本文中,我们将介绍如何计算 LLM 在训练和推理过程中的内存需求以及简要介绍对应的优化方法。
Introduction
我们在本文中回答的核心问题为:
在训练和推理时 LLM 所需要的内存是多少?如何进行优化内存占用?
为了回答这两个问题,我们需要回答以下问题:
- 训练和推理时的内存由哪几部分组成?
- 训练和推理过程中哪个阶段是 memory-bound? 哪个阶段是 compute bound?
- 训练和推理过程中如何进行优化?
我们将首先介绍如何计算 LLM 在训练阶段和推理阶段的内存。接下来,我们针对可优化部分进行分析以及介绍相应的优化算法。后续,我们将针对每部分的优化进行详细介绍
Background
首先我们介绍一下使用的 notation, 这与之前参数量,FLOPs 计算使用的 notation 基本一致。需要注意的是,我们直接使用参数量 $P$ 这个记号,这部分在 LLM parameter analysis 中已经进行了详细介绍,因此我们略过这部分。
| variable | description |
|---|---|
| $P$ | number of parameters |
| $L$ | layers |
| $V$ | vocabulary size |
| $d$ | hidden size |
| $d_{ff}$ | FFN hidden size |
| $s$ | sequence length |
| $b$ | batch size |
| $h$ | number of attention heads |
| $d_h$ | attention head dimension |
Assumption
- 没有特别说明的话,我们使用 BF16/FP16 作为精度,此时每个参数需要 $2$ byte 来表示
- 不使用 dropout (现代大模型普遍没有 dropout)
Computation
Overview
我们首先给出训练和推理阶段各部分的内存需求,然后我们给出详细的计算公式
| component | 训练 | 推理 |
|---|---|---|
| weights | Fixed | Fixed |
| optimizer states | Fixed and massive | 0 |
| gradients | Fixed | 0 |
| activations | Large (stored for backprop) | Tiny (discarded after use) |
| KV cache | 0 | Large (grows with sequence) |
Training
LLM 训练阶段对的内存开销包含三部分
$$ \text{Memory}_{\text{train}} = \text{Memory}(\text{weight}) + \text{Memory}(\text{activation}) + \text{Memory}(\text{optimizer})+\text{Memory}(\text{gradient}) $$Weights
我们在前面已经介绍了如何计算大语言模型的参数量,这里我们就直接记为 $P$, 由于我们使用单精度,因此所需要的内存为 $2P$.
Activation
激活值(activation)是前向传播过程中产生的中间张量,反向传播计算梯度时需复用这些张量,因此训练阶段需全程存储。我们用一个简单的例子来进行说明,假设我们有一层神经网络,定义为
$$ \begin{aligned} \mathbf{z}_l &= W_l\mathbf{a}_{l-1}+b_l\\ \mathbf{a}_{l} &= \phi(\mathbf{z}_l) \end{aligned} $$那么在反向传播过程中,我们有
$$ \frac{\partial \mathcal{L}}{\partial W_l} = \frac{\partial \mathcal{L}}{\partial \mathbf{z}_l}\frac{\partial \mathbf{z}_l}{\partial W_l}=\frac{\partial \mathcal{L}}{\partial \mathbf{z}_l} \mathbf{a}_{l-1} $$也就是说,在计算第 $l$ 层的参数对应的梯度时,我们需要知道对应的输入 $\mathbf{a}_{l-1}$.
