google 在 2020 年发表了 T5 (Text-to-Text Transfer Transformer), 一个使用统一框架来将所有 NLP 任务转换为 text-to-text 格式的迁移学习框架。
Introduction
作者首先回顾了迁移学习和 pre-training, 迁移学习是提高模型在下游任务上表现的一类方法,但是目前还没有一个能够对比各种方法的框架。pre-training 通过在大量数据上进行预训练然后再进行微调,可以有效提高模型在下游任务上的表现。
为了解决这两个问题,作者首先将所有的文本处理任务统一为 “text-to-text” 的形式,这样我们就可以对比不同架构,训练方式以及数据对模型表现的影响
作者提到,本文并不是提供一个新的方法,而是详细对比不同方法,为后续研究提供基础。
Method
Model
在架构上,作者使用了 Transformer 的 encoder-decoder 架构,但是作者做了几点修改
- 作者提出了 T5 bias, 一个用于替换原始 transformer 绝对位置编码的相对位置编码形式
- 作者使用了 RMSNorm 替换了 Transformer 中的 LayerNorm.
Data
作者基于 Common Crawl 构建训练数据集,作者对数据进行了清洗,最终数据集大小为 750GB. 作者将这个数据集记为 C4 (Clean Crawled Corpus).
Downstream Tasks
下游任务包括:
- text classification: GLUE, SuperGLUE
- abstractive summarization: CNN/Daily Mail
- question answering: SQuAD
- translation: WMT English to German, French and Romanian
Input and Output Format
所有任务的输入输出都被转换为 text-to-text 格式。
Experiments
作者使用的 baseline 模型是一个基于 encoder-decoder 架构的 transformer 模型,其大小以及 configuration 与 BERT base 差不多,最终模型参数量为 220M。
| field | num layers | hidden size | MLP hidden size | num heads | head dim | dropout | seq len |
|---|---|---|---|---|---|---|---|
| value | 12 | 768 | 3072 | 12 | 64 | 0.1 | 512 |
训练时,作者使用了 AdaFactor 优化器,batch size 为 512, 训练使用了 34B token. 学习率作者使用了 inverse square root learning schedule: $1/\sqrt{\max(n,k)}$, $n$ 和 $k$ 分别代表当前 step 和 warming up steps.
作者基于 sentencepiece (见 LLM tokenizer) 构建了 Tokenizer, 覆盖 English, German, French 和 Romanian 四种语言。
模型训练的目标函数为 BERT 使用的 “masked language modeling”, 格式如下所示
| |
首先,作者对比了不同的架构。作者对比了如下三种 transformer 的变体:
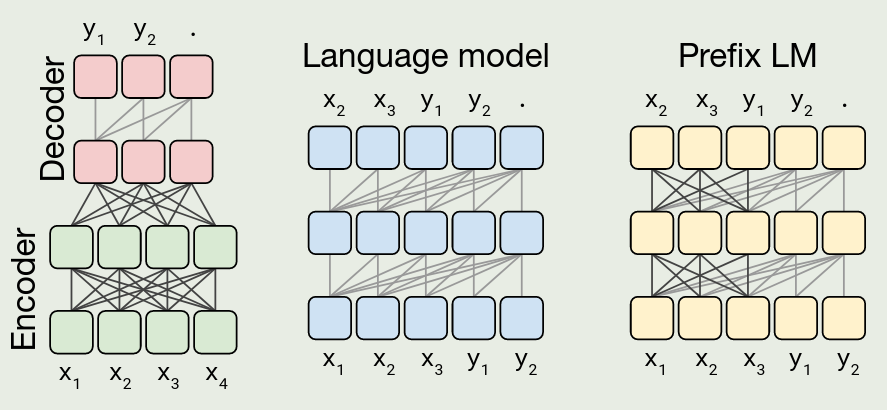
实验结果如下图所示
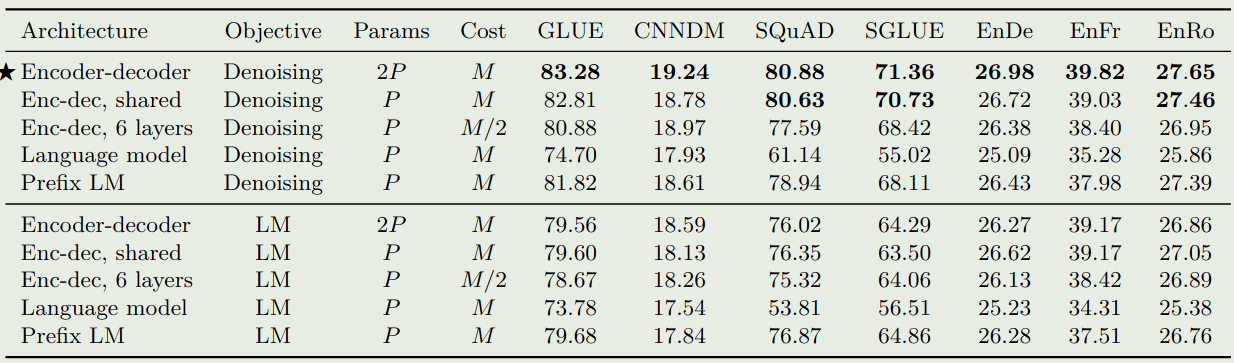
结果显示,encoder-decoder 架构,denoising 训练目标的效果最好。并且,当 layers 减少一半之后,模型的表现大幅度下降。共享参数的 encoder-decoder 架构表现比 prefix LM 效果更好
接下来作者针对 denoising 的配置进行了测试,实验结果发现 BERT-style 的训练目标效果最好,并且 corruption 比例对模型的表现影响有限,作者使用了 BERT 的配置,即 $15\%$ 的 token 被 masked 掉。对于 span length, 作者通过实验发现不同的 span length 对结果影响不大。因此,作者将 span length 设置为 $3$.
在数据上,作者发现:
- 对数据进行过滤可以提高模型的表现
- 使用 in-domain 的数据可以提高模型在该 domain 上的表现,但是问题在于 In-domain 的数据往往比较少
- 数据量过少时,模型会出现 memorization,也就是过拟合的情况
Overall
作者总结前面的发现,构建了 5 个 size 的模型:
| Model | layers | hidden size | FFN hidden size | num heads | head dimension |
|---|---|---|---|---|---|
| Small | 6 | 512 | 2048 | 8 | 64 |
| Base | 12 | 768 | 3072 | 12 | 64 |
| Large | 24 | 1024 | 4096 | 16 | 64 |
| 3B | 24 | 1024 | 16384 | 32 | 128 |
| 11B | 24 | 1024 | 65536 | 128 | 128 |
Conclusion
作者在本文中提出了 T5, 一个统一所有文本处理任务的迁移学习框架,作者系统性探究了架构,数据以及训练对模型最终表现的影响。最终作者基于 encoder-decoder transformer 架构以及 denoising training objective 训练得到了 T5 系列大语言模型。