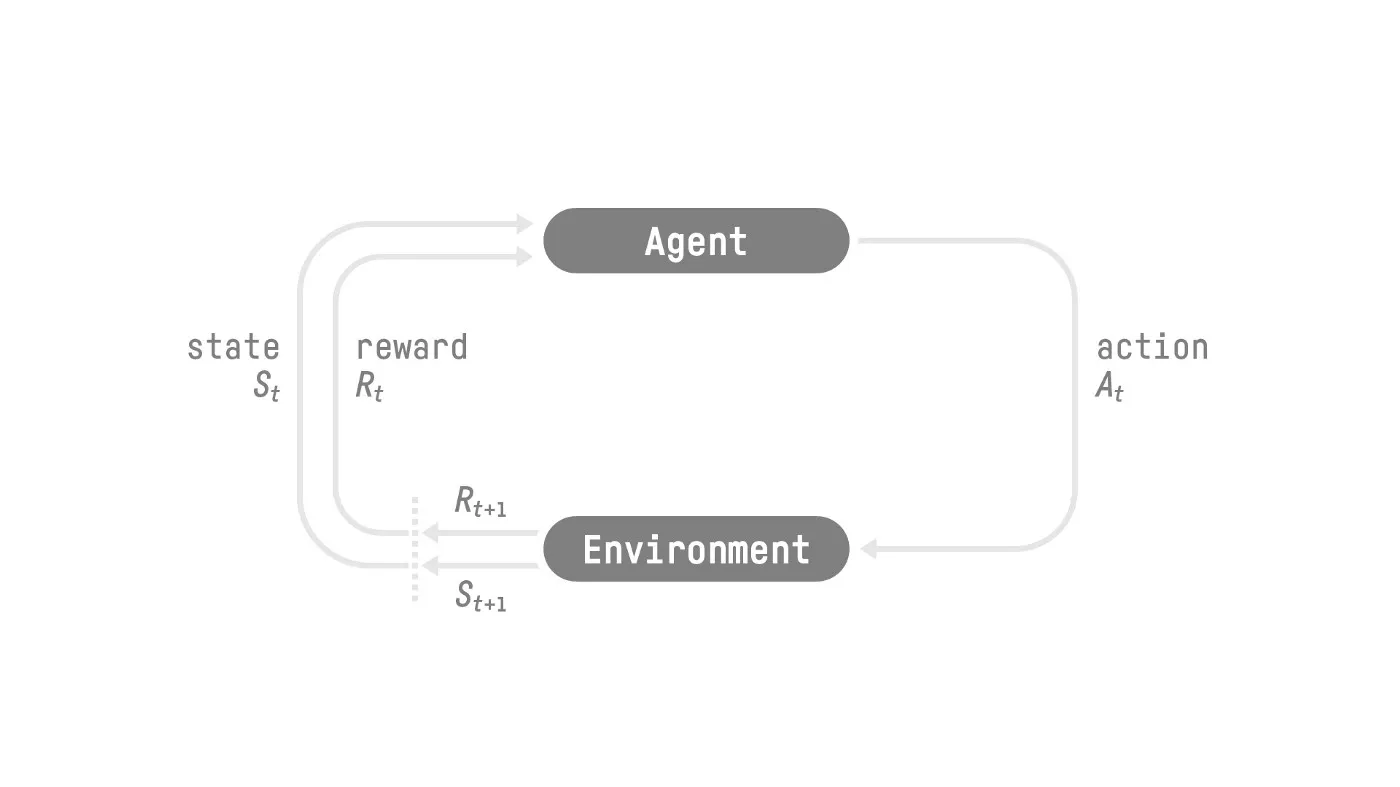
RL 的基本思想是让 agent 通过与环境交互,学习到最优策略。
强化学习是一个通过构建可以与环境进行交互的 agent 来解决控制和决策任务的学习框架,交互的方式为 agent 执行 action, 然后环境给予反馈。
RL 的执行过程如下所示
RL 的数学建模依赖于 Markov Decision Process, 下面我们先介绍相关概念。
MDP 是描述强化学习的数学模型,形式化为:
状态 (State) : s t ∈ S s_t \in \mathcal{S} s t ∈ S S \mathcal{S} S 动作 (Action) : a t ∈ A a_t \in \mathcal{A} a t ∈ A A \mathcal{A} A 奖励 (Reward) : r t ∈ R r_t \in \mathbb{R} r t ∈ R a t a_t a t 终止时间 (Terminal Time) : T T T s T = ⟨ term ⟩ s_T = \langle\text{term}\rangle s T = ⟨ term ⟩ 初始状态分布 (Initial State) : s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 状态转移概率 (Transition Probability) : ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t, s_{t+1}) \sim p(\cdot, \cdot \mid s_t, a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) 马尔可夫性 (Markov Property) : p ( s t + 1 ∣ s t , a t , … ) = p ( s t + 1 ∣ s t , a t ) , p ( r t ∣ s t , a t , … ) = p ( r t ∣ s t , a t ) p(s_{t+1} \mid s_t, a_t, \ldots) = p(s_{t+1} \mid s_t, a_t),\ p(r_t \mid s_t, a_t, \ldots) = p(r_t \mid s_t, a_t) p ( s t + 1 ∣ s t , a t , … ) = p ( s t + 1 ∣ s t , a t ) , p ( r t ∣ s t , a t , … ) = p ( r t ∣ s t , a t )
为了简化,我们采用以下约定:
当 r t r_t r t ( s t , a t ) (s_t,a_t) ( s t , a t ) r t = r ( s t , a t ) r_t = r(s_t, a_t) r t = r ( s t , a t )
假设状态转移函数是平稳的 (stationary), 即 p t ( r , s ′ ∣ s , a ) = p ( r , s ′ ∣ s , a ) p_t(r,s'\mid s,a) = p(r,s'\mid s,a) p t ( r , s ′ ∣ s , a ) = p ( r , s ′ ∣ s , a )
a t a_t a t π \pi π a t = π ( s t ) a_t = \pi(s_t) a t = π ( s t ) a t ∼ π ( ⋅ ∣ s t ) a_t \sim \pi(\cdot \mid s_t) a t ∼ π ( ⋅ ∣ s t ) 通常我们使用神经网络表示策略,即 π = π θ \pi = \pi_\theta π = π θ θ \theta θ
Trajectory (rollout) 定义为 agent 与环境完整的一次交互过程:
τ = ( s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , … , s T − 1 , a T − 1 , r T − 1 , s T ) \tau = (s_0, a_0, r_0, s_1, a_1, r_1, \ldots, s_{T-1}, a_{T-1}, r_{T-1}, s_T) τ = ( s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , … , s T − 1 , a T − 1 , r T − 1 , s T )
轨迹的概率分布为:
p ( τ ∣ s 0 , π , p ) = p 0 ( s 0 ) ∏ t = 0 T − 1 π ( a t ∣ s t ) p ( r t , s t + 1 ∣ s t , a t ) p(\tau \mid s_0, \pi, p) = p_0(s_0) \prod_{t=0}^{T-1} \pi(a_t \mid s_t) \, p(r_t, s_{t+1} \mid s_t, a_t) p ( τ ∣ s 0 , π , p ) = p 0 ( s 0 ) t = 0 ∏ T − 1 π ( a t ∣ s t ) p ( r t , s t + 1 ∣ s t , a t )
轨迹的概率分布由初始状态分布、策略以及环境模型共同决定,记为 τ ∼ ( p 0 , π , p ) \tau \sim (p_0, \pi, p) τ ∼ ( p 0 , π , p )
本教程仅考虑 finite horizon MDP, 即 T < ∞ T < \infty T < ∞
Expected (discounted) return 定义为:
R ( τ ) = ∑ t = 0 T − 1 γ t r t R(\tau) = \sum_{t=0}^{T-1} \gamma^t r_t R ( τ ) = t = 0 ∑ T − 1 γ t r t 其中 γ ∈ ( 0 , 1 ] \gamma \in (0, 1] γ ∈ ( 0 , 1 ] discount factor , 用于将未来的奖励折现到当前时刻。
我们还会使用另一个符号 G 0 G_0 G 0
G 0 = ∑ t = 0 T − 1 γ t r t G_0 = \sum_{t=0}^{T-1} \gamma^t r_t G 0 = t = 0 ∑ T − 1 γ t r t G 0 G_0 G 0
G 0 = r 0 + γ G 1 G_0 = r_0 + \gamma G_1 G 0 = r 0 + γ G 1
Reward Hypothesis : 所有的目标都可以被描述为最大化 expected return.
RL 的最终目标为最大化 expected return, 形式化为:
max π E τ ∼ ( p 0 , π , p ) π R ( τ ) = max π E s 0 ∼ p 0 π [ ∑ t = 0 T − 1 γ t r t ] \max_{\pi} \quad \mathbb{E}_{\tau \sim (p_0, \pi, p)}^\pi \, R(\tau) = \max_{\pi} \quad \mathbb{E}_{s_0 \sim p_0}^\pi \left[ \sum_{t=0}^{T-1} \gamma^t r_t \right] π max E τ ∼ ( p 0 , π , p ) π R ( τ ) = π max E s 0 ∼ p 0 π [ t = 0 ∑ T − 1 γ t r t ] 这里期望 E π \mathbb{E}^\pi E π a t ∼ π ( ⋅ ∣ s t ) a_t \sim \pi(\cdot \mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t, s_{t+1}) \sim p(\cdot, \cdot \mid s_t, a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t )
LLM 的建模方式:
y i ∼ L L M ( ⋅ ∣ y < i , x ) y_i \sim \mathrm{LLM}(\cdot \mid y_{<i}, x) y i ∼ LLM ( ⋅ ∣ y < i , x ) 其中 x x x y < i y_{<i} y < i y i y_i y i
RL 和 LLM 的对应关系如下:
注意到我们并没有对 environment 和 reward 进行建模,可以这样理解:
LLM 中的 environment 仅仅是对 token 进行简单拼接:s t + 1 = c o n c a t ( y i , s t ) s_{t+1} = \mathrm{concat}(y_i, s_t) s t + 1 = concat ( y i , s t )
Reward 由 verifier, reward model (PRM, ORM) 或者 human feedback 给定.
action = token index y i y_i y i ⇒ \Rightarrow ⇒
state = context ( y < i , x ) (y_{<i}, x) ( y < i , x ) ⇒ \Rightarrow ⇒
LLM 中,action space (∣ V ∣ |V| ∣ V ∣ ∣ V ∣ i |V|^i ∣ V ∣ i
state and observation
State 包含了当前进行决策所需要的所有信息(环境信息,历史信息,agent 自身信息),此时 MDP 的 Markov 性质成立。如果 agent 获取的只是部分信息 (observation), 此时 MDP 特化为 Partially Observable Markov Decision Process (POMDP).
对于 LLM 来说,我们可以获取历史状态的所有信息,因此 RL for LLM 可视为一个 MDP 问题。
action space
Action space A \mathcal{A} A
episodic and continuing
根据任务的终止时间 T T T T < ∞ T < \infty T < ∞ T = ∞ T = \infty T = ∞
为了方便分析,我们将 episodic MDP 转化为等价的不会停止的 MDP:
MDP never stops, 即 T = ∞ T = \infty T = ∞
s t ∈ S ∪ { ⟨ term ⟩ } s_t \in \mathcal{S} \cup \{\langle\text{term}\rangle\} s t ∈ S ∪ {⟨ term ⟩} ⟨ term ⟩ \langle\text{term}\rangle ⟨ term ⟩ 当 s t = ⟨ term ⟩ s_t = \langle\text{term}\rangle s t = ⟨ term ⟩ r t = 0 r_t = 0 r t = 0 s t + 1 = ⟨ term ⟩ s_{t+1} = \langle\text{term}\rangle s t + 1 = ⟨ term ⟩
π ( ⋅ ∣ ⟨ term ⟩ ) \pi(\cdot \mid \langle\text{term}\rangle) π ( ⋅ ∣ ⟨ term ⟩)
RL 的基础是 MDP, 其核心假设是 Markov property, 即未来的状态和奖励只与当前状态和动作有关,与历史无关。
RL 通过 Reward Hypothesis, 将目标转化为最大化 expected return.
从 RL 角度看,LLM 本身是一个 policy, 其初始状态为 prompt, 动作空间为 vocabulary 中的 token index, 奖励由多方面给定,environment 仅对 token 进行简单拼接。
虽然 action space 和 state space 是离散的,但是其数量级非常大,因此我们通常使用函数逼近来近似 value function 和 Q-function.
在强化学习中,我们关心的不是某一步立即得到的 reward,而是 agent 从当前状态出发,在未来持续决策后能够获得的 expected return.
但是,expected return 依赖于整条未来轨迹:后续会到达什么状态、采取什么动作、获得什么奖励,都是随机的。直接分析 expected return 往往比较困难。
核心思想 :将长期回报写成”当前一步的收益 + 下一状态的未来价值”,把一个全局问题转化为递推问题。
long-term return = immediate reward + discounted future return \text{long-term return} = \text{immediate reward} + \text{discounted future return} long-term return = immediate reward + discounted future return Definition: Value Function 我们定义 value function 如下:
V π ( s ) = E π [ G 0 ∣ s 0 = s ] V^{\pi}(s) = \mathbb{E}^{\pi}[G_0 \mid s_0 = s] V π ( s ) = E π [ G 0 ∣ s 0 = s ] value function 的具体含义为:agent 从当前状态 s s s π \pi π .
Definition: Q Function Q-function (state-action value function) 定义如下:
Q π ( s , a ) = E π [ G 0 ∣ s 0 = s , a 0 = a ] Q^{\pi}(s, a) = \mathbb{E}^{\pi}[G_0 \mid s_0 = s, a_0 = a] Q π ( s , a ) = E π [ G 0 ∣ s 0 = s , a 0 = a ] 其具体含义为:agent 从当前状态 s s s a a a π \pi π .
💡
为了方便,我们令 V π ( ⟨ term ⟩ ) = 0 V^{\pi}(\langle\text{term}\rangle) = 0 V π (⟨ term ⟩) = 0 Q π ( ⟨ term ⟩ , a ) = 0 , ∀ a ∈ A Q^{\pi}(\langle\text{term}\rangle, a) = 0, \forall a \in \mathcal{A} Q π (⟨ term ⟩ , a ) = 0 , ∀ a ∈ A
由全概率公式,我们有:
V π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ Q π ( s , a ) ] V^{\pi}(s) = \mathbb{E}_{a \sim \pi(\cdot \mid s)}[Q^{\pi}(s, a)] V π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ Q π ( s , a )] 即 value function 是 Q-function 的期望。
证明 :
V π ( s ) = E π [ G 0 ∣ s 0 = s ] = ∑ a ∈ A E π [ G 0 ∣ s 0 = s , a 0 = a ] π ( a ∣ s ) = ∑ a ∈ A Q π ( s , a ) π ( a ∣ s ) = E a ∼ π ( ⋅ ∣ s ) [ Q π ( s , a ) ] \begin{aligned}
V^{\pi}(s) &= \mathbb{E}^{\pi}[G_0 \mid s_0 = s] \\
&= \sum_{a \in \mathcal{A}} \mathbb{E}^{\pi}[G_0 \mid s_0 = s, a_0 = a] \, \pi(a \mid s) \\
&= \sum_{a \in \mathcal{A}} Q^{\pi}(s, a) \, \pi(a \mid s) = \mathbb{E}_{a \sim \pi(\cdot \mid s)}[Q^{\pi}(s, a)]
\end{aligned} V π ( s ) = E π [ G 0 ∣ s 0 = s ] = a ∈ A ∑ E π [ G 0 ∣ s 0 = s , a 0 = a ] π ( a ∣ s ) = a ∈ A ∑ Q π ( s , a ) π ( a ∣ s ) = E a ∼ π ( ⋅ ∣ s ) [ Q π ( s , a )] Value function 和 Q-function 存在如下递推关系:
V π ( s ) = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V π ( s ′ ) ∣ s ] Q π ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) , a ′ ∼ π ( ⋅ ∣ s ′ ) [ r + γ Q π ( s ′ , a ′ ) ∣ s , a ] \boxed{
\begin{aligned}
V^{\pi}(s) &= \mathbb{E}_{a \sim \pi(\cdot \mid s), \, (r, s') \sim p(\cdot, \cdot \mid s, a)}[r + \gamma V^{\pi}(s') \mid s] \\
Q^{\pi}(s, a) &= \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a), \, a' \sim \pi(\cdot \mid s')}[r + \gamma Q^{\pi}(s', a') \mid s, a]
\end{aligned}
} V π ( s ) Q π ( s , a ) = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V π ( s ′ ) ∣ s ] = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) , a ′ ∼ π ( ⋅ ∣ s ′ ) [ r + γ Q π ( s ′ , a ′ ) ∣ s , a ] 证明 (以 value function 为例,利用 Markov property 和重期望定理):
V π ( s ) = E π [ G 0 ∣ s 0 = s ] = E π [ r 0 + γ G 1 ∣ s 0 = s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ E π [ r 0 + γ G 1 ∣ s 0 , a 0 , r 0 , s 1 ] ∣ s 0 = s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r 0 + γ E π [ G 1 ∣ s 1 ] ∣ s 0 = s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] \begin{aligned}
V^{\pi}(s) &= \mathbb{E}^{\pi}[G_0 \mid s_0 = s] \\
&= \mathbb{E}^{\pi}[r_0 + \gamma G_1 \mid s_0 = s] \\
&= \mathbb{E}_{a \sim \pi(\cdot \mid s), \, (r, s') \sim p(\cdot, \cdot \mid s, a)}\left[\mathbb{E}^{\pi}[r_0 + \gamma G_1 \mid s_0, a_0, r_0, s_1] \mid s_0 = s\right] \\
&= \mathbb{E}_{a \sim \pi(\cdot \mid s), \, (r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r_0 + \gamma \mathbb{E}^{\pi}[G_1 \mid s_1] \mid s_0 = s\right] \\
&= \mathbb{E}_{a \sim \pi(\cdot \mid s), \, (r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r_0 + \gamma V^{\pi}(s_1) \mid s_0 = s\right]
\end{aligned} V π ( s ) = E π [ G 0 ∣ s 0 = s ] = E π [ r 0 + γ G 1 ∣ s 0 = s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ E π [ r 0 + γ G 1 ∣ s 0 , a 0 , r 0 , s 1 ] ∣ s 0 = s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r 0 + γ E π [ G 1 ∣ s 1 ] ∣ s 0 = s ] = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r 0 + γ V π ( s 1 ) ∣ s 0 = s ] 这里第四个等式使用了 Markov property,即 G 1 G_1 G 1 s 1 s_1 s 1 s 0 , a 0 , r 0 s_0, a_0, r_0 s 0 , a 0 , r 0
Q-function 的证明类似,略过.