接下来,我们通过计算图来分析 LLM 所需要的 activation
Attention Attention 的计算图如下所示
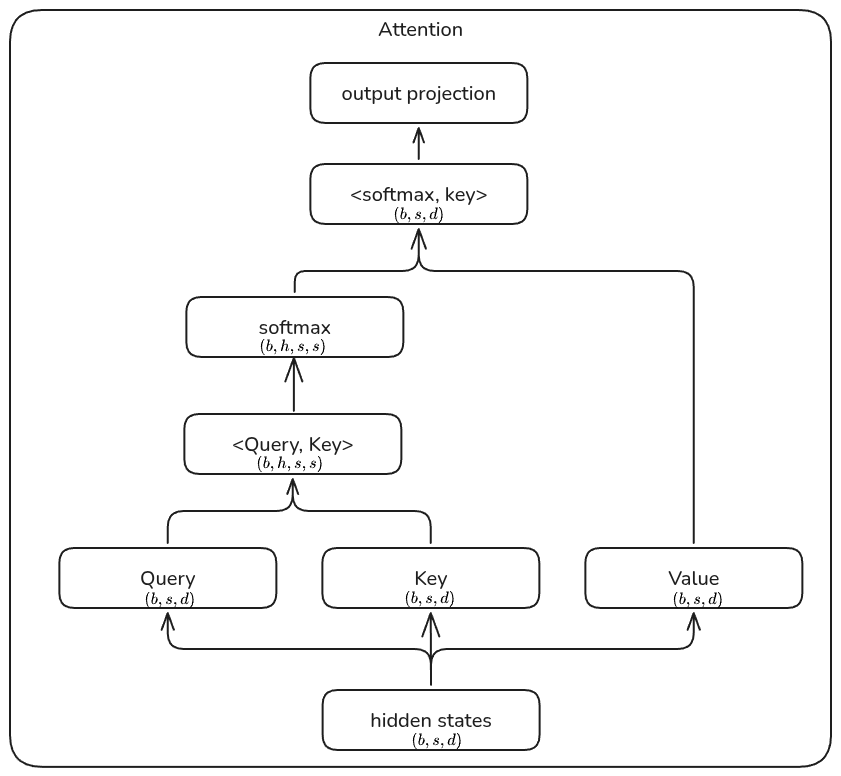
根据计算图,对应的 activation 为(注:这里我们不做任何优化,仅此理论上进行分析):
- query, key, value projection: 共享输入,对应的 activation 大小为 $2bsd$.
- $Q^TK$ : $Q$, $K$ 都需要保存,大小为 $4bsd$.
- softmax: 需要保存 $2bhs^2$ 大小的输入
- weighted sum of values: 两者都需要保存,前者大小为 $2bhs^2$, 后者大小为 $2bsd$
- output projection layer: 需要保存输入,大小为 $2bsd$.
因此 attention 部分总共需要 $\boxed{10sbd+4bhs^2}$.
FFN FFN 计算图如下所示
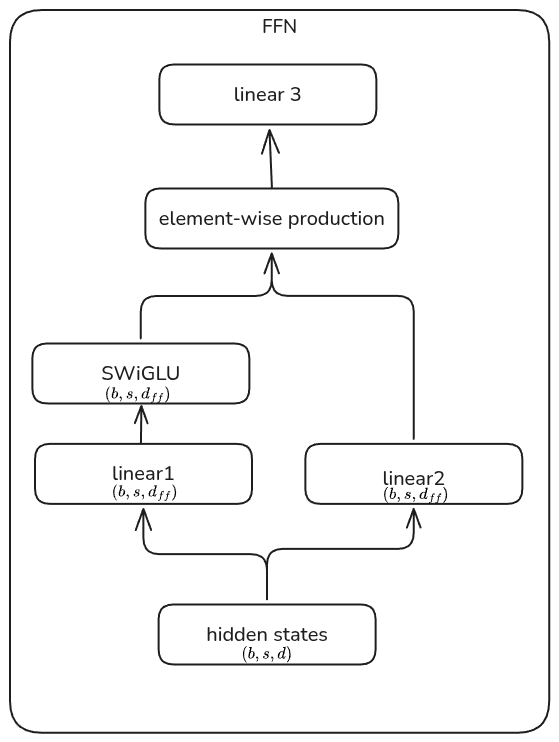
根据计算图,对应的 activation (我们假设 MLP 是一个基于 SwiGLU 的 dense MLP, 其 hidden size $d_{ff}=8/3d$,):
- MLP 的第一层输入大小为 $2sbd$,
- MLP 的第二层输入大小为 $16/3sbd$,
- SwiGLU 的输入为 $16/3sbd$
因此总的 activation 大小为 $\boxed{18sbd}$.
