介绍
本报告基于 OpenRouter 2024 年 11 月 - 2025 年 11 月 100T token 调用数据,从模型、任务、用户维度分析 AI 大模型使用特征,核心结论如下:
模型维度
- 市场格局:闭源模型占 70% token 使用量,主导高价值、高稳定性场景;开源模型占 30%,聚焦低成本、场景化需求,其中中国开源模型占比持续上升,但开源市场因竞争呈现碎片化(2025 年底无单一开源模型占比超 25%)。
- 模型偏好:不同闭源模型形成差异化优势(Anthropic 擅长复杂推理 / 代码、Google 偏向通用翻译 / 知识问答、xAI/Qwen 专注编程等)。
任务维度
- 核心需求:编程类任务 token 占比超 50%,Anthropic 占该领域 60% 以上份额,且编程任务输入长度是其他类别 3 倍以上;但 90% 编程需求依赖闭源模型,开源模型存在能力短板。
- 场景特征:角色扮演是开源模型第一大任务(占比超 50%),其在该场景 token 占比(43%)接近闭源模型(42%)且持续上升;agentic inference(工具调用推理)场景 token 占比超 60%,Claude 系列主导该领域。
用户维度
- 核心逻辑:能力优于成本,企业愿为强能力模型支付溢价(价格弹性低,降价 10% 仅带来 0.5~0.7% 使用率增长);免费开源模型仅达 “可用” 水平,因无法落地到实际工作流程难以形成竞争力;小模型数量占比下降,反映市场对模型能力要求提升。
