在强化学习中,KL divergence 常被用作 policy 正则项,但很多不稳定现象并非来自 KL 本身,而是来自其估计方式。本文展示了为什么“无偏的 KL 估计”并不能保证“无偏的 KL 梯度”,并系统分析了不同 KL estimator 在 on-policy 与 off-policy 场景下的行为差异。通过理论推导与实验验证,文章揭示了 KL 作为 loss 与 reward shaping 时的本质区别,并解释了实践中低方差 KL 设计背后的原因。
在本节中,我们先介绍 KL divergence 的基本定义,然后我们介绍 KL divergence 的一般形式,即 f-divergence.
KL divergence 用于衡量近似概率分布 Q(x) 到真实概率分布 P(x) 的误差,我们可以将其理解为:如果我们用 Q(x) 来替换 P(x), 会有多大的信息损失?
连续概率分布的 KL divergence 的定义如下
DKL(P∥Q)=Ex∼P[logQ(x)P(x)]=∫P(x)log(Q(x)P(x))dx
离散概率分布的 KL divergence 定义如下
DKL(P∥Q)=x∑P(x)log(Q(x)P(x))
KL divergence 有如下几个关键性质:
- 非负性:DKL(P∥Q)≥0, 且 DKL(P∥Q)=0 当且仅当 P(x)=Q(x) 对任意 x 成立
- 非对称性: 一般情况下,DKL(P∥Q)=DKL(Q∥P).
- 有限性:如果存在 x 使得 P(x)>0 但是 Q(x)=0, 则 DKL(P∥Q)=∞.
一般我们称 DKL(P∥Q) 为 forward KL (相对于 Q), 对应的还有 reverse KL DKL(Q∥P) (相对于 Q).
KL divergence 是 f-divergence 的一种特殊情况。 f-divergence 是一类衡量不同概率分布 P 和 Q 的函数 Df(P∥Q).
假设函数 f:(0,∞)→R 是一个凸函数,且 f(1)=0. P 和 Q 是两个概率分布,则 f-divergence 定义如下
Df(P∥Q)=Ex∼Q[f(Q(x)P(x))]=∫Q(x)f(Q(x)P(x))dx
我们称 f 为 Df 的 generator.
以下是几种常见的 f-divergence:
我们这里推导一下 KL divergence 对应的 generator.
对于 forward KL, 注意到
Df(P∥Q)=∫Q(x)(Q(x)P(x)logQ(x)P(x))dx=∫P(x)logQ(x)P(x)dx=DKL(P∥Q)
因此 forward KL 对应的 generator 为 f=xlogx.
对于 reverse KL, 注意到
Df(P∥Q)=∫Q(x)(−logQ(x)P(x))dx=∫Q(x)logP(x)Q(x)dx=DKL(Q∥P)
因此 forward KL 对应的 generator 为 f=−logx.
f-divergence 性质如下
- linearity: Da1f1+a2f2=a1Df1+a2Df2.
- Df=Dg 当且仅当存在 c∈R 使得 f(x)=g(x)+c(x−1).
- non-negativity. Df(P∥Q)≥0 且 Df(P∥Q)=0 当且仅当 P=Q.
性质 2 证明如下:
如果 f(x)=g(x)+c(x−1), 则通过定义,我们可以验证得到 Df=Dg.