LayerNorm LayerNorm 需要保存输入,大小为 $\boxed{2bsd}$.
以上三部分相加,我们就得到单一 transformer layer 所需要的 activation:
$$ \begin{aligned} \mathrm{activation}(\mathrm{transformer}\_{\mathrm{block}})&=\mathrm{activation}(\mathrm{PerNorm})+\mathrm{activation}(\mathrm{Attention})+\mathrm{activation}(\mathrm{PostNorm})+\mathrm{activation}(\mathrm{FFN})\\ &= 2bsd + (10bsd+4bhs^2) + 2bsd + 18bsd\\ &= \boxed{bs(32d+4hs)} \end{aligned} $$output output 部分的计算图如下所示
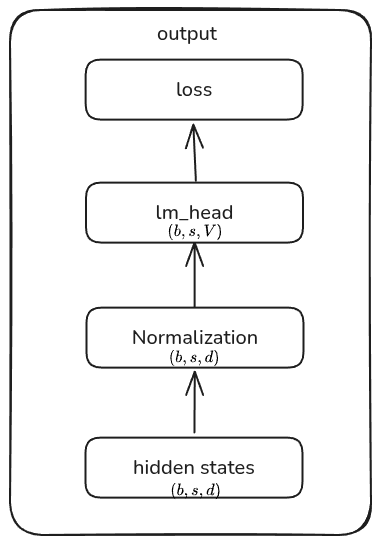
根据计算图,对应的 activation 为:
- normalization 的输入大小为大小为 $2sbd$
lm_head的输入大小为 $2sbd$- loss 的输入大小为 $2bsV$
从而输出部分的 activation 大小为
$$ \mathrm{activation}(\mathrm{output}) = \mathrm{activation}(\mathrm{FinalNorm})+\mathrm{activation}(\mathrm{lm\ head})+\mathrm{activation}(\mathrm{Loss}) = \boxed{4bsd+2bsV} $$因此,总的 activation 为
$$ \begin{aligned} \text{Memory}(\text{activation}) &= L*(\mathrm{transformer}\_{\mathrm{block}}) + \mathrm{activation}(\mathrm{output})\\ &= \boxed{Lsb(32d+4hs) +( 4bsd+2bsV)} \end{aligned} $$Gradients & Optimizer States
现代优化器一般会使用高阶近似以及混合精度训练来提高训练的效率,这部分高阶近似也需要考虑内存占用。
Gradients 当 gradient 和 weight 精度一致时,对应的内存消耗一致,为 $\boxed{2P}$.
Optimizer states AdamW 优化器会保存一阶和二阶动量,以及一份 master weights, 精度一般为 FP32:
- FP32 master weights: $4P$
- FP32 first-order momentum: $4P$
- FP32 second-order momentum: $4P$
因此优化器状态需要 $\boxed{12P}$ 内存。
对于其他优化器,我们也可以算出对应的内存需求,下表总结了 AdamW, bitsandbytes 和 SGD 三种 optimizer
| optimizer | master weights (FP32) | momentum | variance | TOTAL |
|---|---|---|---|---|
| AdamW | $4P$ | $4P$ | $4P$ | $12P$ |
| bitsandbytes | $4P$ | $P$ | $P$ | $6P$ |
| SGD | $4P$ | $4P$ | 0 | $8P$ |
最终,训练阶段所需要的内存为
$$ \text{Memory}_{\text{train}} = 16P+bs(32dL+4hsL+4d+2V) $$下面我们展示 LLaMA 系列训练时不同部分的内存占比 (batch size=64, AdamW, GB)
| Model | weights | gradients | optimizer_states | activations |
|---|---|---|---|---|
| LLaMA-7B | 12.55 | 12.55 | 75.31 | 1545.81 |
