^ 1 ] 这里不等式使用了 Jensen’s inequality. 证毕。■ \blacksquare ■
Rao–Blackwell Theorem 说明了我们可以通过构造一个新的无偏估计,这个新的无偏估计相对于原始的无偏估计,有更小的方差。
最后,我们把前面的 basline 使用统一的公式进行表示,记
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ Ψ ( τ ) ∇ θ log p θ ( τ ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T Ψ t ( τ ) ∇ θ log p θ ( τ ) ] \nabla_\theta \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[\Psi(\tau)\nabla_\theta \log p_\theta(\tau)\right]=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[\sum_{t=0}^T\Psi_t(\tau)\nabla_\theta \log p_\theta(\tau)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ Ψ ( τ ) ∇ θ log p θ ( τ ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T Ψ t ( τ ) ∇ θ log p θ ( τ ) ] 则
在本节中,我们将对比 REINFORCE 算法的不同变体。我们使用
在本节中,我们推导了 policy gradient 的具体形式,然后针对 REINFORCE 算法 variance 过高的问题,我们介绍了不同的减少 variance 的方法。最后,我们从理论上分析了为什么这些方法可以降低 variance.
在上一节中, 我们介绍了经典的 policy gradient 形式,并基于 policy gradient 构建了经典的 REINFORCE 算法,我们还使用了 baseline invariance 性质来降低 policy gradient 的 variance, 并得到了最终的 advantage 形式。
在本节中,我们将要针对 advantage 进行进一步探讨,介绍如何将 value based methods 和 policy based methods 结合起来得到 actor-critic methods.
我们首先考虑最简单的 actor-critic algorithm, 注意到
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] \nabla_\theta \mathcal{J}(\theta) = \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)Q^{\pi_\theta}(s_t,a_t)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] 因此,其对应的 policy gradient methods 为
θ k + 1 = θ k + α E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] \theta_{k+1} = \theta_k + \alpha \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)Q^{\pi_\theta}(s_t,a_t)\right] θ k + 1 = θ k + α E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] 在前面的章节中,我们介绍了基于 MC 和 TD 两种方式来估计 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t,a_t) Q π θ ( s t , a t )
如果 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t,a_t) Q π θ ( s t , a t )
如果 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t,a_t) Q π θ ( s t , a t ) actor-critic , 这是我们本节的重点介绍内容
最简单的 actor-critic algorithm 如下所示
\begin{algorithm} \caption{Q actor-critic} \begin{algorithmic} \STATE initial policy parameters $\theta_0$, value function parameters $\phi_0$. \FOR {$t=0,1,T-1$} \STATE $a_t\sim\pi_{\theta}(\cdot\mid s_t)$, $r_t,s_{t+1}\sim p(\cdot,\cdot\mid s_t,a_t)$, $a_{t+1}\sim\pi_{\theta}(\cdot\mid s_{t+1})$ \STATE (ACTOR) policy update $$ \theta_{t+1} = \theta_t + \alpha_{\theta}\log\pi_{\theta}(a_t\mid s_t)Q^{\phi_t}(s_t,a_t) $$ \STATE (CRITIC) value update $$ \phi_{t+1} = \phi_t + \alpha_\phi\left[r_{t}+\gamma Q^{\phi_t}(s_{t+1},a_{t+1})-Q^{\phi_t}(s_t,a_t)\right]\nabla_\phi Q^{\phi_t}(s_t,a_t) $$ \ENDFOR \end{algorithmic} \end{algorithm} 在上一节中,我们介绍了 QAC, 但实际上我们用的更多的是 advantage actor-critic, 其梯度如下所示