反之,如果 Df=Dg, 令 h=f−g, 对任意两个在集合 {0,1} 上的概率分布 P,Q, 由于 Df(P∥Q)−Dg(P∥Q)=0, 我们有
h(Q(1)P(1))=−Q(1)Q(0)h(Q(0)P(0))
我们不妨假设 P(0)=aQ(0), P(1)=bQ(1), 结合 P(0)+P(1)=1 和 Q(0)+Q(1)=1 我们有
Q(0)=b−a1−a,Q(1)=b−ab−1
从而
b−1h(b)=a−1h(a)
由于我们可以任意选定 P 和 Q, 因此 h 是一个线性函数,形式为 h(x)=c(x−1). ■
本节中,我们将介绍针对 KL divergence 的三种近似形式。
在实际计算 KL divergence 时,由于:
- 完整计算 KL divergence 需要的算力或内存过高
- 没有闭式解
- 我们可以仅保存 log-probability, 而不是整个概率分布
因此,我们假设我们只能计算输入 x 对应的概率 P(x) 和 Q(x). 一般来说,我们会通过 Monte Carlo estimate 来进行近似。即我们先对 P 进行采样得到 x1,…,xN∼P, 然后我们构建估计量。
一个高的估计量应该是无偏 (unbiased) 并且方差低 (low variance) 的。John Schulman 给出了三种 estimator. 我们分别针对 forward KL 和 reverse KL 进行介绍。这里我们定义
r=Q(x)P(x)
对于 forward KL DKL(P∥Q), 其对应的 generator 为 f(x)=xlogx, 注意到 Ex∼Q[r]=1, 且 f 是一个凸函数,因此我们有 f(r)−f′(1)(r−1)≥0, 从而我们可以得到一个新的估计为 k=rlogr−(r−1).
对于 reverse KL DKL(Q∥P), 其对应的 generator 为 f(x)=−logx, 由概率性质,k1=−logr 是 DKL(Q∥P) 的一个无偏估计。但是 k1 的问题在于 当 r 非常小时,k1 会变得非常大。也就是说,k1 的 variance 比较高。
John Schulman 基于 f-divergence 泰勒展开给出了一个新的估计 k2, 其定义为
k2=21(logr)2
其期望为
EQ[k2]=EQ[21(logr)2]
这是一个 f-divergence, 对应的 generator 为 fk2(x)=1/2(logx)2, 而 DKL(Q∥P) 对应的 generator 为 fk1(x)=−logx.
当 P 和 Q 比较靠近时,我们记 θ=r−1, 对 Df(P∥Q) 在 x=1 处进行展开得到
Df(P∥Q)=Ex∼Q[f(r)]=Ex∼Q[f(1)+f′(1)θ+2f′′(1)f(1+λ)θ2+O(θ3)]=2f′′(1)Fθ2+O(θ3)
这里我们应用了 f(1)=0, E[θ]=0, F=E[f(1+λθ) 是 Fisher information matrix.
我们分别带入 fk1(x) 和 fk2(x) 得到 fk1′′(1)=fk2′′(1)=1, 即 k1 和 k2 在 P 和 Q 比较靠近时二阶近似是相同的。因此,**k2 表面上是一个二阶近似,在分布接近时有效,但本质上是在优化 另一个 f-divergence*
John Schulman 还构造了第三种估计。回顾前面 f-divergence 的性质 2,即当 f(x)=g(x)+c(x−1) 时,我们有 Df=Dg, 因此我们可以选取合适的 c 来降低估计的 variance. 注意到 k1 的主要问题在于存在负数的可能性,因此我们就构建一个对应的估计量来解决这个问题。注意到 logx≤x−1, 因此我们可以令 c=1, 此时就得到了新的估计
k3=(r−1)−logr
k3 继承了 k1 的无偏性,并且 k3 通过 f-divergence 等价类消除了负值,兼顾无偏与低方差,解决了 k1 variance 过大的问题
对于分布 P=N(0,1) 以及 Q=N(0.1,1), 真实的 KV divergence 为 0.005, 三个 estimator 的误差如下表所示
当 P=N(1,1), Q=N(0.1,1) 时, 真实的 KV divergence 为 0.405, 三个 estimator 的误差如下表所示
可以看到 k1 的 variance 非常大,k2 是一个有偏估计,k3 既满足了无偏又满足了 low variance.
