Introduction
作者首先提到如何提高模型的训练效率以及 inference efficiency 是两个尚未解决的问题。
基于这两个问题,作者在本文中提出了 DeepSeek-V2,一个开源的 MoE 模型,DeepSeek-V2 的亮点在于训练和推理都非常高效。最终 DeepSeeK-V2 包含 236B 总参数,激活参数为 21B, 上下文长度为 128K. 作者还开源了 DeepSeek-V2-Lite, 一个 15.7B-A2.4B 的 MoE 模型,用于学术研究。
DeepSeek-V2 主要改进点为:
- 基于 DeepSeekMoE, 使用了 MoE 架构
- 使用了 MLA 压缩 KV cache, 大幅度提高推理效率
DeepSeek-V2 预训练使用了 8.1T tokens, 相比于 DeepSeek-LLM, 预训练数据主要增加了中文数据以及提高了数据的质量。
接下来,作者收集了 1.5M 对话数据来进行 SFT, 最终作者基于 DeepSeek Math 提出的 GRPO 来进行对齐。
Architecture
DeepSeek-V2 的模型架构如下
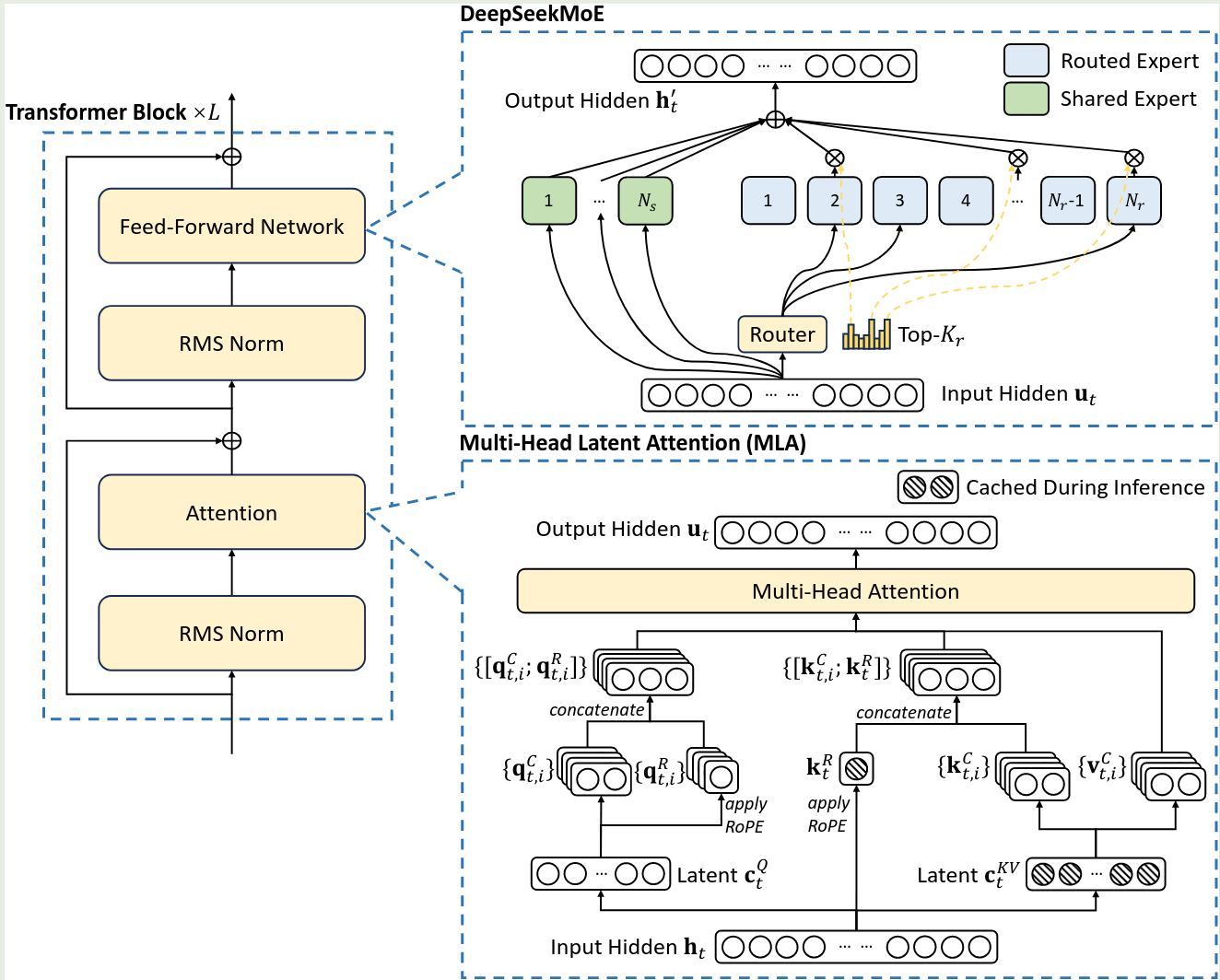
模型基于 DeepSeekMoE 开发得到,相比于 DeepSeekMoE, DeepSeek-V2 主要是使用了 MLA
MLA
这部分介绍见 MLA
DeepSeekMoE
Architecture
关于架构的介绍见 DeepSeekMoE
Device-Limited Routing
由于 DeepSeek-MoE 使用了细粒度的专家,因此专家会分布在更多的设备(GPU)上,计算时,基于 routing 的 expert 所在设备,会产生不同大小的通信开销。为了降低通信开销,作者构建了 device-limited routing mechanism. 具体的做法就是,在 Routing 之前,先基于 experts 的 affinity score 挑选 $M$ 个设备,然后基于这 $M$ 个设备的专家挑选 top-K 专家进行计算。
作者通过实验发现,当 $M\geq3$ 时,device-limited routing 可以和标准的 top-K routing 表现差不多。
Auxiliary Loss for Load Balance
作者使用了三个 loss 来实现负载均衡。其中,expert level 和 device level 的 load balancing loss 与 DeepSeekMoE 相同。第三个 loss 是 communication balance loss, 这个 loss 的目的是让每个设备的通信开销保持平衡。损失函数的表达式如下所示
$$ \mathcal{L}_{communication} = \alpha\sum_{i=1}^D f_iP_i $$其中 $\alpha$ 是超参数,$D$ 是 expert group 的个数。
$$ f_i = \frac{D}{MT}\sum_{t=1}^T\mathbb{1}(\text{Token }t \text{ is sent Device }i),\quad P_i = \sum_{j\in\mathcal{E}_i}P_j $$device limited routing 让每个 device 发送至多 $MT$ 个 hidden states 到其他设备上。而 communication balancing loss 则让每个设备最多从其他设备接收 $MT$ 个 hidden states.
Token-Dropping Strategy