| LLaMA-13B | 24.24 | 24.24 | 145.46 | 2410.31 |
| LLaMA-33B | 60.59 | 60.59 | 363.54 | 4691.06 |
| LLaMA-65B | 121.60 | 121.60 | 729.62 | 7691.81 |
Inference
LLM 推理阶段对的开销包含三部分
$$ \text{Memory}_{\text{Inference}} = \text{Memory}(\text{weight}) + \text{Memory}(\text{activation}) + \text{Memory}(\text{KV cache}) $$weight memory 的内存占用为 $\boxed{2P}$. activation 内存占用比较小,transformer-math 给出了一个经验值,即
$$ \text{Memory}(\text{activation})\approx 0.2*\text{Memory}(\text{weight})=0.4P $$该经验值适用于 batch size = 1 的自回归推理场景。weight 和 activation 这两部分开销只与模型本身有关,第三部分 KV cache 则与我们的生成内容长度相关,下面我们详细进行介绍
Key Value Cache
Key Value Cache (KV Cache) 是 LLM 在推理过程中为了避免重复计算历史 token 对应的 key 和 value 而使用的一个空间换时间的缓存机制。
在 LLM 推理阶段,我们是 token-by-token 进行生成的,每次 attention 的计算都有如下形式
$$ \begin{aligned} \mathbf{q_t} &= W_Q\mathbf{x_t}\\ \mathbf{k}_{:,t}&=W_K[\mathbf{x_1},\dots,\mathbf{x_t}]\\ \mathbf{v}_{:,t}&=W_V[\mathbf{x_1},\dots,\mathbf{x_t}]\\ \mathbf{o}_t&=\mathrm{Attn}(\mathbf{q_t},\mathbf{k}_{:,t}, \mathbf{v}_{:,t})=\sum_{i=1}^t \frac{\alpha_{t,i}}{\sum_{t,i}\alpha_{t,i}}\mathbf{v_i},\ \alpha_{t,i} = \exp\left(\frac{\mathbf{q_t}^T\mathbf{k}_{i}}{\sqrt{d_k}}\right) \end{aligned} $$这里 $\mathbf{q_t}$ 是当前 token $\mathbf{x}_t$ 对应的 query, $\mathbf{k}_{:,t}$ 和 $\mathbf{v}_{:,t}$ 是历史 token $[\mathbf{x_1},\dots,\mathbf{x_t}]$ 对应的 key 和 value. 当我们处理下一个 token $\mathbf{x}_{t+1}$ 时, 对应的计算变成了
$$ \begin{aligned} \mathbf{q_t} &= W_Q\mathbf{x_t}\\ \mathbf{k}_{:,t+1}&=W_K[\mathbf{x_1},\dots,\mathbf{x_t},\mathbf{x}_{t+1}]=[\boxed{\mathbf{k}_{:,t}},W_K\mathbf{x}_{t+1}]\\ \mathbf{v}_{:,t+1}&=W_V[\mathbf{x_1},\dots,\mathbf{x_t},\mathbf{x}_{t+1}]=[\boxed{\mathbf{v}_{:,t}},W_V\mathbf{x}_{t+1}]\\ \end{aligned} $$也就是说,我们每生成一个 token, 都要重新计算一次历史 token 对应的 key 和 value, 因此生成一个包含 $s$ 个 token 的 sequence 时,每个 token 都需要计算其前序 token 的 key 和 value, 其对应的计算量为
