Introduction
作者在本文中提出了 Qwen3-VL 系列多模态大模型,包括 4 个 dense 模型和两个 MoE 模型,模型的上下文长度为 256K, 通过数据和训练上的优化,作者保持了模型的纯文本能力。最终 Qwen3-VL 包括 non-thinking 和 thinking variants.
在架构上,Qwen3-VL 进行了三点改进:
- Interleaved MRoPE: 作者解决了 Qwen2.5-VL 提出的 MRoPE 在长视频理解场景下的频谱不平衡问题
- DeepStack: 作者使用了 DeepStack 来提取 ViT 不同 layer 的视觉特征
- Explicit Video timestamps: 作者使用了绝对时间来标记 frame 来提供更直接的时间信息
在数据上,作者使用了 image caption, OCR, grounding, spatial reasoning, code, long documents 以及 temporally grounded video 等数据,作者 还是用了 GUI-agent interaction 数据来提高模型的 action 能力
在训练上,Qwen3-VL 包含两个大的阶段:pre-training 和 post-traing, pre-training 包含 4 个小阶段,post-training 包含 3 个阶段。
Architecture
Qwen3-VL 的架构如下所示
其中,
- LLM: LLM 使用了 Qwen3 系列大语言模型,包括 2B, 4B, 8B, 32B 四个 dense model 以及 30B-A3B, 235B-A22B 两个 moe 模型
- Vision Encoder: encoder 基于 [[SigLip-2]] 初始化,然后使用了 dynamic input resolutions 进行 continue training, 作者使用了 CoMP 提出的 2D-RoPE 以及 interpolate absolute position embedding, 最终包括 SigLip2-SO-400M 和 SigLip-Large (300M) 两个 size, 后者用于 2B 和 4B 两个 size
- Patch Merger: 一个 2 层的 MLP, 将四个 visual token 压缩为 1 个
Interleaved MRoPE
这部分介绍见 [[MRoPE-Interleave]]
DeepStack
受 Deepstack 启发,作者从 vision encoder 的中间层(具体来说是第 8, 16, 24 层)提取对应的视觉特征,然后经过 MLP 与 LLM 对应 layer 的视觉 token 直接进行相加。
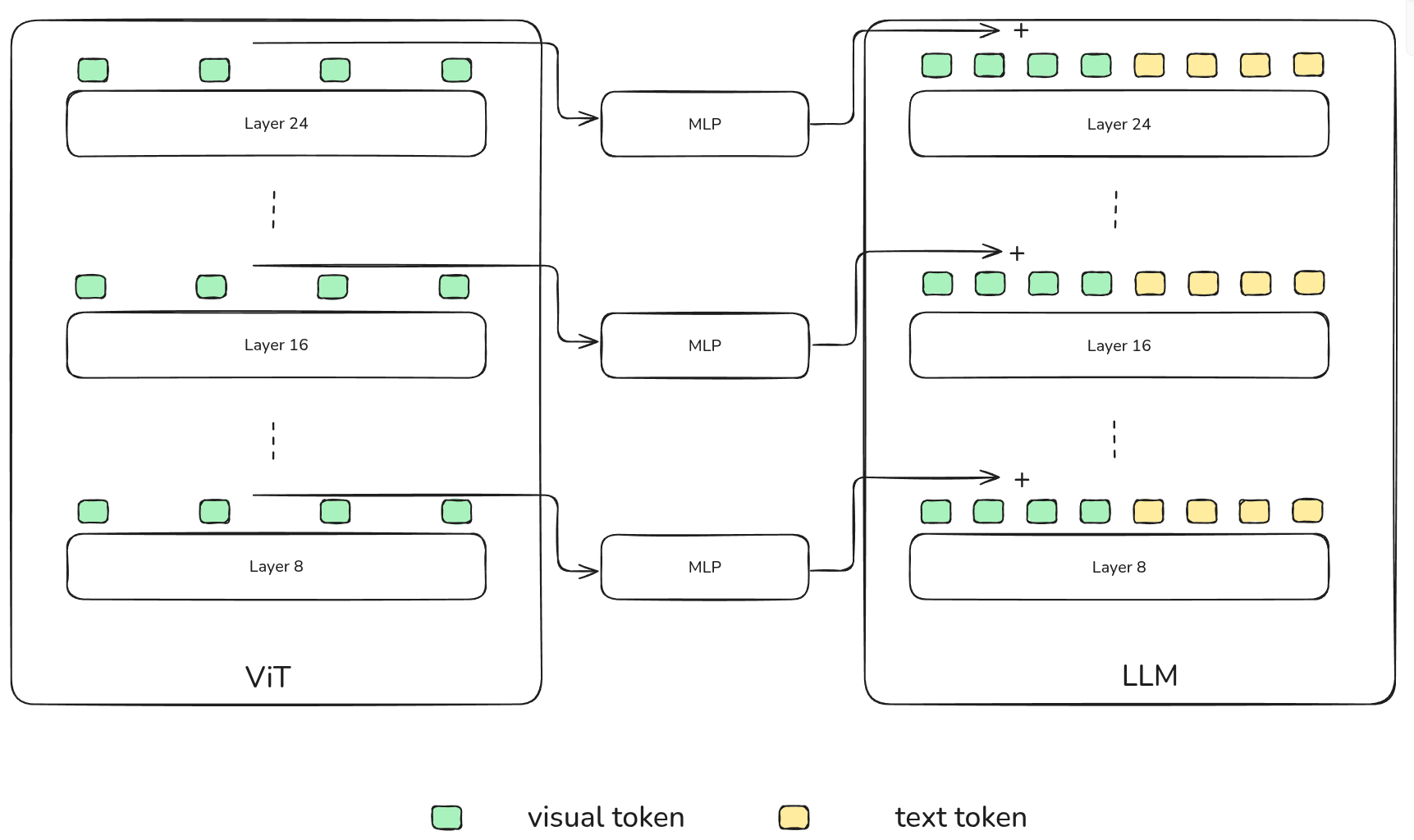
Video Timestamp
作者发现,Qwen2.5-VL 中使用的 MRoPE 存在如下问题:
- 将 temporal position 与绝对时间绑定之后,对于长视频会产生非常大且稀疏的 temporal position ids
- 需要使用不同的 FPS 进行采样来提高模型的泛化性
为了解决这个问题,作者使用了一个 textual token-based time encoding strategy, 其中每个 video temporal patch 对应的 timestamp 表示为 <3.0 seconds>, 这样视频会被处理为以下格式
| |
