Introduction
softmax 函数用于将 $K$ 个实数转换为一个 $K$ 维概率分布。其具体做法是先对所有元素指数化,即求 $e^x$, 然后每个元素除以所有指数的和。即
$$ \begin{aligned} \mathrm{softmax}:\mathbb{R}^K&\to (0,1)^K\\ \mathrm{softmax}(\mathbf{z}) &=\left[\frac{e^{z_1}}{\sum_{j=1}^Ke^{z_j}},\dots,\frac{e^{z_K}}{\sum_{j=1}^Ke^{z_j}}\right] \end{aligned} $$Analysis
Properties
softmax 的第一个性质是 shift invariance, 即
$$ \mathrm{softmax}(\mathbf{z}+c) = \mathrm{softmax}(\mathbf{z}) $$证明比较容易:
$$ \mathrm{softmax}(\mathbf{z}+c)_i = \frac{e^{z_i+c}}{\sum_{j=1}^Ke^{z_j+c}} = \frac{e^ce^{z_i}}{e^c\sum_{j=1}^Ke^{z_j}} = \frac{e^{z_i}}{\sum_{j=1}^Ke^{z_j}}=\mathrm{softmax}(\mathbf{z})_i,\ i=1,\dots,K $$Gradient
向量输入下 Softmax 函数的 Jacobian 矩阵推导
设输入为向量 $\mathbf{z} = [z_1, z_2, \dots, z_d]^\top \in \mathbb{R}^d$,Softmax 函数的输出为向量 $\mathbf{a} = [a_1, a_2, \dots, a_d]^\top \in \mathbb{R}^d$,其中每个元素定义为:
$$ a_j = \text{softmax}(\mathbf{z})_j = \frac{e^{z_j}}{\sum_{k=1}^d e^{z_k}} $$记分母(归一化因子)为 $S = \sum_{k=1}^d e^{z_k}$,则 $a_j = e^{z_j}/S$.
我们分两种情况计算 $\frac{\partial a_j}{\partial z_k}$:
当 $j = k$ 时, 此时求 $a_j$ 对自身输入 $z_j$ 的偏导数:
$$ \frac{\partial a_j}{\partial z_j} = \frac{\partial}{\partial z_j} \left( \frac{e^{z_j}}{S} \right) = \frac{e^{z_j}S-e^{z_j}e^{z_j}}{S^2}=\frac{e^{z_j}}{S}\left(1-\frac{e^{z_j}}{S}\right)=a_j(1-a_j) $$当 $j \neq k$ 时, 此时求 $a_j$ 对输入 $z_k$ 的偏导数有:
$$ \frac{\partial a_j}{\partial z_k} = \frac{\partial}{\partial z_k} \left( \frac{e^{z_j}}{S} \right) = \frac{0\cdot S-e^{z_j}e^{z_k}}{S^2}=-\frac{e^{z_j}e^{z_k}}{S}=-a_ja_j $$综合以上两种情况,Jacobian 矩阵 $\mathbf{J}$ 可表示为:
$$ \mathbf{J} = \text{diag}(\mathbf{a}) - \mathbf{a} \mathbf{a}^\top $$Interpretation
Soft Argmax
softmax 是 argmax 的 smooth approximation, 所以实际上 softmax 指的是 “soft argmax". 为了证明这一点,我们首先定义如下函数
$$ \mathrm{softmax}(\mathbf{z};\tau) =\mathrm{softmax}(\mathbf{z}/\tau)=\left[\frac{e^{z_1/\tau}}{\sum_{j=1}^Ke^{z_j/\tau}},\dots,\frac{e^{z_K/\tau}}{\sum_{j=1}^Ke^{z_j/\tau}}\right] $$易知, $\mathrm{softmax}(\mathbf{z})=\mathrm{softmax}(\mathbf{z};1)$. 并且,$\mathrm{softmax}$ 还是一个光滑函数
我们定义 smooth approximation 为
Definition 如果 $\lim_{\tau\to0^+}\mathrm{softmax}(\mathbf{z};\tau)=\mathbb{1}_{\arg\max(\mathbf{z})}$, 则我们说 $\mathrm{softmax}(\cdot;\tau)$ 是 $\arg\max$ 的光滑近似,特别地,$\mathrm{softmax}(\cdot)$ 是 $\arg\max$ 的光滑近似。 这里 $\arg\max(\mathbf{z})=\arg\max_k z_k$ 是最大值的索引, $\mathbb{1}\in\{0,1\}^K$ 是示性函数 (indicator function), 即 $\mathbb{1}_{\arg\max(\mathbf{z})}[i]=1$ 当且仅当 $z_i=\max_jz_j$.
