Introduction
作者首先回顾了开源模型如 MiniMax-01, Kimi-k2, Qwen3, GLM-4.5 和闭源模型的进展,作者指出,现在的开源模型和闭源模型在表现上仍然存在较大差距。作者认为这种差距主要是由于三个原因:
- Transformer 提出的 softmax attention 在处理长文本时效率非常低
- 已有的开源模型在 post-training 阶段使用的算力不够
- 开原模型的泛化和指令跟随能力不如闭源模型
基于这三个问题,DeepSeek-V3.2 分别进行了改进:
- 在架构上,作者提出了 DSA,一个高效的稀疏注意力机制,用于降低计算复杂度
- 在 post-training 阶段,作者使用了比 pre-training 阶段高 $10\%$ 的算力,用于提高模型的能力
- 作者提出了一个 pipeline 用于提高模型在工具调用场景下的 reasoning 能力
通过实验作者发现,模型达到了和 Kimi-k2 以及 GPT-5 差不多的 reasoning 表现。
Method
Architecture
DeepSeek-V3.2 与 DeepSeek-V3.1 不同之处在于使用了 DeepSeek Sparse Attention (DSA). 架构如下图所示
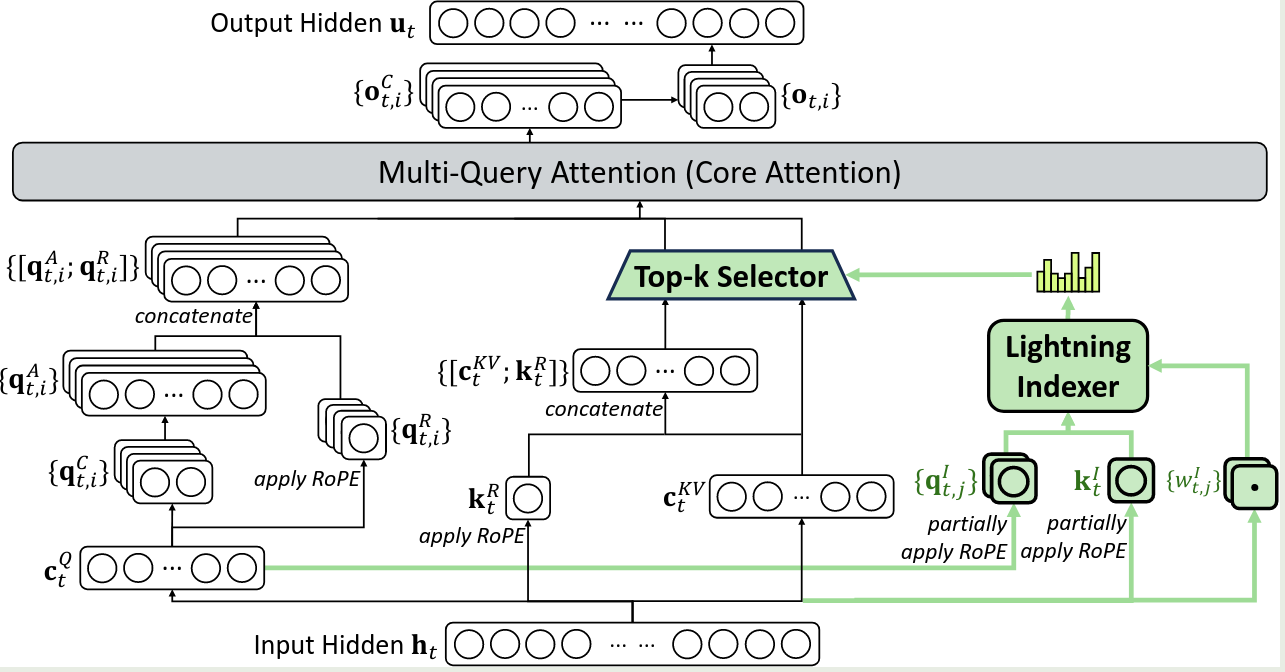
DSA 包含两个模块:
- lightning indexer
- fine-grained token selection mechanism
其中,lightning indexer 负责计算 query token $h_t\in\mathbb{R}^d$ 和一个 preceding token $h_s\in\mathbb{R}^d$ 之间的 index score $I_{t,s}$ 来决定 query token 选择的 token:
$$ I_{t,s} = \sum_{j=1}^{H_I}w_{t,j}^I \mathrm{ReLU}(q_{t,j}^I\cdot k_s^I) $$其中, $H^I$ 代表 indexer heads 的个数,$q_{t,j}^I\in\mathbb{R}^{d^I}$ 和 $w_{t,j}^I$ 由 query token $h_t$ 得到,$k_s^I\in\mathbb{R}^{d^I}$ 由 preceding token $h_s$ 得到