在证明 Bellman equation 的唯一性之前,我们先回顾不动点定理。
Definition: Contraction Mapping
对于函数 f : R n → R n f: \mathbb{R}^n \to \mathbb{R}^n f : R n → R n x ∗ ∈ R n x^* \in \mathbb{R}^n x ∗ ∈ R n f ( x ∗ ) = x ∗ f(x^*) = x^* f ( x ∗ ) = x ∗ x ∗ x^* x ∗ f f f fixed point .
如果存在 γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ ∈ ( 0 , 1 )
∥ f ( x 1 ) − f ( x 2 ) ∥ ≤ γ ∥ x 1 − x 2 ∥ , ∀ x 1 , x 2 ∈ R n \|f(x_1) - f(x_2)\| \leq \gamma \|x_1 - x_2\|, \quad \forall x_1, x_2 \in \mathbb{R}^n ∥ f ( x 1 ) − f ( x 2 ) ∥ ≤ γ ∥ x 1 − x 2 ∥ , ∀ x 1 , x 2 ∈ R n 则我们称 f f f contraction mapping .
对于 contraction mapping, 其满足如下的不动点定理。
Theorem: Fixed Point Theorem Fixed Point Theorem :给定函数 f : R n → R n f: \mathbb{R}^n \to \mathbb{R}^n f : R n → R n f f f
Existence : 存在 fixed point x ∗ x^* x ∗ f ( x ∗ ) = x ∗ f(x^*) = x^* f ( x ∗ ) = x ∗ Uniqueness : fixed point x ∗ x^* x ∗ Algorithm : 对任意 x 0 ∈ R n x_0 \in \mathbb{R}^n x 0 ∈ R n x k + 1 = f ( x k ) x_{k+1} = f(x_k) x k + 1 = f ( x k ) { x k } k = 1 ∞ \{x_k\}_{k=1}^{\infty} { x k } k = 1 ∞ x ∗ x^* x ∗
Theorem: Bellman Equation Theorem (Value Function) 令 π \pi π γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}| < \infty ∣ S ∣ < ∞ ∣ r ∣ ≤ R < ∞ |r| \leq R < \infty ∣ r ∣ ≤ R < ∞ π \pi π V π : S → R V^{\pi}: \mathcal{S} \to \mathbb{R} V π : S → R
V π ( s ) = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V π ( s ′ ) ∣ s ] \boxed{
V^{\pi}(s) = \mathbb{E}_{a \sim \pi(\cdot \mid s), \, (r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^{\pi}(s') \mid s\right]
} V π ( s ) = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V π ( s ′ ) ∣ s ] 反之,如果存在函数 V : S → R V: \mathcal{S} \to \mathbb{R} V : S → R V = V π V = V^{\pi} V = V π
Proof: 由 iterative property 我们知道 value function 满足 Bellman equation,接下来证明唯一性.
假设存在函数 V : S → R V: \mathcal{S} \to \mathbb{R} V : S → R T π \mathcal{T}^{\pi} T π
( T π V ) ( s ) : = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ( s ′ ) ∣ s ] (\mathcal{T}^{\pi} V)(s) := \mathbb{E}_{a \sim \pi(\cdot \mid s), \, (r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V(s') \mid s\right] ( T π V ) ( s ) := E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ( s ′ ) ∣ s ] 我们证明该算子是一个 contraction mapping. 考虑范数 ∥ V ∥ ∞ = max s ∈ S ∣ V ( s ) ∣ \|V\|_{\infty} = \max_{s \in \mathcal{S}} |V(s)| ∥ V ∥ ∞ = max s ∈ S ∣ V ( s ) ∣
∣ ( T π V 1 ) ( s ) − ( T π V 2 ) ( s ) ∣ = ∣ E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ γ V 1 ( s ′ ) − γ V 2 ( s ′ ) ] ∣ ≤ γ E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) ∣ V 1 ( s ′ ) − V 2 ( s ′ ) ∣ ≤ γ max s ′ ′ ∈ S ∣ V 1 ( s ′ ′ ) − V 2 ( s ′ ′ ) ∣ = γ ∥ V 1 − V 2 ∥ ∞ \begin{aligned}
\left|(\mathcal{T}^{\pi} V_1)(s) - (\mathcal{T}^{\pi} V_2)(s)\right| &= \left|\mathbb{E}_{a \sim \pi(\cdot \mid s), \, (r, s') \sim p(\cdot, \cdot \mid s, a)}\left[\gamma V_1(s') - \gamma V_2(s')\right]\right| \\
&\leq \gamma \, \mathbb{E}_{a \sim \pi(\cdot \mid s), \, (r, s') \sim p(\cdot, \cdot \mid s, a)}\left|V_1(s') - V_2(s')\right| \\
&\leq \gamma \max_{s'' \in \mathcal{S}}\left|V_1(s'') - V_2(s'')\right| \\
&= \gamma \left\|V_1 - V_2\right\|_{\infty}
\end{aligned} ∣ ( T π V 1 ) ( s ) − ( T π V 2 ) ( s ) ∣ = E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ γ V 1 ( s ′ ) − γ V 2 ( s ′ ) ] ≤ γ E a ∼ π ( ⋅ ∣ s ) , ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) ∣ V 1 ( s ′ ) − V 2 ( s ′ ) ∣ ≤ γ s ′′ ∈ S max ∣ V 1 ( s ′′ ) − V 2 ( s ′′ ) ∣ = γ ∥ V 1 − V 2 ∥ ∞ 上式对任意 s ∈ S s \in \mathcal{S} s ∈ S
∥ T π V 1 − T π V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ \left\|\mathcal{T}^{\pi} V_1 - \mathcal{T}^{\pi} V_2\right\|_{\infty} \leq \gamma \left\|V_1 - V_2\right\|_{\infty} ∥ T π V 1 − T π V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ 由于 γ < 1 \gamma < 1 γ < 1 T π \mathcal{T}^{\pi} T π
根据不动点定理,已知 V π V^{\pi} V π V = V π V = V^{\pi} V = V π ■ \blacksquare ■
Theorem: Bellman Equation Theorem (Q Function) 令 π \pi π γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}| < \infty ∣ S ∣ < ∞ ∣ A ∣ < ∞ |\mathcal{A}| < \infty ∣ A ∣ < ∞ ∣ r ∣ ≤ R < ∞ |r| \leq R < \infty ∣ r ∣ ≤ R < ∞ π \pi π Q π : S × A → R Q^{\pi}: \mathcal{S} \times \mathcal{A} \to \mathbb{R} Q π : S × A → R
Q π ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) , a ′ ∼ π ( ⋅ ∣ s ′ ) [ r + γ Q π ( s ′ , a ′ ) ∣ s , a ] \boxed{
Q^{\pi}(s, a) = \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a), \, a' \sim \pi(\cdot \mid s')}\left[r + \gamma Q^{\pi}(s', a') \mid s, a\right]
} Q π ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) , a ′ ∼ π ( ⋅ ∣ s ′ ) [ r + γ Q π ( s ′ , a ′ ) ∣ s , a ] 反之,如果存在函数 Q : S × A → R Q: \mathcal{S} \times \mathcal{A} \to \mathbb{R} Q : S × A → R Q = Q π Q = Q^{\pi} Q = Q π
Proof: 证明与 value function 的证明类似,略过.
Definition: Optimal Policy 如果策略 π ∗ \pi^* π ∗
V π ∗ ( s ) ≥ V π ( s ) , ∀ s ∈ S , ∀ π V^{\pi^*}(s) \geq V^{\pi}(s), \quad \forall s \in \mathcal{S}, \, \forall \pi V π ∗ ( s ) ≥ V π ( s ) , ∀ s ∈ S , ∀ π 则称策略 π ∗ \pi^* π ∗ optimal policy .
对应的 V π ∗ V^{\pi^*} V π ∗ Q π ∗ Q^{\pi^*} Q π ∗ optimal value function 和 optimal Q-function , 简记为 V ∗ = V π ∗ V^* = V^{\pi^*} V ∗ = V π ∗ Q ∗ = Q π ∗ Q^* = Q^{\pi^*} Q ∗ = Q π ∗
⚠️
optimal policy 与状态 s s s
Relationship between V ∗ V^* V ∗ Q ∗ Q^* Q ∗ :
V ∗ ( s ) = max a ∈ A Q ∗ ( s , a ) \boxed{V^*(s) = \max_{a \in \mathcal{A}} Q^*(s, a)} V ∗ ( s ) = a ∈ A max Q ∗ ( s , a ) 证明 :
先证左边 ≤ \leq ≤
V ∗ ( s ) = E a ∼ π ∗ ( ⋅ ∣ s ) [ Q ∗ ( s , a ) ] ≤ E a ∼ π ∗ ( ⋅ ∣ s ) [ max a ∈ A Q ∗ ( s , a ) ] = max a ∈ A Q ∗ ( s , a ) V^*(s) = \mathbb{E}_{a \sim \pi^*(\cdot \mid s)}[Q^*(s, a)] \leq \mathbb{E}_{a \sim \pi^*(\cdot \mid s)}[\max_{a \in \mathcal{A}} Q^*(s, a)] = \max_{a \in \mathcal{A}} Q^*(s, a) V ∗ ( s ) = E a ∼ π ∗ ( ⋅ ∣ s ) [ Q ∗ ( s , a )] ≤ E a ∼ π ∗ ( ⋅ ∣ s ) [ a ∈ A max Q ∗ ( s , a )] = a ∈ A max Q ∗ ( s , a ) 再证右边 ≤ \leq ≤ a ∗ ∈ arg max a Q ∗ ( s , a ) a^* \in \arg\max_{a} Q^*(s, a) a ∗ ∈ arg max a Q ∗ ( s , a ) π ′ \pi' π ′ π ′ ( a ∗ ∣ s ) = 1 \pi'(a^* \mid s) = 1 π ′ ( a ∗ ∣ s ) = 1
max a ∈ A Q ∗ ( s , a ∗ ) = Q π ′ ( s , a ∗ ) = V π ′ ( s ) ≤ V ∗ ( s ) \max_{a \in \mathcal{A}} Q^*(s, a^*) = Q^{\pi'}(s, a^*) = V^{\pi'}(s) \leq V^*(s) a ∈ A max Q ∗ ( s , a ∗ ) = Q π ′ ( s , a ∗ ) = V π ′ ( s ) ≤ V ∗ ( s ) 因此两边相等. ■ \blacksquare ■
假设 γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}| < \infty ∣ S ∣ < ∞ ∣ A ∣ < ∞ |\mathcal{A}| < \infty ∣ A ∣ < ∞ ∣ r ∣ ≤ R < ∞ |r| \leq R < \infty ∣ r ∣ ≤ R < ∞ V ∗ : S → R V^*: \mathcal{S} \to \mathbb{R} V ∗ : S → R
V ∗ ( s ) = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] \boxed{
V^*(s) = \max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^*(s') \mid s, a\right]
} V ∗ ( s ) = a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] 反之,如果存在函数 V : S → R V: \mathcal{S} \to \mathbb{R} V : S → R V = V ∗ V = V^* V = V ∗
最后,可以给出一个 optimal deterministic policy:
π ∗ ( s ) = arg max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] = arg max a ∈ A Q ∗ ( s , a ) \pi^*(s) = \arg\max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^*(s') \mid s, a\right] = \arg\max_{a \in \mathcal{A}} Q^*(s, a) π ∗ ( s ) = arg a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] = arg a ∈ A max Q ∗ ( s , a )
证明 (概要):
定义 Bellman optimality operator:
( T ∗ V ) ( s ) : = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ( s ′ ) ∣ s , a ] (\mathcal{T}^* V)(s) := \max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V(s') \mid s, a\right] ( T ∗ V ) ( s ) := a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ( s ′ ) ∣ s , a ] 首先证明 T ∗ \mathcal{T}^* T ∗ V 1 , V 2 V_1, V_2 V 1 , V 2
∣ ( T ∗ V 1 ) ( s ) − ( T ∗ V 2 ) ( s ) ∣ = ∣ max a E [ r + γ V 1 ( s ′ ) ] − max a E [ r + γ V 2 ( s ′ ) ] ∣ ≤ max a ∣ E [ r + γ V 1 ( s ′ ) ] − E [ r + γ V 2 ( s ′ ) ] ∣ = γ max a ∣ E [ V 1 ( s ′ ) − V 2 ( s ′ ) ] ∣ ≤ γ ∥ V 1 − V 2 ∥ ∞ \begin{aligned}
\left|(\mathcal{T}^* V_1)(s) - (\mathcal{T}^* V_2)(s)\right| &= \left|\max_{a} \mathbb{E}[r + \gamma V_1(s')] - \max_{a} \mathbb{E}[r + \gamma V_2(s')]\right| \\
&\leq \max_{a} \left|\mathbb{E}[r + \gamma V_1(s')] - \mathbb{E}[r + \gamma V_2(s')]\right| \\
&= \gamma \max_{a} \left|\mathbb{E}[V_1(s') - V_2(s')]\right| \\
&\leq \gamma \|V_1 - V_2\|_{\infty}
\end{aligned} ∣ ( T ∗ V 1 ) ( s ) − ( T ∗ V 2 ) ( s ) ∣ = a max E [ r + γ V 1 ( s ′ )] − a max E [ r + γ V 2 ( s ′ )] ≤ a max ∣ E [ r + γ V 1 ( s ′ )] − E [ r + γ V 2 ( s ′ )] ∣ = γ a max ∣ E [ V 1 ( s ′ ) − V 2 ( s ′ )] ∣ ≤ γ ∥ V 1 − V 2 ∥ ∞ 这里第一个不等式使用了 ∣ max s v ( s ) − max s u ( s ) ∣ ≤ max s ∣ u ( s ) − v ( s ) ∣ |\max_s v(s) - \max_s u(s)| \leq \max_s |u(s) - v(s)| ∣ max s v ( s ) − max s u ( s ) ∣ ≤ max s ∣ u ( s ) − v ( s ) ∣
因此 ∥ T ∗ V 1 − T ∗ V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ \|\mathcal{T}^* V_1 - \mathcal{T}^* V_2\|_{\infty} \leq \gamma \|V_1 - V_2\|_{\infty} ∥ T ∗ V 1 − T ∗ V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ T ∗ \mathcal{T}^* T ∗
根据不动点定理,T ∗ \mathcal{T}^* T ∗ V ∗ V^* V ∗
π ∗ ( s ) = arg max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] \pi^*(s) = \arg\max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^*(s') \mid s, a\right] π ∗ ( s ) = arg a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V ∗ ( s ′ ) ∣ s , a ] 然后可以验证 V ∗ = V π ∗ V^* = V^{\pi^*} V ∗ = V π ∗ π ∗ \pi^* π ∗ π \pi π V π ≤ V ∗ = V π ∗ V^{\pi} \leq V^* = V^{\pi^*} V π ≤ V ∗ = V π ∗ ■ \blacksquare ■
辅助 Lemma (省略证明):
令 π \pi π T π \mathcal{T}^{\pi} T π T ∗ \mathcal{T}^* T ∗
对任意 V : S → R V: \mathcal{S} \to \mathbb{R} V : S → R T π V ( s ) ≤ T ∗ V ( s ) , ∀ s ∈ S \mathcal{T}^{\pi} V(s) \leq \mathcal{T}^* V(s), \, \forall s \in \mathcal{S} T π V ( s ) ≤ T ∗ V ( s ) , ∀ s ∈ S
对任意 U , V : S → R U, V: \mathcal{S} \to \mathbb{R} U , V : S → R U ≤ V U \leq V U ≤ V T ∗ U ( s ) ≤ T ∗ V ( s ) , ∀ s ∈ S \mathcal{T}^* U(s) \leq \mathcal{T}^* V(s), \, \forall s \in \mathcal{S} T ∗ U ( s ) ≤ T ∗ V ( s ) , ∀ s ∈ S
假设 γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}| < \infty ∣ S ∣ < ∞ ∣ A ∣ < ∞ |\mathcal{A}| < \infty ∣ A ∣ < ∞ ∣ r ∣ ≤ R < ∞ |r| \leq R < \infty ∣ r ∣ ≤ R < ∞ Q ∗ : S × A → R Q^*: \mathcal{S} \times \mathcal{A} \to \mathbb{R} Q ∗ : S × A → R
Q ∗ ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ max a ′ ∈ A Q ∗ ( s ′ , a ′ ) ∣ s , a ] \boxed{
Q^*(s, a) = \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma \max_{a' \in \mathcal{A}} Q^*(s', a') \mid s, a\right]
} Q ∗ ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ a ′ ∈ A max Q ∗ ( s ′ , a ′ ) ∣ s , a ] 反之,如果存在函数 Q : S × A → R Q: \mathcal{S} \times \mathcal{A} \to \mathbb{R} Q : S × A → R Q = Q ∗ Q = Q^* Q = Q ∗
证明与 value function 类似,略过.
根据 BOE 定理的证明,T ∗ \mathcal{T}^* T ∗
V , T ∗ V , ( T ∗ ) 2 V , ⋯ V, \mathcal{T}^* V, (\mathcal{T}^*)^2 V, \cdots V , T ∗ V , ( T ∗ ) 2 V , ⋯ 由不动点定理,该序列收敛到 V ∗ V^* V ∗
V k + 1 = T ∗ V k V k + 1 ( s ) = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V k ( s ′ ) ∣ s , a ] π k + 1 ( s ) = arg max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V k ( s ′ ) ∣ s , a ] \begin{aligned}
V^{k+1} &= \mathcal{T}^* V^k \\
V^{k+1}(s) &= \max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^k(s') \mid s, a\right] \\
\pi^{k+1}(s) &= \arg\max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^k(s') \mid s, a\right]
\end{aligned} V k + 1 V k + 1 ( s ) π k + 1 ( s ) = T ∗ V k = a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V k ( s ′ ) ∣ s , a ] = arg a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V k ( s ′ ) ∣ s , a ] 类似地,还有 Q-value iteration:
Q k + 1 = T ∗ Q k Q k + 1 ( s , a ) = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ max a ′ ∈ A Q k ( s ′ , a ′ ) ∣ s , a ] π k + 1 ( s ) = arg max a ∈ A Q k ( s , a ) \begin{aligned}
Q^{k+1} &= \mathcal{T}^* Q^k \\
Q^{k+1}(s, a) &= \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma \max_{a' \in \mathcal{A}} Q^k(s', a') \mid s, a\right] \\
\pi^{k+1}(s) &= \arg\max_{a \in \mathcal{A}} Q^k(s, a)
\end{aligned} Q k + 1 Q k + 1 ( s , a ) π k + 1 ( s ) = T ∗ Q k = E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ a ′ ∈ A max Q k ( s ′ , a ′ ) ∣ s , a ] = arg a ∈ A max Q k ( s , a )
我们介绍了 value function 和 Q-function 的定义以及它们之间的联系,这是强化学习的核心概念.