我们下面来进行证明。我们不妨假设最大值唯一,其 index 为 $m$, 即 $z_m = \max_i z_i$. 由前面的性质,我们有:
$$ \mathrm{softmax}(\mathbf{z};\tau) = \mathrm{softmax}(\mathbf{z}-z_m;\tau) =\left[\frac{e^{(z_1-z_m)/\tau}}{\sum_{j=1}^Ke^{(z_j-z_m)/\tau}},\dots,\frac{e^{(z_K-z_m)/\tau}}{\sum_{j=1}^Ke^{(z_j-z_m)/\tau}}\right] $$此时,我们有
$$ \lim_{\tau\to0^+}\mathrm{softmax}(\mathbf{z};\tau)_i = \begin{cases} 1, &\text{if }i = m\\ 0, &\text{otherwise} \end{cases} $$当最大值不唯一的时候,我们记 $\mathcal{I} = \{i\in[K]\mid z_i=\max_j z_j\}$, 与上面方法类似,最终 $\mathrm{softmax}(\cdot;\tau)$ 的结果为
$$ \lim_{\tau\to0^+}\mathrm{softmax}(\mathbf{z};\tau)_i = \begin{cases} 1/|\mathcal{I}|, &\text{if }i \in \mathcal{I}\\ 0, &\text{otherwise} \end{cases} $$因此,我们就证明了 softmax 是 argmax 函数的 smooth approximation.
Statistical Mechanics
Temperature
我们前面介绍了 $\mathrm{softmax}(\mathbf{z};\tau)$ 函数,这里的 $\tau$ 实际上被称为温度 (temperature), 它控制了输入的 variance, $T$ 越大,输入的 variance 越低,输出就倾向于均匀分布,而 $T$ 越小,则说明输入的 variance 越高,输出就倾向于 one-hot 分布。
我们前面已经证明了后者,现在我们来证明一下前者,证明思路也很简单,$T\to+\infty$ 时,$e^{x/T}\to 1$, 因而
$$ \lim_{\tau\to+\infty}\mathrm{softmax}(\mathbf{z};\tau)_i =\frac1K,\ i=1,\dots,K $$下面是可视化的代码以及结果
| |
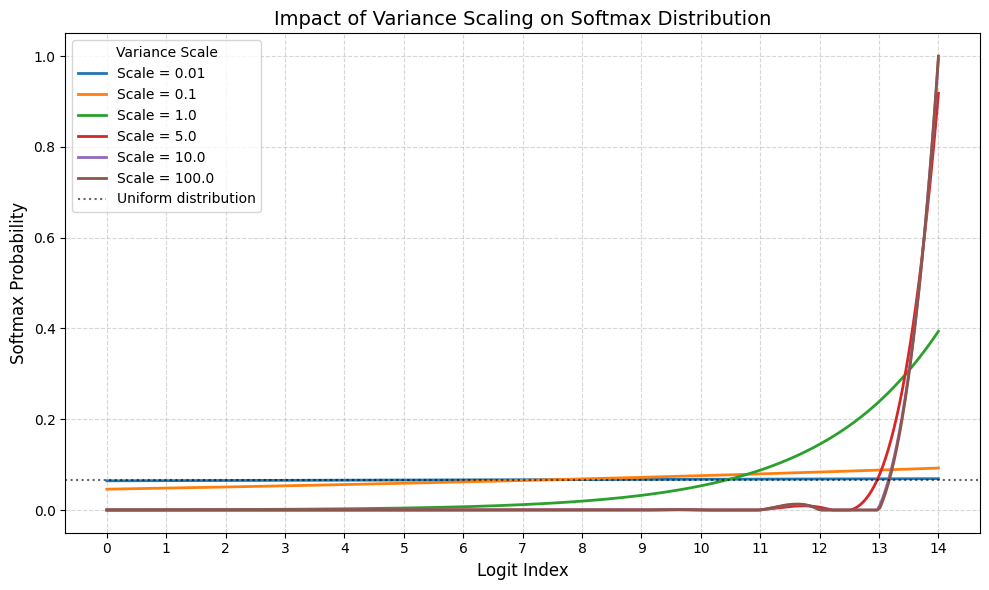
可以看到,当 variance 比较小的时候,输出的分布接近于均匀分布,而 variance 越大,输出的分布越接近 One-hot 分布。
在 attention 的计算过程中,我们也有 softmax 函数,为了在 softmax 过程中避免 variance 的影响,现在会在计算 softmax 之前加入 normalization layer 来提前进行归一化。见 QK-norm.