- 留存逻辑(水晶鞋效应):用户留存由 “能力拐点”(首次解决未被满足的长尾需求)驱动,如 Gemini 2.5 Pro、Claude 4 Sonnet 实现能力突破后 5 个月留存率仍达 40%;缺乏能力突破的模型留存率极差,且 “水晶鞋时刻” 窗口狭窄。
Background
分析使用的 100T token 基于 OpenRouter 从2024 年 11 月到 2025 年 11 月的模型使用情况。
对于模型,作者将模型分为三类, 分别是 Proprietary, Chinese Open Sourced (Chinese OSS), Rest-of-World (RoW) open source models
| category | examples | description |
|---|---|---|
| Proprietary | Claude, GPT-5 | 闭源商业模型 |
| Chinese OSS | DeepSeek-V3, Qwen | 中文开源模型 |
| RoW OSS | mistral, LLaMA | 其他国家开源模型 |
作者基于 metadata 和 GoogleTagClassifier 将任务分为以下类别
| category | sub-category |
|---|---|
| Programming | - Computers & Electronics - Programming - Science - Computer Science |
| Roleplay | - Games - Roleplaying Games - Adult - Arts & Entertainment |
| Translation | - Reference - Language Resources |
| General Q&A / Knowledge | - Reference - General Reference - News |
| Productivity/Writing | - Computers & Electronics - Software - Business & Productivity Software - Business & Industrial - Business Services - Writing & Editing Services |
| Education | - Jobs & Education - Education |
| Literature/Creative Writing | - Books & Literature - narrative leaves under - Arts & Entertainment |
Model
首先是开源模型与闭源模型的对比,结果如下图所示
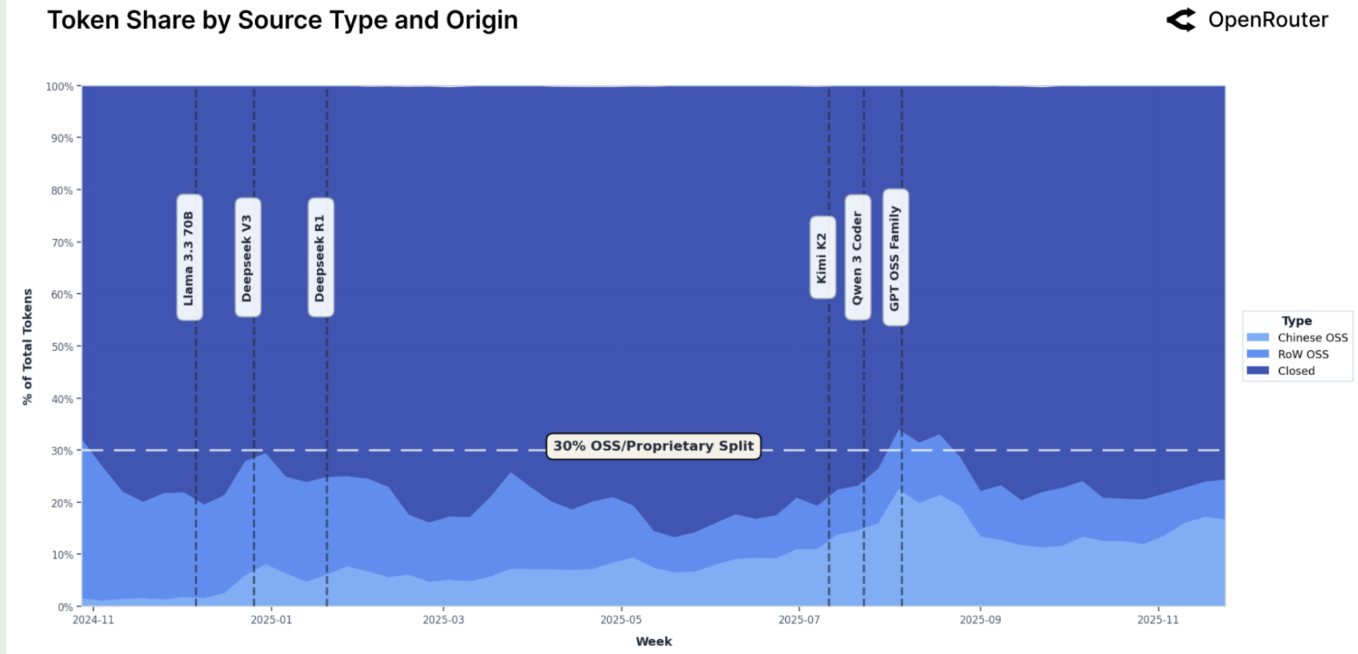
结果显示,开源模型的 token 占比在 $30\%$ 左右,并且中文开源模型 token 占比在持续上升。作者分析认为,闭源模型有着更好的表现以及稳定性,而开源模型的透明程度,成本控制以及可定制化更好。
在闭源模型中,作者对比了不同模型在不同任务上的使用情况,得出了模型偏好如下表所示
| Provider | preference | description |
|---|---|---|
| Anthropic | - Programming - Technology | 擅长推理,代码,复杂任务,领域专家 |
