Introduction
当前大语言模型在性能与效率上面临双重挑战:纯 Softmax 注意力计算成本高,而纯线性注意力则性能不足。Qwen3-Next 尝试通过混合注意力机制解决这一矛盾,同时结合 MoE 架构与多项训练优化策略,实现在保持高性能的同时大幅提升训练与推理效率。
Qwen3-Next 包含三个模型:
- Qwen3-Next-80B-A3B-Base
- Qwen3-Next-80B-A3B-Instruct
- Qwen3-Next-80B-A3B-Thinking
Method
Architecture
模型架构如下图所示
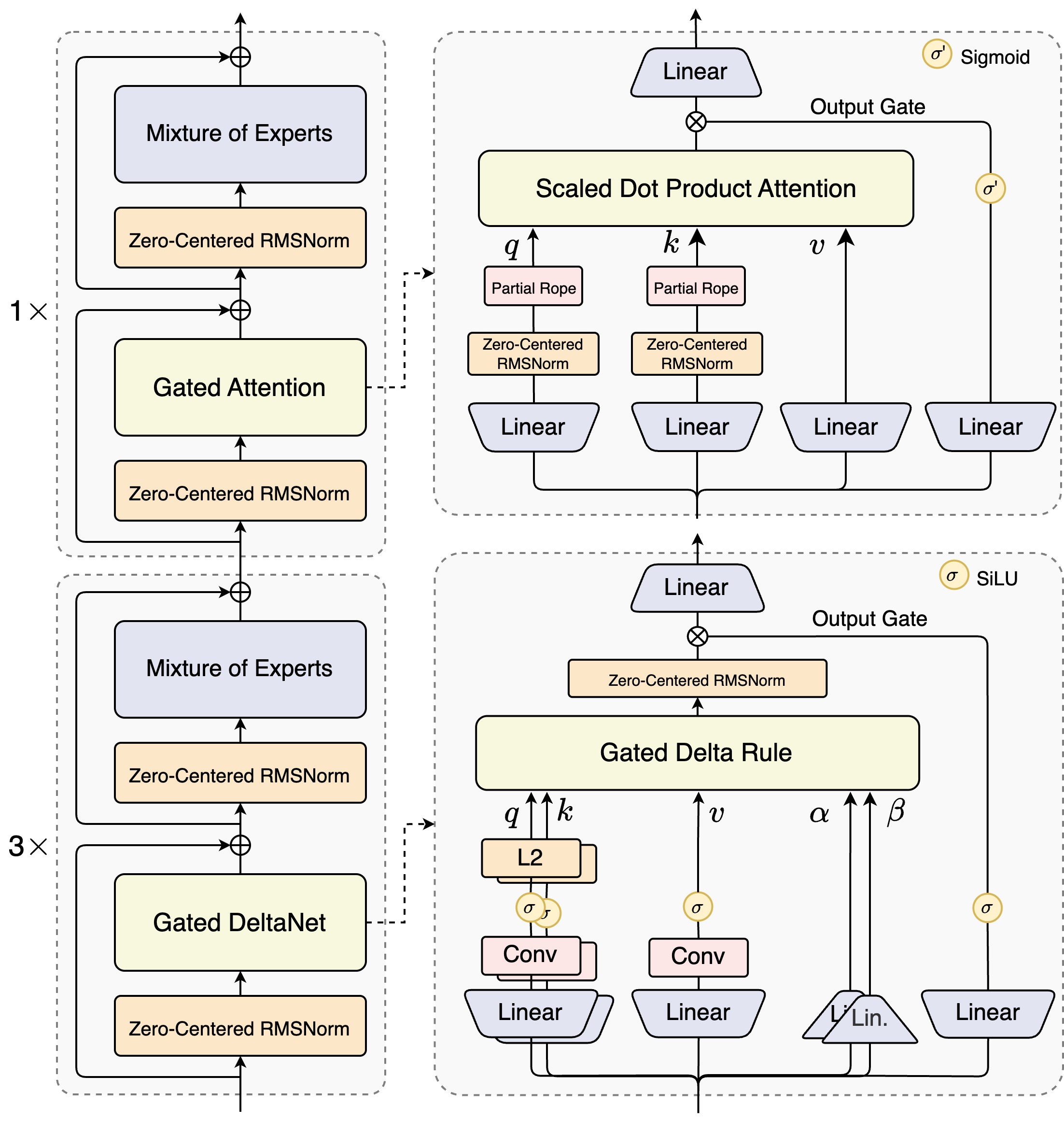
Hybrid Attention
作者首先总结了 linear attention 和 softmax attention 各自的优缺点。
| pros | cons | |
|---|---|---|
| linear attention | fast | low performance |
| softmax attention | slow | high performance |
因此,作者的动机就是是结合 linear attention 与 softmax attention, 在局部利用 linear attention 的高效性来提高训练和推理效率,在关键部分使用 softmax attention 来提高模型的能力。 这种混合注意力机制之前也有很多模型采用,比如 MiniMax-01 等。最终 Qwen3-Next 使用了 Gated DeltaNet+Gated Attention 的混合注意力机制,模型的 transformer layers 按照 4 个为一组,前三层使用 Gated DeltaNet, 第四层使用 Gated Attention.