尽管前面已经增加了 load balance loss, 但毕竟不是硬约束。因此,作者就从硬件层面提出了 Token dropping 策略,来提高训练效率。核心思想就是,在训练时,主动丢弃部分 token, 强制让各个设备的计算量不会超过额度限制,进而减少资源浪费。
具体做法就是,在训练之前,先将每个设备的 capacity factor 设置为 1 (定义见 Switch Transformer). 然后按照 affinity score 来丢弃一些分数比较低的 token, 直到该设备的 token 数量刚到达到 capacity。为了避免过度学习导致模型表现较差,对于 $10\%$ 的训练数据,作者不执行 token dropping 策略。
最终,在 inference 时,可以根据需求来决定是否丢弃 token, 比如在 low latency 场景,我们可以丢弃低价值的 token, 在高精度场景,我们就可以保留所有的 token.由于在训练阶段已经才去过 token dropping 策略,因此在推理时不管是丢弃还是全部保留模型都能比较好的适应。
Pre-training
Data
预训练数据与 DeepSeek-LLM 基本上差不多,作者针对中文数据,数据质量进行了改进。最终预训练数据包括 8.1T token, 其中中文数据比英文数据多 $12\%$.
tokenizer 与 DeepSeek-LLM 一致。
Model Configuration
模型配置如下表所示
| Model | DeepSeek-V2 | DeepSeek-V2-Lite |
|---|---|---|
| Date | 2024-5 | 2024-5 |
| # Total Parameters | 236B | 15.7B |
| # Activated Parameters | 21B | 2.4B |
| # tokens | 8.1T | 5.7T |
| # Dense Layers | 1 | 1 |
| # MoE Layers | 60 | 26 |
| Hidden Dim | 5120 | 2048 |
| Dense Intermediate Dim | 12288 | 10944 |
| MoE Intermediate Dim | 1536 | 1408 |
| Attention | MLA | MLA |
| # Attention Heads | 128 | 16 |
| # Key-Value Heads | 128 | 16 |
| # Routed Experts | 160 | 64 |
| # Experts Active Per Token | 6 | 6 |
| # Shared Experts | 2 | 2 |
这里比较特殊的一点在于,模型在第一层使用了 MoE layer, 这个做法的原因在后面的 olmoe 里有提到,核心思想是 early layer 特别是第一层 layer 收敛比较慢。
MLA 的配置如下 (DeepSeek-V2)
| field | value |
|---|---|
| $d_c$ | 512 |
| $d_c'$ | 1536 |
| $n_h$ | 16 |
| $d_h$ | 128 |
| $d_h^R$ | 64 |
Training Recipe
训练的配置也与 DeepSeek-LLM 差不多,对于 MoE,作者使用了 PP 将不同的 layers 分配在不同的 device 上,然后 MoE 的 experts 被分配在 8 个 device 上 ($D=8$), 对于 device-limited routing, 每个 token 发送到至多 3 个 device, 也就是 $M=3$.