给定 query token $h_t$ 对应的 index score $\{I_{t,s}\}$, fine-grained token selection mechanism 负责选取 top-K index score 对应的 key-value entries $\{c_s\}$, 然后 attention 的输出由 query token 个选取的 key value entries 得到:
$$ u_t = \mathrm{Attn}(h_t,\{c_s\mid I_{t,s}\in \mathrm{TopK}(I_{t,:})\}) $$[!Recall] MoBA 也提出了类似的方法,但是 MoBA 是一个无需训练的策略
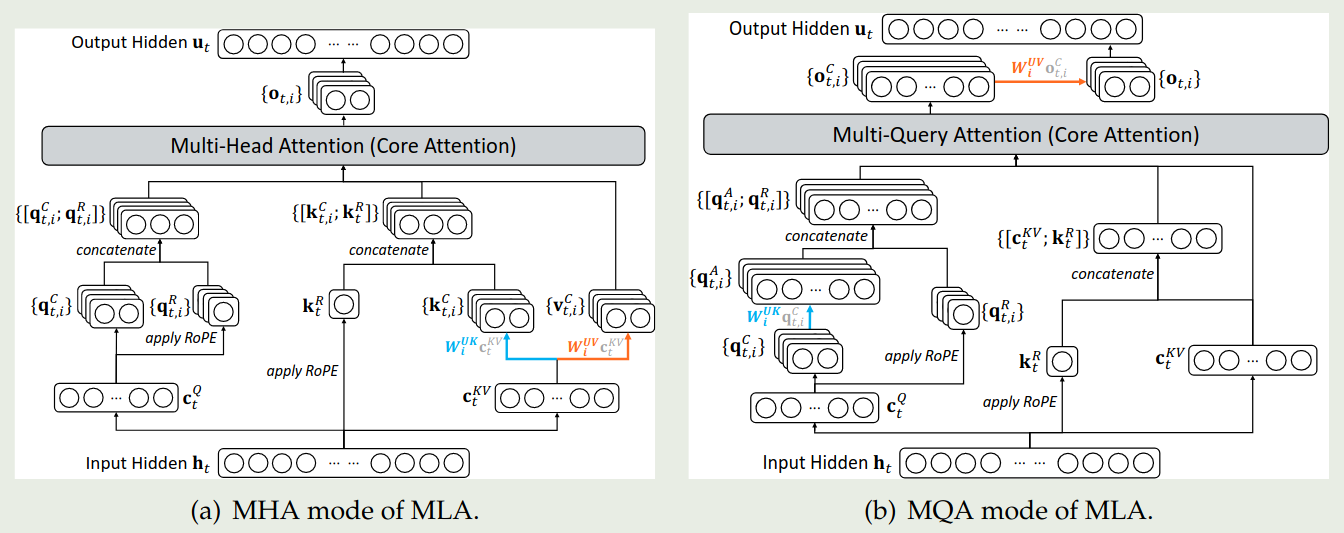
受 NSA 启发,作者实现了基于 MQA 模式的 MLA, 其中 latent vector 对于 query token 所有的 query heads 都是共享的。示意图如下所示
Continue Pre-training
作者在 DeepSeek-V3.1 的基础上进行了 continue pre-training. Continue pre-training 包含两个阶段:
Dense Warm-up stage 这个阶段用于训练 lightning indexer, 作者冻结除 lightning indexer 之外的参数,为了对齐 indexer output 和 main attention distribution, 对于第 $t$ 个 query token, 作者首先计算所有 attention heads 的 main attention score 之和,然后在 sequence 层面进行 L1-normalization 得到 $p_{t,:}\in\mathbb{R}^t$, 最后计算 lightning indexer 输出与 $p_{t,:}$ 之间的 KL divergence:
$$ \mathcal{L}^I = \sum_{t}\mathcal{D}_{KL}(p_{t,:}\ \Vert\ \mathrm{Softmax}(I_{t,:})) $$这个阶段训练一共使用了 2.1B 的 token, lr 为 1e-3, 训练的步数为 1000 steps, batch size 为 16.