我们接下来总结 reverse KL DKL(Q∥P) 的近似 k1, k2 和 k3 的性质如下 (r=P(x)/Q(x))
Remark
本节内容主要参考了 KL Divergence for Machine Learning
我们假设真实目标分布和近似的目标分布分别记为 pdata(x) 和 pθ(x). 由于 KL divergence 的非对称性,因此我们需要考虑两种目标函数:
- forward KL: argminθDKL(pdata∥pθ)
- reverse KL: argminθDKL(pθ∥pdata)
我们将会看到,这两种不同的目标函数导致的结果也不尽相同
对目标函数进行简化得到
argθminDKL(pdata∥pθ)=argθmaxEx∼pdata[logpθ(x)]
实际在计算时,我们会使用 Monte Carlo 的方式对真实分布进行采样然后进行估计。
Forward KL 其代表的含义为,我们从分布 pdata 中进行采样,然后求 pθ 的最大似然估计。最终的结果满足:当 pdata(x) 概率很高时,pθ(x) 的概率也需要很高. 这是一种 mean-seeking behavior, 因为 pθ 必须覆盖 pdata 的所有 modes.
一般来说,supervised learning 对应的就是 forward KL. 我们可以证明 forward KL divergence 和 MLE 是等价的。也就是说,最大似然估计得到的分布就是 KL divergence 最小的近似分布。我们将 pdata(x) 和 pθ(x) 对应的 KL divergence 进行展开得到
θKL∗=argθminDKL(pdata(x)∥pθ(x))=argθmin∫pdata(x)pθ(x)pdata(x)dx=argθmin∫pdata(x)logpdata(x)dx−∫pdata(x)logpθ(x)dx=argθmin−∫pdata(x)logpθ(x)dx=argθmax∫pdata(x)logpθ(x)dx
实际上,真实的数据分布 pdata(x) 是未知的,我们只有从 pdata(x) 采样得到的一批数据 X={x1,…,xn}∼pdata(x). 基于大数定律,我们有
n1i=1∑nlogp(θi∣θ)=Ex∼pdata[logpθ(x)]=∫pdata(x)logpθ(x)dx,n→∞
这样,最大似然估计就与最小化 KL divergence 构建起了联系:
θMLE∗=argθmaxi=1∑nlogp(xi∣θ)=argθmax∫pdata(x)logpθ(x)dx=θKL∗,n→∞.
也就是说,当采样样本足够多的时候,最大似然估计和最小 KL divergence 是等价的。监督学习中,我们先从真实分布 pdata(x,y) 中收集一个数据集 D={(xi,yi)}, 然后我们会基于模型 fθ:X→Y 和损失函数 L:Y×Y→R 来优化模型参数 θ:
argθminE(xi,yi)∼D[L(fθ(xi),yi)]
对于使用 cross-entropy loss 的分类问题以及 MSE loss 的回归问题,其目标函数实际上都是最小化 KL divergence.
对目标函数进行简化,得到
argθminDKL(Qθ∥pdata)=argθmaxEx∼Qθ[logpdata(x)]−Ex∼Qθ[logQθ(x)]
实际在计算时,我们需要知道真实概率分布在采样点上的概率值 pdata(x).
Reverse KL 代表的含义为,我们从分布 pθ(x) 中进行采样,然后最大化采样点在 pdata(x) 中的概率分布。entropy item 鼓励 pθ 尽可能均匀分布(覆盖广),从而最终结果满足:当 pθ(x) 概率很高时,pdata(x) 的概率也需要很高。注意到与 forward KL 不同,Reverse KL 中包含 entropy 项,其避免了 pθ 收缩到 pdata 的某一个 非常窄的 mode 上,最终结果是 pθ 会找到 pdata 的一个 high probability 以及 wide support 的 mode, 然后进行覆盖。
一般来说,reinforcement learning 对应的就是 reverse KL, 这是因为我们希望 policy model 不要离 reference model 太远,并不一定要 cover 所有的 mode.