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) A π θ ( s t , a t ) ] \nabla_\theta \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)A^{\pi_\theta}(s_t,a_t)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) A π θ ( s t , a t ) ] 注意到
A π θ ( s t , a t ) = Q π θ ( s t , a t ) − V π θ ( s t ) = E π θ [ r t + γ V π θ ( s t + 1 ) − V π θ ( s t ) ∣ s t , a t ] A^{\pi_\theta}(s_t,a_t)=Q^{\pi_\theta}(s_t,a_t)-V^{\pi_\theta}(s_t) = \mathbb{E}^{\pi_\theta}\left[r_t + \gamma V^{\pi_\theta}(s_{t+1})-V^{\pi_\theta}(s_t)\mid s_t, a_t\right] A π θ ( s t , a t ) = Q π θ ( s t , a t ) − V π θ ( s t ) = E π θ [ r t + γ V π θ ( s t + 1 ) − V π θ ( s t ) ∣ s t , a t ] 因此我们可以用 TD error 来进行近似:
A ^ t = r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) \hat{A}_t= r_t + \gamma V_{\phi_t}(s_{t+1})-V_{\phi_t}(s_t) A ^ t = r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) 这样我们就得到了 A2C 算法
\begin{algorithm} \caption{Advantage actor-critic} \begin{algorithmic} \STATE initial policy parameters $\theta_0$, value function parameters $\phi_0$. \FOR {$t=0,1,T-1$} \STATE $a_t\sim\pi_{\theta}(\cdot\mid s_t)$, $r_t,s_{t+1}\sim p(\cdot,\cdot\mid s_t,a_t)$, $a_{t+1}\sim\pi_{\theta}(\cdot\mid s_{t+1})$ \STATE advantage estimation $$ \hat{A}_t\approx r_t + \gamma V_{\phi_t}(s_{t+1})-V_{\phi_t}(s_t) $$ \STATE (ACTOR) policy update $$ \theta_{t+1} = \theta_t + \alpha_{\theta}\log\pi_{\theta}(a_t\mid s_t)\hat{A}_t $$ \STATE (CRITIC) value update $$ \phi_{t+1} = \phi_t + \alpha_\phi\hat{A}_t\nabla_\phi V^{\phi_t}(s_t) $$ \ENDFOR \end{algorithmic} \end{algorithm} 在上一节中,我们介绍了我们可以用 1-step TD error 来近似 advantage,
对比结果如下表所示
为了实现更好的 bias-variance trade-off, GAE 提出了使用一个参数 λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ ∈ [ 0 , 1 ]
A ^ t G A E ( γ , λ ) = ∑ ℓ = 0 ∞ ( γ λ ) ℓ δ t + ℓ \hat{A}_t^{GAE(\gamma,\lambda)} = \sum_{\ell=0}^{\infty}(\gamma\lambda)^{\ell}\delta_{t+\ell} A ^ t G A E ( γ , λ ) = ℓ = 0 ∑ ∞ ( γ λ ) ℓ δ t + ℓ 其中
δ t = r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) \delta_t = r_t + \gamma V_{\phi_t}(s_{t+1})-V_{\phi_t}(s_t) δ t = r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) 我们可以探究不同的 λ \lambda λ
当 λ = 0 \lambda=0 λ = 0
A ^ t G A E ( γ , 0 ) = ( γ ⋅ 0 ) 0 δ t = δ t \hat{A}_t^{GAE(\gamma,0)} = (\gamma\cdot0)^0\delta_t=\delta_t A ^ t G A E ( γ , 0 ) = ( γ ⋅ 0 ) 0 δ t = δ t 此时,GAE 就退化成了 one-step TD error estimate,
当 λ = 1 \lambda=1 λ = 1
A ^ t G A E ( γ , 1 ) = ∑ ℓ = 0 ∞ γ ℓ δ t + ℓ = ∑ ℓ = 0 ∞ γ ℓ ( r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) ) \hat{A}_t^{GAE(\gamma,1)} = \sum_{\ell=0}^{\infty}\gamma^{\ell}\delta_{t+\ell}=\sum_{\ell=0}^{\infty}\gamma^{\ell}\left(r_t + \gamma V_{\phi_t}(s_{t+1})-V_{\phi_t}(s_t)\right) A ^ t G A E ( γ , 1 ) = ℓ = 0 ∑ ∞ γ ℓ δ t + ℓ = ℓ = 0 ∑ ∞ γ ℓ ( r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) ) 如果我们假设这里使用的是真实的 value function 的话,那么我们有