Algorithms
Implementation
由于 $e^x$ 在实际计算时,非常容易溢出,因此在实现的时候,我们往往会考虑其数值稳定性。实际上,现在的 softmax 函数基本由 logsumexp 实现,logsumexp 函数定义如下
$$ \mathrm{logsumexp}(\mathbf{z}) = \log \left(\sum_{i=1}^K e^{z_i}\right) $$softmax 函数与 logsumexp 函数的关系如下
$$ \begin{aligned} \mathrm{softmax}(\mathbf{z}) &=\exp\log\left(\frac{e^{\mathbf{z}}}{\sum_{j=1}^Ke^{z_j}}\right)\\ &= \exp\left(\mathbf{z} - \log\left(\sum_{i=1}^K e^{z_i}\right)\right)\\ &= \exp(\mathbf{z} - \mathrm{logsumexp}(\mathbf{z})) \end{aligned} $$考虑前面提到的 $e^x$ 数值溢出的问题,我们的输入会先经过 shift, 减掉最大值。此时我们有
$$ \mathrm{softmax}(\mathbf{z}) = \mathrm{softmax}(\mathbf{z}-c) = \exp((\mathbf{z}-c) - \mathrm{logsumexp}(\mathbf{z}-c)) $$这里我们使用了前面推导出来的 shift invariance 性质。对应的代码实现如下:
| |
Gumbel-softmax Reparametrization Trick
TODO
Online Softmax
注意到我们在计算 softmax 时,需要加载 $\mathbf{z}$ 的全部信息,如果 $\mathbf{z}$ 非常大的话,会产生频繁的内存读写进而影响整体效率。因此 flash attention 中提出了 online softmax 算法来减少内存访问开销。
其具体做法是假设我们的输入被分为若干个 block, 即 $\mathbf{z}=[\mathbf{z}^1;\dots,\mathbf{z}^n]\in\mathbb{R}^K$, 这里 $\mathbf{z}^i\in\mathbb{R}^{K/n}$ ($K\mod n=0$).
对于 $\mathbf{z}\in\mathbb{R}^K$, flash attention 定义如下结果
$$ m(\mathbf{z}) = \max_i z_i,\ f(\mathbf{z}) = [e^{z_1-m(\mathbf{z})},\dots,e^{z_K-m(\mathbf{z})}], \ \ell(\mathbf{z})=\sum_if(z)_i, \ \mathrm{softmax}(\mathbf{z}) = \frac{f(\mathbf{z})}{\ell(\mathbf{z})} $$对于 $\mathbf{z}=[\mathbf{z}^1;\dots,\mathbf{z}^n]\in\mathbb{R}^K$, 我们现在的计算方式为
$$ \begin{aligned} m_i(\mathbf{z}) &= \max([\mathbf{z}^1;\dots;\mathbf{z}^i]) = \max(m_{i-1}(\mathbf{z}),m(\mathbf{z}^i))\\ \ell_i(\mathbf{z}) &= \sum_{j=1}^if(\mathbf{z}^j) = \exp(m_{i-1}(\mathbf{z}) - m_i(\mathbf{z}))\ell(\mathbf{z}^{i-1}) + \exp(\mathbf{z}^i-m_i(\mathbf{z})) \end{aligned} $$因此,如果我们额外记录 $m(x)$ 以及 $\ell(x)$ 这两个量,那么我们可以每次仅计算 softmax 的一个 block. 计算完毕之后,$m_i(\mathbf{z})$ 和 $\ell_i(\mathbf{z})$ 就分别代表了 global max 和 global denominator.
Conclusion
我们回顾了机器学习中 softmax function 的基本定义与性质