我们介绍了 Bellman equation 和 Bellman optimality equation,BOE 定理是后续各种算法的核心.
我们基于 BOE 定理给出了 value iteration algorithm, 这是强化学习的基本算法,后续会对其进行改进.
在强化学习中,我们通常希望回答一个基本问题:
给定一个策略 π \pi π
更具体地说,我们希望知道 agent 在不同状态下遵循该策略时,未来能够获得多大的长期回报.
这个问题本质上对应于求解策略 π \pi π V π V^{\pi} V π V π V^{\pi} V π
在本节中,我们将要介绍如何高效求解 value function V π V^{\pi} V π 核心思想 :利用 Bellman equation、采样和函数逼近,高效地估计或拟合给定策略对应的 value function V π V^{\pi} V π
首先,由 V π V^{\pi} V π
V π ( s 0 ) = E π [ R ( τ ) ∣ s 0 ] V^{\pi}(s_0) = \mathbb{E}^{\pi}\left[R(\tau) \mid s_0\right] V π ( s 0 ) = E π [ R ( τ ) ∣ s 0 ] 这是一个随机变量,由我们可以利用 Monte Carlo (MC) 方法来得到一个 Unbiased Estimator ,即从 s 0 s_0 s 0 N N N
{ τ ( i ) = ( s 0 ( i ) , a 0 ( i ) , r 0 ( i ) , … , a T ( i ) − 1 ( i ) , r T ( i ) − 1 ( i ) , s T ( i ) ( i ) ) } , i = 1 , … , N \{\tau^{(i)} = (s_0^{(i)}, a_0^{(i)}, r_0^{(i)}, \dots, a_{T^{(i)}-1}^{(i)}, r_{T^{(i)}-1}^{(i)}, s_{T^{(i)}}^{(i)})\}, \quad i = 1, \dots, N { τ ( i ) = ( s 0 ( i ) , a 0 ( i ) , r 0 ( i ) , … , a T ( i ) − 1 ( i ) , r T ( i ) − 1 ( i ) , s T ( i ) ( i ) )} , i = 1 , … , N 然后使用样本平均来近似期望:
V π ( s 0 ) = E π [ R ( τ ) ∣ s 0 ] ≈ 1 N ∑ i = 1 N R ( τ ( i ) ) V^{\pi}(s_0) = \mathbb{E}^{\pi}[R(\tau) \mid s_0] \approx \frac{1}{N} \sum_{i=1}^{N} R(\tau^{(i)}) V π ( s 0 ) = E π [ R ( τ ) ∣ s 0 ] ≈ N 1 i = 1 ∑ N R ( τ ( i ) ) 如果 S \mathcal{S} S s ∈ S s \in \mathcal{S} s ∈ S V π V^{\pi} V π S \mathcal{S} S
💡
优点 : 简单、直观、无需环境模型缺点 : 必须等轨迹结束后才能得到一次完整的估计
当状态空间 S \mathcal{S} S V π V^{\pi} V π V ϕ V_{\phi} V ϕ V π V^{\pi} V π ϕ \phi ϕ
min ϕ L ( ϕ ) = E s 0 ∼ p 0 [ 1 2 ( V ϕ ( s 0 ) − V π ( s 0 ) ) 2 ] \min_{\phi} \mathcal{L}(\phi) = \mathbb{E}_{s_0 \sim p_0}\left[\frac{1}{2}\left(V_{\phi}(s_0) - V^{\pi}(s_0)\right)^2\right] ϕ min L ( ϕ ) = E s 0 ∼ p 0 [ 2 1 ( V ϕ ( s 0 ) − V π ( s 0 ) ) 2 ] 对目标函数求导:
∇ ϕ L ( ϕ ) = E s 0 ∼ p 0 [ ( V ϕ ( s 0 ) − V π ( s 0 ) ) ∇ ϕ V ϕ ( s 0 ) ] = E s 0 ∼ p 0 [ ( V ϕ ( s 0 ) − E π [ G 0 ∣ s 0 ] ) ∇ ϕ V ϕ ( s ) ] = E s 0 ∼ p 0 [ E π [ ( V ϕ ( s 0 ) − G 0 ) ∇ ϕ V ϕ ( s 0 ) ∣ s 0 ] ] = E s 0 ∼ p 0 π [ ( V ϕ ( s 0 ) − G 0 ) ∇ ϕ V ϕ ( s 0 ) ∣ s 0 ] \begin{aligned}
\nabla_{\phi} \mathcal{L}(\phi) &= \mathbb{E}_{s_0 \sim p_0}\left[\left(V_{\phi}(s_0) - V^{\pi}(s_0)\right)\nabla_{\phi} V_{\phi}(s_0)\right] \\
&= \mathbb{E}_{s_0 \sim p_0}\left[\left(V_{\phi}(s_0) - \mathbb{E}^{\pi}[G_0 \mid s_0]\right)\nabla_{\phi} V_{\phi}(s)\right] \\
&= \mathbb{E}_{s_0 \sim p_0}\left[\mathbb{E}^{\pi}\left[\left(V_{\phi}(s_0) - G_0\right)\nabla_{\phi} V_{\phi}(s_0) \mid s_0\right]\right] \\
&= \mathbb{E}_{s_0 \sim p_0}^{\pi}\left[\left(V_{\phi}(s_0) - G_0\right)\nabla_{\phi} V_{\phi}(s_0) \mid s_0\right]
\end{aligned} ∇ ϕ L ( ϕ ) = E s 0 ∼ p 0 [ ( V ϕ ( s 0 ) − V π ( s 0 ) ) ∇ ϕ V ϕ ( s 0 ) ] = E s 0 ∼ p 0 [ ( V ϕ ( s 0 ) − E π [ G 0 ∣ s 0 ] ) ∇ ϕ V ϕ ( s ) ] = E s 0 ∼ p 0 [ E π [ ( V ϕ ( s 0 ) − G 0 ) ∇ ϕ V ϕ ( s 0 ) ∣ s 0 ] ] = E s 0 ∼ p 0 π [ ( V ϕ ( s 0 ) − G 0 ) ∇ ϕ V ϕ ( s 0 ) ∣ s 0 ] 现在可以使用 MC 方法来估计梯度:
∇ ϕ L ( ϕ ) ≈ g : = 1 N ∑ i = 1 N ( V ϕ ( s ( i ) ) − R ( τ ( i ) ) ) ∇ ϕ V ϕ ( s ( i ) ) \nabla_{\phi} \mathcal{L}(\phi) \approx g := \frac{1}{N}\sum_{i=1}^{N} \left(V_{\phi}(s^{(i)}) - R(\tau^{(i)})\right)\nabla_{\phi} V_{\phi}(s^{(i)}) ∇ ϕ L ( ϕ ) ≈ g := N 1 i = 1 ∑ N ( V ϕ ( s ( i ) ) − R ( τ ( i ) ) ) ∇ ϕ V ϕ ( s ( i ) ) 结合 MC 和 SGD 的算法如下:
Algorithm: Value function approximation with MC while not converged:
s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 t = 0 t = 0 t = 0 while s t ≠ ⟨ term ⟩ s_t \neq \langle\text{term}\rangle s t = ⟨ term ⟩
a t ∼ π ( ⋅ ∣ s t ) a_t \sim \pi(\cdot \mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t, s_{t+1}) \sim p(\cdot, \cdot \mid s_t, a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) t ← t + 1 t \gets t + 1 t ← t + 1
Set T = t T = t T = t
g ← ( V ϕ ( s 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ V ϕ ( s 0 ) g \gets \left(V_{\phi}(s_0) - \sum_{t=0}^{T-1} \gamma^t r_t\right)\nabla_{\phi} V_{\phi}(s_0) g ← ( V ϕ ( s 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ V ϕ ( s 0 ) Update ϕ \phi ϕ g g g
MC 的优势是可以得到一个无偏估计,但是其劣势在于我们必须完整采样完一条轨迹才能得到这个估计,对于 long-horizon task, MC 方法效率很低。
为了解决这个问题,我们可以使用 Temporal difference (TD) learning 方法。
Temporal difference (TD) learning 通过相邻两步的转换关系来近似 value function.
注意到:
V π ( s t ) = E π [ r t + γ V π ( s t + 1 ) ∣ s t ] V^{\pi}(s_t) = \mathbb{E}^{\pi}[r_t + \gamma V^{\pi}(s_{t+1}) \mid s_t] V π ( s t ) = E π [ r t + γ V π ( s t + 1 ) ∣ s t ] Definition: TD Learning TD learning 是一个通过新的信息和新的预测来更新旧的预测 的学习范式.
对于 value function, 我们定义 TD target 为:
V ‾ t = r t + γ V π ( s t + 1 ) \overline{V}_t = r_t + \gamma V^{\pi}(s_{t+1}) V t = r t + γ V π ( s t + 1 ) 定义 TD error 为
δ t = V π ( s t ) − ( r t + γ V π ( s t + 1 ) ) \delta_t = V^{\pi}(s_t) - \left(r_t + \gamma V^{\pi}(s_{t+1})\right) δ t = V π ( s t ) − ( r t + γ V π ( s t + 1 ) )
当 S \mathcal{S} S
min ϕ L ( ϕ ) = E s 0 ∼ p 0 [ 1 2 ( V ϕ ( s 0 ) − r 0 − γ V π ( s 1 ) ) 2 ] \min_{\phi} \mathcal{L}(\phi) = \mathbb{E}_{s_0 \sim p_0}\left[\frac{1}{2}\left(V_{\phi}(s_0) - r_0 - \gamma V^{\pi}(s_1)\right)^2\right] ϕ min L ( ϕ ) = E s 0 ∼ p 0 [ 2 1 ( V ϕ ( s 0 ) − r 0 − γ V π ( s 1 ) ) 2 ] TODO: explain why we use TD error as objective
对应的梯度为:
∇ ϕ L ( ϕ ) = E s 0 ∼ p 0 π [ ( V ϕ ( s 0 ) − r 0 − γ V π ( s 1 ) ) ∇ ϕ V ϕ ( s 0 ) ∣ s 0 ] \nabla_{\phi} \mathcal{L}(\phi) = \mathbb{E}_{s_0 \sim p_0}^{\pi}\left[\left(V_{\phi}(s_0) - r_0 - \gamma \boxed{V^{\pi}(s_1)}\right)\nabla_{\phi} V_{\phi}(s_0) \mid s_0\right] ∇ ϕ L ( ϕ ) = E s 0 ∼ p 0 π [ ( V ϕ ( s 0 ) − r 0 − γ V π ( s 1 ) ) ∇ ϕ V ϕ ( s 0 ) ∣ s 0 ] 这里使用了 V π ( s 1 ) V^{\pi}(s_1) V π ( s 1 ) V ϕ V_{\phi} V ϕ
∇ ϕ L ( ϕ ) ≈ E s 0 ∼ p 0 π [ ( V ϕ ( s 0 ) − r 0 − γ V ϕ ( s 1 ) ) ∇ ϕ V ϕ ( s 0 ) ∣ s 0 ] \nabla_{\phi} \mathcal{L}(\phi) \approx \mathbb{E}_{s_0 \sim p_0}^{\pi}\left[\left(V_{\phi}(s_0) - r_0 - \gamma V_{\phi}(s_1)\right)\nabla_{\phi} V_{\phi}(s_0) \mid s_0\right] ∇ ϕ L ( ϕ ) ≈ E s 0 ∼ p 0 π [ ( V ϕ ( s 0 ) − r 0 − γ V ϕ ( s 1 ) ) ∇ ϕ V ϕ ( s 0 ) ∣ s 0 ] 这样,我们就得到了一个结合 TD 和 SGD 的 naive 算法:
Algorithm: Value function approximation with TD (not correct) while not converged:
s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 a 0 ∼ π ( ⋅ ∣ s 0 ) a_0 \sim \pi(\cdot \mid s_0) a 0 ∼ π ( ⋅ ∣ s 0 ) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) (r_0, s_1) \sim p(\cdot, \cdot \mid s_0, a_0) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) computer TD target
y = { r 0 + γ V ϕ ( s 1 ) , if s 1 ≠ ⟨ term ⟩ r 0 , otherwise y = \begin{cases}
r_0 + \gamma V_{\phi}(s_1), & \text{if } s_1 \neq \langle\text{term}\rangle \\
r_0, & \text{otherwise}
\end{cases} y = { r 0 + γ V ϕ ( s 1 ) , r 0 , if s 1 = ⟨ term ⟩ otherwise
g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) g = (V_{\phi}(s_0) - y) \nabla_{\phi} V_{\phi}(s_0) g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) Update ϕ \phi ϕ g g g
我们来看一下上述算法对应的 PyTorch 实现:
pred = V_phi(s0) target = r + gamma * V_phi(s1) td_error = pred - target loss = 0.5 * td_error ** 2 loss.backward() 可以看到,我们实际上求的梯度是:
∇ ϕ [ 1 2 ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ ) ) ) 2 ] = ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ ) ) ) ( ∇ ϕ V ϕ ( s ) − ∇ ϕ V ϕ ( s ′ ) ) ≠ g \begin{aligned}
&\nabla_{\phi}\left[\frac{1}{2}\left(V_{\phi}(s) - (r + \gamma V_{\phi}(s'))\right)^2\right] \\
&= (V_{\phi}(s) - (r + \gamma V_{\phi}(s')))(\nabla_{\phi} V_{\phi}(s) - \nabla_{\phi} V_{\phi}(s'))\\
&\neq g
\end{aligned} ∇ ϕ [ 2 1 ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ )) ) 2 ] = ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ ))) ( ∇ ϕ V ϕ ( s ) − ∇ ϕ V ϕ ( s ′ )) = g 这显然与 g g g
为了解决这个问题,我们可以使用 stop-gradient 技巧来避免 V ϕ ( s ′ ) V_{\phi}(s') V ϕ ( s ′ )
L ( ϕ ) = 1 2 ( V ϕ ( s ) − ( r + γ s g [ V ϕ ( s ′ ) ] ) ) 2 \mathcal{L}(\phi)=\frac{1}{2}\left(V_{\phi}(s) - (r + \gamma \, \mathrm{sg}[V_{\phi}(s')])\right)^2 L ( ϕ ) = 2 1 ( V ϕ ( s ) − ( r + γ sg [ V ϕ ( s ′ )]) ) 2 其中 s g [ ⋅ ] \mathrm{sg}[\cdot] sg [ ⋅ ]
s g [ x ] = { x forward pass 0 backward pass \mathrm{sg}[x] = \begin{cases}
x & \text{forward pass} \\
0 & \text{backward pass}
\end{cases} sg [ x ] = { x 0 forward pass backward pass 对应的梯度就是:
∇ ϕ [ 1 2 ( V ϕ ( s ) − ( r + γ s g [ V ϕ ( s ′ ) ] ) ) 2 ] = ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ ) ) ) ∇ ϕ V ϕ ( s ) = g \nabla_{\phi}\left[\frac{1}{2}\left(V_{\phi}(s) - (r + \gamma \, \mathrm{sg}[V_{\phi}(s')])\right)^2\right] = (V_{\phi}(s) - (r + \gamma V_{\phi}(s')))\nabla_{\phi} V_{\phi}(s) = g ∇ ϕ [ 2 1 ( V ϕ ( s ) − ( r + γ sg [ V ϕ ( s ′ )]) ) 2 ] = ( V ϕ ( s ) − ( r + γ V ϕ ( s ′ ))) ∇ ϕ V ϕ ( s ) = g 对应的 Python 代码为:
pred = V_phi(s0) target = r + gamma * V_phi(s1) td_error = pred - target.detach() # stop-gradient operator loss = 0.5 * td_error ** 2 loss.backward() 最终,正确的 TD 算法如下:
Algorithm: Value function approximation with TD while not converged:
s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 a 0 ∼ π ( ⋅ ∣ s 0 ) a_0 \sim \pi(\cdot \mid s_0) a 0 ∼ π ( ⋅ ∣ s 0 ) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) (r_0, s_1) \sim p(\cdot, \cdot \mid s_0, a_0) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) computer TD target
y = { r 0 + γ s g [ V ϕ ( s 1 ) ] , if s 1 ≠ ⟨ term ⟩ r 0 , otherwise y = \begin{cases}
r_0 + \gamma \, \mathrm{sg}[V_{\phi}(s_1)], & \text{if } s_1 \neq \langle\text{term}\rangle \\
r_0, & \text{otherwise}
\end{cases} y = { r 0 + γ sg [ V ϕ ( s 1 )] , r 0 , if s 1 = ⟨ term ⟩ otherwise
g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) g = (V_{\phi}(s_0) - y) \nabla_{\phi} V_{\phi}(s_0) g = ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) Update ϕ \phi ϕ g g g
⚠️
上述做法其实是 semi-gradient methods , 这类方法在参数更新时,只计算部分梯度。虽然这种方法牺牲了严格的梯度下降性质,但是其能够保证更好的表现.