我们通过概率分布来可视化 forward KL 与 reverse KL 的区别,验证二者不同的模式。
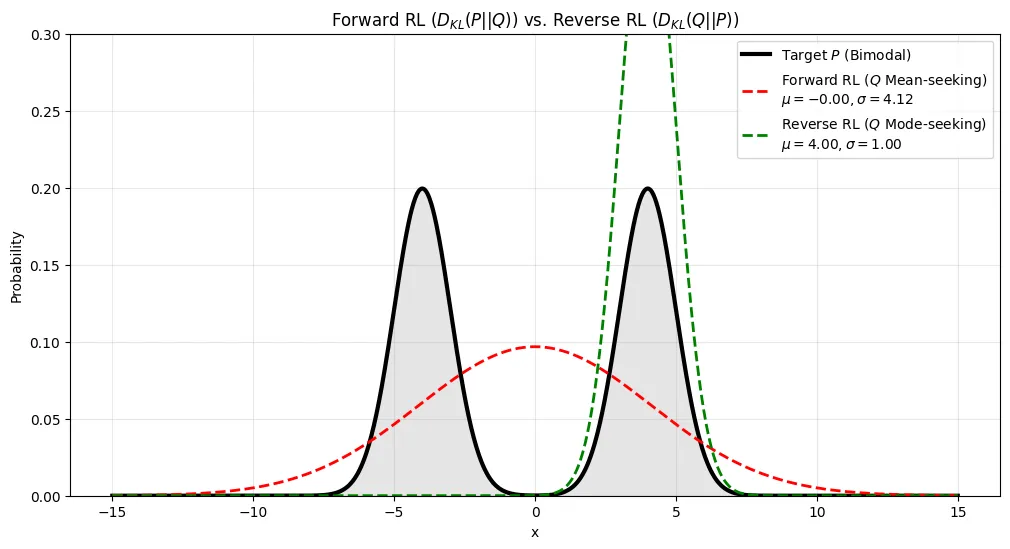
我们假设 pdata=w1N(μ1,σ12)+w2N(μ2,σ22), 然后我们用一个 normal distribution pθ=N(μ,σ2) 来近似 pdata, 这里 θ=(μ,σ2). 对于 forward KL, 我们可以从理论上得出最优解,对应的 μ=w1μ1+w2μ2, 而 reverse KL 则只能通过优化的方式进行求解,并且解与初始化条件相关,下面是相关的实验结果
首先我们令 w1=w2=0.5, μ1=μ2=4.0, σ1=σ2=1, reverse KL 的初始化条件为 θ0=(2,1), 对应的结果为
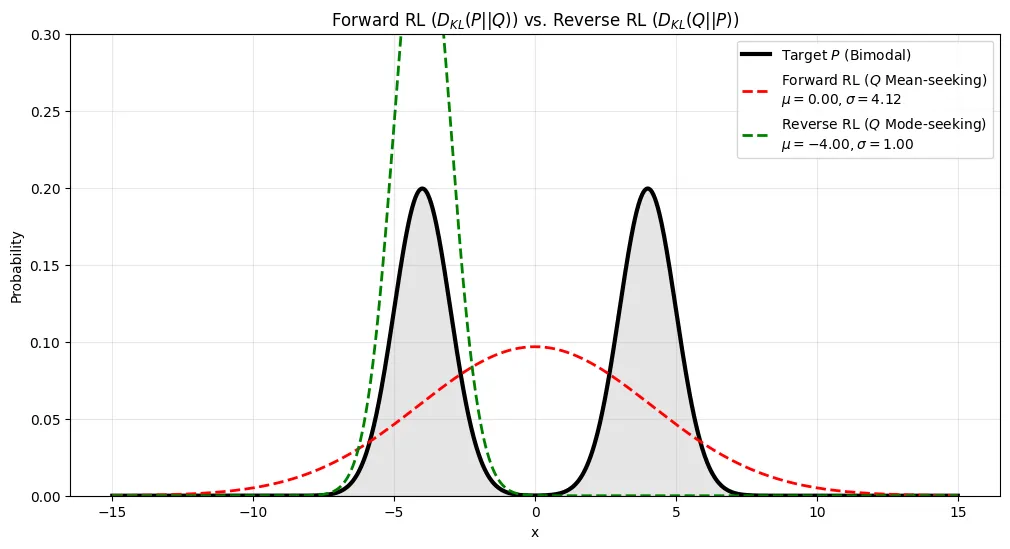
接下来我们改变 reverse KL 的初始化条件为 θ0=(−2,1), 对应的结果为
可以看到,与前面分析一致,使用 forward KL 时,最终得到的 pθ 会倾向于拟合分布的中心 (mean seeking), 即 μ(pθ)=μ(pdata), 而使用 reverse KL 时,最终得到的 P 会倾向于拟合分布的 mode (mode seeking).