A ^ t G A E ( γ , 1 ) ≈ ∑ ℓ = 0 ∞ γ ℓ r t + ℓ + 1 − V ( s t ) = Q π θ ( s t , a t ) − V ( s t ) \hat{A}_t^{GAE(\gamma,1)} \approx \sum_{\ell=0}^{\infty}\gamma^{\ell}r_{t+\ell+1}-V(s_t)=Q^{\pi_\theta}(s_t,a_t)-V(s_t) A ^ t G A E ( γ , 1 ) ≈ ℓ = 0 ∑ ∞ γ ℓ r t + ℓ + 1 − V ( s t ) = Q π θ ( s t , a t ) − V ( s t ) 当 0 < λ < 1 0<\lambda<1 0 < λ < 1 G A E GAE G A E λ \lambda λ λ \lambda λ
实际计算过程中,我们使用如下方法来进行计算
\begin{algorithm} \caption{Generalized Advantage Estimation (GAE)} \begin{algorithmic} \STATE policy parameters $\theta$, value function parameters $\phi$. \STATE sample a trajectory $\tau\sim(p_0,\pi_\theta, p)$ \FOR {$t=0,1,\dots,T-1$} \STATE compute TD errors $$ \delta_t = r_t + \gamma V_{\phi}(s_{t+1})-V_{\phi}(s_t) $$ \ENDFOR \STATE initialization: $\hat{A}_{T}^{GAE}=0$ \FOR {$t=T-1,\dots, 0$} \STATE iterate backward $$ \hat{A}_t^{GAE} = \delta_t + \gamma\lambda \hat{A}_{t+1}^{GAE} $$ \ENDFOR \end{algorithmic} \end{algorithm} GAE 的主要优点在于其相对于 MC estimate 可以大幅度降低 variance, 从而提高训练的稳定性以及效率
在本文中,我们探讨如何提高 policy gradient methods 的 sample efficiency.
在上一节中介绍的 REINFORCE 算法中,我们每次都需要基于当前策略 π θ \pi_\theta π θ
一个自然的想法是,我们能否利用已有的数据集来进行训练,也就是 off-policy 版本的 policy gradient algorithm.
我们的目标函数为
max π J ( θ ) = E s 0 ∼ p 0 [ V π θ ( s 0 ) ] \max_{\pi}\mathcal{J}(\theta)=\mathbb{E}_{s_0\sim p_0}\left[V^{\pi_\theta}(s_0)\right] π max J ( θ ) = E s 0 ∼ p 0 [ V π θ ( s 0 ) ] 我们假设有两个 policy 的参数, θ \theta θ θ o l d \theta_{old} θ o l d
J ( θ ) − J ( θ o l d ) = J ( θ ) − E s 0 ∼ p 0 [ V π θ o l d ( s 0 ) ] = J ( θ ) − E τ ∼ ( p 0 , π θ , p ) [ V π θ o l d ( s 0 ) ] = J ( θ ) − E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t V π θ o l d ( s t ) − ∑ t = 1 T − 1 γ t V π θ o l d ( s t ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t r t ] + E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t ( γ V π θ o l d ( s t + 1 ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t ( r t + γ V π θ o l d ( s t + 1 ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t ( γ Q π θ o l d ( s t , a t ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t A π θ o l d ( s t , a t ) ] \begin{align}
\mathcal{J}(\theta) -\mathcal{J}(\theta_{old}) &= \mathcal{J}(\theta) - \mathbb{E}_{s_0\sim p_0}\left[V^{\pi_{\theta_{old}}}(s_0)\right]\\
&= \mathcal{J}(\theta) - \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[V^{\pi_{\theta_{old}}}(s_0)\right]\\