我们可以进一步推广 TD 到多步场景,注意到:
V π ( s 0 ) = E π [ r 0 + γ V π ( s 1 ) ∣ s 0 ] = E π [ r 0 + γ E π [ r 1 + γ V π ( s 2 ) ∣ s 1 ] ∣ s 0 ] = E π [ E π [ r 0 + γ r 1 + γ 2 V π ( s 2 ) ∣ s 1 ] ∣ s 0 ] \begin{aligned}
V^{\pi}(s_0) &= \mathbb{E}^{\pi}[r_0 + \gamma V^{\pi}(s_1) \mid s_0] \\
&= \mathbb{E}^{\pi}[r_0 + \gamma \mathbb{E}^{\pi}[r_1 + \gamma V^{\pi}(s_2) \mid s_1] \mid s_0] \\
&= \mathbb{E}^{\pi}[\mathbb{E}^{\pi}[r_0 + \gamma r_1 + \gamma^2 V^{\pi}(s_2) \mid s_1] \mid s_0]
\end{aligned} V π ( s 0 ) = E π [ r 0 + γ V π ( s 1 ) ∣ s 0 ] = E π [ r 0 + γ E π [ r 1 + γ V π ( s 2 ) ∣ s 1 ] ∣ s 0 ] = E π [ E π [ r 0 + γ r 1 + γ 2 V π ( s 2 ) ∣ s 1 ] ∣ s 0 ] 由 Law of total expectation :
E π [ E π [ X ∣ s 1 ] ∣ s 0 = s ] = E π [ X ∣ s 0 ] \mathbb{E}^{\pi}[\mathbb{E}^{\pi}[X \mid s_1] \mid s_0 = s] = \mathbb{E}^{\pi}[X \mid s_0] E π [ E π [ X ∣ s 1 ] ∣ s 0 = s ] = E π [ X ∣ s 0 ] 因此:
V π ( s 0 ) = E π [ r 0 + γ r 1 + γ 2 V π ( s 2 ) ∣ s 0 ] V^{\pi}(s_0) = \mathbb{E}^{\pi}[r_0 + \gamma r_1 + \gamma^2 V^{\pi}(s_2) \mid s_0] V π ( s 0 ) = E π [ r 0 + γ r 1 + γ 2 V π ( s 2 ) ∣ s 0 ] 重复这个过程 k 次,我们就可以得到 k 步展开:
V π ( s 0 ) = E π [ ∑ i = 0 k − 1 γ i r i + γ k V π ( s k ) ∣ s 0 ] V^{\pi}(s_0) = \mathbb{E}^{\pi}\left[\sum_{i=0}^{k-1} \gamma^i r_i + \gamma^k V^{\pi}(s_k) \mid s_0\right] V π ( s 0 ) = E π [ i = 0 ∑ k − 1 γ i r i + γ k V π ( s k ) ∣ s 0 ] 基于 k-step transition ,我们可以构建对应的目标函数并应用 stop-gradient:
Algorithm: Value function approximation with k-step TD while not converged:
s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 t = 0 t = 0 t = 0 for t = 0 , … , k − 1 t = 0, \ldots, k-1 t = 0 , … , k − 1
a t ∼ π ( ⋅ ∣ s t ) a_t \sim \pi(\cdot \mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t, s_{t+1}) \sim p(\cdot, \cdot \mid s_t, a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t )
compute k-step TD target
y = { ∑ t = 0 k − 1 γ t r t + γ k s g [ V ϕ ( s k ) ] , if s k ≠ ⟨ term ⟩ ∑ t = 0 k − 1 γ t r t , otherwise y = \begin{cases}
\sum_{t=0}^{k-1} \gamma^t r_t + \gamma^k \, \mathrm{sg}[V_{\phi}(s_k)], & \text{if } s_k \neq \langle\text{term}\rangle \\
\sum_{t=0}^{k-1} \gamma^t r_t, & \text{otherwise}
\end{cases} y = { ∑ t = 0 k − 1 γ t r t + γ k sg [ V ϕ ( s k )] , ∑ t = 0 k − 1 γ t r t , if s k = ⟨ term ⟩ otherwise
g ← ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) g \gets (V_{\phi}(s_0) - y) \nabla_{\phi} V_{\phi}(s_0) g ← ( V ϕ ( s 0 ) − y ) ∇ ϕ V ϕ ( s 0 ) Update ϕ \phi ϕ g g g
一般来说,k = 5 k = 5 k = 5
TD 本质上是 bootstrap: 当需要使用 V π V^{\pi} V π V ϕ V_{\phi} V ϕ V ϕ V_{\phi} V ϕ V π V^{\pi} V π
对于 Q-function, 我们也可以设计类似的算法.
对于 MC, 有:
Q π ( s 0 , a 0 ) = E π [ ∑ t = 0 T − 1 γ t r t ∣ s 0 , a 0 ] ≈ 1 N ∑ i = 1 N ∑ t = 0 T ( i ) − 1 γ t r t ( i ) Q^{\pi}(s_0, a_0) = \mathbb{E}^{\pi}\left[\sum_{t=0}^{T-1} \gamma^t r_t \mid s_0, a_0 \right] \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=0}^{T^{(i)}-1} \gamma^t r_t^{(i)} Q π ( s 0 , a 0 ) = E π [ t = 0 ∑ T − 1 γ t r t ∣ s 0 , a 0 ] ≈ N 1 i = 1 ∑ N t = 0 ∑ T ( i ) − 1 γ t r t ( i ) 当使用模型来近似时,目标函数为:
min ϕ L ( ϕ ) = E s 0 ∼ p 0 , a 0 ∼ π ( ⋅ ∣ s 0 ) [ 1 2 ( Q ϕ ( s 0 , a 0 ) − Q π ( s 0 , a 0 ) ) 2 ] \min_{\phi} \mathcal{L}(\phi) = \mathbb{E}_{s_0 \sim p_0, \, a_0 \sim \pi(\cdot \mid s_0)}\left[\frac{1}{2}\left(Q_{\phi}(s_0, a_0) - Q^{\pi}(s_0, a_0)\right)^2\right] ϕ min L ( ϕ ) = E s 0 ∼ p 0 , a 0 ∼ π ( ⋅ ∣ s 0 ) [ 2 1 ( Q ϕ ( s 0 , a 0 ) − Q π ( s 0 , a 0 ) ) 2 ] 对应的梯度:
∇ ϕ L ( ϕ ) = E s 0 ∼ p 0 , a 0 ∼ π ( ⋅ ∣ s 0 ) π [ ( Q ϕ ( s 0 , a 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ Q ϕ ( s 0 , a 0 ) ] \nabla_{\phi} \mathcal{L}(\phi) = \mathbb{E}_{s_0 \sim p_0, \, a_0 \sim \pi(\cdot \mid s_0)}^{\pi}\left[\left(Q_{\phi}(s_0, a_0) - \sum_{t=0}^{T-1} \gamma^t r_t\right)\nabla_{\phi} Q_{\phi}(s_0, a_0)\right] ∇ ϕ L ( ϕ ) = E s 0 ∼ p 0 , a 0 ∼ π ( ⋅ ∣ s 0 ) π [ ( Q ϕ ( s 0 , a 0 ) − t = 0 ∑ T − 1 γ t r t ) ∇ ϕ Q ϕ ( s 0 , a 0 ) ] 对应的算法如下
Algorithm: Q-function approximation with MC while not converged:
s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 a 0 ∼ π ( ⋅ ∣ s 0 ) a_0 \sim \pi(\cdot \mid s_0) a 0 ∼ π ( ⋅ ∣ s 0 ) t = 0 t = 0 t = 0 while s t ≠ ⟨ term ⟩ s_t \neq \langle\text{term}\rangle s t = ⟨ term ⟩
a t ∼ π ( ⋅ ∣ s t ) a_t \sim \pi(\cdot \mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t, s_{t+1}) \sim p(\cdot, \cdot \mid s_t, a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) t ← t + 1 t \gets t + 1 t ← t + 1
Set T = t T = t T = t
g = ( Q ϕ ( s 0 , a 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ Q ϕ ( s 0 , a 0 ) g = \left(Q_{\phi}(s_0, a_0) - \sum_{t=0}^{T-1} \gamma^t r_t\right) \nabla_{\phi} Q_{\phi}(s_0, a_0) g = ( Q ϕ ( s 0 , a 0 ) − ∑ t = 0 T − 1 γ t r t ) ∇ ϕ Q ϕ ( s 0 , a 0 ) Update ϕ \phi ϕ g g g
对于TD learning, 与 value function 的算法类似,我们也由对应版本的算法:
Algorithm: Q-function approximation with TD while not converged:
s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 a 0 ∼ π ( ⋅ ∣ s 0 ) a_0 \sim \pi(\cdot \mid s_0) a 0 ∼ π ( ⋅ ∣ s 0 ) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) (r_0, s_1) \sim p(\cdot, \cdot \mid s_0, a_0) ( r 0 , s 1 ) ∼ p ( ⋅ , ⋅ ∣ s 0 , a 0 ) a 1 ∼ π ( ⋅ ∣ s 1 ) a_1 \sim \pi(\cdot \mid s_1) a 1 ∼ π ( ⋅ ∣ s 1 )
y = { r 0 + γ s g [ Q ϕ ( s 1 , a 1 ) ] , if s 1 ≠ ⟨ term ⟩ r 0 , otherwise y = \begin{cases}
r_0 + \gamma \, \mathrm{sg}[Q_{\phi}(s_1, a_1)], & \text{if } s_1 \neq \langle\text{term}\rangle \\
r_0, & \text{otherwise}
\end{cases} y = { r 0 + γ sg [ Q ϕ ( s 1 , a 1 )] , r 0 , if s 1 = ⟨ term ⟩ otherwise
g = ( Q ϕ ( s 0 , a 0 ) − y ) ∇ ϕ Q ϕ ( s 0 , a 0 ) g = \left(Q_{\phi}(s_0, a_0) - y\right) \nabla_{\phi} Q_{\phi}(s_0, a_0) g = ( Q ϕ ( s 0 , a 0 ) − y ) ∇ ϕ Q ϕ ( s 0 , a 0 ) Update ϕ \phi ϕ g g g
Algorithm: Q-function approximation with k-step TD while not converged:
s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 t = 0 t = 0 t = 0 for t = 0 , … , k − 1 t = 0, \ldots, k-1 t = 0 , … , k − 1
a t ∼ π ( ⋅ ∣ s t ) a_t \sim \pi(\cdot \mid s_t) a t ∼ π ( ⋅ ∣ s t ) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t, s_{t+1}) \sim p(\cdot, \cdot \mid s_t, a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t )
y = ∑ t = 0 k − 1 γ t r t + γ k s g [ Q ϕ ( s k , a k ) ] y = \sum_{t=0}^{k-1} \gamma^t r_t + \gamma^k \, \mathrm{sg}[Q_{\phi}(s_k, a_k)] y = ∑ t = 0 k − 1 γ t r t + γ k sg [ Q ϕ ( s k , a k )] g = ( Q ϕ ( s 0 , a 0 ) − y ) ∇ ϕ Q ϕ ( s 0 , a 0 ) g = (Q_{\phi}(s_0, a_0) - y) \nabla_{\phi} Q_{\phi}(s_0, a_0) g = ( Q ϕ ( s 0 , a 0 ) − y ) ∇ ϕ Q ϕ ( s 0 , a 0 ) Update ϕ \phi ϕ g g g
介绍完 policy evaluation 之后,我们可以设计 policy iteration 算法,其基本思想是交替进行 policy evaluation 和 policy improvement:
Compute V π k and Q π k (Policy evaluation) π k + 1 ( s ) = arg max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V π k ( s ′ ) ∣ s , a ] (Policy improvement) \begin{aligned}
&\text{Compute } V^{\pi^k} \text{ and } Q^{\pi^k} &\quad&\text{(Policy evaluation)} \\
&\pi^{k+1}(s) = \arg\max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^{\pi^k}(s') \mid s, a\right] &\quad&\text{(Policy improvement)}
\end{aligned} Compute V π k and Q π k π k + 1 ( s ) = arg a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V π k ( s ′ ) ∣ s , a ] (Policy evaluation) (Policy improvement) 算法的正确性由如下定理保证
Theorem: Theorem : 考虑上述 policy iteration 算法,假设 γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ ∈ ( 0 , 1 ) ∣ S ∣ < ∞ |\mathcal{S}| < \infty ∣ S ∣ < ∞ ∣ A ∣ < ∞ |\mathcal{A}| < \infty ∣ A ∣ < ∞ ∣ r ∣ ≤ R < ∞ |r| \leq R < \infty ∣ r ∣ ≤ R < ∞
V π k + 1 ≥ V π k , k = 1 , 2 , … V^{\pi^{k+1}} \geq V^{\pi^k}, \quad k = 1, 2, \dots V π k + 1 ≥ V π k , k = 1 , 2 , … 并且存在 K ∈ N K \in \mathbb{N} K ∈ N V π K = V ∗ V^{\pi^K} = V^* V π K = V ∗
Proof:
Q-learning
SARSA
DQN
Value-based methods 的核心思想是:给当前策略 π \pi π
在 Bellman Equation 中,我们介绍了 value iteration 的基本思路:通过 Bellman optimality operator 迭代求解 V ∗ V^* V ∗ Q ∗ Q^* Q ∗
Value iteration 的更新公式为:
V k + 1 ( s ) = max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V k ( s ′ ) ∣ s , a ] π k + 1 ( s ) = arg max a ∈ A E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V k ( s ′ ) ∣ s , a ] \begin{aligned}
V^{k+1}(s) &= \max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^k(s') \mid s, a\right] \\
\pi^{k+1}(s) &= \arg\max_{a \in \mathcal{A}} \mathbb{E}_{(r, s') \sim p(\cdot, \cdot \mid s, a)}\left[r + \gamma V^k(s') \mid s, a\right]
\end{aligned} V k + 1 ( s ) π k + 1 ( s ) = a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V k ( s ′ ) ∣ s , a ] = arg a ∈ A max E ( r , s ′ ) ∼ p ( ⋅ , ⋅ ∣ s , a ) [ r + γ V k ( s ′ ) ∣ s , a ] 当状态空间较大或连续时,我们需要使用函数逼近. 用 V ϕ V_{\phi} V ϕ V π V^{\pi} V π
J ( ϕ ) = E s [ 1 2 ( V π ( s ) − V ϕ ( s ) ) 2 ] J(\phi) = \mathbb{E}_{s}\left[\frac{1}{2}\left(V^{\pi}(s) - V_{\phi}(s)\right)^2\right] J ( ϕ ) = E s [ 2 1 ( V π ( s ) − V ϕ ( s ) ) 2 ] 目标函数的梯度为:
∇ ϕ J ( ϕ ) = − E s [ ( V π ( s ) − V ϕ ( s ) ) ∇ ϕ V ϕ ( s ) ] \nabla_{\phi} J(\phi) = -\mathbb{E}_{s}\left[(V^{\pi}(s) - V_{\phi}(s))\nabla_{\phi} V_{\phi}(s)\right] ∇ ϕ J ( ϕ ) = − E s [ ( V π ( s ) − V ϕ ( s )) ∇ ϕ V ϕ ( s ) ] 随机梯度下降的更新形式为:
ϕ k + 1 = ϕ k + α k ( V π ( s ) − V ϕ ( s ) ) ∇ ϕ V ϕ ( s ) \phi_{k+1} = \phi_k + \alpha_k (V^{\pi}(s) - V_{\phi}(s))\nabla_{\phi} V_{\phi}(s) ϕ k + 1 = ϕ k + α k ( V π ( s ) − V ϕ ( s )) ∇ ϕ V ϕ ( s ) V π ( s ) V^{\pi}(s) V π ( s )
MC 近似 : V π ( s ) = E π [ G 0 ∣ s 0 = s ] ≈ G 0 V^{\pi}(s) = \mathbb{E}^{\pi}[G_0 \mid s_0 = s] \approx G_0 V π ( s ) = E π [ G 0 ∣ s 0 = s ] ≈ G 0 TD 近似 : V π ( s ) ≈ r t + γ V ϕ ( s t + 1 ) V^{\pi}(s) \approx r_t + \gamma V_{\phi}(s_{t+1}) V π ( s ) ≈ r t + γ V ϕ ( s t + 1 )
DQN 是针对 optimal policy 应用 TD learning. 目标函数为:
min ϕ L ( ϕ ) = E ( s , a , r , s ′ ) ∼ D [ 1 2 ( Q ϕ ( s , a ) − ( r + γ max a ′ Q ϕ ( s ′ , a ′ ) ) ) 2 ] \min_{\phi} \mathcal{L}(\phi) = \mathbb{E}_{(s, a, r, s') \sim \mathcal{D}}\left[\frac{1}{2}\left(Q_{\phi}(s, a) - \left(r + \gamma \max_{a'} Q_{\phi}(s', a')\right)\right)^2\right] ϕ min L ( ϕ ) = E ( s , a , r , s ′ ) ∼ D [ 2 1 ( Q ϕ ( s , a ) − ( r + γ a ′ max Q ϕ ( s ′ , a ′ ) ) ) 2 ] 这里 D \mathcal{D} D ( s , a , r , s ′ ) (s, a, r, s') ( s , a , r , s ′ )
💡
DQN 的两个关键技术:
Experience Replay : 使用 replay buffer 存储过去的 transitions,从中随机采样进行训练。这打破了数据之间的相关性,提高了样本效率.Target Network : 使用一个独立的 target network Q ϕ − Q_{\phi^{-}} Q ϕ − ϕ − \phi^{-} ϕ − ϕ \phi ϕ
带有 target network 和 stop-gradient 的 DQN 目标函数为:
L ( ϕ ) = E ( s , a , r , s ′ ) ∼ D [ 1 2 ( Q ϕ ( s , a ) − ( r + γ max a ′ s g [ Q ϕ − ( s ′ , a ′ ) ] ) ) 2 ] \mathcal{L}(\phi) = \mathbb{E}_{(s, a, r, s') \sim \mathcal{D}}\left[\frac{1}{2}\left(Q_{\phi}(s, a) - \left(r + \gamma \, \max_{a'} \mathrm{sg}[Q_{\phi^{-}}(s', a')]\right)\right)^2\right] L ( ϕ ) = E ( s , a , r , s ′ ) ∼ D [ 2 1 ( Q ϕ ( s , a ) − ( r + γ a ′ max sg [ Q ϕ − ( s ′ , a ′ )] ) ) 2 ] 对应的 Python 实现:
# Compute current Q-values q_values = Q_phi(states).gather( 1 , actions) # Compute target Q-values with target network with torch.no_grad(): next_q_values = Q_target(next_states).max( 1 )[ 0 ] targets = rewards + gamma * next_q_values * ( 1 - dones) # Compute loss loss = 0.5 * (q_values - targets) ** 2 loss = loss.mean() Algorithm: DQN with Experience Replay
Initialize replay buffer D \mathcal{D} D N N N
Initialize Q-network Q ϕ Q_{\phi} Q ϕ
Initialize target network Q ϕ − Q_{\phi^{-}} Q ϕ − ϕ − = ϕ \phi^{-} = \phi ϕ − = ϕ
for episode = 1 , … , M 1, \dots, M 1 , … , M
s 0 ∼ p 0 s_0 \sim p_0 s 0 ∼ p 0 for t = 0 , … , T − 1 t = 0, \dots, T-1 t = 0 , … , T − 1
Select action with ϵ \epsilon ϵ a t = { arg max a Q ϕ ( s t , a ) , with prob 1 − ϵ random action , with prob ϵ a_t = \begin{cases}
\arg\max_a Q_{\phi}(s_t, a), & \text{with prob } 1 - \epsilon \\
\text{random action}, & \text{with prob } \epsilon
\end{cases} a t = { arg max a Q ϕ ( s t , a ) , random action , with prob 1 − ϵ with prob ϵ
( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) (r_t, s_{t+1}) \sim p(\cdot, \cdot \mid s_t, a_t) ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) Store ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) ( s t , a t , r t , s t + 1 ) D \mathcal{D} D
Sample random minibatch { ( s i , a i , r i , s i ′ ) } \{(s_i, a_i, r_i, s'_i)\} {( s i , a i , r i , s i ′ )} D \mathcal{D} D
Compute target:
y i = { r i + γ max a ′ Q ϕ − ( s i ′ , a ′ ) , if not terminal r i , if terminal y_i = \begin{cases}
r_i + \gamma \max_{a'} Q_{\phi^{-}}(s'_i, a'), & \text{if not terminal} \\
r_i, & \text{if terminal}
\end{cases} y i = { r i + γ max a ′ Q ϕ − ( s i ′ , a ′ ) , r i , if not terminal if terminal
Update Q-network:
L = 1 ∣ batch ∣ ∑ i 1 2 ( Q ϕ ( s i , a i ) − y i ) 2 , ϕ ← ϕ − α ∇ ϕ L \mathcal{L} = \frac{1}{|\text{batch}|} \sum_i \frac{1}{2} (Q_{\phi}(s_i, a_i) - y_i)^2, \quad \phi \gets \phi - \alpha \nabla_{\phi} \mathcal{L} L = ∣ batch ∣ 1 i ∑ 2 1 ( Q ϕ ( s i , a i ) − y i ) 2 , ϕ ← ϕ − α ∇ ϕ L
Every C C C ϕ − ← ϕ \phi^{-} \gets \phi ϕ − ← ϕ
Double DQN : 解决 DQN 中 max operator 导致的价值高估 (overestimation) 问题. 使用 online network 选择 action, target network 评估 value:
y i = r i + γ Q ϕ − ( s ′ , arg max a ′ Q ϕ ( s ′ , a ′ ) ) y_i = r_i + \gamma \, Q_{\phi^{-}}\left(s', \arg\max_{a'} Q_{\phi}(s', a')\right) y i = r i + γ Q ϕ − ( s ′ , arg a ′ max Q ϕ ( s ′ , a ′ ) ) Dueling DQN : 将 Q-function 分解为 value function 和 advantage function:
Q ( s , a ) = V ( s ) + ( A ( s , a ) − 1 ∣ A ∣ ∑ a ′ A ( s , a ′ ) ) Q(s, a) = V(s) + \left(A(s, a) - \frac{1}{|\mathcal{A}|}\sum_{a'} A(s, a')\right) Q ( s , a ) = V ( s ) + ( A ( s , a ) − ∣ A ∣ 1 a ′ ∑ A ( s , a ′ ) ) 对于 LLM,action space 很大 (词表大小 ∼ 10 5 \sim 10^5 ∼ 1 0 5 max a ′ Q ( s ′ , a ′ ) \max_{a'} Q(s', a') max a ′ Q ( s ′ , a ′ )
policy-based methods 的 motivation 很好理解,我们想要找到一个 optimal policy, 那我们就直接对当前 policy 进行优化。
我们基于某个策略采集一些数据,通过直接优化的方法来不停改进当前策略 π \pi π
根据采样策略的不同,policy-based methods 一般会被分为两类:
on-policy: 采集数据的 policy 和训练更新的 policy 一致
off-policy: 采集数据的 policy 和训练更新的 policy 不一致
这两者的核心区别在于:我们更新模型所使用的数据是否由当前模型产生?如果回答是,则说明算法是 On-policy, 反之则说明是 Off-policy.
