介绍
Meta在2025年4月10号发布了LLaMA4系列,包含三个模型:Llama 4 Scout, Llama 4 Maverick 以及Llama 4 Behemoth, 三个模型都基于MoE架构,且支持多模态
| Model | Layers | Heads (Q / KV) | Context Length | #Parameters (activated/total) | #Experts (activated/total) | #Tokens |
|---|---|---|---|---|---|---|
| LLaMA 4 Behemoth | - | - | - | 288B / 2T | (1 shared + 1 routed) / 16 | - |
| LLaMA 4 Maverick | 48 | 40/8 | 1M | 17B / 109B | (1 shared + 1 routed) / 128 | ~22T |
| LLaMA 4 Scout | 48 | 40/8 | 10M | 17B / 400B | (1 shared + 1 routed) / 16 | ~40T |
训练数据截止到2024年8月。LLaMa4支持200多种语言,其中100多种语言的训练token数超过了1B
亮点
- 原生多模态 LLaMA 4是一个原生多模态架构
- 超长上下文 LLaMA 4的上下文超过了1M
- iRoPE 通过交替dense和MoE MLP来提高整体推理效率
- 基于MetaCLIP的vision encoder
- MetaP 使用MetaP来调整超参数
- FP8精度训练
Pre-training
LLaMA 4 仍然是一个基于transformer的架构,但是引入了MoE,其示意图如下所示
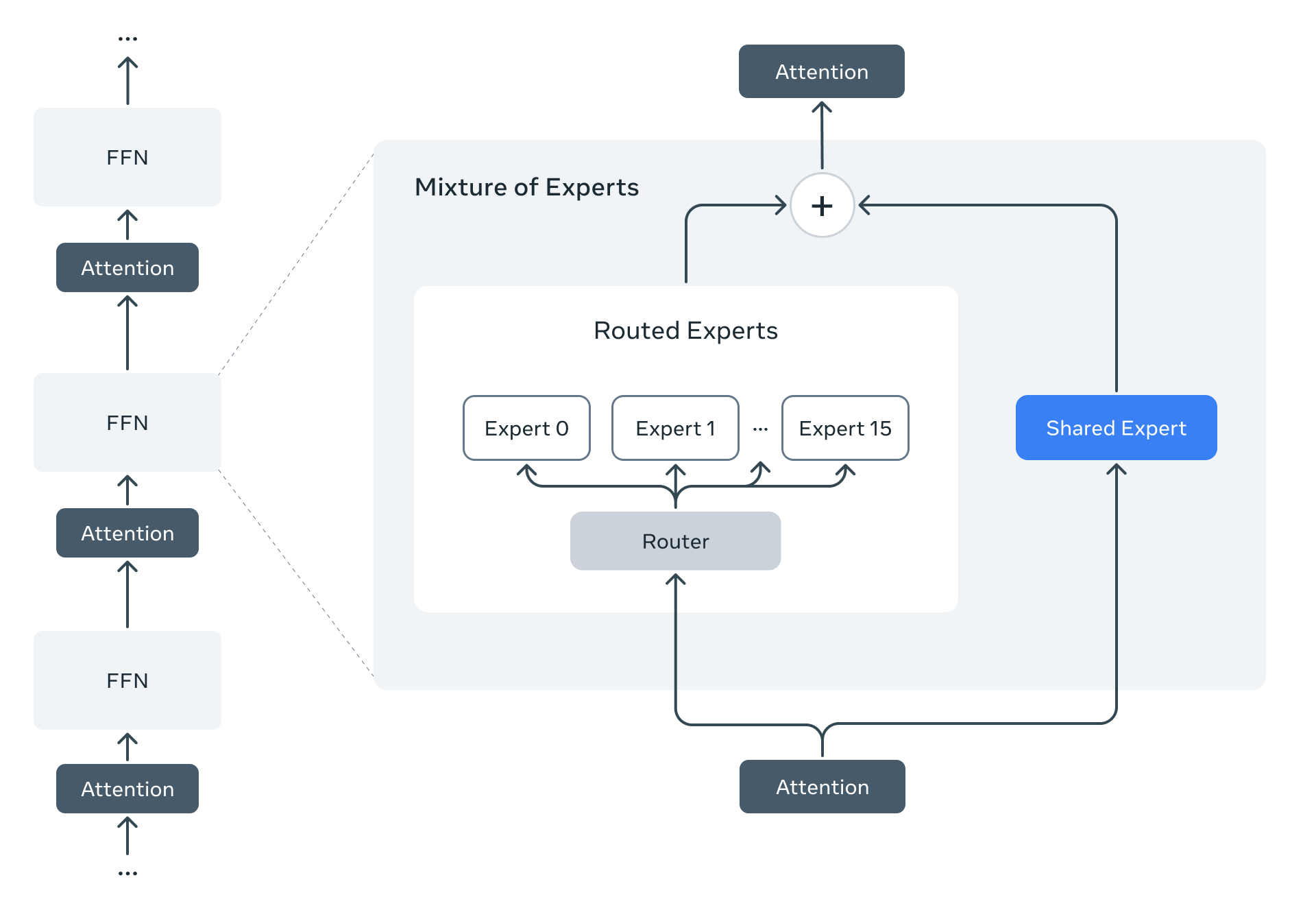
MoE架构中包含1个shared expert以及1个routed expert. 并且,与其他LLM不同,LLaMA 4使用了一个交替MLP个MoE的架构,即iRoPE,即特定的transformer layer是MoE架构,其余的是MLP架构,其核心代码如下:
| |
early fusion. LLaMA 4称其一个原生多模态大模型,但是其架构仍然是 Vision Encoder-MLP-LLM 的形式,其不同点在于patch embedding没有使用convolution, 而是使用 nn.Unfold直接进行展平,然后使用一个线性层与vision encoder进行对齐。代码如下
| |
其他训练优化技巧如下:
- MetaP:用于选择超参数
- FP8 precision:与DeepSeek-V3一样,使用FP8精度进行训练
- mid-training:在预训练阶段之后,额外增加了一个训练阶段,来提高模型的长上下文等关键能力
Post-training
post-training包括三个阶段:
- SFT
- online RL
- DPO
作者发现SFT和DPO会限制模型的探索能力,特别是在math, coding等domain。为了解决这个问题,作者使用LlaMA对问题进行难度分级,然后移除了50%的简单数据。