&= \mathcal{J}(\theta) - \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^tV^{\pi_{\theta_{old}}}(s_t)-\sum_{t=1}^{T-1}\gamma^tV^{\pi_{\theta_{old}}}(s_t)\right]\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t r_t\right] + \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t\left(\gamma V^{\pi_{\theta_{old}}}(s_{t+1})-V^{\pi_{\theta_{old}}}(s_t)\right)\right]\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t\left(r_t+\gamma V^{\pi_{\theta_{old}}}(s_{t+1})-V^{\pi_{\theta_{old}}}(s_t)\right)\right]\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t\left(\gamma Q^{\pi_{\theta_{old}}}(s_{t}, a_t)-V^{\pi_{\theta_{old}}}(s_t)\right)\right]\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t A^{\pi_{\theta_{old}}}(s_t,a_t)\right]\\
\end{align} J ( θ ) − J ( θ o l d ) = J ( θ ) − E s 0 ∼ p 0 [ V π θ o l d ( s 0 ) ] = J ( θ ) − E τ ∼ ( p 0 , π θ , p ) [ V π θ o l d ( s 0 ) ] = J ( θ ) − E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t V π θ o l d ( s t ) − t = 1 ∑ T − 1 γ t V π θ o l d ( s t ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t r t ] + E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t ( γ V π θ o l d ( s t + 1 ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t ( r t + γ V π θ o l d ( s t + 1 ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t ( γ Q π θ o l d ( s t , a t ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t A π θ o l d ( s t , a t ) ] 我们进一步展开得到
J ( θ ) − J ( θ o l d ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t A π θ o l d ( s t , a t ) ] = E s 0 ∼ p 0 , a 0 ∼ π θ ( ⋅ ∣ s 0 ) [ A π θ o l d ( s 0 , a 0 ) + E π θ [ ∑ t = 1 T − 1 γ t A π θ o l d ( s t , a t ) ∣ s 0 , a 0 ] ] = E s 0 ∼ p 0 , a 0 ∼ π θ ( ⋅ ∣ s 0 ) , a 0 ′ ∼ π θ o l d ( ⋅ ∣ s 0 ) [ π θ ( a 0 ′ ∣ s 0 ) π θ o l d ( a 0 ′ ∣ s 0 ) A π θ o l d ( s 0 , a 0 ′ ) + E π θ [ ∑ t = 1 T − 1 γ t A π θ o l d ( s t , a t ) ∣ s 0 , a 0 ] ] = … ( keep enrolling the summation ) = E τ ∼ ( p 0 , π θ , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] \begin{align}
\mathcal{J}(\theta) -\mathcal{J}(\theta_{old}) &= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t A^{\pi_{\theta_{old}}}(s_t,a_t)\right]\\
&= \mathbb{E}_{s_0\sim p_0, a_0\sim\pi_\theta(\cdot\mid s_0)}\left[A^{\pi_{\theta_{old}}}(s_0,a_0)+\mathbb{E}^{\pi_\theta}\left[\sum_{t=1}^{T-1}\gamma^t A^{\pi_{\theta_{old}}}(s_t,a_t)\mid s_0, a_0\right]\right]\\
&= \mathbb{E}_{s_0\sim p_0, a_0\sim\pi_\theta(\cdot\mid s_0),a_0'\sim \pi_{\theta_{old}}(\cdot\mid s_0)}\left[\frac{\pi_{\theta}(a_0'\mid s_0)}{\pi_{\theta_{old}}(a_0'\mid s_0)}A^{\pi_{\theta_{old}}}(s_0,a_0')+\mathbb{E}^{\pi_\theta}\left[\sum_{t=1}^{T-1}\gamma^t A^{\pi_{\theta_{old}}}(s_t,a_t)\mid s_0, a_0\right]\right]\\
&=\dots (\text{keep enrolling the summation})\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p),a_t'\sim \pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t \frac{\pi_{\theta}(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]\\