Remark
本节内容主要参考了 Understanding KL Divergence Estimators in RL: From Value Approximation to Gradient Estimation
在本节中,我们将基于 RL 来推导 KL 的相关性质。为了统一,这里我们使用 RL 中常见的 notation 来进行计算
首先 score function 有一个期望为 0 的性质:
Ex∼πθ[sθ(x)]=∫xπθ(x)∇θlogπθ(x)dx=∫x∇θπθ(x)dx=∇θ∫xπθ(x)dx=∇θ1=0
接下来,我们分别推导 forward KL 和 reverse KL 的梯度。对于 forward KL, 我们有
∇θDKL(πref∥πθ)=−∫πref∇θlogπθdx=−Eπref[sθ]=−Eπθ[πθπrefsθ]
对于 reverse KL,我们有
∇θDKL(πθ∥πref)=∫[∇θπθ⋅logπrefπθ+πθ∇θlogπrefπθ]dx=∫πθsθlogπrefπθdx+∫πθsθdx=Eπθ[sθlogπrefπθ]+Eπθ[sθ]=Eπθ[sθlogπrefπθ]
这里我们使用了 ∇θπθ=πθsθ , ∇θlogπθ=sθ 以及 前面推导的 Eπθ[sθ]=0 的结论.
RL 的目标函数如下
J(θ)=Eτ∼πθ[t=0∑Tγtr(st,at)]−βDKL(πθ∥πref)
由于 KL divergcne 不能直接计算(或者计算难度较大),因此,基于前面对 KL divergence estimation 的分析,我们可以使用如下代理损失函数来优化我们的模型:
J1(θ)=Eτ∼πθ[t=0∑Tγtr(st,at)]−βki(πθ,πref)
这里 i∈{1,2,3} 代表了我们使用的估计。从直觉上来说,这样做是没问题的,但是我们将从数学分析上说明,k1,k3 作为损失函数都存在问题。其核心问题在于
E[DKL]=DKL⇏E[∇θDKL]=∇θDKL
也就是说,KL divergence estimation 的无偏性不能推导出 KL divergence estimation gradient 的无偏性,这是因为我们在求期望时,对应的概率分布可能也与参数相关。实际上,我们有
∇θDKL(πθ∥πref)=∇θEx∼πθ[DKL(πθ∥πref)]=Ex∼πθ[∇θDKL(πθ∥πref)]+Ex∼πθ[DKL(πθ∥πref)∇θπθ(x)]=Ex∼πθ[∇θDKL(πθ∥πref)]
因此 ∇θDKL 是 ∇θDKL 的一个有偏估计。
我们分别来分析一下 k1,k2,k3 梯度,
∇θk1∇θk2∇θk3=∇θ[−logπθπref]=sθ=∇θ[21(logπθπref)2]=−logπθπrefsθ=∇θ[πθπref−1−logπθπref]=(1−πθπref)sθ
此时对应的梯度的期望为
Eπθ[∇θk1]Eπθ[∇θk2]Eπθ[∇θk3]=Eπθ[sθ]=0=Eπθ[−logπθπrefsθ]=∇θDKL(πθ∥πref)=Eπθ[(1−πθπref)sθ]=∇θDKL(πref∥πθ)
也就是说,k1 估计的梯度的期望为 0,对整体训练没有任何帮助,k3 估计的梯度的期望等价于优化 forward KL, **只有 k2 估计的梯度的期望等价于优化 reverse KL.