on-policy 和 off-policy 对比如下表所示
我们的目标与前面一致,仍然是最大化累计奖励,目标函数为
max π J ( θ ) = E s 0 ∼ p 0 [ V π θ ( s 0 ) ] = E s 0 ∼ p 0 π θ [ ∑ t = 0 T − 1 γ t r t ] \max_{\pi}\mathcal{J}(\theta)=\mathbb{E}_{s_0\sim p_0}\left[V^{\pi_\theta}(s_0)\right]=\mathbb{E}_{s_0\sim p_0}^{\pi_\theta}\left[\sum_{t=0}^{T-1}\gamma^tr_t\right] π max J ( θ ) = E s 0 ∼ p 0 [ V π θ ( s 0 ) ] = E s 0 ∼ p 0 π θ [ t = 0 ∑ T − 1 γ t r t ] 我们首先将采集到的轨迹数据 τ \tau τ
τ = ( s 0 , a 0 , r 0 , … , s T − 1 , a T − 1 , r T − 1 , s T ) \tau = (s_0,a_0,r_0,\dots,s_{T-1}, a_{T-1}, r_{T-1}, s_T) τ = ( s 0 , a 0 , r 0 , … , s T − 1 , a T − 1 , r T − 1 , s T ) τ \tau τ
p θ ( τ ) = p 0 ( s 0 ) ∏ t = 0 T − 1 p ( r t , s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) p_\theta(\tau) = p_0(s_0)\prod_{t=0}^{T-1} p(r_t,s_{t+1}\mid s_t,a_t)\pi_\theta(a_t\mid s_t) p θ ( τ ) = p 0 ( s 0 ) t = 0 ∏ T − 1 p ( r t , s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) 我们使用 cumulative return 的定义,就得到
J ( θ ) = E s 0 ∼ p 0 π [ ∑ t = 0 T − 1 γ t r t ] = E s 0 ∼ p 0 , a t ∼ π θ ( ⋅ ∣ s t ) , ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) π [ ∑ t = 0 T − 1 γ t r t ] = E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ] \mathcal{J}(\theta)=\mathbb{E}_{s_0\sim p_0}^\pi\left[\sum_{t=0}^{T-1}\gamma^tr_t\right] = \mathbb{E}_{s_0\sim p_0,a_t\sim\pi_\theta(\cdot\mid s_t), (r_t,s_{t+1})\sim p(\cdot,\cdot\mid s_t,a_t)}^\pi\left[\sum_{t=0}^{T-1}\gamma^tr_t\right] = \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\right] J ( θ ) = E s 0 ∼ p 0 π [ t = 0 ∑ T − 1 γ t r t ] = E s 0 ∼ p 0 , a t ∼ π θ ( ⋅ ∣ s t ) , ( r t , s t + 1 ) ∼ p ( ⋅ , ⋅ ∣ s t , a t ) π [ t = 0 ∑ T − 1 γ t r t ] = E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ]
此时,目标函数的梯度为
∇ θ J ( θ ) = ∇ θ E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ] = ∑ τ G 0 ( τ ) ∇ θ p θ ( τ ) = ∑ τ p θ ( τ ) G 0 ( τ ) ∇ θ log p θ ( τ ) = E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log p θ ( τ ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) G 0 ( τ ) ] \begin{align}
\nabla_\theta \mathcal{J}(\theta)&=\nabla_\theta\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\right]\\
&= \sum_\tau G_0(\tau)\nabla_\theta p_\theta(\tau)\\
&= \sum_\tau p_\theta(\tau)G_0(\tau) \nabla_\theta \log p_\theta(\tau)\\
&= \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\nabla_\theta \log p_\theta(\tau)\right]\\
&= \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)G_0(\tau)\right]
\end{align} ∇ θ J ( θ ) = ∇ θ E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ] = τ ∑ G 0 ( τ ) ∇ θ p θ ( τ ) = τ ∑ p θ ( τ ) G 0 ( τ ) ∇ θ log p θ ( τ ) = E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log p θ ( τ ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) G 0 ( τ ) ] 这里我们使用了如下不等式
∇ θ p θ ( τ ) = p θ ( τ ) ∇ θ log p θ ( τ ) \nabla_\theta p_\theta(\tau)=p_\theta(\tau)\nabla_\theta \log p_\theta(\tau) ∇ θ p θ ( τ ) = p θ ( τ ) ∇ θ log p θ ( τ ) 以及
∇ θ log p θ ( τ ) = ∇ θ log [ p 0 ( s 0 ) ∏ t = 0 T − 1 p ( r t , s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) ] = ∑ t = 0 T − 1 log π θ ( a t ∣ s t ) \nabla_\theta \log p_\theta(\tau) = \nabla_\theta \log \left[p_0(s_0)\prod_{t=0}^{T-1} p(r_t,s_{t+1}\mid s_t,a_t)\pi_\theta(a_t\mid s_t)\right] = \sum_{t=0}^{T-1}\log\pi_\theta(a_t\mid s_t) ∇ θ log p θ ( τ ) = ∇ θ log [ p 0 ( s 0 ) t = 0 ∏ T − 1 p ( r t , s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) ] = t = 0 ∑ T − 1 log π θ ( a t ∣ s t ) 一些教材上还有另一种表达形式,使用了 Q-function, 即
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] \nabla_\theta \mathcal{J}(\theta) = \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)Q^\pi(s_t,a_t)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] 我们可以对其进行证明,证明需要用到 Expectation 中的全概率公式。注意到
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] = ∑ t = 0 T − 1 E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] = ∑ t = 0 T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ∣ τ : t ] ] = ∑ t = 0 T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∣ τ : t ] ] = ∑ t = 0 T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∣ s t , a t ] ] = ∑ t = 0 T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] \begin{align}
\nabla_\theta \mathcal{J}(\theta)&=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}G_0(\tau)\nabla_\theta \log \pi_\theta(a_t\mid s_t)\right]\\
&= \sum_{t=0}^{T-1}\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\nabla_\theta \log\pi_\theta(a_t\mid s_t)\right]\\
&=\sum_{t=0}^{T-1}\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\nabla_\theta \log\pi_\theta(a_t\mid s_t)\mid \tau_{:t}\right]\right]\\
&=\sum_{t=0}^{T-1}\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[\nabla_\theta \log\pi_\theta(a_t\mid s_t)\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\mid \tau_{:t}\right]\right]\\
&=\sum_{t=0}^{T-1}\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[\nabla_\theta \log\pi_\theta(a_t\mid s_t)\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[G_0(\tau)\mid s_t,a_t\right]\right]\\
&=\sum_{t=0}^{T-1}\mathbb{E}_{\tau_{:t}\sim(p_0,\pi_\theta, p)}\left[\nabla_\theta \log\pi_\theta(a_t\mid s_t)Q^\pi(s_t,a_t)\right]
\end{align} ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] = t = 0 ∑ T − 1 E τ ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ] = t = 0 ∑ T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∇ θ log π θ ( a t ∣ s t ) ∣ τ : t ] ] = t = 0 ∑ T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∣ τ : t ] ] = t = 0 ∑ T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) E τ : t ∼ ( p 0 , π θ , p ) [ G 0 ( τ ) ∣ s t , a t ] ] = t = 0 ∑ T − 1 E τ : t ∼ ( p 0 , π θ , p ) [ ∇ θ log π θ ( a t ∣ s t ) Q π ( s t , a t ) ] 这里第三个等式使用了全概率公式,第四个等式是因为 ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log\pi_\theta(a_t\mid s_t) ∇ θ log π θ ( a t ∣ s t ) τ : t \tau_{:t} τ : t
令
g ^ : = ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) G 0 ( τ ) \hat{g} := \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)G_0(\tau) g ^ := t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) G 0 ( τ ) 由 ∇ θ J ( θ ) \nabla_\theta \mathcal{J}(\theta) ∇ θ J ( θ ) g ^ \hat{g} g ^ ∇ θ J ( θ ) \nabla_\theta \mathcal{J}(\theta) ∇ θ J ( θ )
基于 MC 思想,我们可以得到最简单的 policy gradient algorithm, 也就是 REINFORCE 算法
Algorithm: Policy Gradient with MC (REINFORCE)
Initialize policy parameters θ 0 \theta_0 θ 0
for k = 0 , 1 , … k=0,1,\dots k = 0 , 1 , …
Sample M M M { τ i } \{\tau_i\} { τ i } π θ k \pi_{\theta_k} π θ k
Estimate the gradient via MC:
g ^ = 1 M ∑ i = 1 M ∑ t = 0 T i − 1 ∇ θ log π θ k ( a t ∣ s t ) G 0 ( τ i ) \hat{g}=\frac{1}{M}\sum_{i=1}^M\sum_{t=0}^{T_i-1}\nabla_\theta\log\pi_{\theta_k}(a_t\mid s_t)G_0(\tau_i) g ^ = M 1 i = 1 ∑ M t = 0 ∑ T i − 1 ∇ θ log π θ k ( a t ∣ s t ) G 0 ( τ i )
Update θ k \theta_k θ k g ^ \hat{g} g ^
g g g ∇ θ J ( θ ) \nabla_\theta \mathcal{J}(\theta) ∇ θ J ( θ ) g g g
我们本节主要介绍如何减少 g g g
首先我们介绍 policy gradient 的 baseline invariance 性质
: Baseline Invairance of Policy Gradient 我们有如下等式
E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ∑ t = 0 T − 1 r ( s t ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ( ∑ t = 0 T − 1 r ( s t ) − b ( s t ) ) ] \begin{aligned}
&\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\sum_{t=0}^{T-1}r(s_t)\right] \\
=& \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\left(\sum_{t=0}^{T-1}r(s_t)-b(s_t)\right)\right]
\end{aligned} = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) t = 0 ∑ T − 1 r ( s t ) ] E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) ( t = 0 ∑ T − 1 r ( s t ) − b ( s t ) ) ] 其中 b b b
Proof: 我们证明
E τ ∼ ( p 0 , π θ , p ) [ b ( s t ) ∇ θ log p θ ( a t ∣ s t ) ] = 0 \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[b(s_t)\nabla_\theta \log p_\theta(a_t\mid s_t)\right]=0 E τ ∼ ( p 0 , π θ , p ) [ b ( s t ) ∇ θ log p θ ( a t ∣ s t ) ] = 0 注意到
E τ ∼ ( p 0 , π θ , p ) [ b ( s t ) ∇ θ log p θ ( a t ∣ s t ) ] = E s 0 ∼ p 0 [ b ( s t ) E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ] ] = E s 0 ∼ p 0 [ b ( s t ) ∑ a ∇ θ π θ ( a ∣ s ) ] = E s 0 ∼ p 0 [ b ( s t ) ∇ θ ∑ a π θ ( a ∣ s ) ] = E s 0 ∼ p 0 [ b ( s t ) ∇ θ 1 ] = 0 \begin{aligned}
\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[b(s_t)\nabla_\theta \log p_\theta(a_t\mid s_t)\right] &= \mathbb{E}_{s_0\sim p_0}\left[b(s_t)\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\right]\right]\\
&= \mathbb{E}_{s_0\sim p_0}\left[b(s_t)\sum_{a}\nabla_\theta \pi_\theta(a\mid s)\right]\\
&= \mathbb{E}_{s_0\sim p_0}\left[b(s_t)\nabla_\theta \sum_{a}\pi_\theta(a\mid s)\right]\\
&= \mathbb{E}_{s_0\sim p_0}\left[b(s_t)\nabla_\theta 1\right]\\
&=0
\end{aligned} E τ ∼ ( p 0 , π θ , p ) [ b ( s t ) ∇ θ log p θ ( a t ∣ s t ) ] = E s 0 ∼ p 0 [ b ( s t ) E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ] ] = E s 0 ∼ p 0 [ b ( s t ) a ∑ ∇ θ π θ ( a ∣ s ) ] = E s 0 ∼ p 0 [ b ( s t ) ∇ θ a ∑ π θ ( a ∣ s ) ] = E s 0 ∼ p 0 [ b ( s t ) ∇ θ 1 ] = 0 因此, policy gradient 满足 baseline invairance property.
上述等式说明我们可以通过改变 b b b b ( s t ) b(s_t) b ( s t ) baseline .
Reward to go 的基本思想为
对于时刻 t t t s 0 , r 0 , … , r t − 1 s_0,r_0,\dots,r_{t-1} s 0 , r 0 , … , r t − 1 b ( s t ) b(s_t) b ( s t )
其定义的 baseline 如下所示
b ( s t ) = ∑ k = 0 t γ k r k b(s_t) = \sum_{k=0}^{t}\gamma^k r_k b ( s t ) = k = 0 ∑ t γ k r k 此时,我们的 policy gradient 为
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ∑ k = t T − 1 r ( s k ) ] \nabla_\theta \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\sum_{k=t}^{T-1}r(s_{k})\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) k = t ∑ T − 1 r ( s k ) ] 对应的 REINFORCE 算法改进版本为
Algorithm: Policy Gradient with MC and reward to go (REINFORCE)
Initialize policy parameters θ 0 \theta_0 θ 0
for k = 0 , 1 , … k=0,1,\dots k = 0 , 1 , …
Sample M M M { τ i } \{\tau_i\} { τ i } π θ k \pi_{\theta_k} π θ k
Estimate the gradient via MC:
g ^ = 1 M ∑ i = 1 M ∇ θ log π θ k ( a t ∣ s t ) γ t G t ( τ i ) \hat{g}=\frac{1}{M}\sum_{i=1}^M\nabla_\theta\log\pi_{\theta_k}(a_t\mid s_t)\gamma^tG_t(\tau_i) g ^ = M 1 i = 1 ∑ M ∇ θ log π θ k ( a t ∣ s t ) γ t G t ( τ i )
Update θ k \theta_k θ k g ^ \hat{g} g ^
我们可以从理论上推导出最优 baseline.