$$ \sum_{t=1}^s \mathcal{O}(t) = \mathcal{O}(s^2) $$因此,一个自然的想法就是缓存历史 token 对应的 key 和 value, 在生成新的 token 时,我们只需从内存中加载计算好的结果,然后计算当前 token 对应的值 $W_K\mathbf{x}_{t+1}$ 和 $W_V\mathbf{x}_{t+1}$ 即可,这就是 KV cache. 使用 KV cache 之后,我们每次生成新的 token 时,仅需要计算当前 token 对应的 key 和 value, 此时总的计算复杂度为 $\mathcal{O}(s)$, 对应的空间复杂度为 $\mathcal{O}(s)$. 也就是以空间换时间。
容易推导出一个基于 Multi-head attention LLM 的 KV cache 如下
$$ \text{Memory}(\text{KV cache}) = s \times 2 \times 2 \times L\times h \times d_h $$可以看到,KV Cache 占用不仅与模型配置有关,还与生成的 sequence length 有关,生成的 token 越多,KV Cache 这部分占用越高。
最终,推理阶段模型本身的内存占用为
$$ \text{Memory}_{\text{Inference}} = 2.4P+4sLhd_h $$我们还是以 LLaMA 系列为例,结果如下 (batch size=1, GB, 括号里为 sequence length)
| Model | Weights | Activations | KV Cache (1024) | KV Cache (4096) | KV Cache (16384) | KV Cache (32768) | KV Cache (131072) |
|---|---|---|---|---|---|---|---|
| LLaMA-7B | 12.55 | 2.51 | 0.25 | 1.00 | 4.00 | 8.00 | 32.00 |
| LLaMA-13B | 24.24 | 4.85 | 0.39 | 1.56 | 6.25 | 12.50 | 50.00 |
| LLaMA-33B | 60.59 | 12.12 | 0.76 | 3.05 | 12.19 | 24.38 | 97.50 |
| LLaMA-65B | 121.60 | 24.32 | 1.25 | 5.00 | 20.00 | 40.00 | 160.00 |
可以看到,随着输出长度增加,KV cache 的开销占比也逐渐了超过模型权重的内存占用。而实际中 KV cache 往往因 page granularity、padding 和 fragmentation 略高于理论值。
Summary
我们将上面的结果汇总起来就得到下表的结果。
| component | 训练 | 推理 |
|---|---|---|
| weights | $2P$ | $2P$ |
| optimizer states | $12P$ | 0 |
| gradients | $2P$ | 0 |
| activations | $Lsb(32d+4hs) +( 4bsd+2bsV)$ | $\sim 0.4P$ |
| KV cache | 0 | $4sLhd_h$ |
| TOTAL | $16P+bs(32dL+4hsL+4d+2V)$ | $2.4P+4sLhd_h$ |
Analysis & Optimizations
接下来,我们将简单介绍一下如何优化训练和推理过程中的内存占用,我们将优化方法总结如下表所示。后面我们将一一进行详细介绍
| Stage | methods |
|---|---|
| training | - activation checkpointing - flash attention - Parallelism |
| inference | - KV Cache Optimization - PagedAttention - RadixAttention - Attention mechanism |
Training
Mixed Precision Training