Sparse training stage 这个阶段模型所有的参数都参与训练,该阶段的目的是让模型学习到 DSA 的 sparse pattern. 训练时,作者让 lightning indexer 的输出与 $p_{t,S_t}$ 之间的输出进行对齐,其中 $S_t=\{s\mid I_{t,s}\in\mathrm{TopK}(I_{t,:})\}$:
$$ \mathcal{L}^I = \sum_{t}\mathcal{D}_{KL}(p_{t,S_t}\ \Vert\ \mathrm{Softmax}(I_{t,:})) $$实际训练时,lightning indexer 仅接受 $\mathcal{L}^I$ 的反向传播,而 LLM 则仅接受 next-token prediction loss. 这个阶段模型一共使用了943.7B token, 其中 $K$ 设置为 $2048$. 学习率为 $7.3\times 1e-6$, 训练步数为 15,000 steps, batch size 为 480.
Post-training
post-training 与 DeepSeek-V3.1 一致:
Specialist Distillation 作者基于 DeepSeek-V3.2 base 构建了不同领域的 specialized model, 这些领域包括:
- math
- competitive programming
- general logical reasoning
- agentic coding
- agentic search
每个 specialized model 都使用 RL 进行训练,训练数据包括 long CoT reasoning 数据以及 direct response generation 数据,specialized model 训练完毕之后,就被用于生产 domain-specific data, 作者通过实验发现,基于这种蒸馏方法,模型的表现仅比 specialized model 低一点,并且这个 gap 可以被后续的 RL 训练所抵消。GLM-4.5 也采取了类似的做法
Mixed RL Training 作者使用了 GRPO 算法进行训练,与 DeepSeek-V3 不同,作者将 reasoning, agent 以及 human alignment 的 RL 训练合并为了一个阶段,作者认为这种方法可以平衡模型在多个 domain 上的表现,并且可以防止 multi-stage training 带来的灾难性遗忘问题。对于 reasoning 和 agent 任务,作者使用了 rule-basd outcome reward, length penalty 以及 language consistency reward. 对于通用任务,作者使用了 generative reward model, 每个 prompt 都有对应的 rubris 用于 evaluation. 作者构建 reward 时主要考虑了:
- length versus accuracy
- language consistency versus accuracy
DeepSeek-V3.2-Speciale 除了 DeepSeek-V3.2 之外,作者还训练了 DeepSeek-V3.2-Speciale 模型,该模型仅使用 reasoning 数据进行训练,reasoning 数据包含了 DeepSeek-Math-V2 的训练数据以及 reward 方法。训练时,作者降低了 length penalty 的惩罚系数,最终 DeepSeek-V3.2-Speciale 模型拥有更强的 reasoning 能力
Scaling GRPO
作者在 GRPO 的基础上对 KL estimate 进行了改进(见 KL divergence),使用了 importance sampling 对 K3 estimator 进行修正:
$$ \mathcal{D}_{\mathrm{KL}}(\pi_\theta(o_{i,t})\Vert\pi_{\mathrm{ref}}(o_{i,t})) = \frac{\pi_\theta(o_{i,t}\mid q, o_{i,Off-Policy Sequence Masking 作者还使用了 sequence masking 来提高 off-policy data 的数据使用效率,由于不同 rollout 的完成时间不一致,训练过程中会出现 off-policy 现象,即某些 mini-batch 不是由当前 policy 产生,这个现象在 Magistral 中也有提到,这种训练 - 推理不一致性会进一步加剧 off-policy 程度,为了提高训练稳定性,作者将 policy divergence 程度比较高的 sequence 给 mask 掉,更新后的损失函数如下所示
$$ \mathcal{J}_{\mathrm{GRPO}}(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},\{o_i\}_{i=1}^G\sim \pi_{\theta_{old}}(\cdot\mid q)}\left[ \frac{1}{G}\sum_{i=1}^G\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\min\left(r_{i,t}(\theta)\hat{A}_{i,t},\mathrm{clip}\left(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon\right)\hat{A}_{i,t}\right)M_{i,t}-\beta \mathcal{D}_{\mathrm{KL}}(\pi_\theta(o_{i,t})\Vert\pi_{\mathrm{ref}}(o_{i,t}))\right] $$其中,