| - Translation - Science - Technology - General Knowledge | 各个任务都没有短板,通用信息引擎 | |
| xAI | programming | 专注编程,程序员专用 |
| OpenAI | - Science - Programming - Technology | 介于 Anthropic 和 Google 之间,更人性化 |
| DeepSeek | - roleplay | 日常对话,面向消费端 |
| Qwen | - programming | 专注编程,适用范围比 Anthropic 广 |
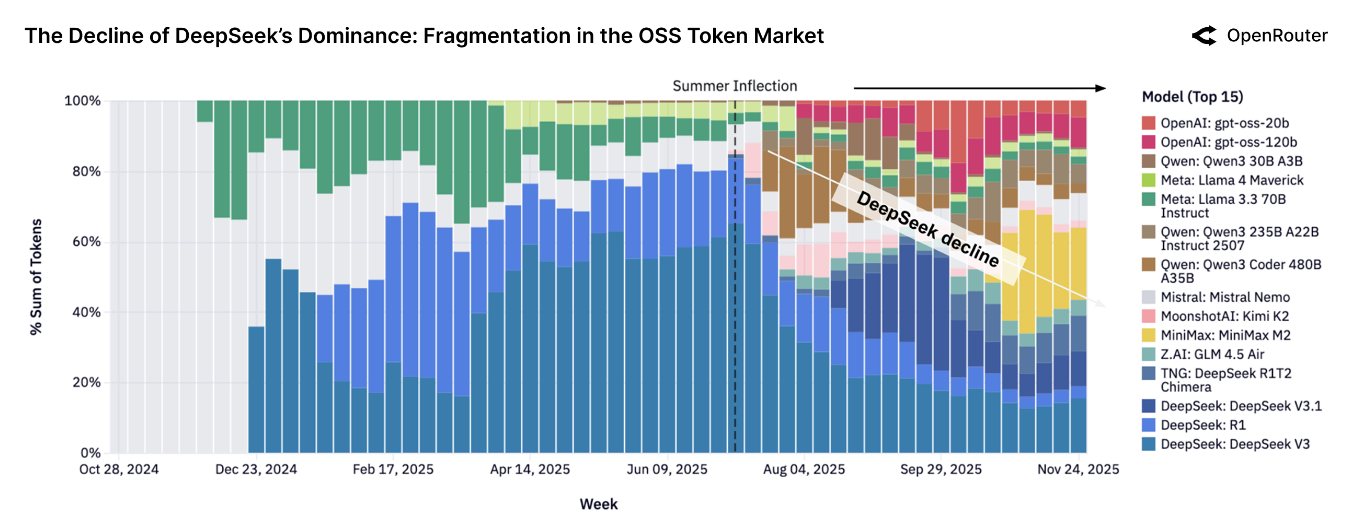
在开源模型中,DeepSeek 占了 $42.51\%$,模型 token 使用情况对比如下表所示
| Provider | # Tokens (T) | ratio (%) |
|---|---|---|
| DeepSeek | 14.37 | 42.51 |
| Qwen | 5.59 | 16.54 |
| Meta LLaMA | 3.96 | 11.72 |
| Mistral AI | 2.92 | 8.64 |
| OpenAI | 1.65 | 4.88 |
| Minimax | 1.26 | 3.73 |
| Z-AI | 1.18 | 3.49 |
| TNGTech | 1.13 | 3.34 |
| MoonshotAI | 0.92 | 2.72 |
| 0.82 | 2.43 |