\end{align} J ( θ ) − J ( θ o l d ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t A π θ o l d ( s t , a t ) ] = E s 0 ∼ p 0 , a 0 ∼ π θ ( ⋅ ∣ s 0 ) [ A π θ o l d ( s 0 , a 0 ) + E π θ [ t = 1 ∑ T − 1 γ t A π θ o l d ( s t , a t ) ∣ s 0 , a 0 ] ] = E s 0 ∼ p 0 , a 0 ∼ π θ ( ⋅ ∣ s 0 ) , a 0 ′ ∼ π θ o l d ( ⋅ ∣ s 0 ) [ π θ o l d ( a 0 ′ ∣ s 0 ) π θ ( a 0 ′ ∣ s 0 ) A π θ o l d ( s 0 , a 0 ′ ) + E π θ [ t = 1 ∑ T − 1 γ t A π θ o l d ( s t , a t ) ∣ s 0 , a 0 ] ] = … ( keep enrolling the summation ) = E τ ∼ ( p 0 , π θ , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] 因此,我们有
J ( θ ) = E τ ∼ ( p 0 , π θ , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] + C \mathcal{J}(\theta) = \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p),a_t'\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t\frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]+C J ( θ ) = E τ ∼ ( p 0 , π θ , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] + C 但是,现在我们的更姓还是依赖于 π θ \pi_\theta π θ 当 π θ \pi_\theta π θ π θ o l d \pi_{\theta_{old}} π θ o l d π θ o l d \pi_{\theta_{old}} π θ o l d π θ \pi_\theta π θ , 这样,上面目标函数就变成了
max θ K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s . t . π θ o l d ≈ π θ \begin{align}
\max_{\theta}\ &\mathcal{K}(\theta;\theta_{old}) = \mathbb{E}_{\tau\sim(p_0,\pi_{\theta_{old}}, p),a_t'\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t\frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]\\
\mathrm{s.t.}\ &\pi_{\theta_{old}}\approx \pi_\theta
\end{align} θ max s.t. K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] π θ o l d ≈ π θ 我们可以证明
∇ J ( θ ) ∣ θ = θ o l d = ∇ θ K ( θ ; θ o l d ) ∣ θ = θ o l d \nabla \mathcal{J}(\theta)\mid _{\theta=\theta_{old}} = \nabla_\theta \mathcal{K}(\theta;\theta_{old})\mid _{\theta=\theta_{old}} ∇ J ( θ ) ∣ θ = θ o l d = ∇ θ K ( θ ; θ o l d ) ∣ θ = θ o l d 这就是 TRPO 的核心改进,在实际求解时,我们将上面的问题规范为如下形式
max θ K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s . t . max s ∈ S K L ( π θ ( ⋅ ∣ s ) ∣ ∣ π θ o l d ( ⋅ ∣ s ) ) ≤ δ \begin{align}
\max_{\theta}\ &\mathcal{K}(\theta;\theta_{old}) = \mathbb{E}_{\tau\sim(p_0,\pi_{\theta_{old}}, p),a_t'\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t\frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]\\
\mathrm{s.t.}\ &\max_{s\in\mathcal{S}}\mathrm{KL}(\pi_\theta(\cdot\mid s)\mid\mid \pi_{\theta_{old}}(\cdot\mid s))\leq \delta
\end{align} θ max s.t. K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s ∈ S max KL ( π θ ( ⋅ ∣ s ) ∣∣ π θ o l d ( ⋅ ∣ s )) ≤ δ 这里 δ > 0 \delta>0 δ > 0
现在我们可以采样多条轨迹 τ ( i ) ∼ ( p 0 , π θ o l d , p ) \tau^{(i)}\sim (p_0,\pi_{\theta_{old}}, p) τ ( i ) ∼ ( p 0 , π θ o l d , p ) K ( θ ; θ o l d ) \mathcal{K}(\theta;\theta_{old}) K ( θ ; θ o l d )