$$ M_{i,t} = \begin{cases} 0, &\hat{A}_{i,t}<0, \frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\log r_{i,t}(\theta)<\delta\\ 1, &\text{otherwise} \end{cases} $$用于决定是否对当前 sequence 进行 mask, $\delta$ 是一个超参数控制 policy divergence 程度。作者认为,模型主要从自身的错误进行学习,而 off-policy 的负样本模型学习提升有限甚至有害。作者发现加入这个 masking 策略之后,模型的训练稳定性有所提升。
Keep Routing MoE 模型在进行 On-policy RL 训练是,由于 policy 的更新,新 policy 和旧 policy 专家的 routing 可能会不一致,这种不一致性会降低训练的稳定性以及 off-policy 现象。为了解决这个问题,作者在采样室,保存了训练阶段所使用的 expert routing path, 来保证训练推理的一致性。这种策略可以有效提高针对 MoE 模型的 RL 训练稳定性
Keep Sampling Mask 作者发现,使用 top-p 和 top-K 可以提高 LLM 输出的质量,但是这种采样擦略也会导致 $\pi_{\mathrm{old}}$ 和 $\pi_{\theta}$ action space 的不匹配,因此,作者记录了 $\pi_{\mathrm{old}}$ 采样过程中的 truncation mask, 然后再训练的时候将其应用到 $\pi_{\theta}$ 上,作者发现通过这种方式可以有效提高 RL 训练过程中的 language consistency
Thinking in Tool-Use
本节的目的是希望能够将 reasoning 能力应用到工具调用的场景下。
作者发现,如果使用 DeepSeek-R1 的策略,在下一轮对话到来时,丢弃到当前的 reasoning content 会让模型重新生成针对问题的 CoT, 从而产生 token inefficiency. 为了解决这个问题,作者构建了一个上下文管理策略,如下图所示

具体做法为:
- reasoning content 只有当有新的 user message 进入时才会丢弃;如果只有工具调用相关的 message, 则 reasoning content 会保留
- 移除 reasoning content 时,会保留对应的工具调用及其结果
在训练时,作者认为模型已经掌握了比较好的指令跟随能力,我们仅需要将 reasoning data (non-agentic) 和 non-reasoning data(agentic) 以不同的 prompt 输入给模型就能够得到比较好的结果。