在实际代码实现的时候,KL divergence 有两种不同的实现形式:
第一种是根据定义将 KL divergence 作为损失函数的一部分,此时我们的 KL divergence 参与反向传播,对应的实现方式如下
loss = -advantage * log_prob + beta * kl
第二种是只调整 reward, 而不参与反向传播(通过 sg(⋅) 实现),对应的实现方式如下所示
shaped_reward = reward - beta * kl.detach()
这两者对于模型的训练影响很大,下面我们分别来进行介绍
为了统一 on-policy 和 off-policy 两种形式,我们使用一个统一的表达形式,即
L=ρki
此时对应的 RL 目标函数为
J2(θ)=Eτ∼πθ[t=0∑Tγtr(st,at)]−βρki(πθ,πref)
这里
ρ=sg(πold)πθ
是 importance weight,
- 当算法为 on-policy 时,πθ=πold, ρ≡1.
- 当算法为 off-policy 时,ρ=πθ/πold, ∇θρ=ρsθ.
通过这种方式,我们使得参数分布本身不会对梯度计算产生影响,从而使得对期望进行求导和对导数求期望相等,即
∇θEπold[k]=∫πold(x)∇θkdx=Eπold[∇θk]
接下来我们来计算对应估计的梯度的期望,即 E[∇θ(ρki)], 首先我们计算对应的梯度
∇θ(ρk1)∇θ(ρk2)∇θ(ρk3)=ρsθk1+rρθ=ρsθ(k1+1)=ρsθk2+ρ(−logπθπrefsθ)=ρsθ(k1+k2)=ρsθk3+ρ(1−πθπref)sθ=ρsθ(k3+1−πθπref)=ρsθk1
注意到 Eπold[ρki]=Eπθ[ki] 以及 Eπθ[sθ]=0, 我们对上述梯度求期望得到
Eπold[∇θ(ρk1)]Eπold[∇θ(ρk2)]Eπold[∇θ(ρk3)]=Eπold[ρsθ(k1+1)]=Eπθ[sθk1]=∇θDKL(πθ∥πref)=Eπold[ρsθ(k1+k2)]=∇θEπθ[k2]=Eπold[ρsθk1]=∇θDKL(πθ∥πref)
这里在计算 Eπold[∇θ(ρk2)] 时,我们使用了 Leibniz 乘法法则:
Eπold[ρsθ(k1+k2)]=Eπθ[sθk2]+Eπθ[∇θk2]=∇θEπθ[k2]
可以看到,ρk1 和 ρk3 都满足梯度与期望的可交换性,而 ρk2 不满足,为了解决这个问题,我们可以使用 stop gradient, 即 sg(ρ)l2, 此时,我们有
∇θ(sg(ρ)k2)=sg(ρ)∇θk2=ρsθk1
对其求期望有
Eπold[∇θ(sg(ρ)k2)]=Eπold[ρsθk1]=Eπθ[sθk1]=∇θDKL(πθ∥πref)
我们将如上结果总结为下表
接下来,我们就可以分析在 on-policy 和 off-policy 场景下分析不同 estimator 的性质了。
如果说,我们显式加入 ρ, 则根据上表我们可以使用上表的 ρk1, sg(ρ)k2 以及 ρk3 都可以作为损失函数的代替。
注