在训练时,作者还使用了 seconds 以及 HMS 两种格式来提高模型对于不同格式的泛化能力。作者认为,虽然这种表示会提高上下文长度,但是也能够提高模型 video grounding 或者 dense captioning 等时序信息敏感任务的表现
Pre-training
Training Recipe
预训练阶段包含 4 个阶段,如下图所示

- Stage 0: 这一阶段的目的是对齐视觉特征和文本特征,只训练 Patch merger, 训练使用了 67B token, 覆盖 image-caption, knowledge, OCR 数据,上下文长度为 8192
- Stage 1: 这一阶段所有参数都参加训练,训练使用了 1Ttoken, 作者在训练是加入了纯文本数据,最终数据包含 interleaved image-text, visual grounding, VQA, STEM, video 数据,上下文长度为 8192
- Stage 2: 这一阶段的目的是扩展模型的上下文长度到 32K, 训练使用了 1T token, 数据包括长视频以及 agent-oriented instruction-following 数据
- Stage 3: 这一阶段的目的是将模型的上下文长度进一步扩展到 262K, 训练使用了 100B token. 数据包括长视频以及长文本
Data
- Image Caption Data: 作者使用了 Qwen2.5-VL 32B 来进行 re-captioning, 然后进行了 de-duplication 以及 clustering 来提高数据的质量和多样性
- Interleaved Text-Image Data: 作者对文档进行分裂,然后使用微调的 Qwen2.5-VL 7B 来进行解析,对于长文本,作者将连续页面拼接在一起。作者使用了对齐以及页数来保证数据的质量
- Knowledge Data: 作者构建了多个类别的数据,然后对这些数据进行 refine
- OCR: 作者构造了 30M 的数据以及 1M 的多语种数据
- Document Parsing Data: 作者从 CC 上收集了 3M PDF 以及处理了自有的 4M 数据,最终数据集里包含合成数据和真实数据;对于长文档理解数据,作者通过将 single-page 数据 merge 在一起得到,然后作者构造了 long document VQA 数据
- Grounding and counting Data: grounding 数据包括 box-based 和 Point-based 两种形式,均从开源数据集收集得到,前者包括 RefCOCO, Object365, 后者包括 PixMo; 对于 Counting, 作者基于 grounding 数据构造了 direct counting, box-based counting 以及 point-based counting 三种形式
- Spatial Understanding: 数据包括 spatial understanding 和 3D grounding 两类数据,前者的数据使用了相对位置关系来提高 spatial reasoning 的 robustness; 后者使用了 Omni3D 来统一数据格式
- Code: 包括 Qwen3, Qwen3-Coder 的纯文本 coding 数据,以及多模态 coding 数据,覆盖了将 UI 截图转换为 HTML/CSS 以及从图片生成 SVG 等任务
- Video: 包括 Dense Caption Synthesis 以及 Spatial-Temporal Video Grounding 两个任务。作者还对不同来源不同长度的数据进行了平衡