K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A π θ o l d ( s t , a t ) ] ≈ 1 N ∑ i = 1 N ∑ t = 0 T ( i ) − 1 γ t π θ ( a t ( i ) ∣ s t ( i ) ) π θ o l d ( a t ( i ) ∣ s t ( i ) ) A ^ t \mathcal{K}(\theta;\theta_{old}) = \mathbb{E}_{\tau\sim(p_0,\pi_{\theta_{old}}, p),a_t\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t\frac{\pi_\theta(a_t\mid s_t)}{\pi_{\theta_{old}}(a_t\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t)\right]\approx \frac{1}{N}\sum_{i=1}^N\sum_{t=0}^{T^{(i)}-1}\gamma^t\frac{\pi_\theta(a_t^{(i)}\mid s_t^{(i)})}{\pi_{\theta_{old}}(a_t^{(i)}\mid s_t^{(i)})}\hat{A}_t K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ∣ s t ) π θ ( a t ∣ s t ) A π θ o l d ( s t , a t ) ] ≈ N 1 i = 1 ∑ N t = 0 ∑ T ( i ) − 1 γ t π θ o l d ( a t ( i ) ∣ s t ( i ) ) π θ ( a t ( i ) ∣ s t ( i ) ) A ^ t 这里 A ^ t ≈ A π θ o l d ( s t , a t ) \hat{A}_t\approx A^{\pi_{\theta_{old}}}(s_t,a_t) A ^ t ≈ A π θ o l d ( s t , a t ) N N N π θ ≈ π θ o l d \pi_{\theta}\approx \pi_{\theta_{old}} π θ ≈ π θ o l d
我们把上面的结果整理为如下算法
\begin{algorithm} \caption{TRPO MC} \begin{algorithmic} \STATE initial policy parameters $\theta_0$, initial value function parameters $\phi_0$. \STATE hyperparameters: $\delta>0$ \FOR {$k=0,1,\dots$} \STATE Sample $N$ trajectories $\{\tau_i\}$ according to $(p_0,\pi_{\theta_k}, p)$ \STATE Solve $$ \begin{aligned} \max_{\theta_{k+1}}\ &\frac{1}{N}\sum_{i=1}^N\sum_{t=0}^{T^{(i)}-1}\gamma^t\frac{\pi_{\theta_{k+1}}(a_t^{(i)}\mid s_t^{(i)})}{\pi_{\theta_k}(a_t^{(i)}\mid s_t^{(i)})}\hat{A}_t\\ \mathrm{s.t.}\ &\max_{s\in\mathcal{S}}\mathrm{KL}(\pi_{\theta_{k+1}}(\cdot\mid s)\mid\mid \pi_{\theta_{k}}(\cdot\mid s))\leq \delta \end{aligned} $$ \STATE $\hat{R}_t^{(i)}=\gamma^{t'-t}r_{t'}^{(i)}$, $i=1,\dots,N$, $t=1,\dots,T^{(i)}-1$ \STATE update the value model $$ \min_{\phi} \frac1N\sum_{i=1}^N\frac{1}{T^{(i)}}\sum_{t=0}^{T^{(i)}-1}\frac12\left(V_{\phi}(s_t^{(i)})-\hat{R}_t^{(i)}\right)^2 $$ \ENDFOR \end{algorithmic} \end{algorithm} 关于这个优化问题的解法可以参考后续 discussion 章节
我们将目标函数和约束进行泰勒展开得到
K ( θ ; θ o l d ) ≈ g T ( θ − θ k ) K L ( θ ∣ ∣ θ k ) ≈ 1 2 ( θ − θ k ) T H ( θ − θ k ) \begin{align}
\mathcal{K}(\theta;\theta_{old}) &\approx g^T(\theta-\theta_k) \\
\mathrm{KL}(\theta\mid\mid \theta_k)&\approx \frac12(\theta-\theta_k)^TH(\theta-\theta_k)
\end{align} K ( θ ; θ o l d ) KL ( θ ∣∣ θ k ) ≈ g T ( θ − θ k ) ≈ 2 1 ( θ − θ k ) T H ( θ − θ k ) 这样我们的优化目标就近似为
max θ g T ( θ − θ k ) s . t . 1 2 ( θ − θ k ) T H ( θ − θ k ) ≤ δ \begin{align}
\max_{\theta}\ & g^T(\theta-\theta_k)\\
\mathrm{s.t.}\ & \frac12(\theta-\theta_k)^TH(\theta-\theta_k)\leq\delta
\end{align} θ max s.t. g T ( θ − θ k ) 2 1 ( θ − θ k ) T H ( θ − θ k ) ≤ δ 这个目标函数与 TRO (trust region methods) 一致,因此我们可以使用类似的做法来解决,我们可以得到上面问题的准确表达式
θ k + 1 = θ k + 2 δ g T H − 1 g H − 1 g \theta_{k+1} = \theta_k + \sqrt{\frac{2\delta}{g^TH^{-1}g}}H^{-1}g θ k + 1 = θ k + g T H − 1 g 2 δ H − 1 g 但是,由于我们使用了 Taylor 展开,实际上我们的更新并不一定满足 KL divergence 的约束,TRPO 对此进行了改进,即在更新时加入了 line search 来使得 θ k + 1 \theta_{k+1} θ k + 1