对于训练的数据,作者认为 RL 任务的多样性可以有效提高模型的 robustness, 因此作者构建了不同的环境及其对应的 prompt, 生成的任务如下表所示
| number of tasks | environment | prompt | |
|---|---|---|---|
| code agent | 24667 | real | extracted |
| search agent | 50275 | real | synthesized |
| general agent | 4417 | synthesized | synthesized |
| code interpreter | 5908 | real | extracted |
- search agent: 作者使用了 multi-agent 的策略,包括 question-construction agent 用于构建 QA pair, multiple answer-generation agent 用于构建不同的 response, 一个 verification agent 用于评估生成的 response. 最后作者使用 generative reward model 来评分
- code agent: 作者爬取了 Github 上的 pull request, 然后进行过滤,接下来作者通过一个 environment-setup agent 来构建对应的环境
- code interpreter agent: 作者使用 jupyter notebook 作为代码解释器来解决复杂的 reasoning tasks, 包括 math, logic, data science 等
- general agent: 作者构建了验证简单解决困难的任务。首先作者基于 agent 和 task category 来生成或检索相关数据;接下来作者合成一个任务相关的工具集合;最后,作者让一个 agent 来提出任务以及对应的解法,并不断提高任务的难度。最后得到
<environment, tools, task, verifier>的 tuple 格式
Experiments
作者对比了 DeepSeek-V3.2-Exp 和 Claude-4.5 Sonnet, GPT-5, Gemini 3.0 Pro, Kimi-K2 thinking, MiniMax M2 的表现,评测结果如下
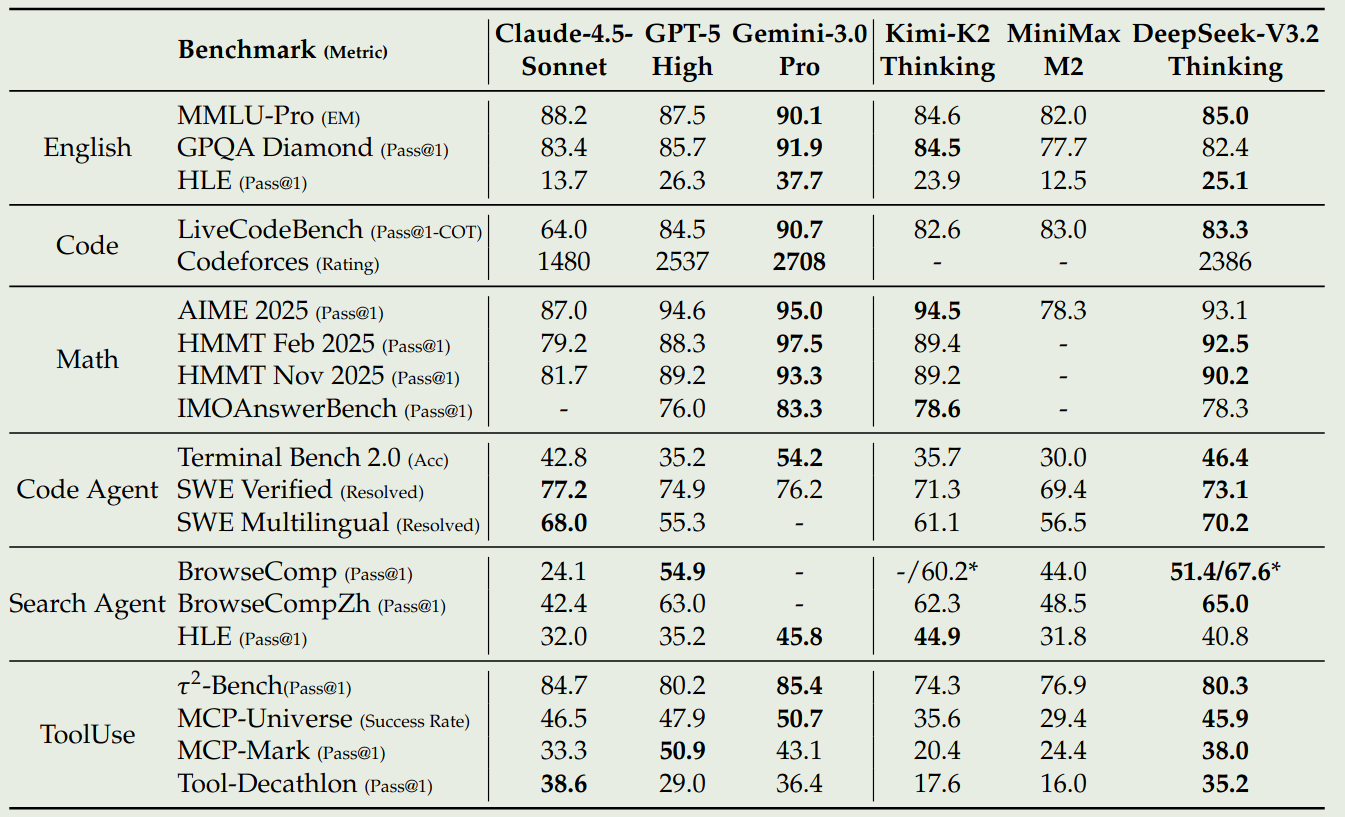
结果显示,DeepSeek V 3.2 和 GPT-high 在 reasoning 任务上的表现差不多。作者认为,进一步提高 RL 阶段的算力可以有效提高模型的表现
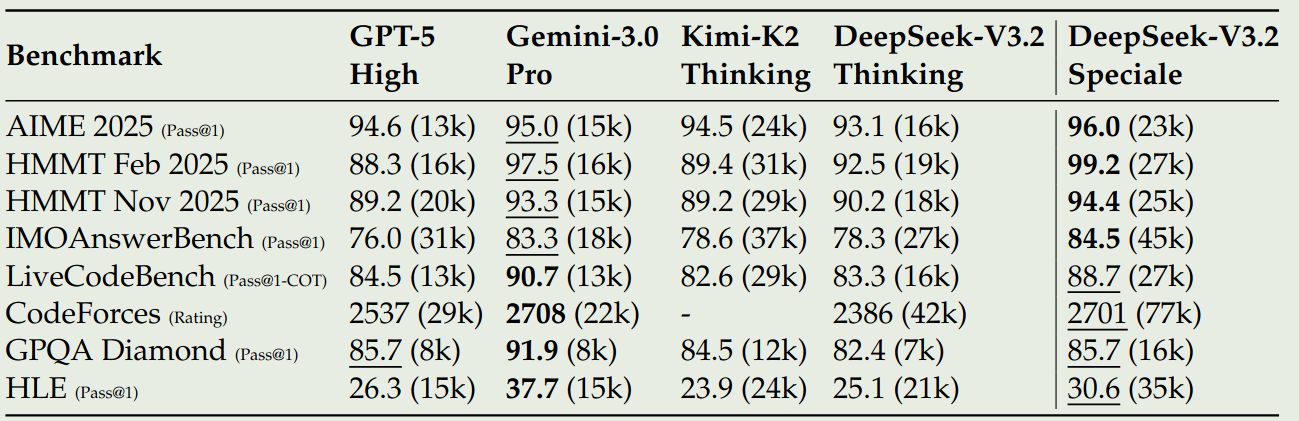