- STEM: 作者构造了一个合成数据 pipeline, 合成了 1M point-grounding samples, 2M perception-oriented VQA 数据,最终数据集包含 6M 标注图表数据,覆盖了 STEM 相关学科;对于多模态推理数据,作者收集了 60M 的 K12 以及本科生级别的练习题,作者还合成了 12M 的多模态推理数据。除了多模态推理数据,作者还加入了纯文本推理数据
- Agent: 这部分数据包括 GUI, function calling 以及 Search 三部分, GUI 数据通过数据合成得到,Function calling 数据通过强模型生成轨迹得到,search 数据通过收集执行搜索轨迹得到
Post-training
Post-training 包含三个阶段:
- SFT: 提高模型的指令跟随能力,SFT 又分为了两个小阶段,上下文长度分别为 32K 和 256K, 对于 instruct 和 reasoning 版本,作者设计了不同的数据格式,后者包含 CoT reasoning trace
- Strong-to-Weak Distillation: 提高小模型的能力,这里应该是和 Qwen3 一样,将大模型的能力蒸馏到小模型里
- RL: 提高模型的 reasoning 能力以及人类偏好对齐。这里包含了 Reasoning RL 以及 General RL 两个阶段,覆盖了 math, OCR, grounding, instruction following 等 domain
整体的训练 pipeline 我猜测应该是这样:
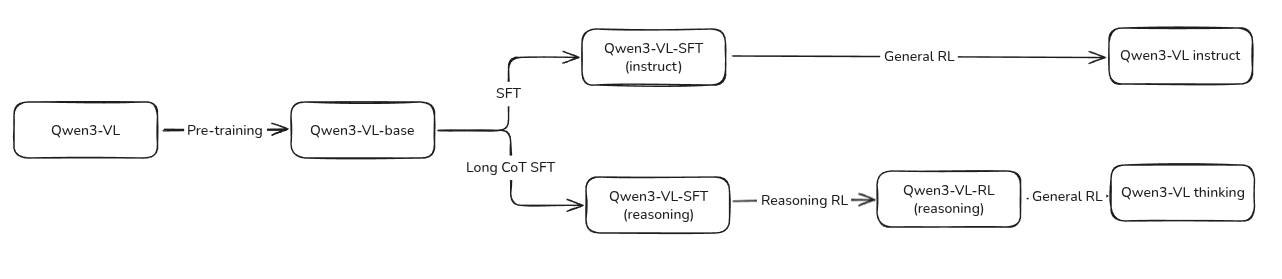
Code-start Data
Code-start Data 分为 SFT 数据和 Long CoT SFT 数据,前者用于训练 instruct 版模型,后者用于训练 reasoning 版模型
| Data | tasks | samples | training | filtering |
|---|---|---|---|---|
| SFT | spatial reasoning image-grounded reasoning spatio-temporal grounding long document understanding | 1.2M (1/3 are text-only) | - stage 1: 32K - stage 2: 256K | - query - rule-based - model-based |
| Long CoT SFT | VQA, OCR, 2D/3D grounding, video analysis, STEM, agent | text:multimodal = 1:1 | - difficulty - multi-modal - response quality |
Strong-to-Weak Distillation
蒸馏过程包括两个阶段:
- off-policy Distillation: 使用教师模型的输出进行训练提高模型基本的 reasoning 能力
- On-policy Distillation: 使用教师模型输出的 logit 作为蒸馏信号提高模型的 reasoning 能力
RL
Reasoning RL
作者收集了 30K 的 RL 数据,然后对通过率超过 90% 的数据进行过滤 (16 responses per query), 对于 reward, 作者构建了一个 unified reward framework 来提供奖励
训练时,作者使用了 SAPO 算法进行训练
General RL
作者采用了一个 multi-task RL 的范式来提高模型在不同任务上的表现,reward 主要包含两个方面:
- instruction following: 评估模型遵循用户指令的能力,包括内容,格式,长度等
- preference alignment: 对于开放式问题,评估模型帮助性,事实准确性等方面的表现
基于这两个方面 reward 有两个部分组成:
- rule-based reward: 基于规则的 reward, 比如格式要求等
- model-based reward: 使用 Qwen2.5-VL 72B 和 Qwen3 作为 judge model 来提供奖励
为了解决模型的重复性实处,中英文混杂等问题,作者构造了一个数据集来故意触发模型这些问题然后加以改正。
Thinking with Images
作者还够在了数据提高模型的 “thinking with images” 的能力,训练包含两个阶段:
- Stage 1: 作者构造了 10K Grounding 数据,然后对 Qwen2.5-VL 32B 进行 SFT 来模仿 agent 的行为: think -> act -> analyze feedback -> answer, 然后作者使用 multi-turn, tool-integrated RL 来进一步提高模型的 reasoning 能力
- Stage 2: 作者从 Qwen2.5-VL 32B 蒸馏得到 120K multi-turn agentic interactions 数据集, 然后作者使用了相似的 cold-start SFT 以及 tool-integrated RL pipeline 来训练 Qwen3-VL
这里 RL 训练的 reward 包含以下几部分:
- answer accuracy reward
- multi-turn reasoning reward
- tool-calling reward
Experiments
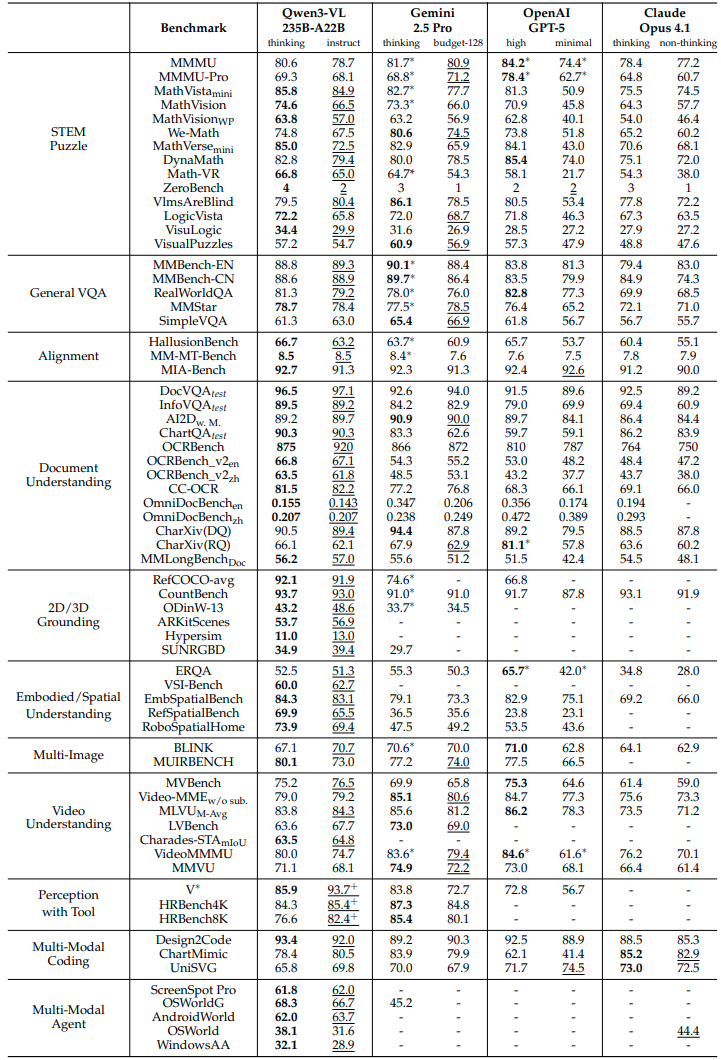
Performance
Qwen3-VL 235B-A22B 的表现如下图所示
Ablation Study
作者对比了以下 Qwen3-ViT 和 SigLIP-2 的表现,结果如下图所示

实验结果显示,使用 1.7B 的 Qwen3 和 1.5T tokens 进行训练之后,Qwen3-ViT 的表现超过了 SigLIP2 的表现,验证了 Qwen3-ViT 的有效性
作者对比了 Deepseek 和 baseline 的表现,结果如下图所示

可以看到,相比于 baseline, DeepStack 的表现更好,说明了 DeepStack 可以提供更丰富的视觉信息。
作者还评估了以下 Qwen3-VL 在视频版大海捞针任务上的表现,实验结果发现,对于 30 分钟的视频,Qwen3-VL 的准确率为 $100\%$, 通过 YARN 上下文扩展策略,模型在 2 个小时视频上的准确率为 $99.5\%$.
Conclusion
作者在本文中提出了 Qwen3-VL 系列多模态大模型,在架构上,作者使用了 interleaved-MRoPE, DeepStack 等改进策略,在数据上,作者扩展了训练数据的多样性,在训练上,作者分别训练了 instruct 版本和 reasoning 版本。最终评估发现,Qwen3-VL 达到了 SOTA 表现。
作者认为,未来的工作在于
- 基于 Qwen3-VL 构建具身智能 agent
- 提高模型的可交互感知,tool-augmented reasoning 以及 real-time multimodal control 能力
- 提高模型与人类学习,合作的能力
- 统一理解与生成多模态大模型