Lemma: 令 s s s a a a w ( s , a ) w(s,a) w ( s , a ) Q ( s , a ) Q(s,a) Q ( s , a ) b ( s ) b(s) b ( s )
b ∗ = arg min b ( ⋅ ) E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ( s ) ) 2 ] b^* = \arg\min_{b(\cdot)} \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b(s)\right)^2\right] b ∗ = arg b ( ⋅ ) min E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ( s ) ) 2 ] 其中
b ∗ ( s ) = E a ∣ s [ w 2 ( s , a ) Q ( s , a ) ∣ s ] E a ∣ s [ w 2 ( s , a ) ∣ s ] b^*(s) = \frac{\mathbb{E}_{a\mid s}\left[w^2(s,a)Q(s,a)\mid s\right]}{\mathbb{E}_{a\mid s}\left[w^2(s,a)\mid s\right]} b ∗ ( s ) = E a ∣ s [ w 2 ( s , a ) ∣ s ] E a ∣ s [ w 2 ( s , a ) Q ( s , a ) ∣ s ]
Proof: 对目标函数进行展开得到
E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ( s ) ) 2 ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) + b ∗ ( s ) − b ( s ) ) 2 ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] + E a , s [ w 2 ( s , a ) ( b ∗ ( s ) − b ( s ) ) 2 ] + 2 E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] + E a , s [ w 2 ( s , a ) ( b ∗ ( s ) − b ( s ) ) 2 ] ≥ E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] \begin{aligned}
\mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b(s)\right)^2\right]&= \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)+b^*(s)-b(s)\right)^2\right]\\
&= \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)^2\right]+\mathbb{E}_{a,s}\left[w^2(s,a)\left(b^*(s)-b(s)\right)^2\right]\\
&+2\mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)\left(b^*(s)-b(s)\right)\right]\\
&= \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)^2\right]+\mathbb{E}_{a,s}\left[w^2(s,a)\left(b^*(s)-b(s)\right)^2\right]\\
&\geq \mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)^2\right]
\end{aligned} E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ( s ) ) 2 ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) + b ∗ ( s ) − b ( s ) ) 2 ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] + E a , s [ w 2 ( s , a ) ( b ∗ ( s ) − b ( s ) ) 2 ] + 2 E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] + E a , s [ w 2 ( s , a ) ( b ∗ ( s ) − b ( s ) ) 2 ] ≥ E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) 2 ] 其中第三个等式用到了
E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = E s [ E a ∣ s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] ∣ s ] = E s [ ( E a ∣ s [ w 2 ( s , a ) Q ( s , a ) ∣ s ] − E a ∣ s [ w 2 ( s , a ) ∣ s ] b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = 0 \begin{aligned}
\mathbb{E}_{a,s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)\left(b^*(s)-b(s)\right)\right]&= \mathbb{E}_{s}\left[\mathbb{E}_{a\mid s}\left[w^2(s,a)\left(Q(s,a)-b^*(s)\right)\left(b^*(s)-b(s)\right)\right]\mid s\right]\\
&= \mathbb{E}_{s}\left[\left(\mathbb{E}_{a\mid s}\left[w^2(s,a)Q(s,a)\mid s\right] - \mathbb{E}_{a\mid s}\left[w^2(s,a)\mid s\right]b^*(s)\right)\left(b^*(s)-b(s)\right)\right]\\
&=0
\end{aligned} E a , s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = E s [ E a ∣ s [ w 2 ( s , a ) ( Q ( s , a ) − b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] ∣ s ] = E s [ ( E a ∣ s [ w 2 ( s , a ) Q ( s , a ) ∣ s ] − E a ∣ s [ w 2 ( s , a ) ∣ s ] b ∗ ( s ) ) ( b ∗ ( s ) − b ( s ) ) ] = 0 证毕。■ \blacksquare ■
基于上述引理,我们可以得到关于 baseline invariance 中的最优 basline:
b ∗ ( s ) = E a t ∼ π θ ( ⋅ ∣ s t ) [ ( ∇ θ log π θ ( a t ∣ s t ) ) 2 Q π θ ( s , a ) ∣ s ] E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ) 2 ∣ s ] b^*(s) =\frac{\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[(\nabla_\theta\log\pi_\theta(a_t\mid s_t))^2Q^{\pi_\theta}(s,a)\mid s\right]}{\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[\nabla_\theta\log\pi_\theta(a_t\mid s_t))^2\mid s\right]} b ∗ ( s ) = E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) ) 2 ∣ s ] E a t ∼ π θ ( ⋅ ∣ s t ) [ ( ∇ θ log π θ ( a t ∣ s t ) ) 2 Q π θ ( s , a ) ∣ s ] 理论上我们可以使用 b ∗ ( s t ) b^*(s_t) b ∗ ( s t ) b ∗ ( s ) b^*(s) b ∗ ( s ) ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta\log\pi_\theta(a_t\mid s_t) ∇ θ log π θ ( a t ∣ s t )
b ( s ) = E a t ∼ π θ ( ⋅ ∣ s t ) [ Q π θ ( s , a ) ∣ s ] E a t ∼ π θ ( ⋅ ∣ s t ) [ 1 ∣ s ] = V π θ ( s ) b(s) = \frac{\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[Q^{\pi_\theta}(s,a)\mid s\right]}{\mathbb{E}_{a_t\sim\pi_\theta(\cdot\mid s_t)}\left[1\mid s\right]} = V^{\pi_\theta}(s) b ( s ) = E a t ∼ π θ ( ⋅ ∣ s t ) [ 1 ∣ s ] E a t ∼ π θ ( ⋅ ∣ s t ) [ Q π θ ( s , a ) ∣ s ] = V π θ ( s ) b ( s ) = V π θ ( s ) b(s)=V^{\pi_\theta}(s) b ( s ) = V π θ ( s )
我们将 b ( s ) = V π θ ( s ) b(s)=V^{\pi_\theta}(s) b ( s ) = V π θ ( s )
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ( Q π θ ( s t , a t ) − V π θ ( s t ) ) ] \nabla_\theta \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\left(Q^{\pi_\theta}(s_t,a_t)-V^{\pi_\theta}(s_t)\right)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) ( Q π θ ( s t , a t ) − V π θ ( s t ) ) ] 我们定义
A π θ ( s t , a t ) : = Q π θ ( s t , a t ) − V π θ ( s t ) \boxed{
A^{\pi_\theta}(s_t,a_t) := Q^{\pi_\theta}(s_t,a_t)-V^{\pi_\theta}(s_t)
} A π θ ( s t , a t ) := Q π θ ( s t , a t ) − V π θ ( s t ) 为 a t a_t a t s t s_t s t advantage . 注意到 V π θ ( s t ) V^{\pi_\theta}(s_t) V π θ ( s t ) π θ \pi_\theta π θ a t a_t a t π θ \pi_\theta π θ
如果 A π θ ( s t , a t ) > 0 A^{\pi_\theta}(s_t,a_t) >0 A π θ ( s t , a t ) > 0 a t a_t a t π θ \pi_\theta π θ
反之如果 A π θ ( s t , a t ) < 0 A^{\pi_\theta}(s_t,a_t) <0 A π θ ( s t , a t ) < 0 a t a_t a t π θ \pi_\theta π θ
实际场景下,由于 V π θ ( s t ) V^{\pi_\theta}(s_t) V π θ ( s t )
A ^ π θ ( s t , a t ) : = Q π θ ( s t , a t ) − V ϕ ( s t ) \hat{A}^{\pi_\theta}(s_t,a_t) := Q^{\pi_\theta}(s_t,a_t)-V^{\phi}(s_t) A ^ π θ ( s t , a t ) := Q π θ ( s t , a t ) − V ϕ ( s t ) 来代替。
对于最优策略 π ∗ \pi^* π ∗
A π ∗ ( s t , a t ) : = Q π ∗ ( s t , a t ) − V π ∗ ( s t ) ≤ 0 A^{\pi^*}(s_t,a_t) := Q^{\pi^*}(s_t,a_t)-V^{\pi^*}(s_t)\leq 0 A π ∗ ( s t , a t ) := Q π ∗ ( s t , a t ) − V π ∗ ( s t ) ≤ 0 证明也很简单,注意到 V π ∗ ( s t ) = max a Q π ∗ ( s t , a t ) V^{\pi^*}(s_t)=\max_{a}Q^{\pi^*}(s_t,a_t) V π ∗ ( s t ) = max a Q π ∗ ( s t , a t )
最后,我们的 REINFORCE 算法改进如下
Algorithm: Policy Gradient with MC and value function (REINFORCE)
Initialize policy parameters θ 0 \theta_0 θ 0
for k = 0 , 1 , … k=0,1,\dots k = 0 , 1 , …
Sample M M M { τ i } \{\tau_i\} { τ i } π θ k \pi_{\theta_k} π θ k
Estimate the gradient via MC:
g ^ = 1 M ∑ i = 1 M ∇ θ log π θ k ( a t ∣ s t ) γ t ( Q π θ ( s t , a t ) − V ϕ ( s t ) ) \hat{g}=\frac{1}{M}\sum_{i=1}^M\nabla_\theta\log\pi_{\theta_k}(a_t\mid s_t)\gamma^t(Q^{\pi_\theta}(s_t,a_t)-V^{\phi}(s_t)) g ^ = M 1 i = 1 ∑ M ∇ θ log π θ k ( a t ∣ s t ) γ t ( Q π θ ( s t , a t ) − V ϕ ( s t ))
Update θ k \theta_k θ k g ^ \hat{g} g ^
我们在前面介绍了不同的降低 variance 的方法,但是我们还没有在理论上回答为什么可以降低 variance, 本节我们将基于 Rao-Blackwell theorem 来回答这个问题
Theorem: Rao-Blackwell Theorem 令 X X X Y Y Y I ^ 1 ( X , Y ) \hat{I}_1(X,Y) I ^ 1 ( X , Y ) I I I
I = E X Y [ I ^ 1 ( X Y ) ] I = \mathbb{E}_{XY}[\hat{I}_1(XY)] I = E X Y [ I ^ 1 ( X Y )] 令 I ^ 2 ( Y ) = E X ∣ Y [ I ^ 1 ( X , Y ) ∣ Y ] \hat{I}_2(Y)=\mathbb{E}_{X\mid Y}[\hat{I}_1(X,Y)\mid Y] I ^ 2 ( Y ) = E X ∣ Y [ I ^ 1 ( X , Y ) ∣ Y ] I ^ 2 \hat{I}_2 I ^ 2 I I I
v a r [ I ^ 2 ] ≤ v a r [ I ^ 1 ] \mathrm{var}[\hat{I}_2]\leq\mathrm{var}[\hat{I}_1] var [ I ^ 2 ] ≤ var [ I ^ 1 ] I ^ 2 \hat{I}_2 I ^ 2 I ^ 1 ( X , Y ) \hat{I}_1(X,Y) I ^ 1 ( X , Y ) Rao-Blackwellized estimator .
Proof: 由 Expectation 中的 law of total expectation, 我们有
E X Y [ I ^ 2 ( X Y ) ] = E Y [ E X ∣ Y [ I ^ 1 ( X , Y ) ∣ Y ] ] = E X Y [ I ^ 1 ( X Y ) ] = I \mathbb{E}_{XY}[\hat{I}_2(XY) ]=\mathbb{E}_{Y}[\mathbb{E}_{X\mid Y}[\hat{I}_1(X,Y)\mid Y]]=\mathbb{E}_{XY}[\hat{I}_1(XY) ]=I E X Y [ I ^ 2 ( X Y )] = E Y [ E X ∣ Y [ I ^ 1 ( X , Y ) ∣ Y ]] = E X Y [ I ^ 1 ( X Y )] = I 其次,我们有
v a r [ I ^ 2 ] = E Y [ ( I − I ^ 2 ( Y ) ) 2 ] = E Y [ ( E X ∣ Y [ I − I ^ 1 ( X , Y ) ∣ Y ] ) 2 ] ≤ E Y [ ( E X ∣ Y [ ( I − I ^ 1 ( X , Y ) ) 2 ∣ Y ] ) ] = E Y [ ( I − I ^ 1 ( X , Y ) ) 2 ] = v a r [ I ^ 1 ] \begin{align}
\mathrm{var}[\hat{I}_2]&=\mathbb{E}_{Y}[(I-\hat{I}_2(Y))^2]\\
&= \mathbb{E}_{Y}[\left(\mathbb{E}_{X\mid Y}\left[I-\hat{I}_1(X,Y)\mid Y\right]\right)^2]\\
&\leq\mathbb{E}_{Y}[\left(\mathbb{E}_{X\mid Y}\left[(I-\hat{I}_1(X,Y))^2\mid Y\right]\right)]\\
&= \mathbb{E}_{Y}[(I-\hat{I}_1(X,Y))^2]\\
&=\mathrm{var}[\hat{I}_1]
\end{align} var [ I ^ 2 ] = E Y [( I − I ^ 2 ( Y ) ) 2 ] = E Y [ ( E X ∣ Y [ I − I ^ 1 ( X , Y ) ∣ Y ] ) 2 ] ≤ E Y [ ( E X ∣ Y [ ( I − I ^ 1 ( X , Y ) ) 2 ∣ Y ] ) ] = E Y [( I − I ^ 1 ( X , Y ) ) 2 ] = var [ I ^ 1 ] 这里不等式使用了 Jensen’s inequality. 证毕。■ \blacksquare ■
Rao–Blackwell Theorem 说明了我们可以通过构造一个新的无偏估计,这个新的无偏估计相对于原始的无偏估计,有更小的方差。
最后,我们把前面的 basline 使用统一的公式进行表示,记
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ Ψ ( τ ) ∇ θ log p θ ( τ ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T Ψ t ( τ ) ∇ θ log p θ ( τ ) ] \nabla_\theta \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[\Psi(\tau)\nabla_\theta \log p_\theta(\tau)\right]=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[\sum_{t=0}^T\Psi_t(\tau)\nabla_\theta \log p_\theta(\tau)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ Ψ ( τ ) ∇ θ log p θ ( τ ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T Ψ t ( τ ) ∇ θ log p θ ( τ ) ] 则不同的方法对应的表达式如下
TODO
在上一节中, 我们介绍了经典的 policy gradient 形式,并基于 policy gradient 构建了经典的 REINFORCE 算法,我们还使用了 baseline invariance 性质来降低 policy gradient 的 variance, 并得到了最终的 advantage 形式。
在本节中,我们将要针对 advantage 进行进一步探讨,介绍如何将 value based methods 和 policy based methods 结合起来得到 actor-critic methods.
actor-critic
A2C/A3C
GAE
我们首先考虑最简单的 actor-critic algorithm, 注意到
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] \nabla_\theta \mathcal{J}(\theta) = \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)Q^{\pi_\theta}(s_t,a_t)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] 因此,其对应的 policy gradient methods 为
θ k + 1 = θ k + α E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] \theta_{k+1} = \theta_k + \alpha \mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)Q^{\pi_\theta}(s_t,a_t)\right] θ k + 1 = θ k + α E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] 在前面的章节中,我们介绍了基于 MC 和 TD 两种方式来估计 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t,a_t) Q π θ ( s t , a t )
如果 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t,a_t) Q π θ ( s t , a t )
如果 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t,a_t) Q π θ ( s t , a t ) actor-critic , 这是我们本节的重点介绍内容
最简单的 actor-critic algorithm 如下所示
Algorithm: Q Actor-Critic
Initialize policy parameters θ 0 \theta_0 θ 0 ϕ 0 \phi_0 ϕ 0
for t = 0 , 1 , … , T − 1 t = 0, 1, \dots, T-1 t = 0 , 1 , … , T − 1
a t ∼ π θ ( ⋅ ∣ s t ) a_t \sim \pi_{\theta}(\cdot \mid s_t) a t ∼ π θ ( ⋅ ∣ s t ) r t , s t + 1 ∼ p ( ⋅ , ⋅ ∣ s t , a t ) r_t, s_{t+1} \sim p(\cdot, \cdot \mid s_t, a_t) r t , s t + 1 ∼ p ( ⋅ , ⋅ ∣ s t , a t ) a t + 1 ∼ π θ ( ⋅ ∣ s t + 1 ) a_{t+1} \sim \pi_{\theta}(\cdot \mid s_{t+1}) a t + 1 ∼ π θ ( ⋅ ∣ s t + 1 ) (ACTOR) policy update :
θ t + 1 = θ t + α θ ∇ θ log π θ ( a t ∣ s t ) Q ϕ t ( s t , a t ) \theta_{t+1} = \theta_t + \alpha_{\theta} \nabla_{\theta} \log \pi_{\theta}(a_t \mid s_t) \, Q^{\phi_t}(s_t, a_t) θ t + 1 = θ t + α θ ∇ θ log π θ ( a t ∣ s t ) Q ϕ t ( s t , a t ) (CRITIC) value update :
ϕ t + 1 = ϕ t + α ϕ [ r t + γ Q ϕ t ( s t + 1 , a t + 1 ) − Q ϕ t ( s t , a t ) ] ∇ ϕ Q ϕ t ( s t , a t ) \phi_{t+1} = \phi_t + \alpha_{\phi} \left[r_t + \gamma Q^{\phi_t}(s_{t+1}, a_{t+1}) - Q^{\phi_t}(s_t, a_t)\right] \nabla_{\phi} Q^{\phi_t}(s_t, a_t) ϕ t + 1 = ϕ t + α ϕ [ r t + γ Q ϕ t ( s t + 1 , a t + 1 ) − Q ϕ t ( s t , a t ) ] ∇ ϕ Q ϕ t ( s t , a t )
在上一节中,我们介绍了 QAC, 但实际上我们用的更多的是 advantage actor-critic, 其梯度如下所示
∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) A π θ ( s t , a t ) ] \nabla_\theta \mathcal{J}(\theta)=\mathbb{E}_{\tau\sim(p_0,\pi_\theta, p)}\left[ \sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)A^{\pi_\theta}(s_t,a_t)\right] ∇ θ J ( θ ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 ∇ θ log π θ ( a t ∣ s t ) A π θ ( s t , a t ) ] 注意到
A π θ ( s t , a t ) = Q π θ ( s t , a t ) − V π θ ( s t ) = E π θ [ r t + γ V π θ ( s t + 1 ) − V π θ ( s t ) ∣ s t , a t ] A^{\pi_\theta}(s_t,a_t)=Q^{\pi_\theta}(s_t,a_t)-V^{\pi_\theta}(s_t) = \mathbb{E}^{\pi_\theta}\left[r_t + \gamma V^{\pi_\theta}(s_{t+1})-V^{\pi_\theta}(s_t)\mid s_t, a_t\right] A π θ ( s t , a t ) = Q π θ ( s t , a t ) − V π θ ( s t ) = E π θ [ r t + γ V π θ ( s t + 1 ) − V π θ ( s t ) ∣ s t , a t ] 因此我们可以用 TD error 来进行近似:
A ^ t = r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) \hat{A}_t= r_t + \gamma V_{\phi_t}(s_{t+1})-V_{\phi_t}(s_t) A ^ t = r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) 这样我们就得到了 A2C 算法
Algorithm: Advantage Actor-Critic (A2C)
Initialize policy parameters θ 0 \theta_0 θ 0 ϕ 0 \phi_0 ϕ 0
for t = 0 , 1 , … , T − 1 t = 0, 1, \dots, T-1 t = 0 , 1 , … , T − 1
a t ∼ π θ ( ⋅ ∣ s t ) a_t \sim \pi_{\theta}(\cdot \mid s_t) a t ∼ π θ ( ⋅ ∣ s t ) r t , s t + 1 ∼ p ( ⋅ , ⋅ ∣ s t , a t ) r_t, s_{t+1} \sim p(\cdot, \cdot \mid s_t, a_t) r t , s t + 1 ∼ p ( ⋅ , ⋅ ∣ s t , a t ) Advantage estimation :
A ^ t ≈ r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) \hat{A}_t \approx r_t + \gamma V_{\phi_t}(s_{t+1}) - V_{\phi_t}(s_t) A ^ t ≈ r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) (ACTOR) policy update :
θ t + 1 = θ t + α θ ∇ θ log π θ ( a t ∣ s t ) A ^ t \theta_{t+1} = \theta_t + \alpha_{\theta} \nabla_{\theta} \log \pi_{\theta}(a_t \mid s_t) \, \hat{A}_t θ t + 1 = θ t + α θ ∇ θ log π θ ( a t ∣ s t ) A ^ t (CRITIC) value update :
ϕ t + 1 = ϕ t + α ϕ A ^ t ∇ ϕ V ϕ t ( s t ) \phi_{t+1} = \phi_t + \alpha_{\phi} \, \hat{A}_t \, \nabla_{\phi} V^{\phi_t}(s_t) ϕ t + 1 = ϕ t + α ϕ A ^ t ∇ ϕ V ϕ t ( s t )
在上一节中,我们介绍了我们可以用 1-step TD error 来近似 advantage,
对比结果如下表所示
为了实现更好的 bias-variance trade-off, GAE (Schulman et al., 2016 ) 提出了使用一个参数 λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ ∈ [ 0 , 1 ]
A ^ t G A E ( γ , λ ) = ∑ ℓ = 0 ∞ ( γ λ ) ℓ δ t + ℓ \hat{A}_t^{GAE(\gamma,\lambda)} = \sum_{\ell=0}^{\infty}(\gamma\lambda)^{\ell}\delta_{t+\ell} A ^ t G A E ( γ , λ ) = ℓ = 0 ∑ ∞ ( γ λ ) ℓ δ t + ℓ 其中
δ t = r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) \delta_t = r_t + \gamma V_{\phi_t}(s_{t+1})-V_{\phi_t}(s_t) δ t = r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) 我们可以探究不同的 λ \lambda λ
当 λ = 0 \lambda=0 λ = 0
A ^ t G A E ( γ , 0 ) = ( γ ⋅ 0 ) 0 δ t = δ t \hat{A}_t^{GAE(\gamma,0)} = (\gamma\cdot0)^0\delta_t=\delta_t A ^ t G A E ( γ , 0 ) = ( γ ⋅ 0 ) 0 δ t = δ t 此时,GAE 就退化成了 one-step TD error estimate,
当 λ = 1 \lambda=1 λ = 1
A ^ t G A E ( γ , 1 ) = ∑ ℓ = 0 ∞ γ ℓ δ t + ℓ = ∑ ℓ = 0 ∞ γ ℓ ( r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) ) \hat{A}_t^{GAE(\gamma,1)} = \sum_{\ell=0}^{\infty}\gamma^{\ell}\delta_{t+\ell}=\sum_{\ell=0}^{\infty}\gamma^{\ell}\left(r_t + \gamma V_{\phi_t}(s_{t+1})-V_{\phi_t}(s_t)\right) A ^ t G A E ( γ , 1 ) = ℓ = 0 ∑ ∞ γ ℓ δ t + ℓ = ℓ = 0 ∑ ∞ γ ℓ ( r t + γ V ϕ t ( s t + 1 ) − V ϕ t ( s t ) ) 如果我们假设这里使用的是真实的 value function 的话,那么我们有
A ^ t G A E ( γ , 1 ) ≈ ∑ ℓ = 0 ∞ γ ℓ r t + ℓ + 1 − V ( s t ) = Q π θ ( s t , a t ) − V ( s t ) \hat{A}_t^{GAE(\gamma,1)} \approx \sum_{\ell=0}^{\infty}\gamma^{\ell}r_{t+\ell+1}-V(s_t)=Q^{\pi_\theta}(s_t,a_t)-V(s_t) A ^ t G A E ( γ , 1 ) ≈ ℓ = 0 ∑ ∞ γ ℓ r t + ℓ + 1 − V ( s t ) = Q π θ ( s t , a t ) − V ( s t ) 当 0 < λ < 1 0<\lambda<1 0 < λ < 1 G A E GAE G A E λ \lambda λ λ \lambda λ
实际计算过程中,我们使用如下方法来进行计算
Algorithm: Generalized Advantage Estimation (GAE)
Given policy parameters θ \theta θ ϕ \phi ϕ
Sample a trajectory τ ∼ ( p 0 , π θ , p ) \tau \sim (p_0, \pi_{\theta}, p) τ ∼ ( p 0 , π θ , p )
for t = 0 , 1 , … , T − 1 t = 0, 1, \dots, T-1 t = 0 , 1 , … , T − 1
Compute TD errors:
δ t = r t + γ V ϕ ( s t + 1 ) − V ϕ ( s t ) \delta_t = r_t + \gamma V_{\phi}(s_{t+1}) - V_{\phi}(s_t) δ t = r t + γ V ϕ ( s t + 1 ) − V ϕ ( s t )
Initialize A ^ T G A E = 0 \hat{A}_{T}^{\mathrm{GAE}} = 0 A ^ T GAE = 0
for t = T − 1 , … , 0 t = T-1, \dots, 0 t = T − 1 , … , 0
Iterate backward:
A ^ t G A E = δ t + γ λ A ^ t + 1 G A E \hat{A}_t^{\mathrm{GAE}} = \delta_t + \gamma\lambda \, \hat{A}_{t+1}^{\mathrm{GAE}} A ^ t GAE = δ t + γ λ A ^ t + 1 GAE
GAE 的主要优点在于其相对于 MC estimate 可以大幅度降低 variance, 从而提高训练的稳定性以及效率
comparison with value-based methods:
无法处理高维或者连续动作空间,actor-critic 中 actor 可以输出一个连续值的概率分布,直接从分布中采样就能得到动作,不需要遍历动作空间
无法学习到随机策略: value-based methods 只能推导出确定性策略,使用 ϵ \epsilon ϵ
学习到的策略更平滑:value-based methods 动作选择依赖于 greedy strategy, 导致 Q function 微小变化导致策略发生剧烈跳变。而 actor-critic 通过 policy gradient 解决了这个问题
comparison with policy-based methods
policy-based methods 依赖完整的 rollout 的 return 来更新,对于 long-term tasks, 最后的 return 方差很大,训练难以收敛。 actor-critic 通过引入 critic 来估计期望收益,计算 advantage, 来降低整体法国差,同时用 TD error 代替回合更新,加速训练。
Schulman, J., Moritz, P., Levine, S., Jordan, M., & Abbeel, P. (2016). High-Dimensional Continuous Control Using Generalized Advantage Estimation. Proceedings of the International Conference on Learning Representations (ICLR) . 在本文中,我们探讨如何提高 policy gradient methods 的 sample efficiency.