实际上 on-policy 场景下使用 k2 也有用的原因在于 ∇θk2=sθk1, 也就是 k2 和 ρk3 的梯度相同,其本质上是一个等效梯度。但是其收敛得到的 policy 与 target optimal policy 不同
接下来,我们来分析一下 ρk1,sg(ρ)k2,ρk3 这三种估计的梯度的 variance, 为了避免混淆,【2】使用了 “projection variance in any direction” 的概念,即任意取一个向量 u, 然后计算 ρk1 和后两者之间对应的 variance 的差(由于 sg(ρ)k2 的梯度与 ρk3 相同,因此这里我们仅计算 ρk3),得到:
var[∇θ(ρk1)Tu]−var[∇θ(ρk3)Tu]=(Eπold[(∇θ(ρk1)Tu)2]−Eπold2[∇θ(ρk1)Tu])−(Eπold[(∇θ(ρk3)Tu)2]−Eπold2[∇θ(ρk3)Tu])=Eπold[(∇θ(ρk1)Tu)2]−Eπold[(∇θ(ρk3)Tu)2]=Eπold[ρ(x)2(s(θ)(x)Tu)2(2k1(x)+1)]
当 πθ 和 πref 比较接近时,我们有
πθ(x)πref(x)=1+ϵ(x), where ∣ϵ(x)∣≪1
此时
2k1(x)+1=1−2log(1+ϵ(x))≈1−2ϵ(x)≥0
从而我们有
var[∇θ(ρk1)]≥var[∇θ(ρk3)]=var[∇θ(sg(ρ)k2)]
即当 πθ 和 πref 比较接近时,ρk3 的 variance 比 ρk1 更小,这是由于 ρsθ(k1+1) 额外包含了一个 期望为零的项,这导致了其 variance 比较高。在 DeepSeek-V3.2 中,作者就使用了 ρk3 来降低梯度的 variance, 提高训练的稳定性。
【3】将相关的估计总结为了下表的形式
【3】还强调了一点就是我们的损失函数必须显式包含 ρ, 在 on-policy 场景下,虽然 ρ≡1, 但是在反向传播时我们通过 ∇θρ=sθ 保留了采样信息从而避免了梯度估计期望的错配问题。
对于 ρk1 variance 比较高的特点,我们还可以采用 variance reduction 的方法来降低不同估计的 variance. 【TODO】
analytic gradient
当 action space 有限时,我们还可以使用解析梯度【TODO】
接下来我们来探究一下第二种形式,即 KL divergence 只影响最终的 reward, 而不参与反向传播。对应的代理目标函数形式为
J3(θ)=Eτ∼πθ[R]−β sg(ki(πθ,πref))
这里 R=∑t=0Tγtr(st,at) 为 accumulative reward
首先,基于前面分析,我们可以得到原始目标函数的梯度为
∇θJ(θ)=∇θEπθ[R]−β∇θDKL(πθ,πref)=Eπθ[sθR]−βEπθ[sθlogπrefπθ]=Eπθ[sθ(R−βk1)]
代理目标函数的梯度为
∇θJ3(θ)=Eπθ[sθ(R−βki)]
显然,当我们使用 k1 时,我们有 ∇θJ(θ)=∇θJ3(θ).
