MX format 是一个表示数据的数据格式,在 LLM 中主要用于量化。相比于直接对整个张量进行量化,MX format 可以在更细粒度的层面控制量化,从而提高模型的表现
Microscaling
Microscaling (MS) format 如下图所示
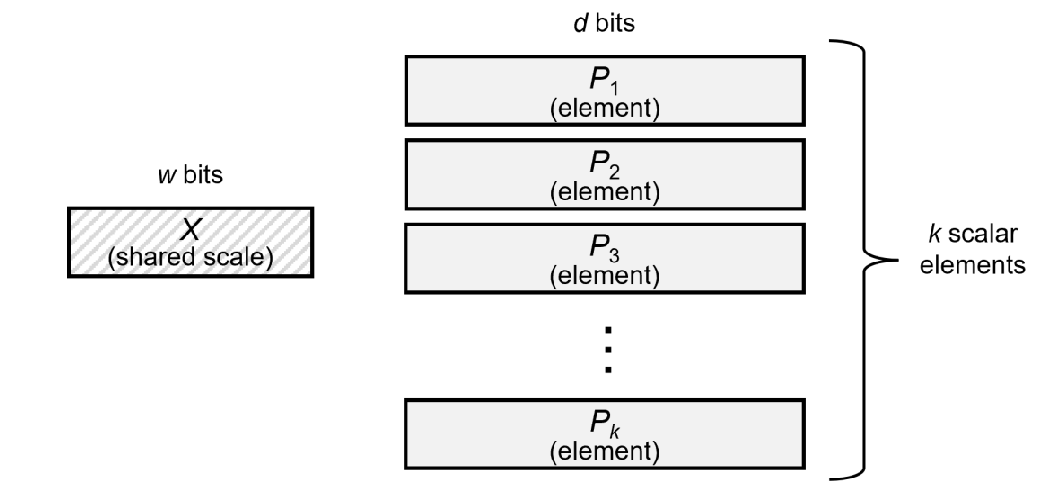
MX format 包括三个部分:
- elements $P_1,\dots,P_k$ 未 scale 的数据,要求 $P_1,\dots,P_k$ 的数据类型相同
- shared scale $X$, 对 element 进行的 scale 参数,所有的 $k$ 个 bits 共享一个 $X$
- block size, 决定 element block 的大小
在存储时,我们只需要存储 $X$ 以及 $P_1,\dots,P_k$, 我们假设 $X$ 需要 $w$ bits 来表示,$P_i$ 需要 $d$ bits 来表示,则我们一共需要 $w+kd$ bits 来表示这 $k$ 个元素。
Concrete MX-compliant Formats
MX-format 包含了一下几种数据格式:
| Format Name | Element Data Type | Element Bits(d) | Scaling Block Size(k) | Scale Data Type | Scale Bits(w) |
|---|---|---|---|---|---|
| MXFP8 | FP8 (E5M2) | 8 | 32 | E8M0 | 8 |
| MXFP8 | FP8 (E4M3) | 8 | 32 | E8M0 | 8 |
| MXFP6 | FP6 (E3M2) | 6 | 32 | E8M0 | 8 |
| MXFP6 | FP6 (E2M3) | 6 | 32 | E8M0 | 8 |
| MXFP4 | FP4 (E2M1) | 4 | 32 | E8M0 | 8 |
| MXINT8 | INT8 | 8 | 32 | E8M0 | 8 |
GPT-oss Quantization
gpt-oss 中使用了 MXFP4 来表示 MoE 中的 down projection 以及 up projection weight matrix 的权重。
其具体操作过程如下:
- 我们将参数分为大小为 32 的 block
- 每个 block 由一个 scale $X$ 来表示,其精度为 E8M0, 即 8bits, 表示范围为 $[-127,127]$, 以及 $32$ 个元素 $P_i$ 来表示,每个元素的精度为 E2M1, 即 4bits, 表示范围为 $[-6.0,6.0]$.
- 由于每个元素由 4bits 来表示,因此我们将两个元素合并在一起来表示
在加载时,我们可以用如下代码来恢复 $P_i$ 的值到 FP8
| |