混合精度训练的核心思想是计算量大的模块使用低精度,计算量小的模块使用高精度。细节见 Mixed precision training, 最近的 DeepSeek-V3 还进一步使用了 FP8 精度进行训练,大幅度提高了训练效率。
Data Parallelism
第一个并行策略是数据并行 (data parallelism), 其基本思想是把模型复制到多个 GPU 上,并行处理数据,然后对 loss 进行求和再进行反向传播。现在最常使用的是微软提出的 ZeRO, 其核心思想为把 optimizer states, gradients, weights 分布到不同的 GPU 上,然后需要的时候再汇总到一起。ZeRO 根据切分的部分不同可以分为三种策略,如下图所示
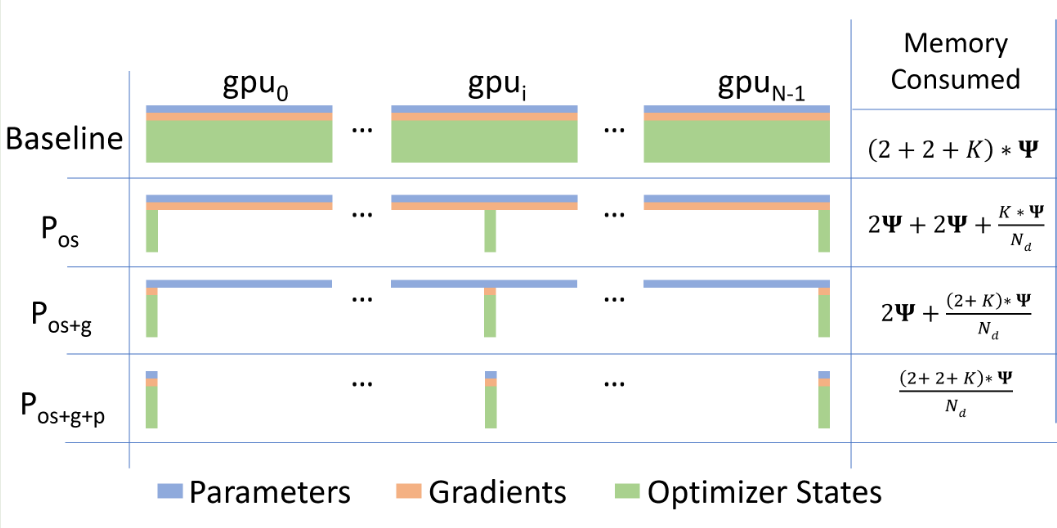
如上图所示,在 baseline 场景下,我们每个 GPU 上都保存有一份模型的 optimizer states, gradients, weights, 这就限制了 batch size, 进而降低了整体的计算效率。
ZeRO 的关键改进在于利用 GPU 可以互相通信的性质来将 tensor 存储在不同的 GPU 上,这时每个 GPU 上不再保存完整的复制,而是独特的一部分数据,在参与计算时,GPU 通过 all gather 来把数据汇总在一起,如下图所示

ZeRO1 只对 optimizer states 进行 shard, 因此其内存占用为
$$ \text{Memory}_{\text{train}} = \text{Memory}(\text{weight}) + \text{Memory}(\text{activation}) + \frac{\text{Memory}(\text{optimizer})}{\text{\# GPUs}}+\text{Memory}(\text{gradient}) $$ZeRO2 在 ZeRO1 的基础上进一步对 gradient 也进行 shard, 其内存占用为
$$ \text{Memory}_{\text{train}} = \text{Memory}(\text{weight}) + \text{Memory}(\text{activation}) + \frac{\text{Memory}(\text{optimizer})+\text{Memory}(\text{gradient})}{\text{\# GPUs}} $$ZeRO3 在 ZeRO2 的基础上对 weight 也进行 shard, 其内存占用为
$$ \text{Memory}_{\text{train}} = \text{Memory}(\text{activation}) + \frac{\text{Memory}(\text{weight}) + \text{Memory}(\text{optimizer})+\text{Memory}(\text{gradient})}{\text{\# GPUs}} $$一般来说,我们比较少使用 ZeRO3, 因为其通信开销变为了原来的 1.5 倍。
Activation Checkpointing
上一节我们介绍了使用 DP 来减少固定部分 (weight, optimizer states, gradients) 部分的占用,但实际上训练时占用部分更多的是 activation, 这部分内存占用会严重影响 batch size 的设置进而影响整体计算效率。我们对固定部分(与模型参数量相关)和非固定部分(与 batch size 相关)进行一个对比,结果如下所示
| Metric | $d$ | $b, s$ |
|---|---|---|
| weight | quadratic ($d^2$) | independent |
| activation | linear ($d$) | linear ($bs$) |
我们可以看到,虽然训练时 batch size 越大越好,但是由于 activation 也会随之增大,batch size 可能只能使用一个非常小的值。下图是 LLaMA 系列在 $b=64$ 时不同部分的内存占用:
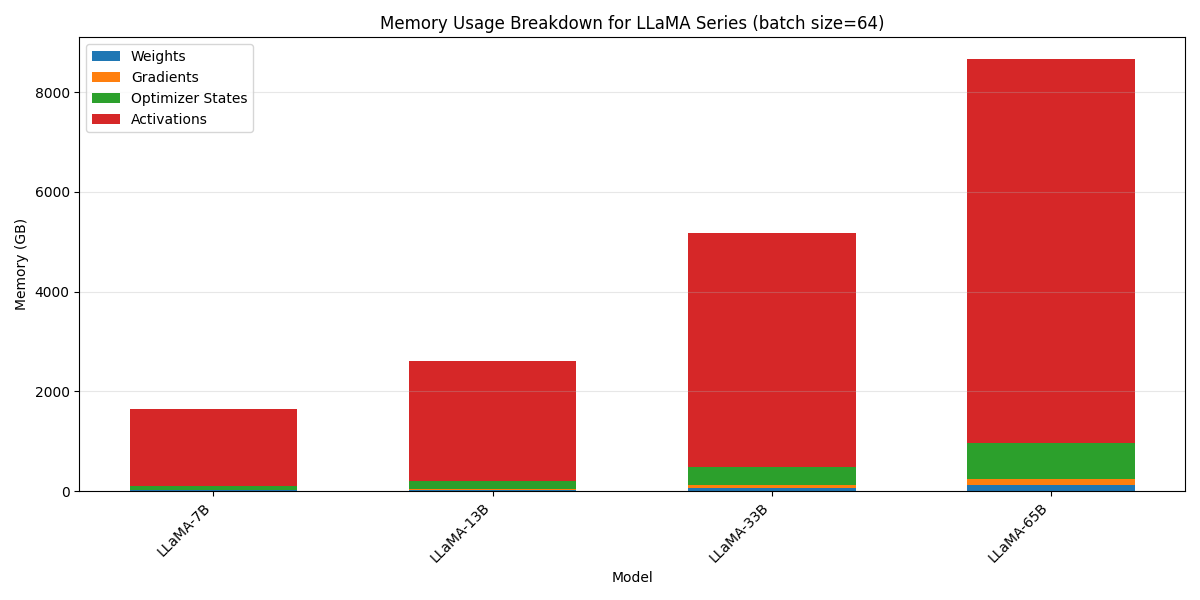
