Aya Vision是一个多模态大语言模型,包含8B, 32B两个size,支持23种语言。Aya Vision基于 Aya Expanse大语言模型。
模型架构
Aya Vision的模型架构如下图所示
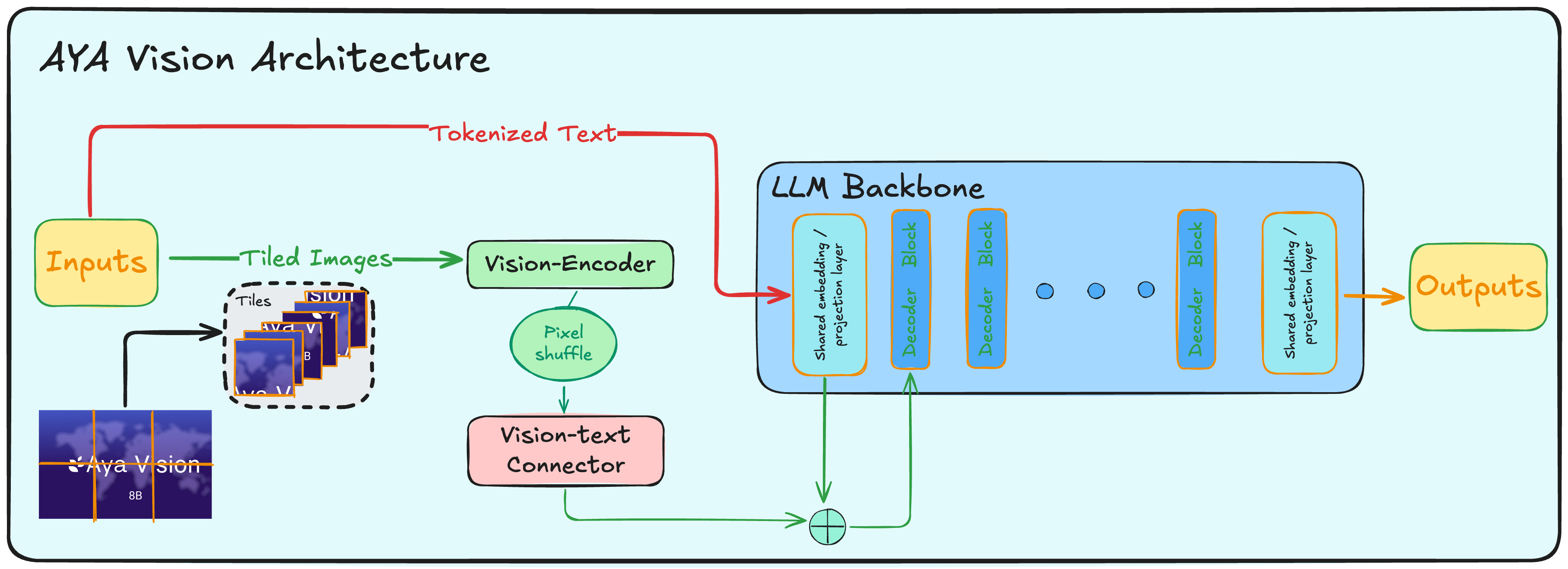
- Vision Encoder: SigLip2-patch14-384
- Vision-text connector: 2 layer MLP
- LLM: Aya Expanse 8B/ 32B
训练
训练包含两个stage:
- Vision-language alignment: 仅训练vision-text connector,基于image-text pairs进行训练
- SFT:训练connector和LLM,基于合成的多语种数据进行训练
多语种数据
为了提高模型的多语种能力,作者先基于English的高质量数据集合成了annotation,然后作者讲这些数据转化为22中语言对应的文本
Model merging
最后为了提高模型在纯文本任务上的表现,作者还使用了model merging的技巧。具体做法就是merge使用的base language model和SFT之后的vision-language model