Infra
在 infra 上,DeepSeek-V2 也是用了 HAI-LLM 框架进行训练。这里面使用了 16-way zero-bubble PP, 8-way EP, ZeRO-1 DP.
由于 DeepSeek-V2 的激活参数比较少,因此,作者没有使用 TP, 进而降低通信开销。作者还将 shared experts 的计算与 expert all-to-all 通信进行重叠来提高计算效率。作者还使用了 kernel fusion 和 flash attention 2 来加速训练。
Long Context
在预训练阶段结束之后,作者使用了 YARN 来将模型的上下文从 4K 扩展到 128K. 超参数设置为
| Parameter | Value |
|---|---|
| $s$ | 40 |
| $\alpha$ | 1 |
| $\beta$ | 32 |
| target context length | 160K |
| scaling factor | $\sqrt{t} = 0.0707\ln s + 1$ |
作者在 32K 的上下文下额外训练了 1000 步,然后在推理阶段通过 YaRN 将模型的上下文长度扩展到 128K.
Evaluation
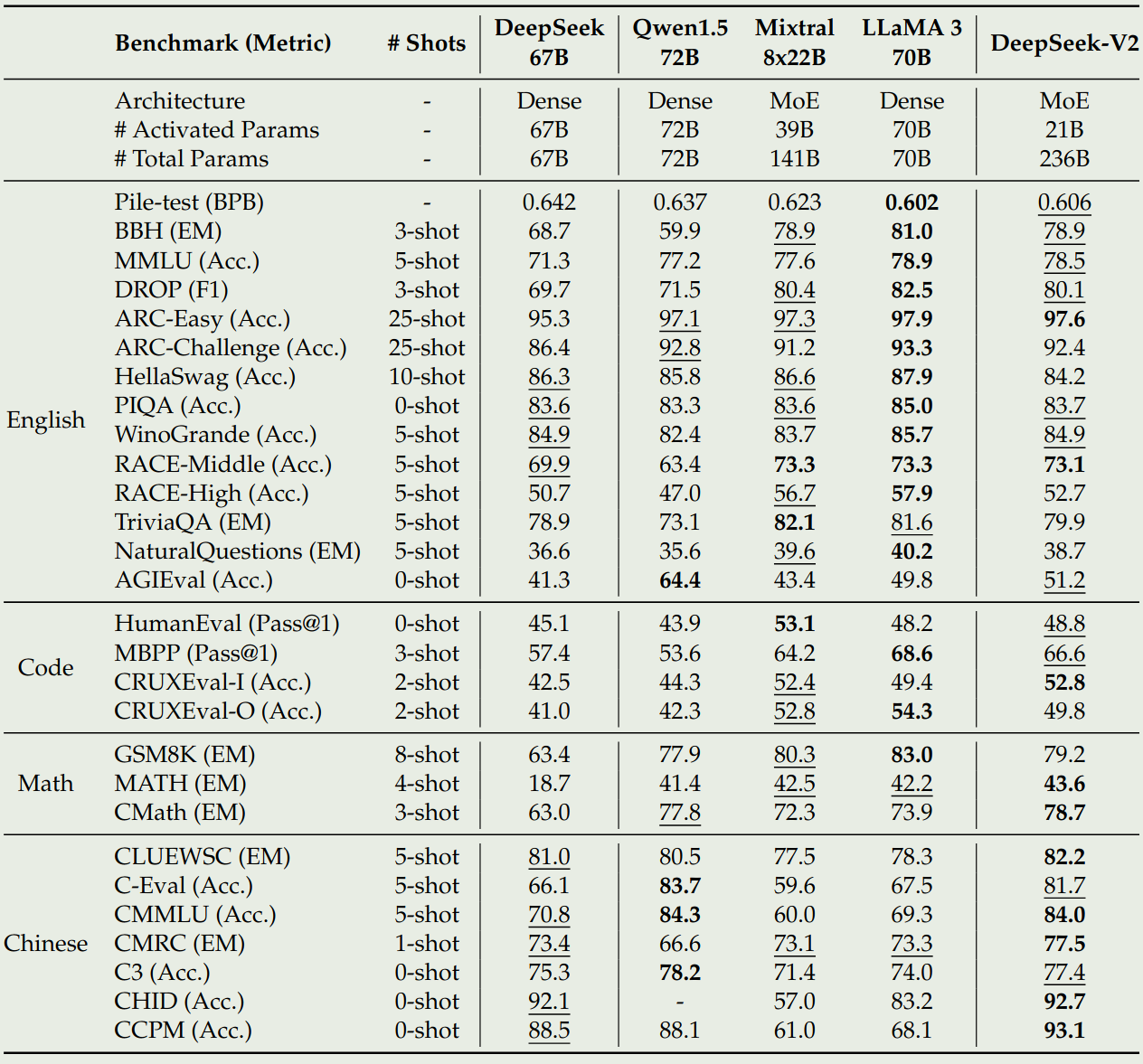
作者对比了 DeepSeek-LLM, Qwen1.5, Mixtral MoE 以及 LLaMA 3, 实验结果如下
Efficiency
作者对比了以下 DeepSeek-MoE 和 DeepSeek-LLM 的训练效率,结果发现,对于 1T 的 token, DeepSeek-LLM 需要 300.6K GPU hours, 而 DeepSeek-V2 仅需要 127.8K GPU hours. 也就是说,DeepSeeK-V2 节省了 $42.5\%$ 的训练成本