但是到 25 年底,因为竞争太强,已经不存在单一模型占比超过 $25\%$, 下面是开源模型 token 使用随时间变化情况
接下来,作者将模型分为 Large (> 70B), Medium (> 15B, < 70B) 以及 Small (< 15B) 三个区间,分析了各自的使用情况。结果发现,整体趋势为,Small 区间的模型数量占比正在减少,如下图所示
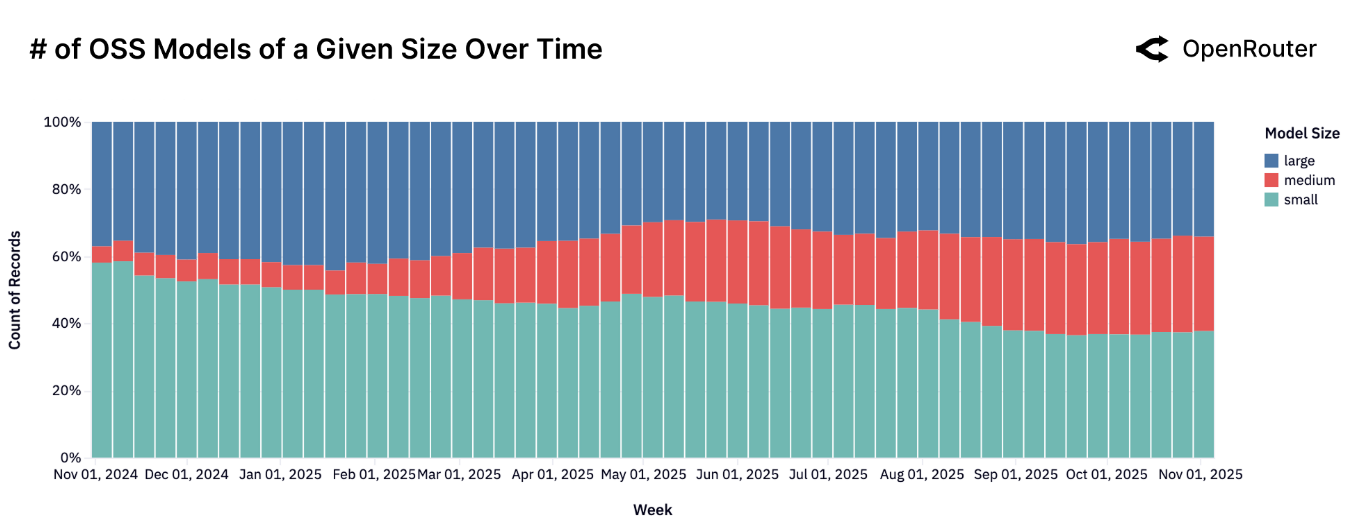
token 使用这方面,由于小模型本地部署较多,因此报告结果存在一定偏差性。
作者还对比了不同模型的价格与 token 使用情况,作者根据中位数 $0.73\$$ per 1M tokens 来将模型分为了四类:
- Premium Workloads (high-cost, high-usage): technology, science 等任务
- Mass-Market Volum Drivers (low-cost, high-usage): programming, roleplay 等任务
- Specialized Experts (high-cost, low-usage): finance, academia, health 等任务
- Niche Utilities (low-cost, low-usage): translation, legal 等任务
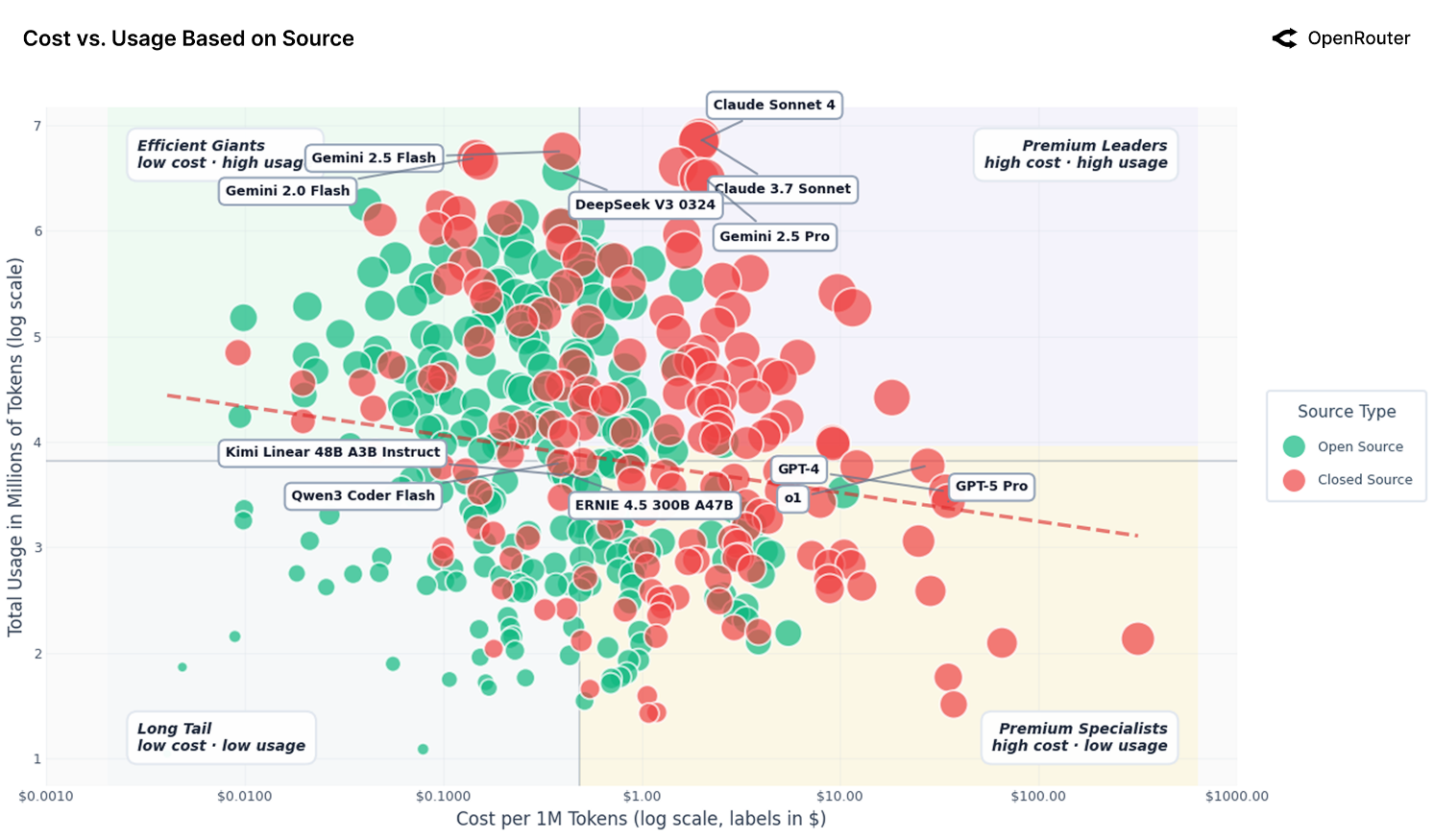
图中红线是拟合出来的结果,红线说明,降低 $10\%$ 的价格只会带来 $0.5\sim0.7\%$ 的 token 使用率增长。上面这幅图说明了闭源模型主要解决高价值的任务,而开原模型则是解决 low-cost 的任务