在online RL阶段,作者设计了一个continuous online RL策略,让模型在训练和筛选问题两种模式之间进行切换,以平衡效率和准确率。
DPO的目的是为了提升模型输出的质量
评测
| benchmark | LLaMA 4 Maverick | LLaMA 4 Maverick | LLaMA 4 Scout | Gemeni 2.0 Flash | GPT-4o |
|---|---|---|---|---|---|
| MMMU | 76.1 | 73.4 | 69.4 | 71.7 | 69.1 |
| Math Vista | 73.7 | 70.7 | 73.1 | 63.8 | |
| ChartQA | - | 90.0 | 88.8 | 88.3 | 85.7 |
| DocVQA | - | 94.4 | 94.4 | - | 92.8 |
| LiveCodeBench | 49.4 | 43.4 | 32.8 | 34.5 | 32.3 |
| MMLU Pro | 82.2 | 80.5 | 74.3 | 77.6 | - |
| GPQA Diamond | 73.7 | 69.8 | 57.2 | 60.1 | 53.6 |
结论
LLaMA 4 采用了MoE架构,是一个原生的多模态大模型系列。在架构上,与DeepSeek-MoE, aria和OLMoE不同,LLaMA4并没有增加expert granularity,OLMoE分析认为,增加granularity可以提高模型的flexibility, 下面总结了一下相关模型的参数
| Model | Layers | Heads (Q / KV) | Context Length | #Parameters (activated/total) | #Experts (activated/total) | #Tokens |
|---|---|---|---|---|---|---|
| DeepSeek-MoE(144.6B) | 62 | 32/32 | 2048 | 22.2B/144.6B | (1 shared + 7 routed)/64 | 245B |
| DeepSeek-V3 | 61 | 128(MLA) | 128K | 37B/671B | (1 shared + 8 routed)/257 | 14.8T |
| Aria | 28 | 20/20 | 64K | 3.5B/24.9B | (2 shared+ 6 routed)/66 | 6.4T(text) |
| OLMoE | 16 | 16/16 | 4096 | 1.3B/6.9B | 8/64 | 5T |
| LLaMA 4 Maverick | 48 | 40/8 | 1M | 17B / 109B | (1 shared + 1 routed) / 128 | ~22T |
| LLaMA 4 Scout | 48 | 40/8 | 10M | 17B / 400B | (1 shared + 1 routed) / 16 | ~40T |