在上一节中介绍的 REINFORCE 算法中,我们每次都需要基于当前策略 π θ \pi_\theta π θ π θ \pi_\theta π θ
一个自然的想法是,我们能否利用已有的数据集来进行训练,也就是 off-policy 版本的 policy gradient algorithm.
这就是 Trust Region Policy Optimization (TRPO) (Schulman et al., 2015 ) 算法的核心。
我们的目标函数为
max π J ( θ ) = E s 0 ∼ p 0 [ V π θ ( s 0 ) ] \max_{\pi}\mathcal{J}(\theta)=\mathbb{E}_{s_0\sim p_0}\left[V^{\pi_\theta}(s_0)\right] π max J ( θ ) = E s 0 ∼ p 0 [ V π θ ( s 0 ) ] 我们假设有两个 policy 的参数, θ \theta θ θ o l d \theta_{old} θ o l d
J ( θ ) − J ( θ o l d ) = J ( θ ) − E s 0 ∼ p 0 [ V π θ o l d ( s 0 ) ] = J ( θ ) − E τ ∼ ( p 0 , π θ , p ) [ V π θ o l d ( s 0 ) ] = J ( θ ) − E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t V π θ o l d ( s t ) − ∑ t = 1 T − 1 γ t V π θ o l d ( s t ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t r t ] + E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t ( γ V π θ o l d ( s t + 1 ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t ( r t + γ V π θ o l d ( s t + 1 ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t ( γ Q π θ o l d ( s t , a t ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t A π θ o l d ( s t , a t ) ] \begin{aligned}
\mathcal{J}(\theta) -\mathcal{J}(\theta_{old}) &= \mathcal{J}(\theta) - \mathbb{E}_{s_0\sim p_0}\left[V^{\pi_{\theta_{old}}}(s_0)\right]\\
&= \mathcal{J}(\theta) - \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[V^{\pi_{\theta_{old}}}(s_0)\right]\\
&= \mathcal{J}(\theta) - \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^tV^{\pi_{\theta_{old}}}(s_t)-\sum_{t=1}^{T-1}\gamma^tV^{\pi_{\theta_{old}}}(s_t)\right]\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t r_t\right] + \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t\left(\gamma V^{\pi_{\theta_{old}}}(s_{t+1})-V^{\pi_{\theta_{old}}}(s_t)\right)\right]\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t\left(r_t+\gamma V^{\pi_{\theta_{old}}}(s_{t+1})-V^{\pi_{\theta_{old}}}(s_t)\right)\right]\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t\left(\gamma Q^{\pi_{\theta_{old}}}(s_{t}, a_t)-V^{\pi_{\theta_{old}}}(s_t)\right)\right]\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t A^{\pi_{\theta_{old}}}(s_t,a_t)\right]\\
\end{aligned} J ( θ ) − J ( θ o l d ) = J ( θ ) − E s 0 ∼ p 0 [ V π θ o l d ( s 0 ) ] = J ( θ ) − E τ ∼ ( p 0 , π θ , p ) [ V π θ o l d ( s 0 ) ] = J ( θ ) − E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t V π θ o l d ( s t ) − t = 1 ∑ T − 1 γ t V π θ o l d ( s t ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t r t ] + E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t ( γ V π θ o l d ( s t + 1 ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t ( r t + γ V π θ o l d ( s t + 1 ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t ( γ Q π θ o l d ( s t , a t ) − V π θ o l d ( s t ) ) ] = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t A π θ o l d ( s t , a t ) ] 我们进一步展开得到
J ( θ ) − J ( θ o l d ) = E τ ∼ ( p 0 , π θ , p ) [ ∑ t = 0 T − 1 γ t A π θ o l d ( s t , a t ) ] = E s 0 ∼ p 0 , a 0 ∼ π θ ( ⋅ ∣ s 0 ) [ A π θ o l d ( s 0 , a 0 ) + E π θ [ ∑ t = 1 T − 1 γ t A π θ o l d ( s t , a t ) ∣ s 0 , a 0 ] ] = E s 0 ∼ p 0 , a 0 ∼ π θ ( ⋅ ∣ s 0 ) , a 0 ′ ∼ π θ o l d ( ⋅ ∣ s 0 ) [ π θ ( a 0 ′ ∣ s 0 ) π θ o l d ( a 0 ′ ∣ s 0 ) A π θ o l d ( s 0 , a 0 ′ ) + E π θ [ ∑ t = 1 T − 1 γ t A π θ o l d ( s t , a t ) ∣ s 0 , a 0 ] ] = … ( keep enrolling the summation ) = E τ ∼ ( p 0 , π θ , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] \begin{align}
\mathcal{J}(\theta) -\mathcal{J}(\theta_{old}) &= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p)}\left[\sum_{t=0}^{T-1}\gamma^t A^{\pi_{\theta_{old}}}(s_t,a_t)\right]\\
&= \mathbb{E}_{s_0\sim p_0, a_0\sim\pi_\theta(\cdot\mid s_0)}\left[A^{\pi_{\theta_{old}}}(s_0,a_0)+\mathbb{E}^{\pi_\theta}\left[\sum_{t=1}^{T-1}\gamma^t A^{\pi_{\theta_{old}}}(s_t,a_t)\mid s_0, a_0\right]\right]\\
&= \mathbb{E}_{s_0\sim p_0, a_0\sim\pi_\theta(\cdot\mid s_0),a_0'\sim \pi_{\theta_{old}}(\cdot\mid s_0)}\left[\frac{\pi_{\theta}(a_0'\mid s_0)}{\pi_{\theta_{old}}(a_0'\mid s_0)}A^{\pi_{\theta_{old}}}(s_0,a_0')+\mathbb{E}^{\pi_\theta}\left[\sum_{t=1}^{T-1}\gamma^t A^{\pi_{\theta_{old}}}(s_t,a_t)\mid s_0, a_0\right]\right]\\
&=\dots (\text{keep enrolling the summation})\\
&= \mathbb{E}_{\tau\sim (p_0,\pi_\theta, p),a_t'\sim \pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t \frac{\pi_{\theta}(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]\\
\end{align} J ( θ ) − J ( θ o l d ) = E τ ∼ ( p 0 , π θ , p ) [ t = 0 ∑ T − 1 γ t A π θ o l d ( s t , a t ) ] = E s 0 ∼ p 0 , a 0 ∼ π θ ( ⋅ ∣ s 0 ) [ A π θ o l d ( s 0 , a 0 ) + E π θ [ t = 1 ∑ T − 1 γ t A π θ o l d ( s t , a t ) ∣ s 0 , a 0 ] ] = E s 0 ∼ p 0 , a 0 ∼ π θ ( ⋅ ∣ s 0 ) , a 0 ′ ∼ π θ o l d ( ⋅ ∣ s 0 ) [ π θ o l d ( a 0 ′ ∣ s 0 ) π θ ( a 0 ′ ∣ s 0 ) A π θ o l d ( s 0 , a 0 ′ ) + E π θ [ t = 1 ∑ T − 1 γ t A π θ o l d ( s t , a t ) ∣ s 0 , a 0 ] ] = … ( keep enrolling the summation ) = E τ ∼ ( p 0 , π θ , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] 因此,我们有
J ( θ ) = E τ ∼ ( p 0 , π θ , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] + C \mathcal{J}(\theta) = \mathbb{E}_{\tau\sim(p_0,\textcolor{red}{\pi_\theta}, p),a_t'\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t\frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]+C J ( θ ) = E τ ∼ ( p 0 , π θ , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] + C 但是,现在我们的更姓还是依赖于 π θ \pi_\theta π θ 当 π θ \pi_\theta π θ π θ o l d \pi_{\theta_{old}} π θ o l d π θ o l d \pi_{\theta_{old}} π θ o l d π θ \pi_\theta π θ , 这样,上面目标函数就变成了
max θ K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s . t . π θ o l d ≈ π θ \begin{align}
\max_{\theta}\ &\mathcal{K}(\theta;\theta_{old}) = \mathbb{E}_{\tau\sim(p_0,\pi_{\theta_{old}}, p),a_t'\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t\frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]\\
\mathrm{s.t.}\ &\pi_{\theta_{old}}\approx \pi_\theta
\end{align} θ max s.t. K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] π θ o l d ≈ π θ 我们可以证明
∇ J ( θ ) ∣ θ = θ o l d = ∇ θ K ( θ ; θ o l d ) ∣ θ = θ o l d \nabla \mathcal{J}(\theta)\mid _{\theta=\theta_{old}} = \nabla_\theta \mathcal{K}(\theta;\theta_{old})\mid _{\theta=\theta_{old}} ∇ J ( θ ) ∣ θ = θ o l d = ∇ θ K ( θ ; θ o l d ) ∣ θ = θ o l d 这就是 TRPO 的核心改进,在实际求解时,我们将上面的问题规范为如下形式
max θ K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s . t . max s ∈ S K L ( π θ o l d ( ⋅ ∣ s ) ∣ ∣ π θ ( ⋅ ∣ s ) ) ≤ δ \begin{align}
\max_{\theta}\ &\mathcal{K}(\theta;\theta_{old}) = \mathbb{E}_{\tau\sim(p_0,\pi_{\theta_{old}}, p),a_t'\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t\frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]\\
\mathrm{s.t.}\ &\max_{s\in\mathcal{S}}\mathrm{KL}(\pi_{\theta_{old}}(\cdot\mid s)\mid\mid \pi_\theta(\cdot\mid s))\leq \delta
\end{align} θ max s.t. K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s ∈ S max KL ( π θ o l d ( ⋅ ∣ s ) ∣∣ π θ ( ⋅ ∣ s )) ≤ δ 这里 δ > 0 \delta>0 δ > 0
现在我们可以采样多条轨迹 τ ( i ) ∼ ( p 0 , π θ o l d , p ) \tau^{(i)}\sim (p_0,\pi_{\theta_{old}}, p) τ ( i ) ∼ ( p 0 , π θ o l d , p ) K ( θ ; θ o l d ) \mathcal{K}(\theta;\theta_{old}) K ( θ ; θ o l d )
K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 γ t π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A π θ o l d ( s t , a t ) ] ≈ 1 N ∑ i = 1 N ∑ t = 0 T ( i ) − 1 γ t π θ ( a t ( i ) ∣ s t ( i ) ) π θ o l d ( a t ( i ) ∣ s t ( i ) ) A ^ t \mathcal{K}(\theta;\theta_{old}) = \mathbb{E}_{\tau\sim(p_0,\pi_{\theta_{old}}, p),a_t\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\gamma^t\frac{\pi_\theta(a_t\mid s_t)}{\pi_{\theta_{old}}(a_t\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t)\right]\approx \frac{1}{N}\sum_{i=1}^N\sum_{t=0}^{T^{(i)}-1}\gamma^t\frac{\pi_\theta(a_t^{(i)}\mid s_t^{(i)})}{\pi_{\theta_{old}}(a_t^{(i)}\mid s_t^{(i)})}\hat{A}_t K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 γ t π θ o l d ( a t ∣ s t ) π θ ( a t ∣ s t ) A π θ o l d ( s t , a t ) ] ≈ N 1 i = 1 ∑ N t = 0 ∑ T ( i ) − 1 γ t π θ o l d ( a t ( i ) ∣ s t ( i ) ) π θ ( a t ( i ) ∣ s t ( i ) ) A ^ t 这里 A ^ t ≈ A π θ o l d ( s t , a t ) \hat{A}_t\approx A^{\pi_{\theta_{old}}}(s_t,a_t) A ^ t ≈ A π θ o l d ( s t , a t ) N N N π θ ≈ π θ o l d \pi_{\theta}\approx \pi_{\theta_{old}} π θ ≈ π θ o l d
在实际实现中,由于 discount factor γ < 1 \gamma < 1 γ < 1 γ = 1 \gamma = 1 γ = 1 gamma trick :通过适当选择 γ \gamma γ
更具体地,当 γ < 1 \gamma < 1 γ < 1
远期奖励对当前决策的影响被衰减,这在经济学中是合理的(现值概念).