作者对比不同模型,给出了一些例子,如下表所示
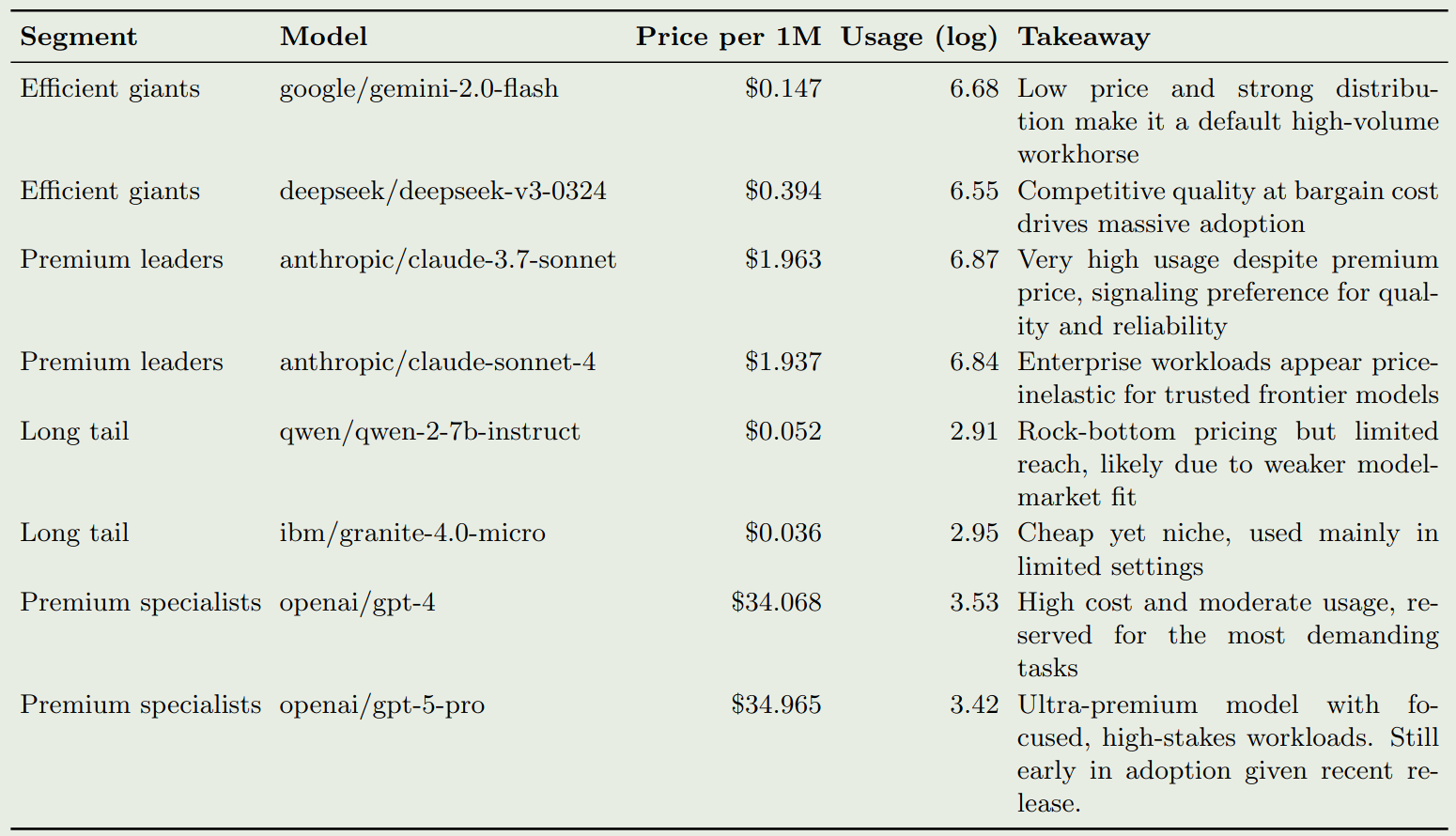
这里的关键结论有几点:
- 宏观需求无弹性,微观行为分化:企业愿意支付成本使用更强模型,而个人用户则对成本比较敏感
- Jevons Paradox: 模型成本下降之后,使用率反而会上升
- 能力优于成本:用户愿意为更强的模型付出更高的成本
- 低价不能成为竞争力:免费开源模型不能落地的原因是仅仅达到“可用”水平,无法部署到实际工作流程中
Task
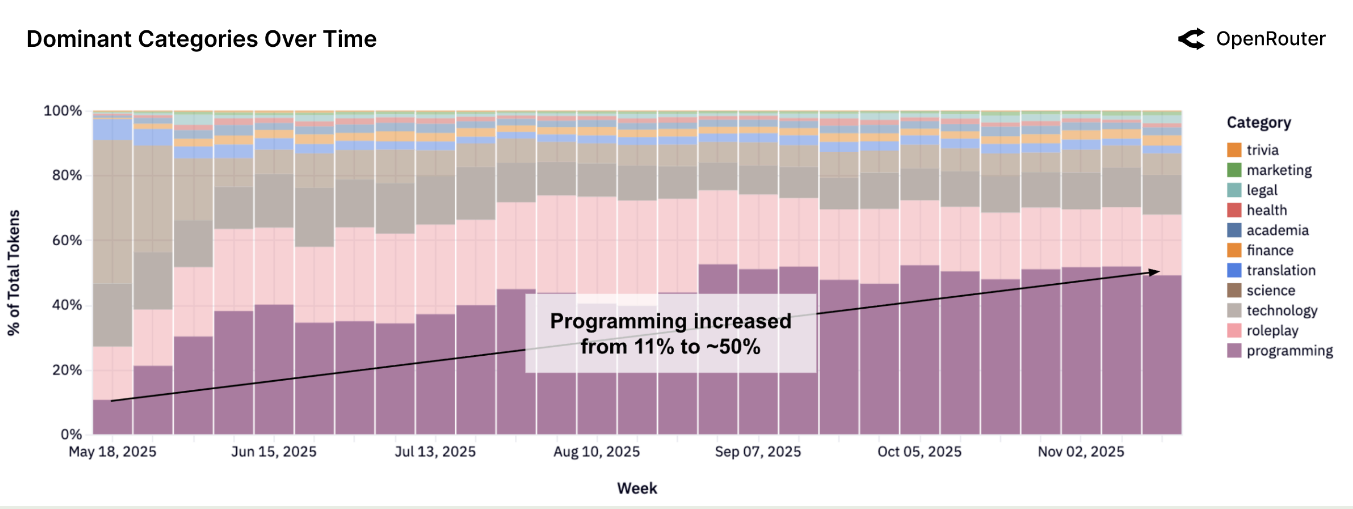
首先是所有模型在不同任务上的 token 使用情况,可以看到,programming 的占比最近已经升到了 $50\%$ 以上
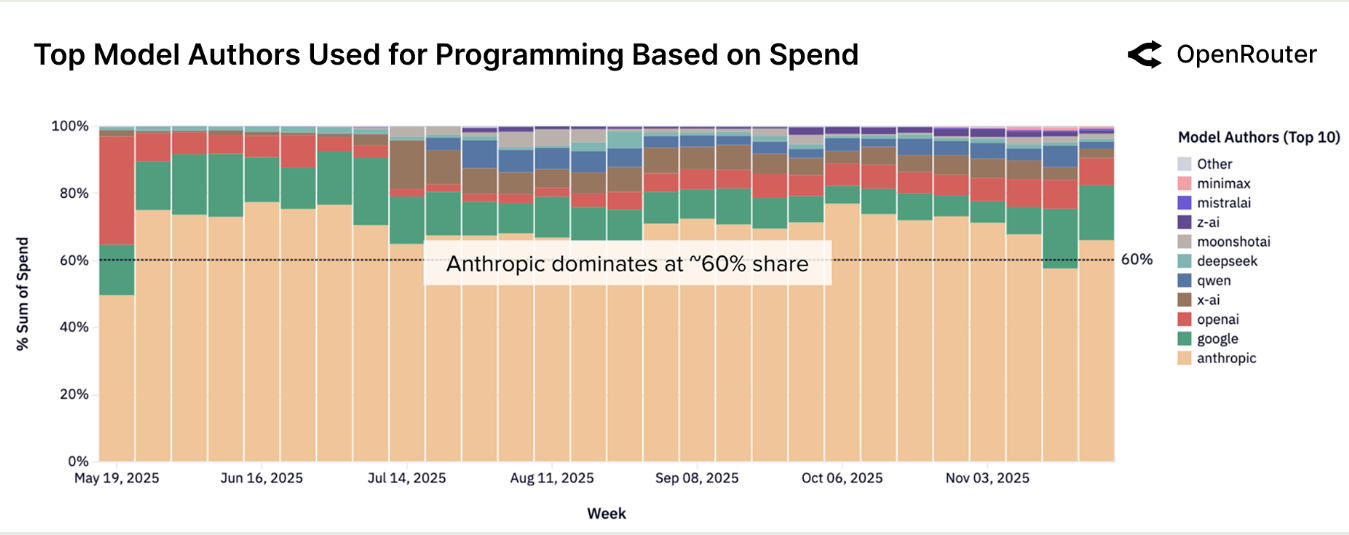
并且对于 programming, Anthropic 拥有 $60\%$ 以上的份额,如下表所示
接下来是开源模型在不同任务上的 token 使用情况。
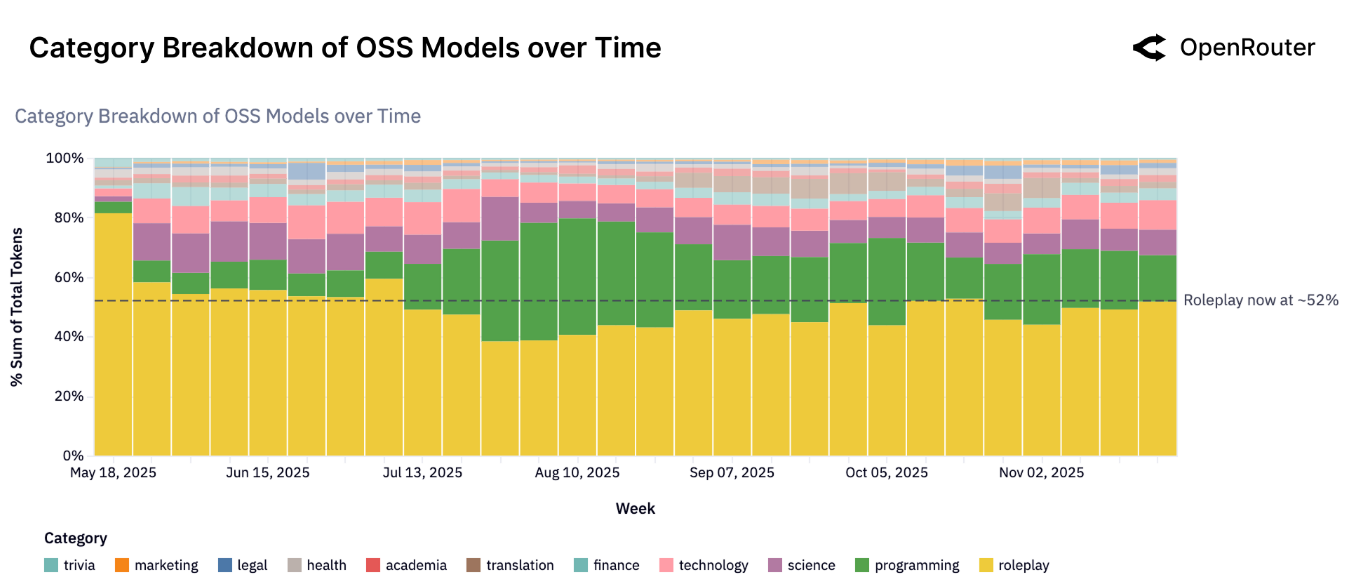
排名前二的任务分别为 roleplay 以及 programming, 前者占比 $50\%$ 以上, 而后者占比在 $15\sim20\%$ 。中文的 OSS model 主要也集中在这两个任务上,但是 roleplay 占比下降到了 $33\%$. 而 programming+technology 的占比为 $39\%$.