θ k + 1 = θ k + α j 2 δ g T H − 1 g H − 1 g \theta_{k+1} = \theta_k + \alpha^j\sqrt{\frac{2\delta}{g^TH^{-1}g}}H^{-1}g θ k + 1 = θ k + α j g T H − 1 g 2 δ H − 1 g 其中 α ∈ ( 0 , 1 ) \alpha\in(0,1) α ∈ ( 0 , 1 ) j j j θ k + 1 \theta_{k+1} θ k + 1 k k k
虽然 TRPO 的理论形式非常简单,但是实际上实现起来很麻烦。其根本原因在于这个约束比较难以满足,原始论文中使用了 line search 来解决这个问题,但是当状态空间大了之后,速度会显著下降,这也是 PPO 的核心贡献之一。
在上一节中,我们介绍了 TRPO 算法,TRPO 算法是一个二阶算法,TRPO 大幅度提高了 sample efficiency, 但是其问题在于计算/优化太过复杂。因此,PPO 就通过 clip 等技巧保留了 TRPO 思想并降低了计算难度。
在 TRPO 算法中,我们的优化问题形式为:
max θ K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s . t . max s ∈ S K L ( π θ ( ⋅ ∣ s ) ∣ ∣ π θ o l d ( ⋅ ∣ s ) ) ≤ δ \begin{align}
\max_{\theta}\ &\mathcal{K}(\theta;\theta_{old}) = \mathbb{E}_{\tau\sim(p_0,\pi_{\theta_{old}}, p),a_t'\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]\\
\mathrm{s.t.}\ &\max_{s\in\mathcal{S}}\mathrm{KL}(\pi_\theta(\cdot\mid s)\mid\mid \pi_{\theta_{old}}(\cdot\mid s))\leq \delta
\end{align} θ max s.t. K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s ∈ S max KL ( π θ ( ⋅ ∣ s ) ∣∣ π θ o l d ( ⋅ ∣ s )) ≤ δ TRPO 的核心思想为,当 π θ \pi_{\theta} π θ π θ o l d \pi_{\theta_{old}} π θ o l d K ( θ ; θ o l d ) \mathcal{K}(\theta;\theta_{old}) K ( θ ; θ o l d ) J ( θ ) \mathcal{J}(\theta) J ( θ )
PPO 针对这一点核心观点进行了扩展,我们可以通过另一种形式来约束 π θ \pi_{\theta} π θ π θ o l d \pi_{\theta_{old}} π θ o l d
r t ( θ ) : = π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) ≈ 1 r_t(\theta) := \frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)} \approx 1 r t ( θ ) := π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) ≈ 1 基于这个思想,我们可以丢弃 TRPO 的约束,直接对 r t ( θ ) r_t(\theta) r t ( θ ) c l i p \mathrm{clip} clip
J ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ o l d ( ⋅ ∣ q ) [ c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ] \mathcal{J}(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},o_{\leq t}\sim \pi_{\theta_{old}}(\cdot\mid q)}\left[ \mathrm{clip}\left(r_t(\theta), 1-\epsilon, 1+\epsilon\right)\hat{A}_t \right] J ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ o l d ( ⋅ ∣ q ) [ clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ] 这里 ϵ > 0 \epsilon>0 ϵ > 0 δ \delta δ
c l i p ( x , ℓ , r ) = { ℓ , if x ≤ ℓ x , if ℓ < x < r r , if x ≥ r \mathrm{clip}(x,\ell, r)=\begin{cases}
\ell, &\text{ if }x\leq \ell\\
x, &\text{ if }\ell<x<r\\
r, &\text{ if }x \geq r
\end{cases} clip ( x , ℓ , r ) = ⎩ ⎨ ⎧ ℓ , x , r , if x ≤ ℓ if ℓ < x < r if x ≥ r 现在我们已经通过 c l i p \mathrm{clip} clip
从结果中我们可以看出,只有当 r t ≈ 1 r_t\approx 1 r t ≈ 1 A ^ t > 0 , r t < 1 − ϵ \hat{A}_t>0, r_t<1-\epsilon A ^ t > 0 , r t < 1 − ϵ A ^ t < 0 , r t < 1 − ϵ \hat{A}_t<0, r_t<1-\epsilon A ^ t < 0 , r t < 1 − ϵ c l i p \mathrm{clip} clip min \min min
