Introduction
A multimodal large language model (MLLM) usually consists of three parts: an encoder that ingests the information from different modality, a large language model (LLM) that is corresponds to complete various of downstream tasks given multimodal input such as image and text, and an adaption layer that aligns features of different modality to word embedding space of the LLM. Below is an example MLLM adopting aforementioned architecture: LLaVA [1]
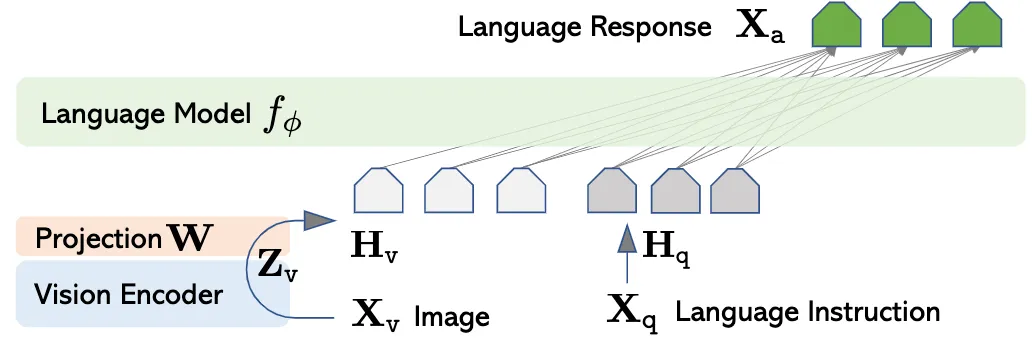
Efforts have been made to improve the performance of MLLMs. In this post, we aim to review the design of adaption layer and its potential effect on the downstream tasks.
Method
Suppose the hidden size of the LLM is , the feature produced by encoder is , where is the number of features (number of visual patches if is an visual encoder) and is the channel dimension. The adaption layer then aligns the feature with the word embedding space with , where is the number of tokens. As we can see, is actually a mapping from to .
Based on relationship between and , we can divide projection layers into two types:
- Feature-preserving adaption layer, where
- Feature-compressing adaption layer, where .
Feature-preserving adaption layer
Feature-preserving adaption layer does not change the number of features extracted by . It is used by LLaVA [1] and LLaVA 1.5 [2]. In LLaVA, the adaption layer is a linear layer [2], which is given by the code reads as:
# linear layer
adaption_layer = nn.Linear(config.hidden_size, config.num_features)
In LLaVA 1.5 , the adaption layer is a two-layer MLP, which is adopted be various of following works. It is given by
where , , is a activation function, specified as nn.GELU(). The code reads as:
# two-layer MLP
adaption_layer = nn.Sequential(
nn.Linear(config.num_features, config.hidden_size),
nn.GELU(),
nn.Linear(config.hidden_size, config.hidden_size)
)
Feature-compressing adaption layer
The feature compression adaption layers can be categorized into three types:
- average pooling
- attention pooling
- convolution mapping
They usually comprise two steps:
- reduce the number of features from to with a pooling operation:
- project compressed features to word embedding space with a transformation :
Average pooling This type of adaption layers use an average pooling as to reduce the number of tokens, followed by a two-layer MLP as , which is the same as LLaVA 1.5:
Perceiver Resampler This type of adaption layers use an cross-attention layer as , the transformation is also the same as LLaVA 1.5. where and is a learnable query.
class PerceiverResampler(nn.Module):
def __init__(self, num_queries, hidden_size, num_features, num_heads):
self.num_queries = num_queries
self.hidden_size = hidden_size
self.num_features = num_features
self.query_tokens = nn.Parameter(torch.zeros(self.num_queries, self.num_features), requires_grad=True)
self.query_tokens.data.normal_(mean=0.0, std=0.02)
self.attention = nn.MultiheadAttention(hidden_size, num_heads)
self.layer_norm_kv = nn.LayerNorm(hidden_size)
self.layer_norm_q = nn.LayerNorm(hidden_size)
def forward(self, x, attention_mask=None):
x = self.layer_norm_kv(x)
x = x.permute(1, 0, 2)
N = x.shape[1]
q = self.layer_norm_q(self.query_tokens)
q = q.unsqueeze(1).repeat(1, N, 1)
out = self.attention(q, k, v, attention_mask=attention_mask)[0]
out = out.permute(1, 0, 2)
adaption_layer = nn.Sequential(
PerceiverResampler(num_queries, hidden_size, num_features, num_heads),
MLP(hidden_size, intermediate_size, hidden_size)
)
C-Abstractor This type of adaption layers use a combination of convolution layer and averaging pooling as . is defined as an additional convolution layers. where and are the weights of the convolution layers.
D-Abstractor aa