对于 programming,目前 $90\%$ 的 token 都基于闭源商业模型,对于开源模型,目前中文开源模型的占比已经超过了其他开源模型
对于 roleplay, 其他开源模型与闭源商业模型的占比分别为 $43\%$, $42\%$ , 且开源模型占比持续上升
开源模型的几个关键用途为:
- roleplay and creative dialogue: 写作,虚拟人物等
- programming: 编程,开发
- translation: 多语种任务
- general QA: 日常问答
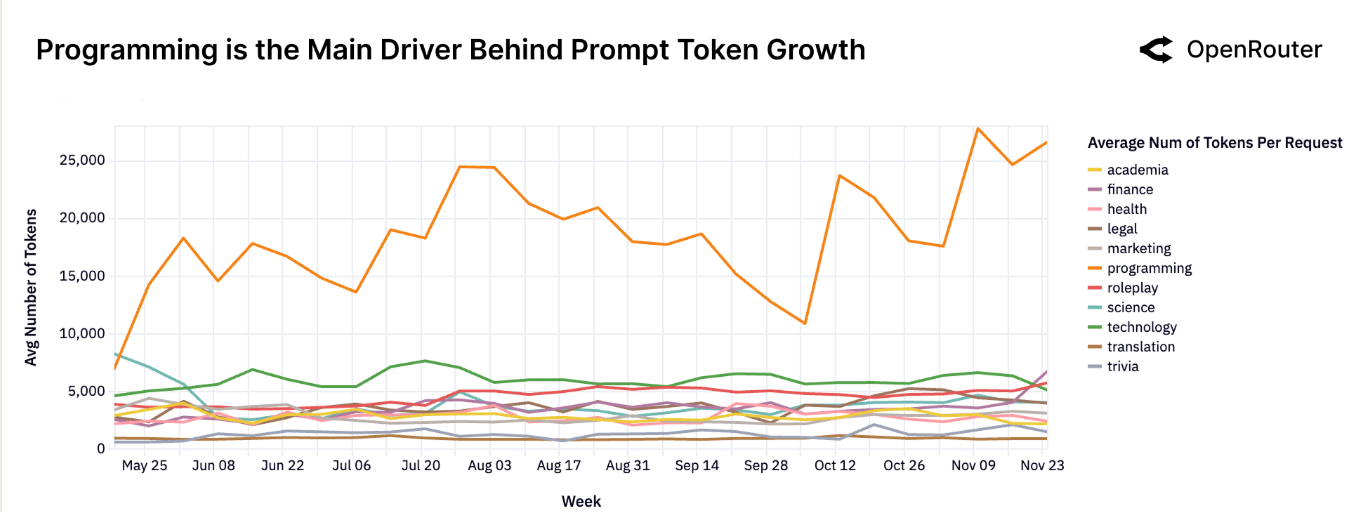
作者还对 token 长度进行了分析,结果显示,目前输入长度区间为 $[1.5K, 6K]$, 输出长度区间为 $[150, 400]$, 这说明不同于早期简单问答,现在用户倾向于输入更丰富的上下文或者材料来让模型解决相应问题。而且,programming 相关的输入长度大约是其他 category 输入的 3 倍以上,下图是不同 category 输入长度随时间的变化情况
作者还展示了不同子任务的占比情况(只列出大于 $10\%$ 的部分)
| category | sub-category | ratio (%) |
|---|---|---|
| Roleplay | Games/Roleplaying Games | 57.9 |
| Books & Literature/Wrters Resources | 16.4 | |
| Adult | 15.0 | |
| Programming | general programming | 66.1 |
| developing tools | 26.4 | |
| Translation | general | 51 |
| Foreign Language Resources | 49 | |
| Science | Machine Learning & AI | 80.4 |
| Technology | personal assistences | 31.3 |
| software | 10.9 | |
| health | general | 25.0 |
| research | 11.6 | |
| finance | currencies | 19.2 |
| stocks | 15.9 | |
| investing | 15.5 | |
| accounting | 13.0 | |
| academia | educational | 42.7 |
| writing | 36.1 | |
| management | 14.8 | |