从图表可看出,LLaMA-65B 在 batch size=64 时,激活值占用内存超 80%,远高于权重 / 梯度 / 优化器状态,而且随着 batch size 增加,这个比例会进一步上升。
为了解决这个问题,我们一般会使用 activation checkpointing 方法,这个方法是一个通过重新计算中间激活值,来减少内存占用的方法。其核心思想在于用计算复杂度换空间复杂度。Reducing Activation Recomputation in Large Transformer Models 给出了不同的 checkpointing 策略,需要的算力也不同相同,我们下表进行总结
| No checkpointing | Selective checkpointing | full checkpointing | |
|---|---|---|---|
| description | stores everything needed | store states stagely (e.g., the input to each layer) | only store the input to the model |
| memory | very high ($\text{Memory}(\text{activation})$) | medium | very low $2bsd$ |
| extra compute | None | medium | very high $2Pbs$ |
一般来说我们会结合 model parallelism 和 selective checkpointing 来实现一个均衡
Model Parallelism
与 DP 在数据维度上进行切分不同,model parallelism 通过对模型进行切分来提高内存使用效率。Model Parallelism 又可以分为 Pipeline Parallelism (PP) 和 Tensor Parallelisim (TP)
通过 PP 和 TP 我们可以将模型切分部署在多个 GPU 上进而减少内存占用,对应的计算方式为
$$ \text{Memory}(\text{weight};\text{parallelism}) = \frac{\text{Memory}(\text{weight})}{\text{PP degree}\times\text{TP degree}} $$实际情况中,我们还可以结合 ZeRO 以及 Model Paralelism, 我们根据 PP degree 和 TP degree 来决定 DP degree
$$ \text{DP degree} = \frac{\text{\# GPUs}}{\text{PP degree}\times\text{TP degree}} $$最终,我们把以上优化技巧汇总起来就得到 (假设我们采用 ZeRO1 和 Model Parallelism)
$$ \text{Memory}_{\text{train}} \approx \frac{\text{Memory}(\text{weight})}{\text{PP degree}\times\text{TP degree}} + \frac{\text{Memory}(\text{activation})}{\text{TP degree}} + \frac{\text{Memory}(\text{optimizer})}{\text{\# GPUs}}+\frac{\text{Memory}(\text{gradient})}{\text{PP degree}} $$这里> activation 中 被 tensor-parallel 的部分 按 TP degree 缩减。
关于 Parallelism 的具体细节见 Parallelism tutorial
Flash Attention
在前面的分析中,我们给出了 attention softmax 这一部分的 activation 为 $2bhs^2$ 而 flashattention 通过 tiling 和 online-softmax 降低了这一部分的内存占用,进而提高整体的效率。
具体细节见 flash attention