有助于减少远期估计的方差(远期的 V π V^{\pi} V π
在 TRPO 的 derivation 中,γ \gamma γ γ \gamma γ π θ ≈ π θ o l d \pi_{\theta} \approx \pi_{\theta_{old}} π θ ≈ π θ o l d
我们把上面的结果整理为如下算法
Algorithm: TRPO MC
Initialize policy parameters θ 0 \theta_0 θ 0 ϕ 0 \phi_0 ϕ 0 δ > 0 \delta > 0 δ > 0
for k = 0 , 1 , … k = 0, 1, \dots k = 0 , 1 , …
Sample N N N { τ i } \{\tau_i\} { τ i } ( p 0 , π θ k , p ) (p_0, \pi_{\theta_k}, p) ( p 0 , π θ k , p )
Solve the constrained optimization :
max θ k + 1 1 N ∑ i = 1 N ∑ t = 0 T ( i ) − 1 π θ k + 1 ( a t ( i ) ∣ s t ( i ) ) π θ k ( a t ( i ) ∣ s t ( i ) ) A ^ t s . t . max s ∈ S K L ( π θ k ( ⋅ ∣ s ) ∣ ∣ π θ k + 1 ( ⋅ ∣ s ) ) ≤ δ \begin{aligned}
\max_{\theta_{k+1}} \quad &\frac{1}{N} \sum_{i=1}^{N} \sum_{t=0}^{T^{(i)}-1} \frac{\pi_{\theta_{k+1}}(a_t^{(i)} \mid s_t^{(i)})}{\pi_{\theta_k}(a_t^{(i)} \mid s_t^{(i)})} \hat{A}_t \\
\mathrm{s.t.} \quad &\max_{s \in \mathcal{S}} \mathrm{KL}(\pi_{\theta_{k}}(\cdot \mid s) \mid\mid \pi_{\theta_{k+1}}(\cdot \mid s)) \leq \delta
\end{aligned} θ k + 1 max s.t. N 1 i = 1 ∑ N t = 0 ∑ T ( i ) − 1 π θ k ( a t ( i ) ∣ s t ( i ) ) π θ k + 1 ( a t ( i ) ∣ s t ( i ) ) A ^ t s ∈ S max KL ( π θ k ( ⋅ ∣ s ) ∣∣ π θ k + 1 ( ⋅ ∣ s )) ≤ δ Compute R ^ t ( i ) = γ t ′ − t r t ′ ( i ) \hat{R}_t^{(i)} = \gamma^{t'-t} r_{t'}^{(i)} R ^ t ( i ) = γ t ′ − t r t ′ ( i ) i = 1 , … , N i = 1, \dots, N i = 1 , … , N t = 1 , … , T ( i ) − 1 t = 1, \dots, T^{(i)}-1 t = 1 , … , T ( i ) − 1
Update the value model :
min ϕ 1 N ∑ i = 1 N 1 T ( i ) ∑ t = 0 T ( i ) − 1 1 2 ( V ϕ ( s t ( i ) ) − R ^ t ( i ) ) 2 \min_{\phi} \frac{1}{N} \sum_{i=1}^{N} \frac{1}{T^{(i)}} \sum_{t=0}^{T^{(i)}-1} \frac{1}{2} \left(V_{\phi}(s_t^{(i)}) - \hat{R}_t^{(i)}\right)^2 ϕ min N 1 i = 1 ∑ N T ( i ) 1 t = 0 ∑ T ( i ) − 1 2 1 ( V ϕ ( s t ( i ) ) − R ^ t ( i ) ) 2
关于这个优化问题的解法可以参考后续 discussion 章节
我们将目标函数和约束进行泰勒展开得到
K ( θ ; θ o l d ) ≈ g T ( θ − θ k ) K L ( θ ∣ ∣ θ k ) ≈ 1 2 ( θ − θ k ) T H ( θ − θ k ) \begin{align}
\mathcal{K}(\theta;\theta_{old}) &\approx g^T(\theta-\theta_k) \\
\mathrm{KL}(\theta\mid\mid \theta_k)&\approx \frac12(\theta-\theta_k)^TH(\theta-\theta_k)
\end{align} K ( θ ; θ o l d ) KL ( θ ∣∣ θ k ) ≈ g T ( θ − θ k ) ≈ 2 1 ( θ − θ k ) T H ( θ − θ k ) 这样我们的优化目标就近似为
max θ g T ( θ − θ k ) s . t . 1 2 ( θ − θ k ) T H ( θ − θ k ) ≤ δ \begin{align}
\max_{\theta}\ & g^T(\theta-\theta_k)\\
\mathrm{s.t.}\ & \frac12(\theta-\theta_k)^TH(\theta-\theta_k)\leq\delta
\end{align} θ max s.t. g T ( θ − θ k ) 2 1 ( θ − θ k ) T H ( θ − θ k ) ≤ δ 这个目标函数与 TRO (trust region methods) 一致,因此我们可以使用类似的做法来解决,我们可以得到上面问题的准确表达式
θ k + 1 = θ k + 2 δ g T H − 1 g H − 1 g \theta_{k+1} = \theta_k + \sqrt{\frac{2\delta}{g^TH^{-1}g}}H^{-1}g θ k + 1 = θ k + g T H − 1 g 2 δ H − 1 g 但是,由于我们使用了 Taylor 展开,实际上我们的更新并不一定满足 KL divergence 的约束,TRPO 对此进行了改进,即在更新时加入了 line search 来使得 θ k + 1 \theta_{k+1} θ k + 1
θ k + 1 = θ k + α j 2 δ g T H − 1 g H − 1 g \theta_{k+1} = \theta_k + \alpha^j\sqrt{\frac{2\delta}{g^TH^{-1}g}}H^{-1}g θ k + 1 = θ k + α j g T H − 1 g 2 δ H − 1 g 其中 α ∈ ( 0 , 1 ) \alpha\in(0,1) α ∈ ( 0 , 1 ) j j j θ k + 1 \theta_{k+1} θ k + 1 k k k
虽然 TRPO 的理论形式非常简单,但是实际上实现起来很麻烦。其根本原因在于这个约束比较难以满足,原始论文中使用了 line search 来解决这个问题,但是当状态空间大了之后,速度会显著下降,这也是 PPO 的核心贡献之一。
Schulman, J., Levine, S., Moritz, P., Jordan, M. I., & Abbeel, P. (2015). Trust Region Policy Optimization. Proceedings of the 32nd International Conference on Machine Learning (ICML) . 在上一节中,我们介绍了 TRPO 算法,TRPO 算法是一个二阶算法,TRPO 大幅度提高了 sample efficiency, 但是其问题在于计算/优化太过复杂。因此,PPO 就通过 clip 等技巧保留了 TRPO 思想并降低了计算难度。
在 TRPO 算法中,我们的优化问题形式为:
max θ K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ ∑ t = 0 T − 1 π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s . t . max s ∈ S K L ( π θ o l d ( ⋅ ∣ s ) ∣ ∣ π θ ( ⋅ ∣ s ) ) ≤ δ \begin{align}
\max_{\theta}\ &\mathcal{K}(\theta;\theta_{old}) = \mathbb{E}_{\tau\sim(p_0,\pi_{\theta_{old}}, p),a_t'\sim\pi_{\theta_{old}}(\cdot\mid s_t)}\left[\sum_{t=0}^{T-1}\frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)}A^{\pi_{\theta_{old}}}(s_t,a_t')\right]\\
\mathrm{s.t.}\ &\max_{s\in\mathcal{S}}\mathrm{KL}(\pi_{\theta_{old}}(\cdot\mid s)\mid\mid \pi_{\theta}(\cdot\mid s))\leq \delta
\end{align} θ max s.t. K ( θ ; θ o l d ) = E τ ∼ ( p 0 , π θ o l d , p ) , a t ′ ∼ π θ o l d ( ⋅ ∣ s t ) [ t = 0 ∑ T − 1 π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) A π θ o l d ( s t , a t ′ ) ] s ∈ S max KL ( π θ o l d ( ⋅ ∣ s ) ∣∣ π θ ( ⋅ ∣ s )) ≤ δ TRPO 的核心思想为,当 π θ \pi_{\theta} π θ π θ o l d \pi_{\theta_{old}} π θ o l d K ( θ ; θ o l d ) \mathcal{K}(\theta;\theta_{old}) K ( θ ; θ o l d ) J ( θ ) \mathcal{J}(\theta) J ( θ )
PPO 针对这一点核心观点进行了扩展,我们可以通过另一种形式来约束 π θ \pi_{\theta} π θ π θ o l d \pi_{\theta_{old}} π θ o l d
r t ( θ ) : = π θ ( a t ′ ∣ s t ) π θ o l d ( a t ′ ∣ s t ) ≈ 1 r_t(\theta) := \frac{\pi_\theta(a_t'\mid s_t)}{\pi_{\theta_{old}}(a_t'\mid s_t)} \approx 1 r t ( θ ) := π θ o l d ( a t ′ ∣ s t ) π θ ( a t ′ ∣ s t ) ≈ 1 基于这个思想,我们可以丢弃 TRPO 的约束,直接对 r t ( θ ) r_t(\theta) r t ( θ ) c l i p \mathrm{clip} clip
J ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ o l d ( ⋅ ∣ q ) [ c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ] \mathcal{J}(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},o_{\leq t}\sim \pi_{\theta_{old}}(\cdot\mid q)}\left[ \mathrm{clip}\left(r_t(\theta), 1-\epsilon, 1+\epsilon\right)\hat{A}_t \right] J ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ o l d ( ⋅ ∣ q ) [ clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ] 这里 ϵ > 0 \epsilon>0 ϵ > 0 δ \delta δ
c l i p ( x , ℓ , r ) = { ℓ , if x ≤ ℓ x , if ℓ < x < r r , if x ≥ r \mathrm{clip}(x,\ell, r)=\begin{cases}
\ell, &\text{ if }x\leq \ell\\
x, &\text{ if }\ell<x<r\\
r, &\text{ if }x \geq r
\end{cases} clip ( x , ℓ , r ) = ⎩ ⎨ ⎧ ℓ , x , r , if x ≤ ℓ if ℓ < x < r if x ≥ r 现在我们已经通过 c l i p \mathrm{clip} clip
从结果中我们可以看出,只有当 r t ≈ 1 r_t\approx 1 r t ≈ 1 A ^ t > 0 , r t < 1 − ϵ \hat{A}_t>0, r_t<1-\epsilon A ^ t > 0 , r t < 1 − ϵ A ^ t < 0 , r t < 1 − ϵ \hat{A}_t<0, r_t<1-\epsilon A ^ t < 0 , r t < 1 − ϵ c l i p \mathrm{clip} clip min \min min
J P P O ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ o l d ( ⋅ ∣ q ) [ min ( r t ( θ ) A ^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] \mathcal{J}_{\mathrm{PPO}}(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},o_{\leq t}\sim \pi_{\theta_{old}}(\cdot\mid q)}\left[ \min\left(r_t(\theta)\hat{A}_t,\mathrm{clip}\left(r_t(\theta), 1-\epsilon, 1+\epsilon\right)\hat{A}_t\right) \right] J PPO ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ o l d ( ⋅ ∣ q ) [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] 此时,我们再对目标函数进行分析,就得到
可以看到,此时 PPO 的目标函数就解决了 sample efficiency 过低的问题了。
其中
r t ( θ ) = π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) r_t(\theta) = \frac{\pi_{\theta}(o_t\mid q, o_{< t})}{\pi_{\theta_{old}}(o_t\mid q, o_{< t})} r t ( θ ) = π θ o l d ( o t ∣ q , o < t ) π θ ( o t ∣ q , o < t ) ( q , a ) (q,a) ( q , a ) D \mathcal{D} D ϵ > 0 \epsilon>0 ϵ > 0 A ^ t \hat{A}_t A ^ t t t t V V V R R R A ^ t \hat{A}_t A ^ t
A ^ t G A E ( γ , λ ) = ∑ k = 0 ∞ ( γ λ ) k δ t + k \hat{A}_t^{\mathrm{GAE}(\gamma, \lambda)}=\sum_{k=0}^{\infty}(\gamma\lambda)^k\delta_{t+k} A ^ t GAE ( γ , λ ) = k = 0 ∑ ∞ ( γ λ ) k δ t + k 其中
δ k = R k + γ V ( s k + 1 ) − V ( s k ) , 0 ≤ γ , λ ≤ 1 \delta_k = R_k + \gamma V(s_{k+1})-V(s_k),\quad 0\leq \gamma,\lambda\leq 1 δ k = R k + γ V ( s k + 1 ) − V ( s k ) , 0 ≤ γ , λ ≤ 1 TODO
GRPO (Group Relative Policy Optimization) 是 DeepSeek 提出的 RL 算法,相比于 PPO,GRPO 不依赖于 value function(因此也不需要 reward model 来训练 critic),而是通过同一 prompt 下的多组输出来估计 advantage.
PPO 需要维护一个 value function V ϕ V_{\phi} V ϕ A t A_t A t
A ^ t G A E = ∑ k = 0 ∞ ( γ λ ) k δ t + k , δ k = r k + γ V ϕ ( s k + 1 ) − V ϕ ( s k ) \hat{A}_t^{\mathrm{GAE}} = \sum_{k=0}^{\infty} (\gamma\lambda)^k \delta_{t+k}, \quad \delta_k = r_k + \gamma V_{\phi}(s_{k+1}) - V_{\phi}(s_k) A ^ t GAE = k = 0 ∑ ∞ ( γ λ ) k δ t + k , δ k = r k + γ V ϕ ( s k + 1 ) − V ϕ ( s k ) 但是在 LLM 场景下,训练 value function 会带来额外的计算和内存开销:
需要额外训练一个与 policy model 规模相当的 critic model
需要 reward model 提供的 token-level reward(而很多 verifier 只提供 outcome-level reward)
GRPO 的核心思想:用同一 prompt 下的一组输出来估计 baseline(即群体级别的相对奖励),从而避免训练 value function.
给定 QA pair ( q , a ) (q, a) ( q , a ) π θ o l d \pi_{\theta_{old}} π θ o l d G G G { o i } i = 1 G \{o_i\}_{i=1}^G { o i } i = 1 G { R i } i = 1 G \{R_i\}_{i=1}^G { R i } i = 1 G
Advantage Estimation :
GRPO 使用 group-level 归一化来估计 advantage:
A ^ i , t = R i − m e a n ( { R i } i = 1 G ) s t d ( { R i } i = 1 G ) \hat{A}_{i,t} = \frac{R_i - \mathrm{mean}(\{R_i\}_{i=1}^G)}{\mathrm{std}(\{R_i\}_{i=1}^G)} A ^ i , t = std ({ R i } i = 1 G ) R i − mean ({ R i } i = 1 G ) 这里 advantage A ^ i , t \hat{A}_{i,t} A ^ i , t t t t
💡
直观理解:同一 prompt 下的 G G G A t = Q t − V t A_t = Q_t - V_t A t = Q t − V t V t V_t V t
GRPO Objective :
GRPO 的训练目标与 PPO 类似,但在分组上进行了归一化:
J G R P O ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) [ 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) ] \mathcal{J}_{\mathrm{GRPO}}(\theta) = \mathbb{E}_{(q, a) \sim \mathcal{D}, \, \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(\cdot \mid q)}\left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min\left(r_{i,t}(\theta) \hat{A}_{i,t}, \; \mathrm{clip}\left(r_{i,t}(\theta), 1 - \epsilon, 1 + \epsilon\right) \hat{A}_{i,t}\right) \right] J GRPO ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) G 1 i = 1 ∑ G ∣ o i ∣ 1 t = 1 ∑ ∣ o i ∣ min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) 其中:
r i , t ( θ ) = π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) r_{i,t}(\theta) = \frac{\pi_{\theta}(o_{i,t} \mid q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t} \mid q, o_{i,<t})} r i , t ( θ ) = π θ o l d ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) 是 importance sampling ratio,衡量新旧策略在 token o i , t o_{i,t} o i , t
⚠️
GRPO 中 A ^ i , t \hat{A}_{i,t} A ^ i , t
在实际的 RLHF/GRPO 训练中,通常会在 reward 中减去一个 KL 惩罚项,以防止模型偏离 reference model 太远:
R i = R t a s k ( o i ) − β K L ( π θ ∥ π r e f ) R_i = R_{\mathrm{task}}(o_i) - \beta \, \mathrm{KL}(\pi_{\theta} \| \pi_{\mathrm{ref}}) R i = R task ( o i ) − β KL ( π θ ∥ π ref ) 其中 β > 0 \beta > 0 β > 0 π r e f \pi_{\mathrm{ref}} π ref
常用的 KL 估计方式包括:
Kullback-Leibler divergence : K L ( π θ ∥ π r e f ) = E o ∼ π θ [ log π θ ( o ∣ q ) π r e f ( o ∣ q ) ] \mathrm{KL}(\pi_{\theta} \| \pi_{\mathrm{ref}}) = \mathbb{E}_{o \sim \pi_{\theta}}\left[\log\frac{\pi_{\theta}(o \mid q)}{\pi_{\mathrm{ref}}(o \mid q)}\right] KL ( π θ ∥ π ref ) = E o ∼ π θ [ log π ref ( o ∣ q ) π θ ( o ∣ q ) ] Unbiased KL estimator : DeepSeek 使用的低方差估计,形式为:
K L ( π θ ∥ π r e f ) = π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − log π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 \mathrm{KL}(\pi_{\theta} \| \pi_{\mathrm{ref}}) = \frac{\pi_{\mathrm{ref}}(o_{i,t} \mid q, o_{i,<t})}{\pi_{\theta}(o_{i,t} \mid q, o_{i,<t})} - \log\frac{\pi_{\mathrm{ref}}(o_{i,t} \mid q, o_{i,<t})}{\pi_{\theta}(o_{i,t} \mid q, o_{i,<t})} - 1 KL ( π θ ∥ π ref ) = π θ ( o i , t ∣ q , o i , < t ) π ref ( o i , t ∣ q , o i , < t ) − log π θ ( o i , t ∣ q , o i , < t ) π ref ( o i , t ∣ q , o i , < t ) − 1
GRPO 的典型训练流程如下:
Algorithm: GRPO Training
Input : Dataset D \mathcal{D} D π r e f \pi_{\mathrm{ref}} π ref G G G Initialize : policy π θ = π r e f \pi_{\theta} = \pi_{\mathrm{ref}} π θ = π ref for each training iteration:
Sample a batch of prompts { q } \{q\} { q } D \mathcal{D} D
For each prompt q q q G G G { o i } \{o_i\} { o i } π θ \pi_{\theta} π θ o i ∼ π θ ( ⋅ ∣ q ) , i = 1 , … , G o_i \sim \pi_{\theta}(\cdot \mid q), \quad i = 1, \dots, G o i ∼ π θ ( ⋅ ∣ q ) , i = 1 , … , G
Compute reward for each response:
R i = R t a s k ( o i ) − β K L ( π θ ∥ π r e f ) R_i = R_{\mathrm{task}}(o_i) - \beta \, \mathrm{KL}(\pi_{\theta} \| \pi_{\mathrm{ref}}) R i = R task ( o i ) − β KL ( π θ ∥ π ref )
Compute group-level advantage:
A ^ i = R i − m e a n ( { R } ) s t d ( { R } ) \hat{A}_i = \frac{R_i - \mathrm{mean}(\{R\})}{\mathrm{std}(\{R\})} A ^ i = std ({ R }) R i − mean ({ R })
Update π θ \pi_{\theta} π θ L = 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( r i , t ( θ ) A ^ i , c l i p ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i ) \mathcal{L} = \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min\!\left(r_{i,t}(\theta) \hat{A}_i, \; \mathrm{clip}\!\left(r_{i,t}(\theta), 1 - \epsilon, 1 + \epsilon\right) \hat{A}_i\right) L = G 1 i = 1 ∑ G ∣ o i ∣ 1 t = 1 ∑ ∣ o i ∣ min ( r i , t ( θ ) A ^ i , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i )
(Optional) Update π r e f \pi_{\mathrm{ref}} π ref
无需求解 value function : 在 LLM 场景下,action space (词表) 和 state space (上下文) 极大,训练 value function 是非常困难且昂贵的。GRPO 通过 group 比较自然避免了这一问题.
Outcome-level reward 友好 : 许多 LLM 任务(如数学推理、代码生成)只有最终的 outcome reward (答案正确与否)。GRPO 可以直接利用 outcome reward,无需 reward model 提供 token-level reward.
简单高效 : GRPO 的实现相对简单,无需维护 critic network,计算和内存开销更小.