Introduction
已有的 MLLM 将视觉 token 作为一个 1d sequence, 输入给 LLM. 在本文中,作者将 visual token 注入到 LLM 的不同 layer 中来提高视觉信息的利用率
Method
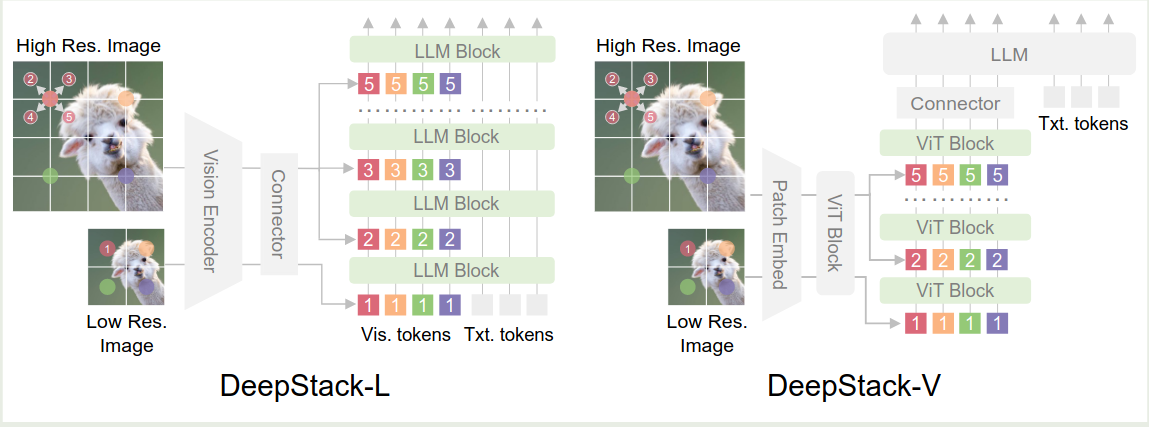
首先,对于输入的图片 $I$, 我们将其分为高精度图片版本 $I_{high}$ 和低精度图片版本 $I_{low}$, $I_{low}$ 通过 vision encoder 和 MLP 得到对应的视觉 token $X_v$ 作为 LLM 的输入,然后在 LLM transformer block 的第 $i$ 层,其对应的视觉 token $X_{i,v}$ 会与 stack feature $X_{v}^i$ 相加,这里 $X_v^i$ 是对高精度图片输入的一个采样,即
$$ X_v^i = \mathrm{Sampling2D}(\mathrm{MLP}(\mathrm{ViT}(I_{high}))) $$算法伪代码如下所示
| |
Experiments
Ablation Study
作者进一步验证了不同实验配置,结果发现在 early layer 进行 deepstack 效果最好,越往后效果越差
作者还在 ViT 上应用了 DeepStack 策略,结果发现 ViT 的效果也有所提升
作者还发现,模型表现提升是因为加入了 high-reoslution image token 信息
Conclusion
作者在本文中提出了 DeepStack, 一个提高 MLLM 中视觉信息利用率的方法,作者验证了这个方法的有效性。