在推理时,作者首先将模型的精度转换为 FP8,然后作者进一步对模型进行 KV cache quantization 来进一步压缩每个 token 的 KV cache 到 6bits. 最终,DeepSeek-V2 的 throughtput 为 50K tokens/s.
Post-training
post-training 分为 SFT 和 RL 两个阶段。
SFT
在 SFT 阶段,作者构建了 1.5M 样本,包括 1.2M 有帮助性的样本和 0.3M 安全性相关的样本。模型训练了 2 个 epoch, 学习率为 $5e-6$.
RL
作者使用了 GRPO 算法来进一步对齐模型的表现。
作者通过实验发现,在 reasoning data, 如 code 和 math 相关数据上进行训练时,可以有效提高模型的表现。因此作者将 RL 的训练分为两个阶段,第一个阶段用于提高模型的 reasoning 能力,第二个阶段用于对齐人类偏好。
在第一个阶段,作者首先训练了一个针对 code 和 Math 的 reward model $\mathrm{RM}_{\mathrm{reasoning}}$, 然后基于这个 reward model 来训练 policy model:
$$ r_i=\mathrm{RM}_{\mathrm{reasoning}}(o_i) $$在第二阶段,作者使用了一个 Multi-reward 框架,包括一个 helpful reward model $\mathrm{RM}_{\mathrm{helpful}}$, 一个 safety reward model $\mathrm{RM}_{\mathrm{safety}}$ 和一个 rule-based reward model $\mathrm{RM}_{\mathrm{rule}}$, 最终的 reward 为
$$ r_i = c_1\mathrm{RM}_{\mathrm{helpful}}+c_2\mathrm{RM}_{\mathrm{safety}}+c_3\mathrm{RM}_{\mathrm{rule}} $$训练时,reward model 由 SFT model 初始化得到,然后基于 point-wise 或者 pair-wise loss 进行训练。