下面是一些细节:
- Gated DeltaNet 相比于 SWA 和 Mamba2, 其 in-context learning 能力更强
- 对于 softmax attention:
- 使用了 Gated Attention 提出的 gating 机制来解决 massive activation 和 attention sink 问题
- 将 attention head 的 dimension 从 128 提高到 256
- 使用了和 DeepSeek-V3 类似的 partial RoPE 机制,仅对前 $25\%$ 的元素进行旋转
MoE
- 1 个共享专家,512 个路由专家,其中激活专家个数为 10 个。
- 对于 MoE router 的参数,作者还进行了 normalization 来保证每个专家被选择的概率相同。
- 与 Qwen3 一致,Qwen3-Next 也是用了 Global-batch load balancing 策略,在保持激活专家数不变的情况下,通过提高总专家个数来降低训练损失。
Normalization and Training
- 使用 Gemma 提出的 Zero-Centered RMSNorm 以及 weight decay 来避免过大的权重出现
- 为了提高数据使用效率,作者还使用了 MTP 策略来提高训练效率,模型表现以及 Speculative decoding 的接受率。
- 预训练时,Qwen3-Next 使用了15T token 进行训练,训练时间相比于 Qwen3-30B-A3B 有了大幅度的提升
Experiments
Efficiency
下图是 Qwen3-Next 与 Qwen3-32B 模型的训练效率对比
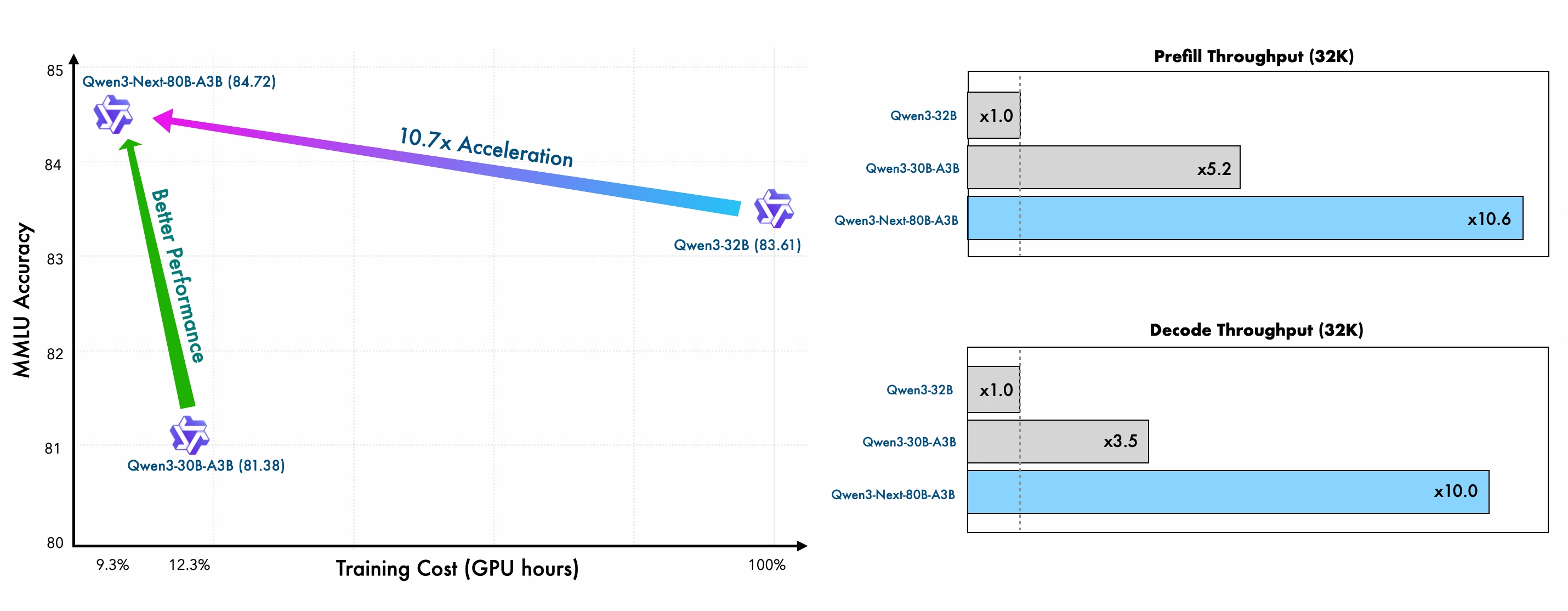
从结果可以看出,相比于 Qwen3-32B, Qwen3-Next 只用了 $9.3\%$ 的算力就达到了更强的表现。