Inference
Quantization
quantization 是用低精度加载模型权重从而降低推理阶段模型参数内存占用的一个方法。比如说原始模型使用了 BF16 精度,那么我们可以通过使用 int8 量化来将模型权重对应的内存从 $2P$ 降低到 $P$. 现在一些模型还会在训练阶段就加入 quantization, 比如 quantization aware training 以及 post-training quantization 等。这部分细节可以参考 Efficient Large Language Models: A Survey
KV Cache Optimization
我们在前面已经介绍了 KV cache 可以通过以空间换时间来提高计算效率,但是随着输出长度增加,对应的 KV cache 也会越来越大,因此目前有相当一部分工作旨在降低 KV cache 占用,比如 KV Cache compression, quantization 等。这部分细节可以参考 A Survey on Large Language Model Acceleration based on KV Cache Management
Attention
实际上,相当一部分工作都是通过优化 attention 来降低
Inference Framework
现在也有一些推理框架专注于提高 LLM 的推理效率,下面是两个比较流行的推理框架
- SGLang: 定制化强,适用于复杂任务如 RL 推理等
- vLLM: 简单高效
对应的轻量化推理框架为
- nano-vLLM
- mini-SGLang
这部分
Conclusion
在本文中,我们详细介绍了 LLM 在训练和推理阶段的内存占用开销以及简要介绍了对应的优化方法。关键结论为:
- 训练阶段内存核心瓶颈是激活值(随 batch size / 序列长度线性增长),推理阶段核心瓶颈是 KV Cache(随序列长度增长);
- 训练优化优先通过 ZeRO(多卡)+ activation checkpointing(单卡)降低内存,推理优化优先通过 KV Cache 优化 + 量化降低内存;
- 所有内存计算均为理论值,实际落地需考虑显存碎片、硬件特性、通信开销等工程因素。
需要注意的是,所有内存计算均为理论值,实际落地需考虑显存碎片、硬件特性、通信开销等工程因素。下一步,我们将分别针对不同的优化方法来进行展开并详细介绍。
References
- transformer-math
- transformer inference arithmetic
- https://zhuanlan.zhihu.com/p/687226668
- Reducing Activation Recomputation in Large Transformer Models
- https://blog.eleuther.ai/transformer-math/
- A Survey on Large Language Model Acceleration based on KV Cache Management
- Efficient Large Language Models: A Survey
Appendix
Activation Visualization
LLaMA 系列的配置如下表所示
| Model | s | V | L | d | d_ff | h | h_d | P |
|---|---|---|---|---|---|---|---|---|
| LLaMA-7B | 2048 | 32000 | 32 | 4096 | 11008 | 32 | 128 | 6738411520 |
| LLaMA-13B | 2048 | 32000 | 40 | 5120 | 13824 | 40 | 128 | 13015859200 |
| LLaMA-33B | 2048 | 32000 | 60 | 6656 | 17920 | 52 | 128 | 32528936960 |
| LLaMA-65B | 2048 | 32000 | 80 | 8192 | 22016 | 64 | 128 | 65285652480 |
对应的可视化代码如下
| |