作者还对比了 DeepSeek-V 3.2-Speciale 的表现,结果显示,提高 token budget 之后,模型的表现显著提高,与 Gemini 3.0 Pro 可以相比,但是其 token efficiency 仍然弱于 Gemini 3.0 Pro, 结果如下图所示
接下来作者验证了 synthesis agentic tasks 对模型表现的影响。首先,作者随机采样一批样本使用闭源 LLM 进行测试,发现闭源模型表现最好为 $62\%$, 这说明了合成数据对于 DeepSeek V3.2 和闭源模型都是有挑战的。
其次,作者探究了合成数据是否能够提高 RL 的泛化性,作者构建了两个额外模型:
- SFT: 在 SFT checkpoint 上进行 RL
- Exp: 仅在 search 以及 code environment 上进行 RL
对比结果发现,合成数据缺失可以有效提高模型的表现
作者还对比了 DSA 的效率,DSA 可以将 attention 的计算复杂度由 $\mathcal{O}(L^2)$ 降低到 $\mathcal{O}(LK)$, 其中 $K$ 是选取的 top-K tokens. 尽管 lightning indexer 的复杂度仍然是 $\mathcal{O}(L^2)$, 但是其计算量远小于 MLA, 作者对比了两者的效率,实验结果如下图所示
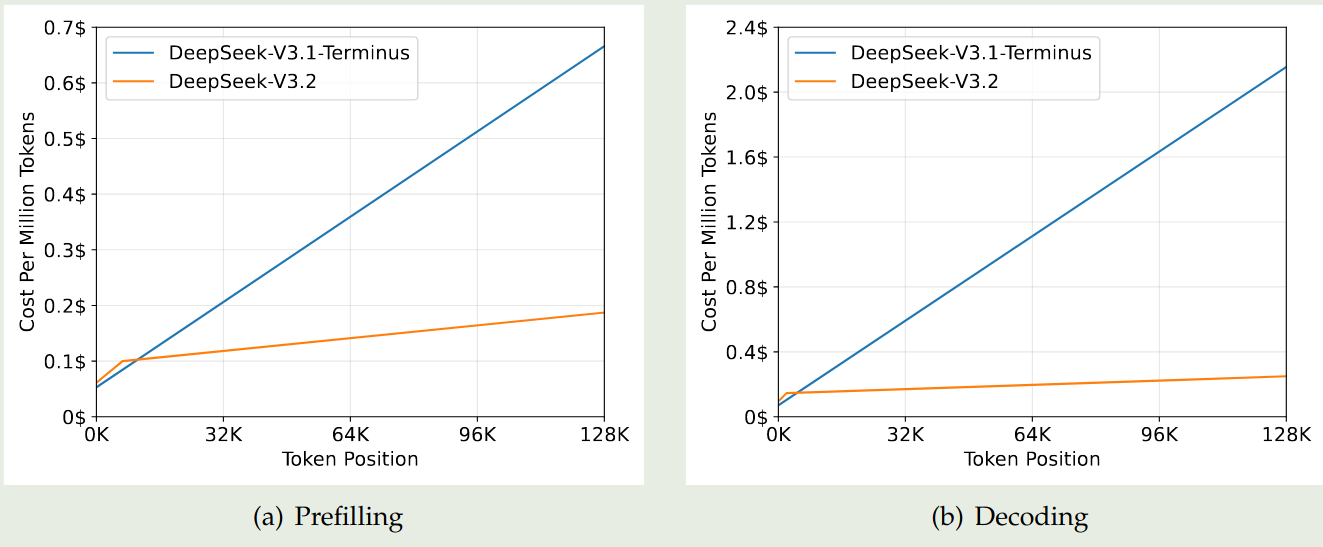
可以看到,DeepSeek-V3.2 的 prefilling 和 decoding 效率都远高于 DeepSeek-V3.1
最后,作者对比了不同上下文管理策略对模型表现的影响,对比策略有:
- Summary: 对轨迹进行总结然后重新初始化 rollout
- Discard 75%: 丢弃到初始 75% 的工具调用历史
- Discard-all: 丢弃掉所有的工具调用历史
- Parallel-fewest step: 多次采样然后保留步数最少得轨迹
实验结果如下图所示
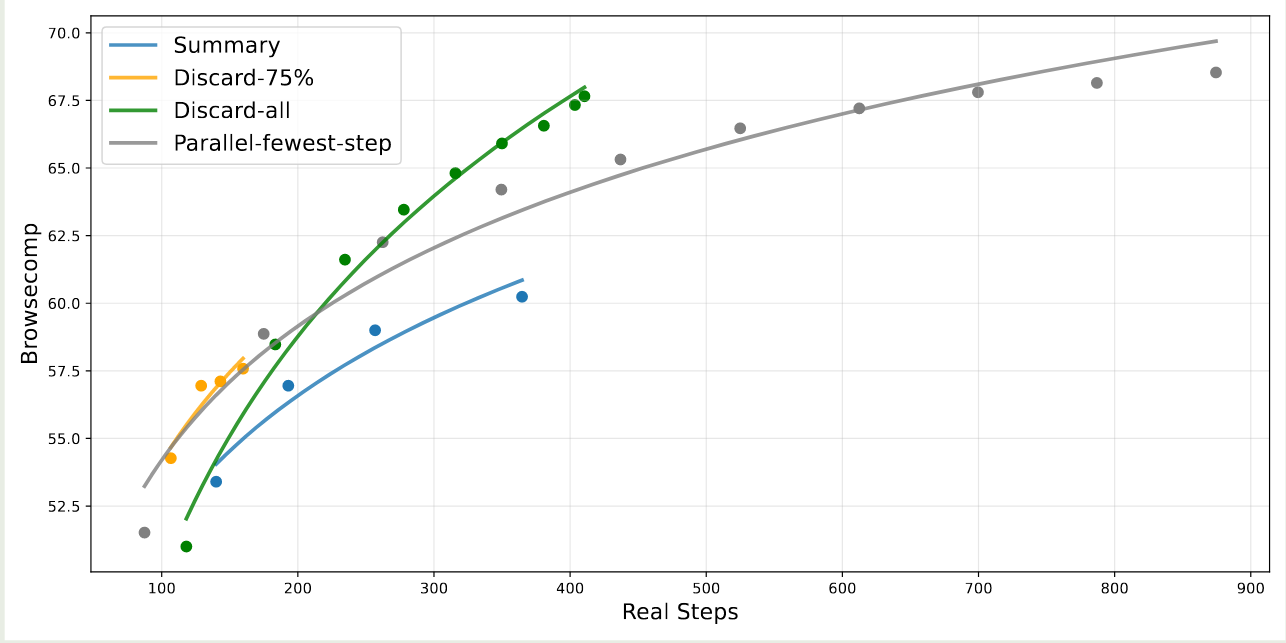
结果显示,使用上下文管理策略之后,模型的表现有了显著提升。并且,discard-all 策略虽然很简单,但是其表现非常好。作者认为如何根据不同场景来选取合适的策略是一个待解决的问题。
Conclusion
作者在本文中提出了 DeepSeek-V 3.2, DeepSeek-V 3.2 使用了一个稀疏注意力机制来提高模型在长上下文场景下的计算效率。作者还通过提升 RL 阶段的算力来提高模型在下游任务上的表现。最后,作者合成了大规模的 agentic task 来提升模型的 agent 能力。
作者认为,相比于 Gemini 3.0 Pro, 模型的知识广度仍然有限。并且,目前模型的 token efficiency 仍然是一个问题,模型需要更长的轨迹输出才能达到 Gemini 3.0 Pro 的表现。最后,模型解决复杂问题的能力仍然弱于闭源模型。