| legal | Government | 42.1 |
| Legal | 18.9 | |
| trivia | - | 96.2 |
| marketing | marketing | 66.3 |
| sales | 16.0 | |
| seo | seo | 100 |
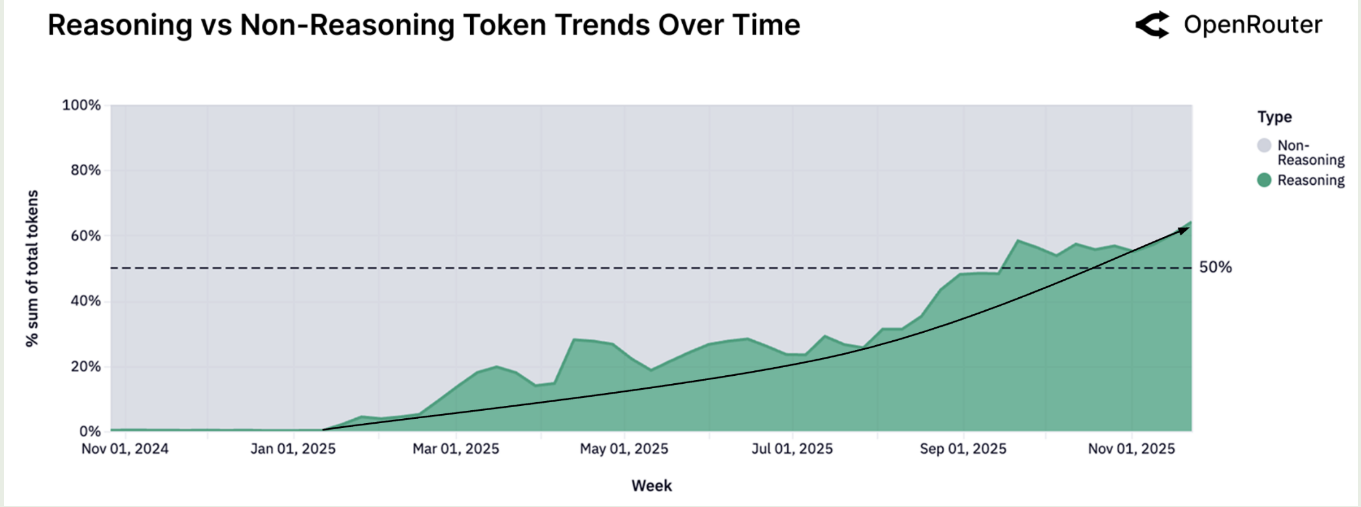
接下来是模型在 agentic inference 场景下的 token 使用情况,从下图可以看出,Reasoning token 占比已经超过了 $60\%$. 这代表了用户对于使用工具解决复杂能力的需求
这 agentic inference 场景下, 使用最多的模型有 Grok Code Fast1, Gemini 2.5 Pro/flash 等,下图是不同模型的占比情况
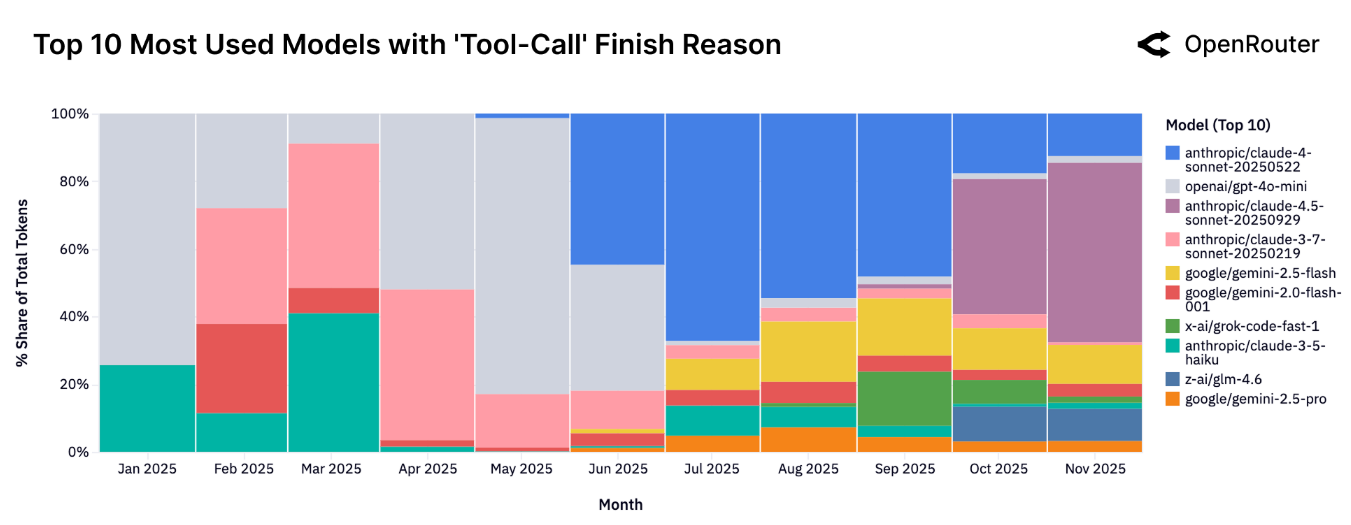
可以看到,Claude 系列占了大部分份额
User
用户这方面,中国和北美的使用占了近 $80\%$, 其中中文用户最近占 $31\%$
语言上,token 的语言占比情况如下表所示
| Language | Token Share (%) |
|---|---|
| English | 82.87 |
| Chinese (Simplified) | 4.95 |
| Russian | 2.47 |
| Spanish | 1.43 |
| Thai | 1.03 |
| Other (combined) | 7.25 |
作者还分了用户留存行为,发现一小部分用户的留存率非常高,作者将这个现象称之为水晶鞋效应 (Glass Slipper effect). 作者分析原因有以下几点:
- 市场存在未被满足的需求:尽管 AI 模型层出不穷,但是始终有些任务连续多代模型都无法解决,也就是 " 水晶鞋“”
- 新模型发布是一个“试穿水晶鞋的过程”:每一代模型都会被用于测试是否能解决这些未解决需求
- “灰姑娘时刻”:一旦某一个模型解决这个未解决的需求,这个模型就会吸引相当一部分用户从维持比较高的留存率
作者举例说明,Gemini 2.5 Pro 和 Claude 4 Sonnet 在 5 个月以后用户留存率还有 $40\%$, 而 Gemini 2.0 Flash 和 LLaMA 4 Maverick 的用户留存率非常差。作者因此得出三个关键结论:
- 首次解决是持久竞争的核心优势:也就是先发制人
- 用户留存率是能力拐点的信号:因为模型实现了从不可能到可能得跨越,才能保留一批早期用户
- “水晶鞋时刻”的窗口很窄:一旦抓不住机会,很可能就会丢掉一大批用户群体