J P P O ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ o l d ( ⋅ ∣ q ) [ min ( r t ( θ ) A ^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] \mathcal{J}_{\mathrm{PPO}}(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},o_{\leq t}\sim \pi_{\theta_{old}}(\cdot\mid q)}\left[ \min\left(r_t(\theta)\hat{A}_t,\mathrm{clip}\left(r_t(\theta), 1-\epsilon, 1+\epsilon\right)\hat{A}_t\right) \right] J PPO ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ o l d ( ⋅ ∣ q ) [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] 此时,我们再对目标函数进行分析,就得到
可以看到,此时 PPO 的目标函数就解决了 sample efficiency 过低的问题了。
其中
r t ( θ ) = π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) r_t(\theta) = \frac{\pi_{\theta}(o_t\mid q, o_{< t})}{\pi_{\theta_{old}}(o_t\mid q, o_{< t})} r t ( θ ) = π θ o l d ( o t ∣ q , o < t ) π θ ( o t ∣ q , o < t ) ( q , a ) (q,a) ( q , a ) D \mathcal{D} D ϵ > 0 \epsilon>0 ϵ > 0 A ^ t \hat{A}_t A ^ t t t t V V V R R R A ^ t \hat{A}_t A ^ t
A ^ t G A E ( γ , λ ) = ∑ k = 0 ∞ ( γ λ ) k δ t + k \hat{A}_t^{\mathrm{GAE}(\gamma, \lambda)}=\sum_{k=0}^{\infty}(\gamma\lambda)^k\delta_{t+k} A ^ t GAE ( γ , λ ) = k = 0 ∑ ∞ ( γ λ ) k δ t + k 其中
δ k = R k + γ V ( s k + 1 ) − V ( s k ) , 0 ≤ γ , λ ≤ 1 \delta_k = R_k + \gamma V(s_{k+1})-V(s_k),\quad 0\leq \gamma,\lambda\leq 1 δ k = R k + γ V ( s k + 1 ) − V ( s k ) , 0 ≤ γ , λ ≤ 1 相比于 PPO ,GRPO 不依赖于 value function, 因此不需要使用 reward model. GRPO 通过一组输出来估计 value V ( s ) V(s) V ( s ) ( q , a ) (q,a) ( q , a ) π θ o l d \pi_{\theta_{old}} π θ o l d G G G { o i } i = 1 G \{o_i\}_{i=1}^G { o i } i = 1 G { R i } i = 1 G \{R_i\}_{i=1}^G { R i } i = 1 G
A ^ i , t = r i − m e a n ( { R i } i = 1 G ) s t d ( { R i } i = 1 G ) \hat{A}_{i,t} = \frac{r_i - \mathrm{mean}(\{R_i\}_{i=1}^G)}{\mathrm{std}(\{R_i\}_{i=1}^G)} A ^ i , t = std ({ R i } i = 1 G ) r i − mean ({ R i } i = 1 G ) 最后,GRPO 的训练目标与 PPO 类似,只不过将 A ^ t \hat{A}_t A ^ t A ^ i , t \hat{A}_{i,t} A ^ i , t
J G R P O ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) [ 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) ] \mathcal{J}_{\mathrm{GRPO}}(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},\{o_i\}_{i=1}^G\sim \pi_{\theta_{old}}(\cdot\mid q)}\left[ \frac{1}{G}\sum_{i=1}^G\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\min\left(r_{i,t}(\theta)\hat{A}_{i,t},\mathrm{clip}\left(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon\right)\hat{A}_{i,t}\right) \right] J GRPO ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) G 1 i = 1 ∑ G ∣ o i ∣ 1 t = 1 ∑ ∣ o i ∣ min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) 其中,
r i , t ( θ ) = π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) r_{i,t}(\theta) = \frac{\pi_{\theta}(o_{i,t}\mid q, o_{i,< t})}{\pi_{\theta_{old}}(o_{i,t}\mid q, o_{i,< t})} r i , t ( θ ) = π θ o l d ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) KL divergence 的近似见 KL divergence