Evaluation
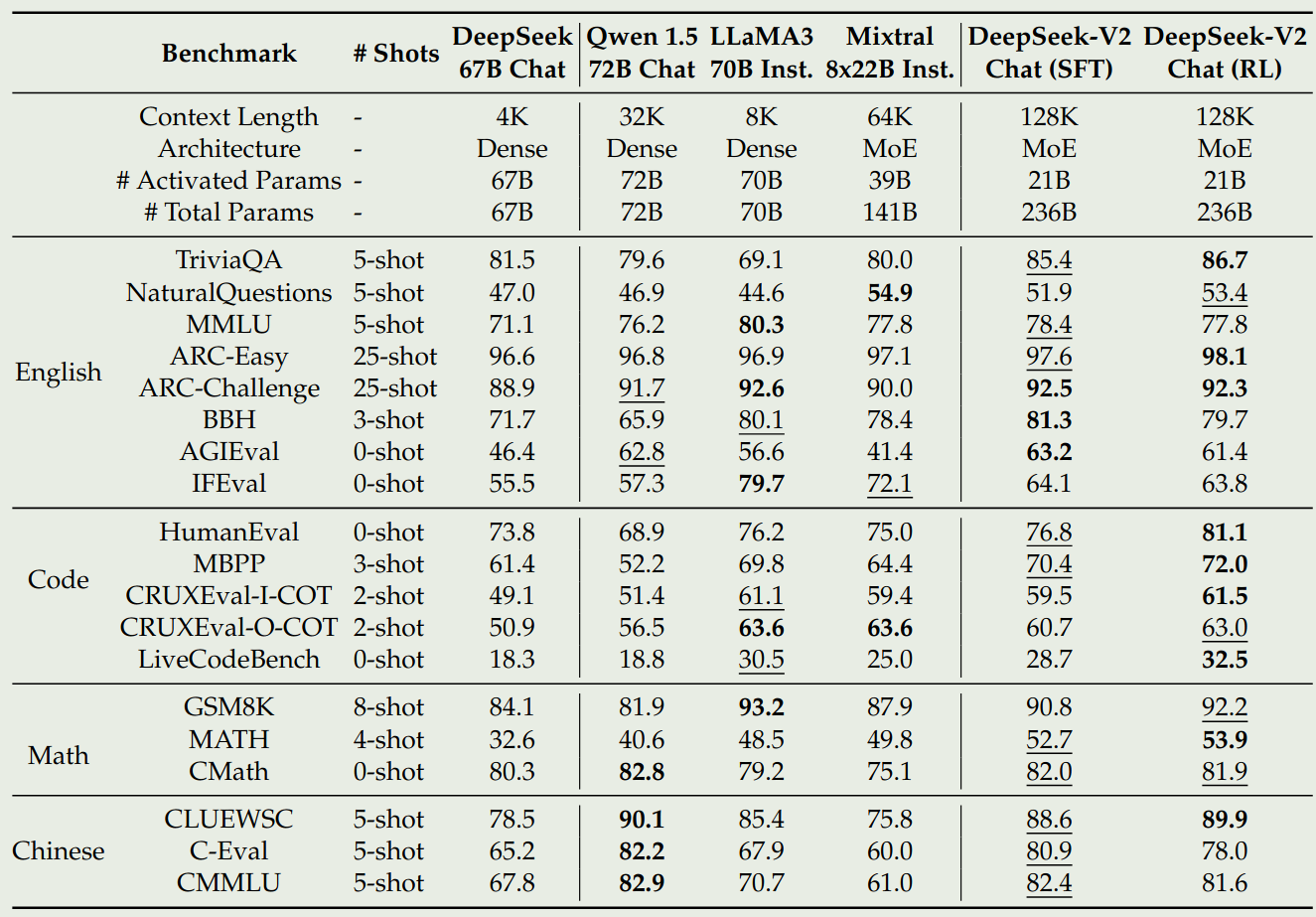
chat 版本的模型评估结果如下所示
Discussion
作者讨论了三点发现:
- SFT data 数量。已有工作认为进需要 10K 左右的样本就可以进行 SFT,但是作者发现当数据量小于 10K 时,模型在 IFEval benchmark 上的表现大幅度下降。作者认为,这是由于数据过少导致模型很难掌握特定的技能。因此,作者认为足够的数据以及数据质量都很重要,特别是写作类任务和 open-ended QA 类任务。
- alignment tax. 作者发现通过 human preference alignment, 模型在 open-ended generation benchmark 上的保险有了很大提升。与 RLHF 一样,作者也发现了 alignment 之后模型在一些 benchmark 上表现也会下降。作者通过改进解决了这个问题,作者认为如何在不损失模型表现的情况下实现对齐是一个值得探究的方向。
- online RL. 作者发现 Online RL 比 offline RL 的表现更好。作者认为如何根据不同的任务来选取 offline RL 和 online RL 也是一个值得探究的问题。
Conclusion
在本文中,作者提出了 DeepSeek-V2, 一个基于 MoE 架构的大语言模型系列,模型的上下文为 128K. 作者基于 DeepSeek-MoE, 提出了 MLA 来提高模型的 inference 效率,并大幅度降低了训练的成本。
作者介绍了几点未来工作:
- 进一步 scaling up MoE 模型,降低模型的训练以及推理成本
- 进一步对齐模型和人类的价值观,然后最小化人类监督信号
- 扩展模型到多模态版本