并且,在 inference 阶段,由于使用了 linear attention, Qwen3-Next 的效率也更高,下面是 Qwen3-Next 相比于 Qwen3-32B 的效率提升
| 4K | 32K | |
|---|---|---|
| Prefilling | $7\times$ | $10\times$ |
| Decoding | $4\times$ | $10\times$ |
Performance
下面是 Qwen3-Next-Base 的表现
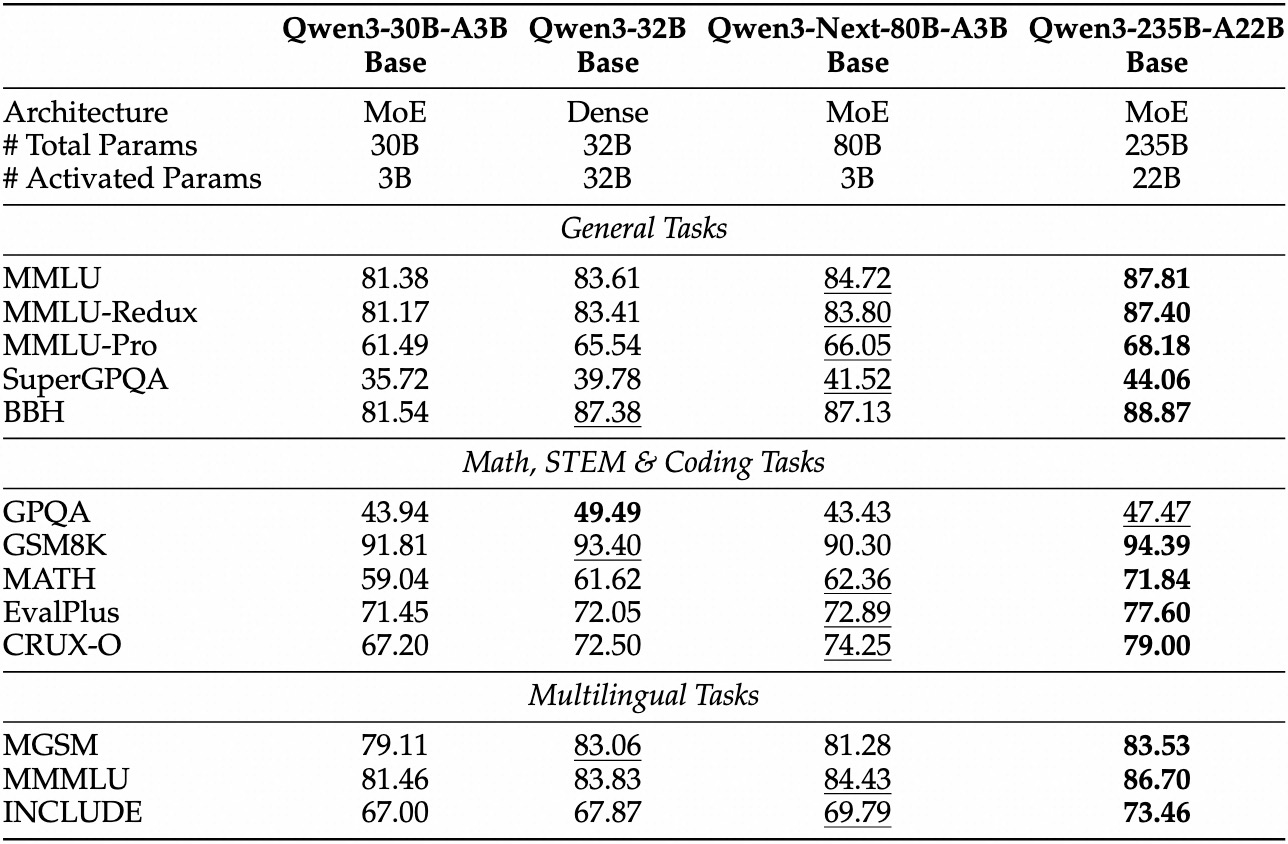
可以看到,Qwen3-Next-Base 在多个 Benchmark 上的表现仅次于 Qwen3-235B-A22B
Qwen3-Next-Instruct 的表现如下表所示
| Benchmark | Qwen3-Next-80B-A3B-Instruct | Qwen3-235B-A22B-Instruct-2507 | Qwen3-32B Non-thinking | Qwen3-30B-A3B-Instruct-2507 |
|---|---|---|---|---|
| SuperGPQA | 58.8 | 62.6 | 43.2 | 53.4 |
| AIME25 | 69.5 | 70.3 | 20.2 | 61.3 |
| LiveCodeBench v6 | 56.6 | 51.8 | 29.1 | 43.2 |
| Arena-Hard v2 | 82.7 | 79.2 | 34.1 | 69.0 |
| LiveBench | 75.8 | 75.4 | 59.8 | 69.0 |
Qwen3-Next-Instruct 的长文本表现(RULER Benchmark)如下
| Model | Avg. | 4K | 8K | 16K | 32K | 64K | 96k | 128K | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-30B-A3B-Instruct-2507 | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-235B-A22B-Instruct-2507 | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-Next-80B-A3B-Instruct | 91.8 | 98.5 | 99.0 | 98.0 | 98.7 | 97.6 | 95.0 | 96.0 | 94.0 | 93.5 | 91.7 | 86.9 | 85.5 | 81.7 | 80.3 | 80.3 |
可以看到, Qwen3-Next-Instruct 在 1M 长度范围内保持稳定性能,整体平均得分 91.8,接近 Qwen3-235B(92.5)。
Qwen3-Next-Thinking 的表现如下表所示
| Benchmark | Qwen3-Next-80B-A3B-Thinking | Gemini-2.5-Flash Thinking | Qwen3-32B Thinking | Qwen3-30B-A3B-Thinking2507 |
|---|---|---|---|---|
| SuperGPQA | 60.8 | 57.8 | 54.1 | 56.8 |
| AIME25 | 87.8 | 72.0 | 72.9 | 85.0 |
| LiveCodeBench v6 | 68.7 | 61.2 | 60.6 | 66.0 |
| Arena-Hard v2 | 62.3 | 56.7 | 48.4 | 56.0 |
| LiveBench | 76.6 | 74.3 | 74.9 | 76.8 |
可以看到,Qwen3-Next-Thinking 的表现在除了 Livebench 之外的三个 Benchmark 均达到了 SOTA
Conclusion
Qwen3-Next 通过混合注意力架构与精细化 MoE 设计,在训练与推理效率上实现突破性提升。其仅以较小计算代价达到接近超大模型性能的表现,为下一代高效大语言模型的设计提供了重要参考。