当我们使用 k2 时,带入 k2 表达式易知 ∇θJ3(θ)=∇θJ(θ),
当我们使用 k3 时,
Eπθ[sθki]=Eπθ[sθ(πθπref−1−logπθπref)]=Eπθ[sθπθπref]−Eπθ[sθ]−Eπθ[sθlogπθπref]=sθk1−∇θDKL(πref∥πθ)
此时,∇θJ3(θ)=∇θJ(θ). 因此,在 on-policy 场景下,只有 k1 对应的梯度是无偏的
在 off-policy 场景下,由于 Off-policy 只影响 R 的计算,因此原始目标函数和代理目标函数的梯度仍然保持不变,on-policy 场景的结论也适用。
总之,当我们将 KL divergence 作为 reward reshaping item 时,只有 k1 产生的梯度是无偏的。
接下来我们来比较一下 KL divergence 作为 loss 和 reward shaping item 的异同之处。首先,两者对于梯度的贡献分别为
ρsθk1Eπold[ρsθk1](loss)(reward shaping)
即两者在期望上时一致的。但是两者也存在不一致的地方,即 KL divergence 作为 loss 时不会影响 R, 而作为 reward shaping item 时会影响。因此这就导致两者的优化方向不一致。
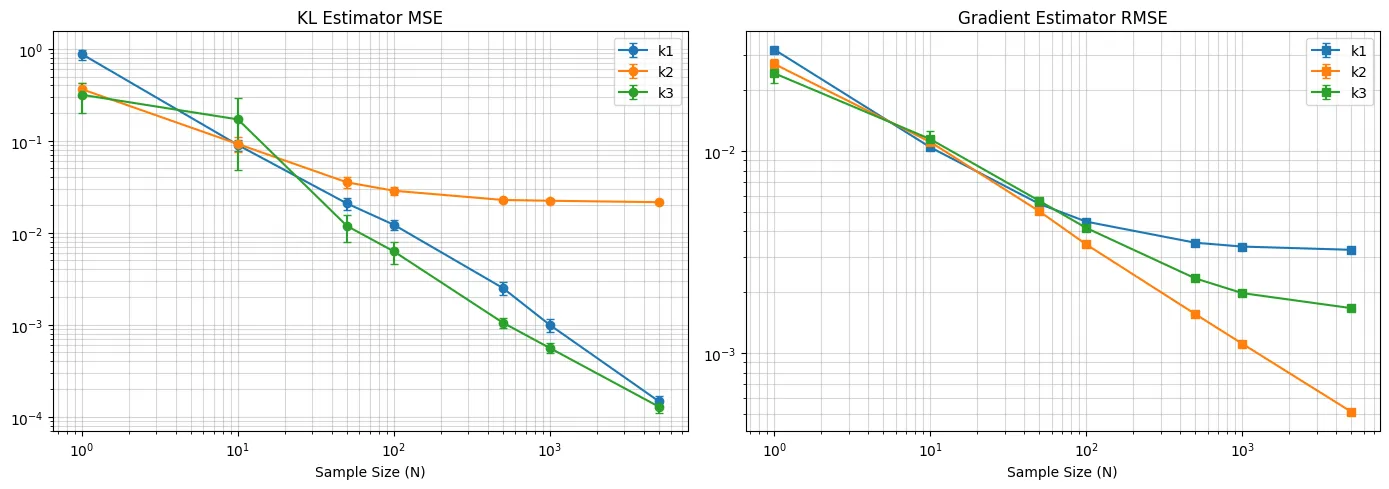
首先,我们来验证前面的结论,我们构造一个包含 100 个 arms 的 multi-arm bandits, 然后令
πref=ϵ1,π=ϵ1+ϵ2
其中 ϵ1,ϵ2∼N(0,1), 我们实验 100 次然后取平均值,然后分别计算 estimator 与真实 KL divergence 之间的 MSE 和 estimator gradient 与真实 kl divergence gradient 的 RMSE, 结果如下图所示
可以看到,这验证了我们之前分析的结论,即 k1 和 k3 是无偏估计,而在计算梯度时,只有 k2 梯度的期望与真实 KL divergence 的梯度相同。
我们在本节总结前面的分析,如下表所示
在本文中,我们详细介绍了 KL-divergence 的基本性质,相关估计方法以及在机器学习特别是 RL 领域中的应用。最终结论为:
- 如果希望稳定可控,则将 KL divergence 作为 loss item; 如果希望更灵活,与奖励信号结合的话,则将其作为 reward shaping item.
- 使用 KL divergence 作为 loss item 时,on-policy 场景下使用 k2 近似 KL divergence 效果最好;off-policy 场景下,使用 sg(ρ)k2,ρk3 效果最好
- 使用 KL divergence 作为 reward shaping item 时,k1 的效果最好